Mastering the Game of Go with Deep Neural Networks and Tree Search
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
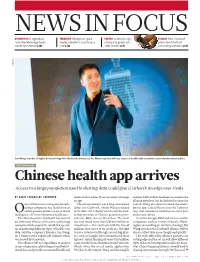
Chinese Health App Arrives Access to a Large Population Used to Sharing Data Could Give Icarbonx an Edge Over Rivals
NEWS IN FOCUS ASTROPHYSICS Legendary CHEMISTRY Deceptive spice POLITICS Scientists spy ECOLOGY New Zealand Arecibo telescope faces molecule offers cautionary chance to green UK plans to kill off all uncertain future p.143 tale p.144 after Brexit p.145 invasive predators p.148 ICARBONX Jun Wang, founder of digital biotechnology firm iCarbonX, showcases the Meum app that will use reams of health data to provide customized medical advice. BIOTECHNOLOGY Chinese health app arrives Access to a large population used to sharing data could give iCarbonX an edge over rivals. BY DAVID CYRANOSKI, SHENZHEN medical advice directly to consumers through another $400 million had been invested in the an app. alliance members, but he declined to name the ne of China’s most intriguing biotech- The announcement was a long-anticipated source. Wang also demonstrated the smart- nology companies has fleshed out an debut for iCarbonX, which Wang founded phone app, called Meum after the Latin for earlier quixotic promise to use artificial in October 2015 shortly after he left his lead- ‘my’, that customers would use to enter data Ointelligence (AI) to revolutionize health care. ership position at China’s genomics pow- and receive advice. The Shenzhen firm iCarbonX has formed erhouse, BGI, also in Shenzhen. The firm As well as Google, IBM and various smaller an ambitious alliance with seven technology has now raised more than US$600 million in companies, such as Arivale of Seattle, Wash- companies from around the world that special- investment — this contrasts with the tens of ington, are working on similar technology. But ize in gathering different types of health-care millions that most of its rivals are thought Wang says that the iCarbonX alliance will be data, said the company’s founder, Jun Wang, to have invested (although several big play- able to collect data more cheaply and quickly. -

Computer Go: from the Beginnings to Alphago Martin Müller, University of Alberta
Computer Go: from the Beginnings to AlphaGo Martin Müller, University of Alberta 2017 Outline of the Talk ✤ Game of Go ✤ Short history - Computer Go from the beginnings to AlphaGo ✤ The science behind AlphaGo ✤ The legacy of AlphaGo The Game of Go Go ✤ Classic two-player board game ✤ Invented in China thousands of years ago ✤ Simple rules, complex strategy ✤ Played by millions ✤ Hundreds of top experts - professional players ✤ Until 2016, computers weaker than humans Go Rules ✤ Start with empty board ✤ Place stone of your own color ✤ Goal: surround empty points or opponent - capture ✤ Win: control more than half the board Final score, 9x9 board ✤ Komi: first player advantage Measuring Go Strength ✤ People in Europe and America use the traditional Japanese ranking system ✤ Kyu (student) and Dan (master) levels ✤ Separate Dan ranks for professional players ✤ Kyu grades go down from 30 (absolute beginner) to 1 (best) ✤ Dan grades go up from 1 (weakest) to about 6 ✤ There is also a numerical (Elo) system, e.g. 2500 = 5 Dan Short History of Computer Go Computer Go History - Beginnings ✤ 1960’s: initial ideas, designs on paper ✤ 1970’s: first serious program - Reitman & Wilcox ✤ Interviews with strong human players ✤ Try to build a model of human decision-making ✤ Level: “advanced beginner”, 15-20 kyu ✤ One game costs thousands of dollars in computer time 1980-89 The Arrival of PC ✤ From 1980: PC (personal computers) arrive ✤ Many people get cheap access to computers ✤ Many start writing Go programs ✤ First competitions, Computer Olympiad, Ing Cup ✤ Level 10-15 kyu 1990-2005: Slow Progress ✤ Slow progress, commercial successes ✤ 1990 Ing Cup in Beijing ✤ 1993 Ing Cup in Chengdu ✤ Top programs Handtalk (Prof. -

