The Linux Command Line
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

CST8207 – Linux O/S I
Mounting a Filesystem Directory Structure Fstab Mount command CST8207 - Algonquin College 2 Chapter 12: page 467 - 496 CST8207 - Algonquin College 3 The mount utility connects filesystems to the Linux directory hierarchy. The mount point is a directory in the local filesystem where you can access mounted filesystem. This directory must exist before you can mount a filesystem. All filesystems visible on the system exist as a mounted filesystem someplace below the root (/) directory CST8207 - Algonquin College 4 can be mounted manually ◦ can be listed in /etc/fstab, but not necessary ◦ all mounting information supplied manually at command line by user or administrator can be mounted automatically on startup ◦ must be listed /etc/fstab, with all appropriate information and options required Every filesystem, drive, storage device is listed as a mounted filesystem associated to a directory someplace under the root (/) directory CST8207 - Algonquin College 5 CST8207 - Algonquin College 6 Benefits Scalable ◦ As new drives are added and new partitions are created, further filesystems can be mounted at various mount points as required. ◦ This means a Linux system does not need to worry about running out of disk space. Transparent ◦ No application would stop working if transferred to a different partition, because access to data is done via the mount point. ◦ Also transparent to user CST8207 - Algonquin College 7 All known filesystems volumes are typically listed in the /etc/fstab (static information about filesystem) file to help automate the mounting process If it is not listed in the /etc/fstab file, then all appropriate information about the filesystem needs to be listed manually at the command line. -

Analyzing Code for KDE/Qt && Other Open Source Software
Analyzing code for KDE/Qt && other open source software http://leetcode.cn/2016/11/analyzing-code-for-kde-qt-open-source-components.html Leslie Zhai 普华——操作系统整合解决方案专家 Senior Software Engineer iSOFT Infrastructure Software co., Ltd; KDE developer KDE-China.org && Leetcode.cn 1 WHY 目录 HOWTO Contents 2 3 REFERENCE Part1 WHY? VULNERABILITIES OPTIMIZATION WHY -VULNERABILITIES 普华——操作系统整合解决方案专家 WHY - OPTIMIZATION 普华——操作系统整合解决方案专家 Identifying potential bottlenecks; Detecting problems in memory management; Detecting problems in C/C++ via static/dynamic analyzer source code analysis tool; Analyzing the CPU usage of embedded applications and Linux desktop applications; Part 2 HOWTO Static Analyzer Sanitizer libFuzzer CFI Safe Stack HOWTO – static analyer for k3b v2.10.0 普华——操作系统整合解决方案专家 HOWTO - static analyzer for k3b v2.10.0 普华——操作系统整合解决方案专家 scan-build -k -v -V cmake .. -DCMAKE_INSTALL_PREFIX=/usr \ -DKDE_INSTALL_LIBDIR=lib \ -DKDE_INSTALL_LIBEXECDIR=lib \ -DKDE_INSTALL_USE_QT_SYS_PATHS=ON \ -DK3B_BUILD_API_DOCS=ON \ -DK3B_ENABLE_PERMISSION_HELPER=ON \ -DK3B_DEBUG=ON scan-build -k -v -V make HOWTO - static analyzer for k3b v2.10.0 普华——操作系统整合解决方案专家 HOWTO - static analyzer for k3b v2.10.0 普华——操作系统整合解决方案专家 HOWTO - static analyzer for k3b v2.10.0 普华——操作系统整合解决方案专家 Q_UNUSED(dialogOpen); HOWTO - static analyzer for k3b v2.10.0 普华——操作系统整合解决方案专家 HOWTO - static analyzer for k3b v2.10.0 普华——操作系统整合解决方案专家 HOWTO - static analyzer for k3b v2.10.0 普华——操作系统整合解决方案专家 http://clang-analyzer.llvm.org/annotations.html#custom_assertions HOWTO - static analyzer for -

