Freebsd General Commands Manual BSDCPIO (1)
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Lossless Audio Codec Comparison
Contents Introduction 3 1 CD-audio test 4 1.1 CD's used . .4 1.2 Results all CD's together . .4 1.3 Interesting quirks . .7 1.3.1 Mono encoded as stereo (Dan Browns Angels and Demons) . .7 1.3.2 Compressibility . .9 1.4 Convergence of the results . 10 2 High-resolution audio 13 2.1 Nine Inch Nails' The Slip . 13 2.2 Howard Shore's soundtrack for The Lord of the Rings: The Return of the King . 16 2.3 Wasted bits . 18 3 Multichannel audio 20 3.1 Howard Shore's soundtrack for The Lord of the Rings: The Return of the King . 20 A Motivation for choosing these CDs 23 B Test setup 27 B.1 Scripting and graphing . 27 B.2 Codecs and parameters used . 27 B.3 MD5 checksumming . 28 C Revision history 30 Bibliography 31 2 Introduction While testing the efficiency of lossy codecs can be quite cumbersome (as results differ for each person), comparing lossless codecs is much easier. As the last well documented and comprehensive test available on the internet has been a few years ago, I thought it would be a good idea to update. Beside comparing with CD-audio (which is often done to assess codec performance) and spitting out a grand total, this comparison also looks at extremes that occurred during the test and takes a look at 'high-resolution audio' and multichannel/surround audio. While the comparison was made to update the comparison-page on the FLAC website, it aims to be fair and unbiased. -

Contrasting the Performance of Compression Algorithms on Genomic Data
Contrasting the Performance of Compression Algorithms on Genomic Data Cornel Constantinescu, IBM Research Almaden Outline of the Talk: • Introduction / Motivation • Data used in experiments • General purpose compressors comparison • Simple Improvements • Special purpose compression • Transparent compression – working on compressed data (prototype) • Parallelism / Multithreading • Conclusion Introduction / Motivation • Despite the large number of research papers and compression algorithms proposed for compressing genomic data generated by sequencing machines, by far the most commonly used compression algorithm in the industry for FASTQ data is gzip. • The main drawbacks of the proposed alternative special-purpose compression algorithms are: • slow speed of either compression or decompression or both, and also their • brittleness by making various limiting assumptions about the input FASTQ format (for example, the structure of the headers or fixed lengths of the records [1]) in order to further improve their specialized compression. 1. Ibrahim Numanagic, James K Bonfield, Faraz Hach, Jan Voges, Jorn Ostermann, Claudio Alberti, Marco Mattavelli, and S Cenk Sahinalp. Comparison of high-throughput sequencing data compression tools. Nature Methods, 13(12):1005–1008, October 2016. Fast and Efficient Compression of Next Generation Sequencing Data 2 2 General Purpose Compression of Genomic Data As stated earlier, gzip/zlib compression is the method of choice by the industry for FASTQ genomic data. FASTQ genomic data is a text-based format (ASCII readable text) for storing a biological sequence and the corresponding quality scores. Each sequence letter and quality score is encoded with a single ASCII character. FASTQ data is structured in four fields per record (a “read”). The first field is the SEQUENCE ID or the header of the read. -

NOAA Technical Report NOS NGS 60
NOAA Technical Report NOS NGS 60 NAD83 (NSR2007) National Readjustment Final Report Dale G. Pursell Mike Potterfield Rockville, MD August 2008 NOAA Technical Report NOS NGS 60 NAD 83(NSRS2007) National Readjustment Final Report Dale G. Pursell Mike Potterfield Silver Spring, MD August 2008 U.S. DEPARTMENT OF COMMERCE National Oceanic and Atmospheric Administration National Ocean Service Contents Overview ........................................................................................................................ 1 Part I. Background .................................................................................................... 5 1. North American Datum of 1983 (1986) .......................................................................... 5 2. High Accuracy Reference Networks (HARNs) .............................................................. 5 3. Continuously Operating Reference Stations (CORS) .................................................... 7 4. Federal Base Networks (FBNs) ...................................................................................... 8 5. National Readjustment .................................................................................................... 9 Part II. Data Inventory, Assessment and Input ....................................... 11 6. Preliminary GPS Project Analysis ................................................................................11 7. Master File .....................................................................................................................11 -