(CMPUT) 455 Search, Knowledge, and Simulations
Computing Science (CMPUT) 455 Search, Knowledge, and Simulations James Wright Department of Computing Science University of Alberta [email protected] Winter 2021 1 455 Today - Lecture 22 • AlphaGo - overview and early versions • Coursework • Work on Assignment 4 • Reading: AlphaGo Zero paper 2 AlphaGo Introduction • High-level overview • History of DeepMind and AlphaGo • AlphaGo components and versions • Performance measurements • Games against humans • Impact, limitations, other applications, future 3 About DeepMind • Founded 2010 as a startup company • Bought by Google in 2014 • Based in London, UK, Edmonton (from 2017), Montreal, Paris • Expertise in Reinforcement Learning, deep learning and search 4 DeepMind and AlphaGo • A DeepMind team developed AlphaGo 2014-17 • Result: Massive advance in playing strength of Go programs • Before AlphaGo: programs about 3 levels below best humans • AlphaGo/Alpha Zero: far surpassed human skill in Go • Now: AlphaGo is retired • Now: Many other super-strong programs, including open source Image source: • https://www.nature.com All are based on AlphaGo, Alpha Zero ideas 5 DeepMind and UAlberta • UAlberta has deep connections • Faculty who work part-time or on leave at DeepMind • Rich Sutton, Michael Bowling, Patrick Pilarski, Csaba Szepesvari (all part time) • Many of our former students and postdocs work at DeepMind • David Silver - UofA PhD, designer of AlphaGo, lead of the DeepMind RL and AlphaGo teams • Aja Huang - UofA postdoc, main AlphaGo programmer • Many from the computer Poker group -

Human Vs. Computer Go: Review and Prospect
This article is accepted and will be published in IEEE Computational Intelligence Magazine in August 2016 Human vs. Computer Go: Review and Prospect Chang-Shing Lee*, Mei-Hui Wang Department of Computer Science and Information Engineering, National University of Tainan, TAIWAN Shi-Jim Yen Department of Computer Science and Information Engineering, National Dong Hwa University, TAIWAN Ting-Han Wei, I-Chen Wu Department of Computer Science, National Chiao Tung University, TAIWAN Ping-Chiang Chou, Chun-Hsun Chou Taiwan Go Association, TAIWAN Ming-Wan Wang Nihon Ki-in Go Institute, JAPAN Tai-Hsiung Yang Haifong Weiqi Academy, TAIWAN Abstract The Google DeepMind challenge match in March 2016 was a historic achievement for computer Go development. This article discusses the development of computational intelligence (CI) and its relative strength in comparison with human intelligence for the game of Go. We first summarize the milestones achieved for computer Go from 1998 to 2016. Then, the computer Go programs that have participated in previous IEEE CIS competitions as well as methods and techniques used in AlphaGo are briefly introduced. Commentaries from three high-level professional Go players on the five AlphaGo versus Lee Sedol games are also included. We conclude that AlphaGo beating Lee Sedol is a huge achievement in artificial intelligence (AI) based largely on CI methods. In the future, powerful computer Go programs such as AlphaGo are expected to be instrumental in promoting Go education and AI real-world applications. I. Computer Go Competitions The IEEE Computational Intelligence Society (CIS) has funded human vs. computer Go competitions in IEEE CIS flagship conferences since 2009. -

When Are We Done with Games?
When Are We Done with Games? Niels Justesen Michael S. Debus Sebastian Risi IT University of Copenhagen IT University of Copenhagen IT University of Copenhagen Copenhagen, Denmark Copenhagen, Denmark Copenhagen, Denmark [email protected] [email protected] [email protected] Abstract—From an early point, games have been promoted designed to erase particular elements of unfairness within the as important challenges within the research field of Artificial game, the players, or their environments. Intelligence (AI). Recent developments in machine learning have We take a black-box approach that ignores some dimensions allowed a few AI systems to win against top professionals in even the most challenging video games, including Dota 2 and of fairness such as learning speed and prior knowledge, StarCraft. It thus may seem that AI has now achieved all of focusing only on perceptual and motoric fairness. Additionally, the long-standing goals that were set forth by the research we introduce the notions of game extrinsic factors, such as the community. In this paper, we introduce a black box approach competition format and rules, and game intrinsic factors, such that provides a pragmatic way of evaluating the fairness of AI vs. as different mechanical systems and configurations within one human competitions, by only considering motoric and perceptual fairness on the competitors’ side. Additionally, we introduce the game. We apply these terms to critically review the aforemen- notion of extrinsic and intrinsic factors of a game competition and tioned AI achievements and observe that game extrinsic factors apply these to discuss and compare the competitions in relation are rarely discussed in this context, and that game intrinsic to human vs. -