Full Circle Magazine #63 1 Full Circle Magazine Is Neither Affiliated With, Nor Endorsed By, Canonical Ltd
Full Circle THE INDEPENDENT MAGAZINE FOR THE UBUNTU LINUX COMMUNITY WEB DEV ISSUE #63 - July 2012 LAMP & WEB DEVELOPMENT ) m o c . r k c i l F ( e u S : o t o h P RREEDDUUCCEE **BBUUNNTTUU BBOOOOTT TTIIMMEE WWIITTHH TTHHIISS IINN DDEEPPTTHH AARRTTIICCLLEE.. WWIITTHH GGRRAAPPHHSS!! full circle magazine #63 1 Full Circle Magazine is neither affiliated with, nor endorsed by, Canonical Ltd. contents ^ HowTo Full Circle Opinions THE INDEPENDENT MAGAZINE FOR THE UBUNTU LINUX COMMUNITY My Story p.39 Python - Part 34 p.07 Columns LibreOffice - Part 15 p.11 Command & Conquer p.05 Audio Flux p.52 My Opinion p.41 Amateur Astronomy - Pt1 p.14 Ask The New Guy p.26 Ubuntu Games p.54 Review p.44 Letters p.46 GIMP - Beanstalk Pt3 p.17 Linux Labs p.29 Q&A p.49 Inkscape - Part 2 p.19 Ubuntu Women p.53 Closing Windows p.36 Web Dev - Pt1 p.22 Graphics Web Dev The articles contained in this magazine are released under the Creative Commons Attribution-Share Alike 3.0 Unported license. This means you can adapt, copy, distribute and transmit the articles but only under the following conditions: you must attribute the work to the original author in some way (at least a name, email or URL) and to this magazine by name ('Full Circle Magazine') and the URL www.fullcirclemagazine.org (but not attribute the article(s) in any way that suggests that they endorse you or your use of the work). If you alter, transform, or build upon this work, you must distribute the resulting work under the same, similar or a compatible license. -

Making Linux Protection Mechanisms Egalitarian with Userfs
Making Linux Protection Mechanisms Egalitarian with UserFS Taesoo Kim and Nickolai Zeldovich MIT CSAIL ABSTRACT firewall rules, forcing applications to invent their own UserFS provides egalitarian OS protection mechanisms protection techniques like system call interposition [15], in Linux. UserFS allows any user—not just the system binary rewriting [30] or analysis [13, 45], or interposing administrator—to allocate Unix user IDs, to use chroot, on system accesses in a language runtime like Javascript. and to set up firewall rules in order to confine untrusted This paper presents the design of UserFS, a kernel code. One key idea in UserFS is representing user IDs as framework that allows any application to use traditional files in a /proc-like file system, thus allowing applica- OS protection mechanisms on a Unix system, and a proto- tions to manage user IDs like any other files, by setting type implementation of UserFS for Linux. UserFS makes permissions and passing file descriptors over Unix do- protection mechanisms egalitarian, so that any user—not main sockets. UserFS addresses several challenges in just the system administrator—can allocate new user IDs, making user IDs egalitarian, including accountability, re- set up firewall rules, and isolate processes using chroot. source allocation, persistence, and UID reuse. We have By using the operating system’s own protection mecha- ported several applications to take advantage of UserFS; nisms, applications can avoid race conditions and ambi- by changing just tens to hundreds of lines of code, we guities associated with system call interposition [14, 43], prevented attackers from exploiting application-level vul- can confine existing code without having to recompile or nerabilities, such as code injection or missing ACL checks rewrite it in a new language, and can enforce a coherent in a PHP-based wiki application. -