A Longitudinal and Cross-Dataset Study of Internet Latency and Path Stability
A Longitudinal and Cross-Dataset Study of Internet Latency and Path Stability Mosharaf Chowdhury Rachit Agarwal Vyas Sekar Ion Stoica Electrical Engineering and Computer Sciences University of California at Berkeley Technical Report No. UCB/EECS-2014-172 http://www.eecs.berkeley.edu/Pubs/TechRpts/2014/EECS-2014-172.html October 11, 2014 Copyright © 2014, by the author(s). All rights reserved. Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. To copy otherwise, to republish, to post on servers or to redistribute to lists, requires prior specific permission. A Longitudinal and Cross-Dataset Study of Internet Latency and Path Stability Mosharaf Chowdhury Rachit Agarwal Vyas Sekar Ion Stoica UC Berkeley UC Berkeley Carnegie Mellon University UC Berkeley ABSTRACT Even though our work does not provide new active mea- We present a retrospective and longitudinal study of Internet surement techniques or new datasets, we believe that there is value in this retrospective analysis on several fronts. First, it latency and path stability using three large-scale traceroute provides a historical and longitudinal perspective of Internet datasets collected over several years: Ark and iPlane from path properties that are surprisingly lacking in the measure- 2008 to 2013 and a proprietary CDN’s traceroute dataset spanning 2012 and 2013. Using these different “lenses”, we ment community today. Second, it can help us revisit and revisit classical properties of Internet paths such as end-to- reappraise classical assumptions about path latency and sta- end latency, stability, and of routing graph structure. -

Cluster-Based Delta Compression of a Collection of Files Department of Computer and Information Science
Cluster-Based Delta Compression of a Collection of Files Zan Ouyang Nasir Memon Torsten Suel Dimitre Trendafilov Department of Computer and Information Science Technical Report TR-CIS-2002-05 12/27/2002 Cluster-Based Delta Compression of a Collection of Files Zan Ouyang Nasir Memon Torsten Suel Dimitre Trendafilov CIS Department Polytechnic University Brooklyn, NY 11201 Abstract Delta compression techniques are commonly used to succinctly represent an updated ver- sion of a file with respect to an earlier one. In this paper, we study the use of delta compression in a somewhat different scenario, where we wish to compress a large collection of (more or less) related files by performing a sequence of pairwise delta compressions. The problem of finding an optimal delta encoding for a collection of files by taking pairwise deltas can be re- duced to the problem of computing a branching of maximum weight in a weighted directed graph, but this solution is inefficient and thus does not scale to larger file collections. This motivates us to propose a framework for cluster-based delta compression that uses text clus- tering techniques to prune the graph of possible pairwise delta encodings. To demonstrate the efficacy of our approach, we present experimental results on collections of web pages. Our experiments show that cluster-based delta compression of collections provides significant im- provements in compression ratio as compared to individually compressing each file or using tar+gzip, at a moderate cost in efficiency. A shorter version of this paper appears in the Proceedings of the 3rd International Con- ference on Web Information Systems Engineering (WISE), December 2002. -

