Bogog00000000000000
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Translators' Tool
The Translator’s Tool Box A Computer Primer for Translators by Jost Zetzsche Version 9, December 2010 Copyright © 2010 International Writers’ Group, LLC. All rights reserved. This document, or any part thereof, may not be reproduced or transmitted electronically or by any other means without the prior written permission of International Writers’ Group, LLC. ABBYY FineReader and PDF Transformer are copyrighted by ABBYY Software House. Acrobat, Acrobat Reader, Dreamweaver, FrameMaker, HomeSite, InDesign, Illustrator, PageMaker, Photoshop, and RoboHelp are registered trademarks of Adobe Systems Inc. Acrocheck is copyrighted by acrolinx GmbH. Acronis True Image is a trademark of Acronis, Inc. Across is a trademark of Nero AG. AllChars is copyrighted by Jeroen Laarhoven. ApSIC Xbench and Comparator are copyrighted by ApSIC S.L. Araxis Merge is copyrighted by Araxis Ltd. ASAP Utilities is copyrighted by eGate Internet Solutions. Authoring Memory Tool is copyrighted by Sajan. Belarc Advisor is a trademark of Belarc, Inc. Catalyst and Publisher are trademarks of Alchemy Software Development Ltd. ClipMate is a trademark of Thornsoft Development. ColourProof, ColourTagger, and QA Solution are copyrighted by Yamagata Europe. Complete Word Count is copyrighted by Shauna Kelly. CopyFlow is a trademark of North Atlantic Publishing Systems, Inc. CrossCheck is copyrighted by Global Databases, Ltd. Déjà Vu is a trademark of ATRIL Language Engineering, S.L. Docucom PDF Driver is copyrighted by Zeon Corporation. dtSearch is a trademark of dtSearch Corp. EasyCleaner is a trademark of ToniArts. ExamDiff Pro is a trademark of Prestosoft. EmEditor is copyrighted by Emura Software inc. Error Spy is copyrighted by D.O.G. GmbH. FileHippo is copyrighted by FileHippo.com. -
Compress/Decompress Encrypt/Decrypt
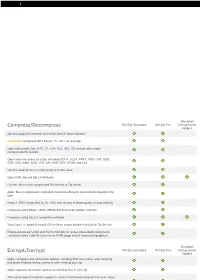
Windows Compress/Decompress WinZip Standard WinZip Pro Compressed Folders Zip and unzip files instantly with 64-bit, best-in-class software ENHANCED! Compress MP3 files by 15 - 20 % on average Open and extract Zipx, RAR, 7Z, LHA, BZ2, IMG, ISO and all other major compression file formats Open more files types as a Zip, including DOCX, XLSX, PPTX, XPS, ODT, ODS, ODP, ODG,WMZ, WSZ, YFS, XPI, XAP, CRX, EPUB, and C4Z Use the super picker to unzip locally or to the cloud Open CAB, Zip and Zip 2.0 Methods Convert other major compressed file formats to Zip format Apply 'Best Compression' method to maximize efficiency automatically based on file type Reduce JPEG image files by 20 - 25% with no loss of photo quality or data integrity Compress using BZip2, LZMA, PPMD and Enhanced Deflate methods Compress using Zip 2.0 compatible methods 'Auto Open' a zipped Microsoft Office file by simply double-clicking the Zip file icon Employ advanced 'Unzip and Try' functionality to review interrelated components contained within a Zip file (such as an HTML page and its associated graphics). Windows Encrypt/Decrypt WinZip Standard WinZip Pro Compressed Folders Apply encryption and conversion options, including PDF conversion, watermarking and photo resizing, before, during or after creating your zip Apply separate conversion options to individual files in your zip Take advantage of hardware support in certain Intel-based computers for even faster AES encryption Administrative lockdown of encryption methods and password policies Check 'Encrypt' to password protect your files using banking-level encryption and keep them completely secure Secure sensitive data with strong, FIPS-197 certified AES encryption (128- and 256- bit) Auto-wipe ('shred') temporarily extracted copies of encrypted files using the U.S. -

ACS – the Archival Cytometry Standard
http://flowcyt.sf.net/acs/latest.pdf ACS – the Archival Cytometry Standard Archival Cytometry Standard ACS International Society for Advancement of Cytometry Candidate Recommendation DRAFT Document Status The Archival Cytometry Standard (ACS) has undergone several revisions since its initial development in June 2007. The current proposal is an ISAC Candidate Recommendation Draft. It is assumed, however not guaranteed, that significant features and design aspects will remain unchanged for the final version of the Recommendation. This specification has been formally tested to comply with the W3C XML schema version 1.0 specification but no position is taken with respect to whether a particular software implementing this specification performs according to medical or other valid regulations. The work may be used under the terms of the Creative Commons Attribution-ShareAlike 3.0 Unported license. You are free to share (copy, distribute and transmit), and adapt the work under the conditions specified at http://creativecommons.org/licenses/by-sa/3.0/legalcode. Disclaimer of Liability The International Society for Advancement of Cytometry (ISAC) disclaims liability for any injury, harm, or other damage of any nature whatsoever, to persons or property, whether direct, indirect, consequential or compensatory, directly or indirectly resulting from publication, use of, or reliance on this Specification, and users of this Specification, as a condition of use, forever release ISAC from such liability and waive all claims against ISAC that may in any manner arise out of such liability. ISAC further disclaims all warranties, whether express, implied or statutory, and makes no assurances as to the accuracy or completeness of any information published in the Specification. -