Lee Sedol 9P+
The Match Leo Dorst The First Match (Nature, January 2016): AlphaGo vs Fan Hui 2p: 5-0! (played October 2015) Weaknesses of AlphaGo: pro view (about October 2015) • Too soft • Follows patterns, always mimicking • Does not understand concepts like value of sente • No understanding of complicated moves with delayed consequences Myungwan Kim 9p’s conclusion: needs lessons from humans! Lee Sedol 9p+ Guo Juan 5p Fan Hui 2p Dutch Champion 6d Leo Dorst 1k Figure from the Nature paper. AlphaGo in October (4p+?) Rank Beginner The Match: AlphaGo vs Lee Sedol 9p Lee Sedol 9p digitally meets Demis Hassabis CEO Lee Sedol 9p (+) • 33 years old, professional since 12-year old • Among top 5 in the world (now, still) • Invents new joseki moves in important games • Played one of history’s most original games (the ‘broken ladder’ game) sedol_laddergame.sgf • Very good reading skills, for a human • Can manage a game, and himself, very well • But: knew that there was 1M$ at stake • But: knew that he was playing a program (Dutch) Go Players’ Expectations 5-0 4-1 3-2 2-3 1-4 0-5 Source: Bob van den Hoek, http://deeplearningskysthelimit.blogspot.nl/ The Match: AlphaGo vs Lee Sedol Nice detail: Fan Hui was referee! Game 1 B: Lee Sedol W: AlphaGo Move 102 was dubbed ‘superhuman’ in the press Black resigns! Hassabis’ tweet after GAME 1 Lee Sedol: “I am in shock [but] I do not regret accepting this challenge. I failed in the opening… " Game 2 W: Lee Sedol B: AlphaGo Move 37 (a 5th line shoulder hit ) was ‘very surprising ’ White resigns! Game 3 Lee Sedol (B) resigns -

Go Champ Recalls Defeat at Hands of 'Calm' Computer 8 March 2016
Go champ recalls defeat at hands of 'calm' computer 8 March 2016 progress—it shows that a machine can execute a certain "intellectual" task better than the humans who created it Fan is being held to secrecy about AlphaGo's playing style and his expectations for the outcome of the match. But he did insinuate that Lee will have his work cut out for him if he wants to take home the $1-million (908,000-euro) prize money. "He will face a machine that is much stronger than the one that played against me," said the Chinese- born, Bordeaux-based Go teacher. Go is something of a Holy Grail for AI developers, as the ancient Chinese board game is arguably more complex The marathon match, to be played over five days, than chess is seen as a test of how far Artificial Intelligence (AI) has advanced. What makes AlphaGo special is that it is partly self- Last October, Fan Hui was beaten by a computer taught—playing millions of games against itself after at the ancient board game of Go that is not only his initial programming to hone its tactics through trial passion but also his life's work. and error. This week, the 35-year-old European champ will referee as his vanquisher, Google's AlphaGo programme, faces the world's human Number One in a battle for Go supremacy. "I was the first professional Go player to be beaten by a computer programme. It was hard," Fan told AFP ahead of AlphaGo's five-day duel against Go world champion Lee Se-dol. -