Getting to Grips with Unix and the Linux Family
Getting to grips with Unix and the Linux family David Chiappini, Giulio Pasqualetti, Tommaso Redaelli Torino, International Conference of Physics Students August 10, 2017 According to the booklet At this end of this session, you can expect: • To have an overview of the history of computer science • To understand the general functioning and similarities of Unix-like systems • To be able to distinguish the features of different Linux distributions • To be able to use basic Linux commands • To know how to build your own operating system • To hack the NSA • To produce the worst software bug EVER According to the booklet update At this end of this session, you can expect: • To have an overview of the history of computer science • To understand the general functioning and similarities of Unix-like systems • To be able to distinguish the features of different Linux distributions • To be able to use basic Linux commands • To know how to build your own operating system • To hack the NSA • To produce the worst software bug EVER A first data analysis with the shell, sed & awk an interactive workshop 1 at the beginning, there was UNIX... 2 ...then there was GNU 3 getting hands dirty common commands wait till you see piping 4 regular expressions 5 sed 6 awk 7 challenge time What's UNIX • Bell Labs was a really cool place to be in the 60s-70s • UNIX was a OS developed by Bell labs • they used C, which was also developed there • UNIX became the de facto standard on how to make an OS UNIX Philosophy • Write programs that do one thing and do it well. -
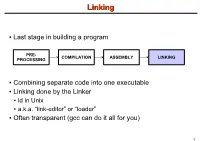
Linking + Libraries
LinkingLinking ● Last stage in building a program PRE- COMPILATION ASSEMBLY LINKING PROCESSING ● Combining separate code into one executable ● Linking done by the Linker ● ld in Unix ● a.k.a. “link-editor” or “loader” ● Often transparent (gcc can do it all for you) 1 LinkingLinking involves...involves... ● Combining several object modules (the .o files corresponding to .c files) into one file ● Resolving external references to variables and functions ● Producing an executable file (if no errors) file1.c file1.o file2.c gcc file2.o Linker Executable fileN.c fileN.o Header files External references 2 LinkingLinking withwith ExternalExternal ReferencesReferences file1.c file2.c int count; #include <stdio.h> void display(void); Compiler extern int count; int main(void) void display(void) { file1.o file2.o { count = 10; with placeholders printf(“%d”,count); display(); } return 0; Linker } ● file1.o has placeholder for display() ● file2.o has placeholder for count ● object modules are relocatable ● addresses are relative offsets from top of file 3 LibrariesLibraries ● Definition: ● a file containing functions that can be referenced externally by a C program ● Purpose: ● easy access to functions used repeatedly ● promote code modularity and re-use ● reduce source and executable file size 4 LibrariesLibraries ● Static (Archive) ● libname.a on Unix; name.lib on DOS/Windows ● Only modules with referenced code linked when compiling ● unlike .o files ● Linker copies function from library into executable file ● Update to library requires recompiling program 5 LibrariesLibraries ● Dynamic (Shared Object or Dynamic Link Library) ● libname.so on Unix; name.dll on DOS/Windows ● Referenced code not copied into executable ● Loaded in memory at run time ● Smaller executable size ● Can update library without recompiling program ● Drawback: slightly slower program startup 6 LibrariesLibraries ● Linking a static library libpepsi.a /* crave source file */ … gcc .. -

Dspic DSC Speex Speech Encoding/Decoding Library As a Development Tool to Emulate and Debug Firmware on a Target Board
dsPIC® DSC Speex Speech Encoding/Decoding Library User’s Guide © 2008-2011 Microchip Technology Inc. DS70328C Note the following details of the code protection feature on Microchip devices: • Microchip products meet the specification contained in their particular Microchip Data Sheet. • Microchip believes that its family of products is one of the most secure families of its kind on the market today, when used in the intended manner and under normal conditions. • There are dishonest and possibly illegal methods used to breach the code protection feature. All of these methods, to our knowledge, require using the Microchip products in a manner outside the operating specifications contained in Microchip’s Data Sheets. Most likely, the person doing so is engaged in theft of intellectual property. • Microchip is willing to work with the customer who is concerned about the integrity of their code. • Neither Microchip nor any other semiconductor manufacturer can guarantee the security of their code. Code protection does not mean that we are guaranteeing the product as “unbreakable.” Code protection is constantly evolving. We at Microchip are committed to continuously improving the code protection features of our products. Attempts to break Microchip’s code protection feature may be a violation of the Digital Millennium Copyright Act. If such acts allow unauthorized access to your software or other copyrighted work, you may have a right to sue for relief under that Act. Information contained in this publication regarding device Trademarks applications and the like is provided only for your convenience The Microchip name and logo, the Microchip logo, dsPIC, and may be superseded by updates. -

AR400 User Guide 2.7.1
AR400 SERIES User Guide Software Release 2.7.1 AR410 AR440S AR441S AR450S AR400 Series Router User Guide for Software Release 2.7.1 Document Number C613-02021-00 REV F. Copyright © 2004 Allied Telesyn International Corp. 19800 North Creek Parkway, Suite 200, Bothell, WA 98011, USA. All rights reserved. No part of this publication may be reproduced without prior written permission from Allied Telesyn. Allied Telesyn International Corp. reserves the right to make changes in specifications and other information contained in this document without prior written notice. The information provided herein is subject to change without notice. In no event shall Allied Telesyn be liable for any incidental, special, indirect, or consequential damages whatsoever, including but not limited to lost profits, arising out of or related to this manual or the information contained herein, even if Allied Telesyn has been advised of, known, or should have known, the possibility of such damages. All trademarks are the property of their respective owner. Contents CHAPTER 1 Introduction Why Read this User Guide? ............................................................................... 7 Where To Find More Information ...................................................................... 8 The Documentation Set .............................................................................. 8 Technical support .............................................................................................. 9 Features of the Router ..................................................................................... -

