Machine Translation Kemal Oflazer 2 the Rosetta Stone
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Aviation Classics Magazine
Avro Vulcan B2 XH558 taxies towards the camera in impressive style with a haze of hot exhaust fumes trailing behind it. Luigino Caliaro Contents 6 Delta delight! 8 Vulcan – the Roman god of fire and destruction! 10 Delta Design 12 Delta Aerodynamics 20 Virtues of the Avro Vulcan 62 Virtues of the Avro Vulcan No.6 Nos.1 and 2 64 RAF Scampton – The Vulcan Years 22 The ‘Baby Vulcans’ 70 Delta over the Ocean 26 The True Delta Ladies 72 Rolling! 32 Fifty years of ’558 74 Inside the Vulcan 40 Virtues of the Avro Vulcan No.3 78 XM594 delivery diary 42 Vulcan display 86 National Cold War Exhibition 49 Virtues of the Avro Vulcan No.4 88 Virtues of the Avro Vulcan No.7 52 Virtues of the Avro Vulcan No.5 90 The Council Skip! 53 Skybolt 94 Vulcan Furnace 54 From wood and fabric to the V-bomber 98 Virtues of the Avro Vulcan No.8 4 aviationclassics.co.uk Left: Avro Vulcan B2 XH558 caught in some atmospheric lighting. Cover: XH558 banked to starboard above the clouds. Both John M Dibbs/Plane Picture Company Editor: Jarrod Cotter [email protected] Publisher: Dan Savage Contributors: Gary R Brown, Rick Coney, Luigino Caliaro, Martyn Chorlton, Juanita Franzi, Howard Heeley, Robert Owen, François Prins, JA ‘Robby’ Robinson, Clive Rowley. Designers: Charlotte Pearson, Justin Blackamore Reprographics: Michael Baumber Production manager: Craig Lamb [email protected] Divisional advertising manager: Tracey Glover-Brown [email protected] Advertising sales executive: Jamie Moulson [email protected] 01507 529465 Magazine sales manager: -

Report on the Progress of Civil Aviation 1939 – 1945
Report on the Progress of Civil Aviation 1939 – 1945 Prepared by John Wilson from contemporary documents in the library of the Civil Aviation Authority Foreword Page 1 Chapter I 1939: Civil Aviation after the outbreak of War Page 4 Chapter II Empire and Trans-Oceanic Services Page 9 Appendix B Details of Services Operated During the Period, set out year by year Page 68 Appendix C Regular Air Services in British Empire Countries other than the United Kingdom, set out year by year Page 140 Note that names of companies and places are copied as they were typed in the UK on a standard typewriter. Therefore no accented letters were available, and they have not been added into this transcript. Report on the Progress of Civil Aviation 1939 - 1945 Foreword by John Wilson When in the 1980s I was trying to unravel the exact story surrounding a PBY aircraft called "Guba" and its wartime career in carrying airmails to and from West Africa, I came across a voluminous report [Ref.1] in the Civil Aviation Authority (C.A.A.) Library which gave me the answers to most, if not all, of my questions, and enabled me to write a short booklet [Ref.2] on the vicissitudes of trying to keep an airmail service running in wartime conditions. The information contained in the report was so comprehensive that I was able to use it to answer questions raised by other researchers, both philatelic and aeronautic, but my response to requests for "a copy" of the full document had to be negative because I was well aware of the perils of copyright law as applied at the time, and also aware of the sheer cost of reproduction (I still have the original invoice for the photocopying charges levied by the C.A.A. -
B&W Real.Xlsx
NO REGN TYPE OWNER YEAR ‐‐‐‐‐‐ ‐‐‐‐‐‐‐‐‐‐ ‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐ ‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐ ‐‐‐‐‐‐‐‐‐‐‐‐‐‐ X00001 Albatros L‐68C X00002 Albatros L‐68D X00003 Albatros L‐69 X00004 Albatros L‐72C Hamburg Fremdenblatt X00005 Albatros L‐72C striped c/s X00006 D‐961 Albatros L‐73 Lufthansa X00007 Aviatik B.II German AF X00008 B.558/15 Aviatik B.II German AF X00009 Aviatik PG.20/2 X00010 C.1952 Aviatik C.I German AF X00011 Aviatik C.III German AF X00012 6306 Aviatik C.IX German AF X00013 Aviatik D.II nose view X00014 Aviatik D.III German AF X00015 Aviatik D.III nose view X00016 Aviatik D.VII German AF X00017 Aviatik D.VII nose view X00018 Arado J.1 X00019 D‐1707 Arado L.1 Ostseebad Warnemunde X00020 Arado L.II X00021 D‐1874 Arado L.II X00022 D‐817 Arado S.I DVL X00023 Arado S.IA nose view X00024 Arado S.I modified X00025 D‐1204 Arado SC.I X00026 D‐1192 Arado SC.I X00027 Arado SC.Ii X00028 Arado SC.II nose view X00029 D‐1984 Arado SC.II X00030 Arado SD.1 floatplane @ (poor) X00031 Arado SD.II X00032 Arado SD.III X00033 D‐1905 Arado SSD.I X00034 D‐1905 Arado SSD.I nose view X00035 Arado SSD.I on floats X00036 Arado V.I X00037 D‐1412 Arado W.2 X00038 D‐2994 Arado Ar.66 X00039 D‐IGAX Arado AR.66 Air to Air X00040 D‐IZOF Arado Ar.66C X00041 Arado Ar.68E Luftwaffe X00042 D‐ITEP Arado Ar.68E X00043 Arado Ar.68E nose view X00044 D‐IKIN Arado Ar.68F X00045 D‐2822 Arado Ar.69A X00046 D‐2827 Arado Ar.69B X00047 D‐EPYT Arado Ar.69B X00048 D‐IRAS Arado Ar.76 X00049 D‐ Arado Ar.77 @ X00050 D‐ Arado Ar.77 X00051 D‐EDCG Arado Ar.79 Air to Air X00052 D‐EHCR -