Table of Contents Modules and Packages
Table of Contents Modules and Packages...........................................................................................1 Software on NAS Systems..................................................................................................1 Using Software Packages in pkgsrc...................................................................................4 Using Software Modules....................................................................................................7 Modules and Packages Software on NAS Systems UPDATE IN PROGRESS: Starting with version 2.17, SGI MPT is officially known as HPE MPT. Use the command module load mpi-hpe/mpt to get the recommended version of MPT library on NAS systems. This article is being updated to reflect this change. Software programs on NAS systems are managed as modules or packages. Available programs are listed in tables below. Note: The name of a software module or package may contain additional information, such as the vendor name, version number, or what compiler/library is used to build the software. For example: • comp-intel/2016.2.181 - Intel Compiler version 2016.2.181 • mpi-sgi/mpt.2.15r20 - SGI MPI library version 2.15r20 • netcdf/4.4.1.1_mpt - NetCDF version 4.4.1.1, built with SGI MPT Modules Use the module avail command to see all available software modules. Run module whatis to view a short description of every module. For more information about a specific module, run module help modulename. See Using Software Modules for more information. Available Modules (as -

Pack, Encrypt, Authenticate Document Revision: 2021 05 02
PEA Pack, Encrypt, Authenticate Document revision: 2021 05 02 Author: Giorgio Tani Translation: Giorgio Tani This document refers to: PEA file format specification version 1 revision 3 (1.3); PEA file format specification version 2.0; PEA 1.01 executable implementation; Present documentation is released under GNU GFDL License. PEA executable implementation is released under GNU LGPL License; please note that all units provided by the Author are released under LGPL, while Wolfgang Ehrhardt’s crypto library units used in PEA are released under zlib/libpng License. PEA file format and PCOMPRESS specifications are hereby released under PUBLIC DOMAIN: the Author neither has, nor is aware of, any patents or pending patents relevant to this technology and do not intend to apply for any patents covering it. As far as the Author knows, PEA file format in all of it’s parts is free and unencumbered for all uses. Pea is on PeaZip project official site: https://peazip.github.io , https://peazip.org , and https://peazip.sourceforge.io For more information about the licenses: GNU GFDL License, see http://www.gnu.org/licenses/fdl.txt GNU LGPL License, see http://www.gnu.org/licenses/lgpl.txt 1 Content: Section 1: PEA file format ..3 Description ..3 PEA 1.3 file format details ..5 Differences between 1.3 and older revisions ..5 PEA 2.0 file format details ..7 PEA file format’s and implementation’s limitations ..8 PCOMPRESS compression scheme ..9 Algorithms used in PEA format ..9 PEA security model .10 Cryptanalysis of PEA format .12 Data recovery from -

Metadefender Core V4.12.2
MetaDefender Core v4.12.2 © 2018 OPSWAT, Inc. All rights reserved. OPSWAT®, MetadefenderTM and the OPSWAT logo are trademarks of OPSWAT, Inc. All other trademarks, trade names, service marks, service names, and images mentioned and/or used herein belong to their respective owners. Table of Contents About This Guide 13 Key Features of Metadefender Core 14 1. Quick Start with Metadefender Core 15 1.1. Installation 15 Operating system invariant initial steps 15 Basic setup 16 1.1.1. Configuration wizard 16 1.2. License Activation 21 1.3. Scan Files with Metadefender Core 21 2. Installing or Upgrading Metadefender Core 22 2.1. Recommended System Requirements 22 System Requirements For Server 22 Browser Requirements for the Metadefender Core Management Console 24 2.2. Installing Metadefender 25 Installation 25 Installation notes 25 2.2.1. Installing Metadefender Core using command line 26 2.2.2. Installing Metadefender Core using the Install Wizard 27 2.3. Upgrading MetaDefender Core 27 Upgrading from MetaDefender Core 3.x 27 Upgrading from MetaDefender Core 4.x 28 2.4. Metadefender Core Licensing 28 2.4.1. Activating Metadefender Licenses 28 2.4.2. Checking Your Metadefender Core License 35 2.5. Performance and Load Estimation 36 What to know before reading the results: Some factors that affect performance 36 How test results are calculated 37 Test Reports 37 Performance Report - Multi-Scanning On Linux 37 Performance Report - Multi-Scanning On Windows 41 2.6. Special installation options 46 Use RAMDISK for the tempdirectory 46 3. Configuring Metadefender Core 50 3.1. Management Console 50 3.2. -

