TTIC 31230, Fundamentals of Deep Learning David Mcallester, April 2017
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Game Changer
Matthew Sadler and Natasha Regan Game Changer AlphaZero’s Groundbreaking Chess Strategies and the Promise of AI New In Chess 2019 Contents Explanation of symbols 6 Foreword by Garry Kasparov �������������������������������������������������������������������������������� 7 Introduction by Demis Hassabis 11 Preface 16 Introduction ������������������������������������������������������������������������������������������������������������ 19 Part I AlphaZero’s history . 23 Chapter 1 A quick tour of computer chess competition 24 Chapter 2 ZeroZeroZero ������������������������������������������������������������������������������ 33 Chapter 3 Demis Hassabis, DeepMind and AI 54 Part II Inside the box . 67 Chapter 4 How AlphaZero thinks 68 Chapter 5 AlphaZero’s style – meeting in the middle 87 Part III Themes in AlphaZero’s play . 131 Chapter 6 Introduction to our selected AlphaZero themes 132 Chapter 7 Piece mobility: outposts 137 Chapter 8 Piece mobility: activity 168 Chapter 9 Attacking the king: the march of the rook’s pawn 208 Chapter 10 Attacking the king: colour complexes 235 Chapter 11 Attacking the king: sacrifices for time, space and damage 276 Chapter 12 Attacking the king: opposite-side castling 299 Chapter 13 Attacking the king: defence 321 Part IV AlphaZero’s -

Monte-Carlo Tree Search As Regularized Policy Optimization
Monte-Carlo tree search as regularized policy optimization Jean-Bastien Grill * 1 Florent Altche´ * 1 Yunhao Tang * 1 2 Thomas Hubert 3 Michal Valko 1 Ioannis Antonoglou 3 Remi´ Munos 1 Abstract AlphaZero employs an alternative handcrafted heuristic to achieve super-human performance on board games (Silver The combination of Monte-Carlo tree search et al., 2016). Recent MCTS-based MuZero (Schrittwieser (MCTS) with deep reinforcement learning has et al., 2019) has also led to state-of-the-art results in the led to significant advances in artificial intelli- Atari benchmarks (Bellemare et al., 2013). gence. However, AlphaZero, the current state- of-the-art MCTS algorithm, still relies on hand- Our main contribution is connecting MCTS algorithms, crafted heuristics that are only partially under- in particular the highly-successful AlphaZero, with MPO, stood. In this paper, we show that AlphaZero’s a state-of-the-art model-free policy-optimization algo- search heuristics, along with other common ones rithm (Abdolmaleki et al., 2018). Specifically, we show that such as UCT, are an approximation to the solu- the empirical visit distribution of actions in AlphaZero’s tion of a specific regularized policy optimization search procedure approximates the solution of a regularized problem. With this insight, we propose a variant policy-optimization objective. With this insight, our second of AlphaZero which uses the exact solution to contribution a modified version of AlphaZero that comes this policy optimization problem, and show exper- significant performance gains over the original algorithm, imentally that it reliably outperforms the original especially in cases where AlphaZero has been observed to algorithm in multiple domains. -
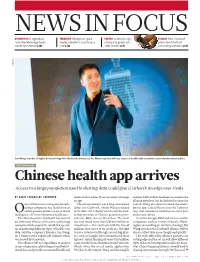
Chinese Health App Arrives Access to a Large Population Used to Sharing Data Could Give Icarbonx an Edge Over Rivals
NEWS IN FOCUS ASTROPHYSICS Legendary CHEMISTRY Deceptive spice POLITICS Scientists spy ECOLOGY New Zealand Arecibo telescope faces molecule offers cautionary chance to green UK plans to kill off all uncertain future p.143 tale p.144 after Brexit p.145 invasive predators p.148 ICARBONX Jun Wang, founder of digital biotechnology firm iCarbonX, showcases the Meum app that will use reams of health data to provide customized medical advice. BIOTECHNOLOGY Chinese health app arrives Access to a large population used to sharing data could give iCarbonX an edge over rivals. BY DAVID CYRANOSKI, SHENZHEN medical advice directly to consumers through another $400 million had been invested in the an app. alliance members, but he declined to name the ne of China’s most intriguing biotech- The announcement was a long-anticipated source. Wang also demonstrated the smart- nology companies has fleshed out an debut for iCarbonX, which Wang founded phone app, called Meum after the Latin for earlier quixotic promise to use artificial in October 2015 shortly after he left his lead- ‘my’, that customers would use to enter data Ointelligence (AI) to revolutionize health care. ership position at China’s genomics pow- and receive advice. The Shenzhen firm iCarbonX has formed erhouse, BGI, also in Shenzhen. The firm As well as Google, IBM and various smaller an ambitious alliance with seven technology has now raised more than US$600 million in companies, such as Arivale of Seattle, Wash- companies from around the world that special- investment — this contrasts with the tens of ington, are working on similar technology. But ize in gathering different types of health-care millions that most of its rivals are thought Wang says that the iCarbonX alliance will be data, said the company’s founder, Jun Wang, to have invested (although several big play- able to collect data more cheaply and quickly. -