Mastering the Game of Go Without Human Knowledge
Mastering the Game of Go without Human Knowledge David Silver*, Julian Schrittwieser*, Karen Simonyan*, Ioannis Antonoglou, Aja Huang, Arthur Guez, Thomas Hubert, Lucas Baker, Matthew Lai, Adrian Bolton, Yutian Chen, Timothy Lillicrap, Fan Hui, Laurent Sifre, George van den Driessche, Thore Graepel, Demis Hassabis. DeepMind, 5 New Street Square, London EC4A 3TW. *These authors contributed equally to this work. A long-standing goal of artificial intelligence is an algorithm that learns, tabula rasa, su- perhuman proficiency in challenging domains. Recently, AlphaGo became the first program to defeat a world champion in the game of Go. The tree search in AlphaGo evaluated posi- tions and selected moves using deep neural networks. These neural networks were trained by supervised learning from human expert moves, and by reinforcement learning from self- play. Here, we introduce an algorithm based solely on reinforcement learning, without hu- man data, guidance, or domain knowledge beyond game rules. AlphaGo becomes its own teacher: a neural network is trained to predict AlphaGo’s own move selections and also the winner of AlphaGo’s games. This neural network improves the strength of tree search, re- sulting in higher quality move selection and stronger self-play in the next iteration. Starting tabula rasa, our new program AlphaGo Zero achieved superhuman performance, winning 100-0 against the previously published, champion-defeating AlphaGo. Much progress towards artificial intelligence has been made using supervised learning sys- tems that are trained to replicate the decisions of human experts 1–4. However, expert data is often expensive, unreliable, or simply unavailable. Even when reliable data is available it may impose a ceiling on the performance of systems trained in this manner 5. -

'Humanity-Packed' AI Prepares to Take on World Champion
NATURE | BLOG The Go Files: ‘Humanity-packed’ AI prepares to take on world champion Nature reports from a battle of man vs machine over the Go board. Tanguy Chouard 07 March 2016 The computer that mastered Go Nature Video Tanguy Chouard, an editor with Nature, saw Google-DeepMind’s AI system AlphaGo defeat a human professional for the first time last year at the ancient board game Go. This week, he is watching top professional Lee Sedol take on AlphaGo, in Seoul, for a $1 million prize. Welcome everyone. I’m Tanguy, an editor for the journal Nature in London. This week I will be in Tanguy Chouard Seoul to watch the AI matchup of the century so far: it’s computer versus human champion at the ancient Chinese board game Go. The AI algorithm AlphaGo will be taking on Lee Sedol, the most successful player of the past decade. The formidable complexity of Go has been considered a fundamental challenge for computer science, something that AI wouldn’t crack for another decade. Then last October, AlphaGo became the first machine to defeat a human professional at the game (without a handicap) – it thrashed European champion Fan Hui 5-0. As the Nature editor in charge of the peer-review process for the scientific paper1 that described the system and the feat, I was at that match, held behind closed doors at the London headquarters of DeepMind, Google’s AI company which built AlphaGo. It was one of the most gripping moments in my career. In a room upstairs, where the game was shown on a big screen, DeepMind’s engineering team were cheering for the machine, occasionally scribbling technical notes on white boards that lined the walls. -

Reinforcement Learning
Reinforcement Learning AlphaGo 的左右互搏 Tsung-Hsi Tsai 2018. 8. 8 統計研習營 1 絕藝如君天下少 , 閒⼈似我世間無 。 別後⽵窗⾵雪夜 , ⼀燈明暗覆吳圖 。 —— 杜牧 《 重送絕句 》 2 Overview I. Story of AlphaGo II. Algorithm of AlphaGo Zero III. Experiments of simple AlphaZero 3 Story of AlphaGo 4 To develop an AlphaGo Human experts technically games (oponal) ApproaCh: reinforcement learning + deep neural network Manpower: Compung programming power: CPUs + skill GPUs or TPUs 5 AlphaGo = 夢想 + 努⼒ + 時運 storytelling 6 Three key persons • Demis Hassabis (direcon) • David Silver (method) • Aja Huang (implement) Demis Hassabis (1976) • Age 13, chess master, No 2. • In 1993, designed classic game Theme Park, in 1998 to found Elixir Studios, games developer • 2009, PhD in Cognive Neuroscience • In 2010, founded DeepMind • In 2014, started AlphaGo project 8 David Silver • Demis Hassabis’ partner of game development in 1998 • Deep Q-Network (breakthrough on AGI arLficial general intelligence) show Atari game • Idea of Value Network (breakthrough on Go program) 9 Aja Huang • AlphaGo 的⼈⾁⼿臂 • 圍棋棋⼒業餘六段 • 2010 年 ,⿈⼠傑開發的圍棋程式 「 Erica」 得到 競賽冠軍 。 • 臺師⼤資⼯所 碩⼠論⽂為 《 電腦圍棋打劫的策略 》 2003 博⼠論⽂為 《 應⽤於電腦圍棋之蒙地卡羅樹搜尋 法的新啟發式演算法 》 2011 • Join DeepMind in 2012 10 The birth of AlphaGo • The DREAM started right aer DeepMind joined Google in 2014. • Research direcLon: deep learning and reinforcement learning. • First achievement: a high quality policy network to play Go, trained from big data of human expert games. • It beated No. 1 Go program CrazyStone with 70%. 11 A Cool idea • The most challenging part of Go program is to evaluate the situaon of board. • David Silver’s new idea: self-play using policy network to produce big data of games. -