Scalable Speculative Parallelization on Commodity Clusters
Scalable Speculative Parallelization on Commodity Clusters Hanjun Kim Arun Raman Feng Liu Jae W. Leey David I. August Departments of Electrical Engineering and Computer Science y Parakinetics Inc. Princeton University Princeton, USA Princeton, USA [email protected] {hanjunk, rarun, fengliu, august}@princeton.edu Abstract by the cluster is difficult. For these reasons, such programs have been deemed unsuitable for execution on clusters. While clusters of commodity servers and switches are the most popular form of large-scale parallel computers, many programs are Recent research has demonstrated that a combination of not easily parallelized for execution upon them. In particular, high pipeline parallelism (DSWP), thread-level speculation (TLS), inter-node communication cost and lack of globally shared memory and speculative pipeline parallelism (Spec-DSWP) can un- appear to make clusters suitable only for server applications with lock significant amounts of parallelism in general-purpose abundant task-level parallelism and scientific applications with regu- programs on shared memory systems [6, 24, 27, 29, 30, 32, lar and independent units of work. Clever use of pipeline parallelism (DSWP), thread-level speculation (TLS), and speculative pipeline 36, 37]. Pipeline parallelization techniques such as DSWP parallelism (Spec-DSWP) can mitigate the costs of inter-thread partition a loop in such a way that the critical path is executed communication on shared memory multicore machines. This paper in a thread-local fashion, with off-critical path data flowing presents Distributed Software Multi-threaded Transactional memory unidirectionally through the pipeline. The combination of these (DSMTX), a runtime system which makes these techniques applicable two factors makes the program execution highly insensitive to non-shared memory clusters, allowing them to efficiently address inter-node communication costs. -

Electronic Data Deliverables Reference Guide EPA Region 4
Electronic Data Deliverables Reference Guide Version 1.0 EPA Region 4 Prepared By: for Region 4 Superfund Division Environmental Protection Agency March 2010 DISCLAIMER OF ENDORSEMENT Reference herein to any specific commercial products, process, or service by trade name, trademark, manufacturer, or otherwise, does not necessarily constitute or imply its endorsement, recommendation, or favoring by the United States Government. The views and opinions of authors expressed herein do not necessarily state or reflect those of the United States Government, and shall not be used for advertising or product endorsement purposes. STATUS OF DOCUMENT As of March 2010, this document and all contents contained herein are considered DRAFT and are subject to revision and subsequent republication. Ecological EDD specifications do not appear in this guidance as they are currently under development, and will appear in future addenda. CONTACTS For questions and comments, contact: Your RPM or, DART Coordinator Superfund Division, 11th Floor East United States Environmental Protection Agency, Region 4 Sam Nunn Atlanta Federal Center 61 Forsyth Street, SW Atlanta, GA 30303-8960 (404) 562-8558 [email protected] Acronyms CAS RN – Chemical Abstracts Service Registry Number DART – Data Archival and ReTrieval EDD – Electronic Data Deliverable EDP – EQuIS Data Processor EPA – Environmental Protection Agency O&M – Operation and Maintenance SESD – Science and Ecosystem Support Division SRS – Substance Registry System CLP – Contract Laboratory Program PRP – Potentially Responsible Party Definitions Darter - Darter is a set of software utilities written by EPA that assist in moving data from other platforms such as FORMS, Niton, YSI and Scribe to the Region 4 EDD format. Data Provider – It is important to distinguish between “Data Provider” and “Sample Provider” with regard to EDD submittals. -

Symantec Web Security Service Policy Guide
Web Security Service Policy Guide Revision: NOV.07.2020 Symantec Web Security Service/Page 2 Policy Guide/Page 3 Copyrights Broadcom, the pulse logo, Connecting everything, and Symantec are among the trademarks of Broadcom. The term “Broadcom” refers to Broadcom Inc. and/or its subsidiaries. Copyright © 2020 Broadcom. All Rights Reserved. The term “Broadcom” refers to Broadcom Inc. and/or its subsidiaries. For more information, please visit www.broadcom.com. Broadcom reserves the right to make changes without further notice to any products or data herein to improve reliability, function, or design. Information furnished by Broadcom is believed to be accurate and reliable. However, Broadcom does not assume any liability arising out of the application or use of this information, nor the application or use of any product or circuit described herein, neither does it convey any license under its patent rights nor the rights of others. Policy Guide/Page 4 Symantec WSS Policy Guide The Symantec Web Security Service solutions provide real-time protection against web-borne threats. As a cloud-based product, the Web Security Service leverages Symantec's proven security technology, including the WebPulse™ cloud community. With extensive web application controls and detailed reporting features, IT administrators can use the Web Security Service to create and enforce granular policies that are applied to all covered users, including fixed locations and roaming users. If the WSS is the body, then the policy engine is the brain. While the WSS by default provides malware protection (blocks four categories: Phishing, Proxy Avoidance, Spyware Effects/Privacy Concerns, and Spyware/Malware Sources), the additional policy rules and options you create dictate exactly what content your employees can and cannot access—from global allows/denials to individual users at specific times from specific locations. -