Computer Go: from the Beginnings to Alphago Martin Müller, University of Alberta
Computer Go: from the Beginnings to AlphaGo Martin Müller, University of Alberta 2017 Outline of the Talk ✤ Game of Go ✤ Short history - Computer Go from the beginnings to AlphaGo ✤ The science behind AlphaGo ✤ The legacy of AlphaGo The Game of Go Go ✤ Classic two-player board game ✤ Invented in China thousands of years ago ✤ Simple rules, complex strategy ✤ Played by millions ✤ Hundreds of top experts - professional players ✤ Until 2016, computers weaker than humans Go Rules ✤ Start with empty board ✤ Place stone of your own color ✤ Goal: surround empty points or opponent - capture ✤ Win: control more than half the board Final score, 9x9 board ✤ Komi: first player advantage Measuring Go Strength ✤ People in Europe and America use the traditional Japanese ranking system ✤ Kyu (student) and Dan (master) levels ✤ Separate Dan ranks for professional players ✤ Kyu grades go down from 30 (absolute beginner) to 1 (best) ✤ Dan grades go up from 1 (weakest) to about 6 ✤ There is also a numerical (Elo) system, e.g. 2500 = 5 Dan Short History of Computer Go Computer Go History - Beginnings ✤ 1960’s: initial ideas, designs on paper ✤ 1970’s: first serious program - Reitman & Wilcox ✤ Interviews with strong human players ✤ Try to build a model of human decision-making ✤ Level: “advanced beginner”, 15-20 kyu ✤ One game costs thousands of dollars in computer time 1980-89 The Arrival of PC ✤ From 1980: PC (personal computers) arrive ✤ Many people get cheap access to computers ✤ Many start writing Go programs ✤ First competitions, Computer Olympiad, Ing Cup ✤ Level 10-15 kyu 1990-2005: Slow Progress ✤ Slow progress, commercial successes ✤ 1990 Ing Cup in Beijing ✤ 1993 Ing Cup in Chengdu ✤ Top programs Handtalk (Prof. -

Efficiently Mastering the Game of Nogo with Deep Reinforcement
electronics Article Efficiently Mastering the Game of NoGo with Deep Reinforcement Learning Supported by Domain Knowledge Yifan Gao 1,*,† and Lezhou Wu 2,† 1 College of Medicine and Biological Information Engineering, Northeastern University, Liaoning 110819, China 2 College of Information Science and Engineering, Northeastern University, Liaoning 110819, China; [email protected] * Correspondence: [email protected] † These authors contributed equally to this work. Abstract: Computer games have been regarded as an important field of artificial intelligence (AI) for a long time. The AlphaZero structure has been successful in the game of Go, beating the top professional human players and becoming the baseline method in computer games. However, the AlphaZero training process requires tremendous computing resources, imposing additional difficulties for the AlphaZero-based AI. In this paper, we propose NoGoZero+ to improve the AlphaZero process and apply it to a game similar to Go, NoGo. NoGoZero+ employs several innovative features to improve training speed and performance, and most improvement strategies can be transferred to other nonspecific areas. This paper compares it with the original AlphaZero process, and results show that NoGoZero+ increases the training speed to about six times that of the original AlphaZero process. Moreover, in the experiment, our agent beat the original AlphaZero agent with a score of 81:19 after only being trained by 20,000 self-play games’ data (small in quantity compared with Citation: Gao, Y.; Wu, L. Efficiently 120,000 self-play games’ data consumed by the original AlphaZero). The NoGo game program based Mastering the Game of NoGo with on NoGoZero+ was the runner-up in the 2020 China Computer Game Championship (CCGC) with Deep Reinforcement Learning limited resources, defeating many AlphaZero-based programs. -