Pack, Encrypt, Authenticate Document Revision: 2021 05 02
PEA Pack, Encrypt, Authenticate Document revision: 2021 05 02 Author: Giorgio Tani Translation: Giorgio Tani This document refers to: PEA file format specification version 1 revision 3 (1.3); PEA file format specification version 2.0; PEA 1.01 executable implementation; Present documentation is released under GNU GFDL License. PEA executable implementation is released under GNU LGPL License; please note that all units provided by the Author are released under LGPL, while Wolfgang Ehrhardt’s crypto library units used in PEA are released under zlib/libpng License. PEA file format and PCOMPRESS specifications are hereby released under PUBLIC DOMAIN: the Author neither has, nor is aware of, any patents or pending patents relevant to this technology and do not intend to apply for any patents covering it. As far as the Author knows, PEA file format in all of it’s parts is free and unencumbered for all uses. Pea is on PeaZip project official site: https://peazip.github.io , https://peazip.org , and https://peazip.sourceforge.io For more information about the licenses: GNU GFDL License, see http://www.gnu.org/licenses/fdl.txt GNU LGPL License, see http://www.gnu.org/licenses/lgpl.txt 1 Content: Section 1: PEA file format ..3 Description ..3 PEA 1.3 file format details ..5 Differences between 1.3 and older revisions ..5 PEA 2.0 file format details ..7 PEA file format’s and implementation’s limitations ..8 PCOMPRESS compression scheme ..9 Algorithms used in PEA format ..9 PEA security model .10 Cryptanalysis of PEA format .12 Data recovery from -

GNU CPIO GNU Cpio 2.5 June 2002
GNU CPIO GNU cpio 2.5 June 2002 by Robert Carleton Copyright c 1995, 2001, 2002 Free Software Foundation, Inc. This is the first edition of the GNU cpio documentation, and is consistent with GNU cpio 2.5. Published by the Free Software Foundation 59 Temple Place - Suite 330, Boston, MA 02111-1307, USA Permission is granted to make and distribute verbatim copies of this manual provided the copyright notice and this permission notice are preserved on all copies. Permission is granted to copy and distribute modified versions of this manual under the con- ditions for verbatim copying, provided that the entire resulting derived work is distributed under the terms of a permission notice identical to this one. Permission is granted to copy and distribute translations of this manual into another lan- guage, under the above conditions for modified versions, except that this permission notice may be stated in a translation approved by the Free Software Foundation. Chapter 2: Tutorial 1 1 Introduction GNU cpio copies files into or out of a cpio or tar archive, The archive can be another file on the disk, a magnetic tape, or a pipe. GNU cpio supports the following archive formats: binary, old ASCII, new ASCII, crc, HPUX binary, HPUX old ASCII, old tar, and POSIX.1 tar. The tar format is provided for compatability with the tar program. By default, cpio creates binary format archives, for compatibility with older cpio programs. When extracting from archives, cpio automatically recognizes which kind of archive it is reading and can read archives created on machines with a different byte-order. -

Real Time Operating Systems Rootfs Creation: Summing Up
Real Time Operating Systems RootFS Creation: Summing Up Luca Abeni Real Time Operating Systems – p. System Boot System boot → the CPU starts executing from a well-known address ROM address: BIOS → read the first sector on the boot device, and executes it Bootloader (GRUB, LILO, U-Boot, . .) In general, load a kernel and an “intial ram disk” The initial fs image isn’t always needed (example: netboot) Kernel: from arm-test-*.tar.gz Initial filesystem? Loaded in RAM without the kernel help Generally contains the boot scripts and binaries Real Time Operating Systems – p. Initial Filesystem Old (2.4) kernels: Init Ram Disk (initrd); New (2.6) kernels: Init Ram Filesystem (initramfs) Generally used for modularized disk and FS drivers Example: if IDE drivers and Ext2 FS are modules (not inside the kernel), how can the kernel load them from disk? Solution: boot drivers can be on initrd / initramfs The bootloader loads it from disk with the kernel The kernel creates a “fake” fs based on it Modules are loaded from it Embedded systems can use initial FS for all the binaries Qemu does not need a bootloader to load kernel and initial FS (-kernel and -initrd) Real Time Operating Systems – p. Init Ram Filesystem Used in 2.6 kernels It is only a RAM FS: no real filesystem metadata on a storage medium All the files that must populate the FS are stored in a cpio package (similar to tar or zip file) The bootloader loads the cpio file in ram At boot time, the kernel “uncompresses” it, creating the RAM FS, and populating it with the files contained in the archive The cpio archive can be created by using the cpio -o -H newc command (see man cpio) Full command line: find .