Sandboxing 2 Change Root: Chroot()
Sandboxing 2 Change Root: chroot() Oldest Unix isolation mechanism Make a process believe that some subtree is the entire file system File outside of this subtree simply don’t exist Sounds good, but. Sandboxing 2 2 / 47 Chroot Sandboxing 2 3 / 47 Limitations of Chroot Only root can invoke it. (Why?) Setting up minimum necessary environment can be painful The program to execute generally needs to live within the subtree, where it’s exposed Still vulnerable to root compromise Doesn’t protect network identity Sandboxing 2 4 / 47 Root versus Chroot Suppose an ordinary user could use chroot() Create a link to the sudo command Create /etc and /etc/passwd with a known root password Create links to any files you want to read or write Besides, root can escape from chroot() Sandboxing 2 5 / 47 Escaping Chroot What is the current directory? If it’s not under the chroot() tree, try chdir("../../..") Better escape: create device files On Unix, all (non-network) devices have filenames Even physical memory has a filename Create a physical memory device, open it, and change the kernel data structures to remove the restriction Create a disk device, and mount a file system on it. Then chroot() to the real root (On Unix systems, disks other than the root file system are “mounted” as a subtree somewhere) Sandboxing 2 6 / 47 Trying Chroot # mkdir /usr/sandbox /usr/sandbox/bin # cp /bin/sh /usr/sandbox/bin/sh # chroot /usr/sandbox /bin/sh chroot: /bin/sh: Exec format error # mkdir /usr/sandbox/libexec # cp /libexec/ld.elf_so /usr/sandbox/libexec # chroot /usr/sandbox -

Getting to Grips with Unix and the Linux Family
Getting to grips with Unix and the Linux family David Chiappini, Giulio Pasqualetti, Tommaso Redaelli Torino, International Conference of Physics Students August 10, 2017 According to the booklet At this end of this session, you can expect: • To have an overview of the history of computer science • To understand the general functioning and similarities of Unix-like systems • To be able to distinguish the features of different Linux distributions • To be able to use basic Linux commands • To know how to build your own operating system • To hack the NSA • To produce the worst software bug EVER According to the booklet update At this end of this session, you can expect: • To have an overview of the history of computer science • To understand the general functioning and similarities of Unix-like systems • To be able to distinguish the features of different Linux distributions • To be able to use basic Linux commands • To know how to build your own operating system • To hack the NSA • To produce the worst software bug EVER A first data analysis with the shell, sed & awk an interactive workshop 1 at the beginning, there was UNIX... 2 ...then there was GNU 3 getting hands dirty common commands wait till you see piping 4 regular expressions 5 sed 6 awk 7 challenge time What's UNIX • Bell Labs was a really cool place to be in the 60s-70s • UNIX was a OS developed by Bell labs • they used C, which was also developed there • UNIX became the de facto standard on how to make an OS UNIX Philosophy • Write programs that do one thing and do it well. -