Challenge Match Game 2: “Invention”
Challenge Match 8-15 March 2016 Game 2: “Invention” Commentary by Fan Hui Go expert analysis by Gu Li and Zhou Ruiyang Translated by Lucas Baker, Thomas Hubert, and Thore Graepel Invention AlphaGo's victory in the first game stunned the world. Many Go players, however, found the result very difficult to accept. Not only had Lee's play in the first game fallen short of his usual standards, but AlphaGo had not even needed to play any spectacular moves to win. Perhaps the first game was a fluke? Though they proclaimed it less stridently than before, the overwhelming majority of commentators were still betting on Lee to claim victory. Reporters arrived in much greater numbers that morning, and with the increased attention from the media, the pressure on Lee rose. After all, the match had begun with everyone expecting Lee to win either 50 or 41. I entered the playing room fifteen minutes before the game to find Demis Hassabis already present, looking much more relaxed than the day before. Four minutes before the starting time, Lee came in with his daughter. Perhaps he felt that she would bring him luck? As a father myself, I know that feeling well. By convention, the media is allowed a few minutes to take pictures at the start of a major game. The room was much fuller this time, another reflection of the increased focus on the match. Today, AlphaGo would take Black, and everyone was eager to see what opening it would choose. Whatever it played would represent what AlphaGo believed to be best for Black. -
Mastering the Game of Go with Deep Neural Networks and Tree Search
Mastering the Game of Go with Deep Neural Networks and Tree Search David Silver1*, Aja Huang1*, Chris J. Maddison1, Arthur Guez1, Laurent Sifre1, George van den Driessche1, Julian Schrittwieser1, Ioannis Antonoglou1, Veda Panneershelvam1, Marc Lanctot1, Sander Dieleman1, Dominik Grewe1, John Nham2, Nal Kalchbrenner1, Ilya Sutskever2, Timothy Lillicrap1, Madeleine Leach1, Koray Kavukcuoglu1, Thore Graepel1, Demis Hassabis1. 1 Google DeepMind, 5 New Street Square, London EC4A 3TW. 2 Google, 1600 Amphitheatre Parkway, Mountain View CA 94043. *These authors contributed equally to this work. Correspondence should be addressed to either David Silver ([email protected]) or Demis Hassabis ([email protected]). The game of Go has long been viewed as the most challenging of classic games for ar- tificial intelligence due to its enormous search space and the difficulty of evaluating board positions and moves. We introduce a new approach to computer Go that uses value networks to evaluate board positions and policy networks to select moves. These deep neural networks are trained by a novel combination of supervised learning from human expert games, and reinforcement learning from games of self-play. Without any lookahead search, the neural networks play Go at the level of state-of-the-art Monte-Carlo tree search programs that sim- ulate thousands of random games of self-play. We also introduce a new search algorithm that combines Monte-Carlo simulation with value and policy networks. Using this search al- gorithm, our program AlphaGo achieved a 99.8% winning rate against other Go programs, and defeated the European Go champion by 5 games to 0. This is the first time that a com- puter program has defeated a human professional player in the full-sized game of Go, a feat previously thought to be at least a decade away.