Release Notes Micro Focus the Lawn 22-30 Old Bath Road Newbury, Berkshire RG14 1QN UK
Micro Focus Visual COBOL 2.3 for ISVs Release Notes Micro Focus The Lawn 22-30 Old Bath Road Newbury, Berkshire RG14 1QN UK http://www.microfocus.com Copyright © Micro Focus 2009-2015. All rights reserved. MICRO FOCUS, the Micro Focus logo and Visual COBOL are trademarks or registered trademarks of Micro Focus IP Development Limited or its subsidiaries or affiliated companies in the United States, United Kingdom and other countries. All other marks are the property of their respective owners. 2015-11-09 ii Contents Micro Focus Visual COBOL 2.3 for ISVs Release Notes .................................5 System Requirements ........................................................................................6 System Requirements for Visual COBOL for Visual Studio ................................................ 6 Hardware Requirements .......................................................................................... 6 Operating Systems Supported ................................................................................. 6 Software Requirements ............................................................................................6 System Requirements for Visual COBOL for Eclipse (Windows) ........................................8 Hardware Requirements .......................................................................................... 8 Operating Systems Supported ................................................................................. 8 Software requirements ............................................................................................ -

Managing Many Files with Disk Archiver (DAR)
Intro Manual demos Function demos Summary Managing many files with Disk ARchiver (DAR) ALEX RAZOUMOV [email protected] WestGrid webinar - ZIP file with slides and functions http://bit.ly/2GGR9hX 2019-May-01 1 / 16 Intro Manual demos Function demos Summary To ask questions Websteam: email [email protected] Vidyo: use the GROUP CHAT to ask questions Please mute your microphone unless you have a question Feel free to ask questions via audio at any time WestGrid webinar - ZIP file with slides and functions http://bit.ly/2GGR9hX 2019-May-01 2 / 16 Intro Manual demos Function demos Summary Parallel file system limitations Lustre object storage servers (OSS) can get overloaded with lots of small requests I /home, /scratch, /project I Lustre is very different from your laptop’s HDD/SSD I a bad workflow will affect all other users on the system Avoid too many files, lots of small reads/writes I use quota command to see your current usage I maximum 5 × 105 files in /home, 106 in /scratch, 5 × 106 in /project (1) organize your code’s output (2) use TAR or another tool to pack files into archives and then delete the originals WestGrid webinar - ZIP file with slides and functions http://bit.ly/2GGR9hX 2019-May-01 3 / 16 Intro Manual demos Function demos Summary TAR limitations TAR is the most widely used archiving format on UNIX-like systems I first released in 1979 Each TAR archive is a sequence of files I each file inside contains: a header + some padding to reach a multiple of 512 bytes + file content I EOF padding (some zeroed blocks) at the end of the -

An Optimal Real-Time Controller for Vertical Plasma Stabilization N
1 An optimal real-time controller for vertical plasma stabilization N. Cruz, J.-M. Moret, S. Coda, B.P. Duval, H.B. Le, A.P. Rodrigues, C.A.F. Varandas, C.M.B.A. Correia and B. Gonc¸alves Abstract—Modern Tokamaks have evolved from the initial ax- presents important advantages since it allows the creation isymmetric circular plasma shape to an elongated axisymmetric of divertor plasmas, the increase of the plasma current and plasma shape that improves the energy confinement time and the density limit as well as providing plasma stability. However, triple product, which is a generally used figure of merit for the conditions needed for fusion reactor performance. However, the an elongated plasma is unstable due to the forces that pull elongated plasma cross section introduces a vertical instability the plasma column upward or downward. The result of these that demands a real-time feedback control loop to stabilize forces is a plasma configuration that tends to be pushed up or the plasma vertical position and velocity. At the Tokamak down depending on the initial displacement disturbance. For Configuration Variable (TCV) in-vessel poloidal field coils driven example, a small displacement downwards results in the lower by fast switching power supplies are used to stabilize highly elongated plasmas. TCV plasma experiments have used a PID poloidal field coils pulling the plasma down, with increased algorithm based controller to correct the plasma vertical position. strength as the plasma gets further from the equilibrium posi- In late 2013 experiments a new optimal real-time controller was tion. To compensate this instability, feedback controllers have tested improving the stability of the plasma.