Alias Manager 4
CHAPTER 4 Alias Manager 4 This chapter describes how your application can use the Alias Manager to establish and resolve alias records, which are data structures that describe file system objects (that is, files, directories, and volumes). You create an alias record to take a “fingerprint” of a file system object, usually a file, that you might need to locate again later. You can store the alias record, instead of a file system specification, and then let the Alias Manager find the file again when it’s needed. The Alias Manager contains algorithms for locating files that have been moved, renamed, copied, or restored from backup. Note The Alias Manager lets you manage alias records. It does not directly manipulate Finder aliases, which the user creates and manages through the Finder. The chapter “Finder Interface” in Inside Macintosh: Macintosh Toolbox Essentials describes Finder aliases and ways to accommodate them in your application. ◆ The Alias Manager is available only in system software version 7.0 or later. Use the Gestalt function, described in the chapter “Gestalt Manager” of Inside Macintosh: Operating System Utilities, to determine whether the Alias Manager is present. Read this chapter if you want your application to create and resolve alias records. You might store an alias record, for example, to identify a customized dictionary from within a word-processing document. When the user runs a spelling checker on the document, your application can ask the Alias Manager to resolve the record to find the correct dictionary. 4 To use this chapter, you should be familiar with the File Manager’s conventions for Alias Manager identifying files, directories, and volumes, as described in the chapter “Introduction to File Management” in this book. -
Linux Software Für Jeden Zweck Linux Days Dortmund 2017
Linux Software für jeden Zweck Linux Days Dortmund 2017 FOSS-AG Dortmund Vortragender: @draget (Michael Gajda) 25. Juni 2017 1 There’s an App a Package for that! 68829! (2016-12-01) wget http://packages.ubuntu.com/xenial/allpackages?format=txt.gz -q -O - | zcat | tail -n +6 | wc -l 2 Hinweis • Die hier vorgestellte Software ist eine persönliche Auswahl des Vortragenden • Vorschläge oder Fragen gewünscht! 3 GPL, Fuck Yeah! Fast jede hier vorgestellte Software ist: • kostenlos! • quelloffen! • aus Spaß am Entwickeln entstanden! 4 Mit Winows zu Linux WinSCP Dateiaustausch zwischen Windows und Linux • Wer Angst vor der Kommandozeile hat… • Unterstützt SFTP und SCP Praktisch um Dateien von Zuhause mit entfernten Server. URL: https://winscp.net/ 5 Putty Windows SSH • Wer Angst vor GUIs hat… • De facto Standard • Netzwerktunnel Bitte darauf achten den korrekte Installer herunterzuladen. Angriffs-Gefahr! URL: http://www.putty.org/ 6 Produktivität TeXstudio LaTeX Editor • Gute Autovervollständigung • Vorschau für Bilder und Dateien Ubuntu, Mint, etc. > apt install texstudio URL: http://www.texstudio.org/ 7 Brasero Das Gnome Brennprogramm • Benutzerfreundlich • CD/DVD/BR usw. • Integrierter Cover-Editor • Unterstütze Backends: cdrtools, cdrkit, growisofs und libburn. Ubuntu, Mint, etc. > apt install brasero URL: https://wiki.gnome.org/Apps/Brasero 8 K3B Das KDE Brennprogramm • KDE Burn Baby, Burn! • Umfangreicher als Brasero • Viele Funktionen • CD/DVD/BR usw. • Abbild-Verwaltung Ubuntu, Mint, etc. > apt install k3b URL: http://k3b.plainblack.com/ 9 VirtualBox Virtuelle PCs per Knopfdruck • Performante Emulation von kompletten PCs • Software ausprobieren • Betriebssysteme ausprobieren • Viren ausprobieren • Snapshots • Alternativen: qemu + libvirt/virt- manager, VMWare Workstation Ubuntu, Mint, etc. > apt install virtualbox-qt 10 URL: https://www.virtualbox.org/ Marble Virtueller Globus • Nicht hübsch, aber vielfältig • Zugriff auf OSM • Viele weitere Datenquellen • Routing Ubuntu, Mint, etc. -

File System, Files, and *Tab /Etc/Fstab
File system, files, and *tab File system files directories volumes, file systems mounting points local versus networked file systems 1 /etc/fstab Specifies what is to be mounted where and how fs_spec: describes block special device for remote filesystem to be mounted fs_file: describes the mount point fs_vfstype: describes the type of file system fs_mntops: describes the mount options associated with the filesystem 2 /etc/fstab cont. fs_freq: used by the dump command fs_passno: used by fsck to determine the order in which checks are done at boot time. Root file systems should be specified as 1, others should be 2. Value 0 means that file system does not need to be checked 3 /etc/fstab 4 from blocks to mounting points metadata inodes directories superblocks 5 mounting file systems mounting e.g., mount -a unmounting manually or during shutdown umount 6 /etc/mtab see what is mounted 7 Network File System Access file system (FS) over a network looks like a local file system to user e.g. mount user FS rather than duplicating it (which would be a disaster) Developed by Sun Microsystems (mid 80s) history for NFS: NFS, NFSv2, NFSv3, NFSv4 RFC 3530 (from 2003) take a look to see what these RFCs are like!) 8 Network File System How does this actually work? server needs to export the system client needs to mount the system server: /etc/exports file client: /etc/fstab file 9 Network File System Security concerns UID GID What problems could arise? 10 Network File System example from our raid system (what is a RAID again?) Example of exports file from -