ELF Opengo: an Analysis and Open Reimplementation of Alphazero
ELF OpenGo: An Analysis and Open Reimplementation of AlphaZero Yuandong Tian 1 Jerry Ma * 1 Qucheng Gong * 1 Shubho Sengupta * 1 Zhuoyuan Chen 1 James Pinkerton 1 C. Lawrence Zitnick 1 Abstract However, these advances in playing ability come at signifi- The AlphaGo, AlphaGo Zero, and AlphaZero cant computational expense. A single training run requires series of algorithms are remarkable demonstra- millions of selfplay games and days of training on thousands tions of deep reinforcement learning’s capabili- of TPUs, which is an unattainable level of compute for the ties, achieving superhuman performance in the majority of the research community. When combined with complex game of Go with progressively increas- the unavailability of code and models, the result is that the ing autonomy. However, many obstacles remain approach is very difficult, if not impossible, to reproduce, in the understanding of and usability of these study, improve upon, and extend. promising approaches by the research commu- In this paper, we propose ELF OpenGo, an open-source nity. Toward elucidating unresolved mysteries reimplementation of the AlphaZero (Silver et al., 2018) and facilitating future research, we propose ELF algorithm for the game of Go. We then apply ELF OpenGo OpenGo, an open-source reimplementation of the toward the following three additional contributions. AlphaZero algorithm. ELF OpenGo is the first open-source Go AI to convincingly demonstrate First, we train a superhuman model for ELF OpenGo. Af- superhuman performance with a perfect (20:0) ter running our AlphaZero-style training software on 2,000 record against global top professionals. We ap- GPUs for 9 days, our 20-block model has achieved super- ply ELF OpenGo to conduct extensive ablation human performance that is arguably comparable to the 20- studies, and to identify and analyze numerous in- block models described in Silver et al.(2017) and Silver teresting phenomena in both the model training et al.(2018). -

(CMPUT) 455 Search, Knowledge, and Simulations
Computing Science (CMPUT) 455 Search, Knowledge, and Simulations James Wright Department of Computing Science University of Alberta [email protected] Winter 2021 1 455 Today - Lecture 22 • AlphaGo - overview and early versions • Coursework • Work on Assignment 4 • Reading: AlphaGo Zero paper 2 AlphaGo Introduction • High-level overview • History of DeepMind and AlphaGo • AlphaGo components and versions • Performance measurements • Games against humans • Impact, limitations, other applications, future 3 About DeepMind • Founded 2010 as a startup company • Bought by Google in 2014 • Based in London, UK, Edmonton (from 2017), Montreal, Paris • Expertise in Reinforcement Learning, deep learning and search 4 DeepMind and AlphaGo • A DeepMind team developed AlphaGo 2014-17 • Result: Massive advance in playing strength of Go programs • Before AlphaGo: programs about 3 levels below best humans • AlphaGo/Alpha Zero: far surpassed human skill in Go • Now: AlphaGo is retired • Now: Many other super-strong programs, including open source Image source: • https://www.nature.com All are based on AlphaGo, Alpha Zero ideas 5 DeepMind and UAlberta • UAlberta has deep connections • Faculty who work part-time or on leave at DeepMind • Rich Sutton, Michael Bowling, Patrick Pilarski, Csaba Szepesvari (all part time) • Many of our former students and postdocs work at DeepMind • David Silver - UofA PhD, designer of AlphaGo, lead of the DeepMind RL and AlphaGo teams • Aja Huang - UofA postdoc, main AlphaGo programmer • Many from the computer Poker group -