Georgia Department of Revenue
Form MV-9W (Rev. 6-2015) Web and MV Manual Georgia Department of Revenue - Motor Vehicle Division Request for Manufacture of a Special Veteran License Plate ______________________________________________________________________________________ Purpose of this Form: This form is to be used to apply for a military license plate/tag. This form should not be used to record a change of ownership, change of address, or change of license plate classification. Required documentation: You must provide a legible copy of your service discharge (DD-214, DD-215, or for World War II veterans, a WD form) indicating your branch and term of service. If you are an active duty member, a copy of the approved documentation supporting your current membership in the respective reserve or National Guard unit is required. In the case of a retired reserve member from that unit, you must furnish approved documentation supporting the current retired membership status from that reserve unit. OWNER INFORMATION First Name Middle Initial Last Name Suffix Owners’ Full Legal Name: Mailing Address: City: State: Zip: Telephone Number: Owner(s)’ Full Legal Name: First Name Middle Initial Last Name Suffix If secondary Owner(s) are listed Mailing Address: City: State: Zip: Telephone Number: VEHICLE INFORMATION Passenger Vehicle Motorcycle Private Truck Vehicle Identification Number (VIN): Year: Make: Model: CAMPAIGN/TOUR of DUTY Branch of Service: SERVICE AWARD Branch of Service: LICENSE PLATES ______________________ LICENSE PLATES ______________________ World War I World -

Answers to Even- Numbered Exercises 5
Answers to Even- Numbered Exercises 5 from page 163 1. What does the shell ordinarily do while a command is executing? What should you do if you do not want to wait for a command to finish before running another command? 2. Using sort as a filter, rewrite the following sequence of commands: $ sort list > temp $ lpr temp $ rm temp $ cat list | sort | lpr 3. What is a PID number? Why are they useful when you run processes in the background? 4. Assume that the following files are in the working directory: $ ls intro notesb ref2 section1 section3 section4b notesa ref1 ref3 section2 section4a sentrev Give commands for each of the following, using wildcards to express filenames with as few characters as possible. 1 2 Chapter 5 Answers to Exercises a. List all files that begin with section. $ ls section* b. List the section1, section2, and section3 files only. $ ls section[1-3] c. List the intro file only. $ ls i* d. List the section1, section3, ref1, and ref3 files. $ ls *[13] 5. Refer to the documentation of utilities in Part III or the man pages to determine what commands will a. Output the number of lines in the standard input that contain the word a or A. b. Output only the names of the files in the working directory that contain the pattern $(. c. List the files in the working directory in their reverse alphabetical order. d. Send a list of files in the working directory to the printer, sorted by size. 6. Give a command to a. Redirect the standard output from a sort command into a file named phone_list. -
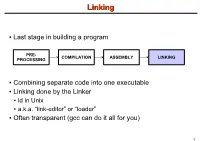
Linking + Libraries
LinkingLinking ● Last stage in building a program PRE- COMPILATION ASSEMBLY LINKING PROCESSING ● Combining separate code into one executable ● Linking done by the Linker ● ld in Unix ● a.k.a. “link-editor” or “loader” ● Often transparent (gcc can do it all for you) 1 LinkingLinking involves...involves... ● Combining several object modules (the .o files corresponding to .c files) into one file ● Resolving external references to variables and functions ● Producing an executable file (if no errors) file1.c file1.o file2.c gcc file2.o Linker Executable fileN.c fileN.o Header files External references 2 LinkingLinking withwith ExternalExternal ReferencesReferences file1.c file2.c int count; #include <stdio.h> void display(void); Compiler extern int count; int main(void) void display(void) { file1.o file2.o { count = 10; with placeholders printf(“%d”,count); display(); } return 0; Linker } ● file1.o has placeholder for display() ● file2.o has placeholder for count ● object modules are relocatable ● addresses are relative offsets from top of file 3 LibrariesLibraries ● Definition: ● a file containing functions that can be referenced externally by a C program ● Purpose: ● easy access to functions used repeatedly ● promote code modularity and re-use ● reduce source and executable file size 4 LibrariesLibraries ● Static (Archive) ● libname.a on Unix; name.lib on DOS/Windows ● Only modules with referenced code linked when compiling ● unlike .o files ● Linker copies function from library into executable file ● Update to library requires recompiling program 5 LibrariesLibraries ● Dynamic (Shared Object or Dynamic Link Library) ● libname.so on Unix; name.dll on DOS/Windows ● Referenced code not copied into executable ● Loaded in memory at run time ● Smaller executable size ● Can update library without recompiling program ● Drawback: slightly slower program startup 6 LibrariesLibraries ● Linking a static library libpepsi.a /* crave source file */ … gcc ..