Human Vs. Computer Go: Review and Prospect
This article is accepted and will be published in IEEE Computational Intelligence Magazine in August 2016 Human vs. Computer Go: Review and Prospect Chang-Shing Lee*, Mei-Hui Wang Department of Computer Science and Information Engineering, National University of Tainan, TAIWAN Shi-Jim Yen Department of Computer Science and Information Engineering, National Dong Hwa University, TAIWAN Ting-Han Wei, I-Chen Wu Department of Computer Science, National Chiao Tung University, TAIWAN Ping-Chiang Chou, Chun-Hsun Chou Taiwan Go Association, TAIWAN Ming-Wan Wang Nihon Ki-in Go Institute, JAPAN Tai-Hsiung Yang Haifong Weiqi Academy, TAIWAN Abstract The Google DeepMind challenge match in March 2016 was a historic achievement for computer Go development. This article discusses the development of computational intelligence (CI) and its relative strength in comparison with human intelligence for the game of Go. We first summarize the milestones achieved for computer Go from 1998 to 2016. Then, the computer Go programs that have participated in previous IEEE CIS competitions as well as methods and techniques used in AlphaGo are briefly introduced. Commentaries from three high-level professional Go players on the five AlphaGo versus Lee Sedol games are also included. We conclude that AlphaGo beating Lee Sedol is a huge achievement in artificial intelligence (AI) based largely on CI methods. In the future, powerful computer Go programs such as AlphaGo are expected to be instrumental in promoting Go education and AI real-world applications. I. Computer Go Competitions The IEEE Computational Intelligence Society (CIS) has funded human vs. computer Go competitions in IEEE CIS flagship conferences since 2009. -

When Are We Done with Games?
When Are We Done with Games? Niels Justesen Michael S. Debus Sebastian Risi IT University of Copenhagen IT University of Copenhagen IT University of Copenhagen Copenhagen, Denmark Copenhagen, Denmark Copenhagen, Denmark [email protected] [email protected] [email protected] Abstract—From an early point, games have been promoted designed to erase particular elements of unfairness within the as important challenges within the research field of Artificial game, the players, or their environments. Intelligence (AI). Recent developments in machine learning have We take a black-box approach that ignores some dimensions allowed a few AI systems to win against top professionals in even the most challenging video games, including Dota 2 and of fairness such as learning speed and prior knowledge, StarCraft. It thus may seem that AI has now achieved all of focusing only on perceptual and motoric fairness. Additionally, the long-standing goals that were set forth by the research we introduce the notions of game extrinsic factors, such as the community. In this paper, we introduce a black box approach competition format and rules, and game intrinsic factors, such that provides a pragmatic way of evaluating the fairness of AI vs. as different mechanical systems and configurations within one human competitions, by only considering motoric and perceptual fairness on the competitors’ side. Additionally, we introduce the game. We apply these terms to critically review the aforemen- notion of extrinsic and intrinsic factors of a game competition and tioned AI achievements and observe that game extrinsic factors apply these to discuss and compare the competitions in relation are rarely discussed in this context, and that game intrinsic to human vs. -

Alpha Zero Paper
RESEARCH COMPUTER SCIENCE programmers, combined with a high-performance alpha-beta search that expands a vast search tree by using a large number of clever heuristics and domain-specific adaptations. In (10) we describe A general reinforcement learning these augmentations, focusing on the 2016 Top Chess Engine Championship (TCEC) season 9 algorithm that masters chess, shogi, world champion Stockfish (11); other strong chess programs, including Deep Blue, use very similar and Go through self-play architectures (1, 12). In terms of game tree complexity, shogi is a substantially harder game than chess (13, 14): It David Silver1,2*†, Thomas Hubert1*, Julian Schrittwieser1*, Ioannis Antonoglou1, is played on a larger board with a wider variety of Matthew Lai1, Arthur Guez1, Marc Lanctot1, Laurent Sifre1, Dharshan Kumaran1, pieces; any captured opponent piece switches Thore Graepel1, Timothy Lillicrap1, Karen Simonyan1, Demis Hassabis1† sides and may subsequently be dropped anywhere on the board. The strongest shogi programs, such Thegameofchessisthelongest-studieddomainin the history of artificial intelligence. as the 2017 Computer Shogi Association (CSA) The strongest programs are based on a combination of sophisticated search techniques, world champion Elmo, have only recently de- domain-specific adaptations, and handcrafted evaluation functions that have been refined feated human champions (15). These programs by human experts over several decades. By contrast, the AlphaGo Zero program recently use an algorithm similar to those used by com- achieved superhuman performance in the game of Go by reinforcement learning from self-play. puter chess programs, again based on a highly In this paper, we generalize this approach into a single AlphaZero algorithm that can achieve Downloaded from optimized alpha-beta search engine with many superhuman performance in many challenging games. -

Introduction to Deep Reinforcement Learning
Parallel & Scalable Machine Learning Introduction to Machine Learning Algorithms Dr. Jenia Jitsev Head of Cross-Sectional Team Deep Learning (CST-DL) Scientific Lead Helmholtz AI Local (HAICU Local) Institute for Advanced Simulation (IAS) Juelich Supercomputing Center (JSC) @Jenia Jitsev LECTURE 9 Introduction to Deep Reinforcement Learning Feb 19th, 2020 JSC, Germany Machine Learning: Forms of Learning ● Supervised learning: correct responses Y for input data X are given; → Y “teacher” signal, correct “outcomes”, “labels” for the data X - usually : estimate unknown f: X→Y, y = f(x; W) - classical frameworks: classification, regression ● Unsupervised learning: only data X is given - find “hidden” structure, patterns in the data; - in general, estimate unknown probability density p(X) - in general : find a model that underlies / generates X - broad class of latent (“hidden”) variable models - classical frameworks: clustering, dimensionality reduction (e.g PCA) ● Reinforcement learning: data X, including (sparse) reward r(X) - discover actions a that maximize total future reward R t f a - active learning: experience X depends on choice of a h c s n i e - estimate p(a|X), p(r|X), V(X), Q(X,a) – future reward predictors m e G - z t l o h m l ● e H For all holds: r e d n i - Define a loss L(D,W), optimize by tuning free parameters W d e i l g t i M Deep Neural Networks: Forms of Learning ● Supervised learning: correct responses Y for input data X are given - find unknown f: y = f(x;W) or density p(Y|X;W) for data (x,y) - Deep CNN for visual object recognition (e.g, Inception, ResNet, ...) ● Unsupervised learning: only data X is given - general setting: estimate unknown density p(X;W) - find a model that underlies / generates X - broad class of latent (“hidden”) variable models - Variational Autoencoder (VAE), data generation and inference - Generative Adversarial Networks (GANs), data generation - Autoregressive models : PixelRNN, PixelCNN, .. -

Tackling Morpion Solitaire with Alphazero-Like Ranked Reward Reinforcement Learning
Tackling Morpion Solitaire with AlphaZero-like Ranked Reward Reinforcement Learning Hui Wang, Mike Preuss, Michael Emmerich and Aske Plaat Leiden Institute of Advanced Computer Science Leiden University The Netherlands email: [email protected] Abstract—Morpion Solitaire is a popular single player game, AlphaGo and AlphaZero combine deep neural networks [9] performed with paper and pencil. Due to its large state space and Monte Carlo Tree Search (MCTS) [10] in a self-play (on the order of the game of Go) traditional search algorithms, framework that learns by curriculum learning [11]. Unfor- such as MCTS, have not been able to find good solutions. A later algorithm, Nested Rollout Policy Adaptation, was able to find a tunately, these approaches can not be directly used to play new record of 82 steps, albeit with large computational resources. single agent combinatorial games, such as travelling salesman After achieving this record, to the best of our knowledge, there problems (TSP) [12] and bin package problems (BPP) [13], has been no further progress reported, for about a decade. where cost minimization is the goal of the game. To apply In this paper we take the recent impressive performance self-play for single player games, Laterre et al. proposed a of deep self-learning reinforcement learning approaches from AlphaGo/AlphaZero as inspiration to design a searcher for Ranked Reward (R2) algorithm. R2 creates a relative per- Morpion Solitaire. A challenge of Morpion Solitaire is that the formance metric by means of ranking the rewards obtained state space is sparse, there are few win/loss signals.