Primera Parte
Datos útiles para denuncias, contactos e inquietudes más frecuentes. DENUNCIA DE ACCIDENTES AEREOS Durante las 24 horas, todos los días, personalmente o por cualquier medio en : Av. Belgrano 1370 piso 11- Capital Federal (CP 1093AAQ). Telefax 011- 4381-6333. EMail: [email protected] o [email protected] De lunes a viernes de 08:00 a 19:00 Hs Telefax 011 4317- 6000 int. 16704 / 05 011 4382- 8890 / 91 DELEGACIONES CORDOBA (Córdoba) Aeropuerto Internacional lng Taravella Telefax: (0351) 4338139 RESISTENCIA (Chaco) Aeropuerto Internacional Resistencia Telefax (03722) 424199 – 461511 COMODORO RIVADAVIA (Chubut) Aeropuerto Internacional Gral. Mosconi Telefax (0297) 4467051 Oficinas MENDOZA (Mendoza) Aeropuerto Internacional Mendoza/El plumerillo Telefax: (0261) 44352415 - 44887483 BAHIA BLANCA (Buenos Aires) Aeropuerto Internacional Bahía Blanca Tel (0291) 486-0319 Telefax (0291) 4883576 Nuestros lectores hallarán en este boletín especial, un compendio de hechos, causas, motivos, factores y recomendaciones que analizadas, fueron punto de partida para tratar de establecer alguna norma de comportamiento en primer término y facilitar simultáneamente la búsqueda de un hecho en particular. Encontraran, también un análisis de las investigaciones más particulares realizadas durante los 50 años y las conclusiones a las que se arribó. Más adelante, algunos accidentes que por sus características o reincidencia, nos pareció necesario repetir su publicación en forma reducida. Como adelanto de los que se publicará en el 2005, se han incluido las primeras investigaciones resueltas en el año 2004, en idioma Castellano e Inglés. Luego están publicadas las estadísticas generalizadas, con comentarios al respecto, divididas en dos periodos 1954-1984 y 1985-2003, periodo este último en que se adopta definitivamente el formato y contenidos del Anexo 13 de OACI para su clasificación. -

Tue, Jun 6, 2017 Page: 1 BCAM# Title Author 820 "Air Force Spoken Here"
Date: Tue, Jun 6, 2017 BCAM Library Page: 1 BCAM# Title Author 820 "Air Force Spoken Here" Parton, James 800 "Alan in Wonderland" - NIGERIA and the Air Beetle Pr... Ludford, K.A. 471 "And I Was There" Layton, Edwin 458 "Certified Serviceable" Swordfish to Sea King Peter, Michael Charlton, Whitby 473 "Great Ingratitude" The Bomber Command in WW 2 Fyfe, James 840 "It's Really Quite Safe!" Rotherham, G.A. 457 "Nabob", the First Canadian Manned Aircraft Carrier Warrilow, Betty 840 "We Sat Alone" Diary of a Rear Gunner (booklet) Whitfield, Fred D.F.M. 457 'Til We Meet Again (2) McQuarrie, John 152 (Archive Box 10 09) Lockheed T33 10 Mk 3 Instruction... Canadair, Nothwest Industries 1967 152 (Archive Box 10 10) Lockheed T33 10 Mk3 Instruction ... Canadair, Northwest Industries 1967 152 (Archive Box 10 11) Lockheed T33A 08 Flight Manual IT-33A-1, 1963 USAF Flight manual 152 (Archive Box 10 12) Lockheed T33A Training Operating, 1962 RCAF Manual EO... 152 (Archive Box 10 13) North American F-86 Sabre 5, 5A ... Instructions, 1957 Pilots Operating 152 (Archive Box 10 14) North American F-86 Sabre 5, 5A ... Instructions, 1957 Pilots Operating 152 (Archive Box 15 16) Cessna Citation 500 Series Recurre... manual, 1982 Flight Safety Recurre... 152 (Archive Box 15 17) Beechcraft Expeditor 3 Aircraft Op... instructions, Beech Expeditor 3 RC... 152 (Archive Box 15 18) De Havilland DHC-2 Beaver Flight... manual, Flight 152 (Archive Box 15 19) Cessna Model 177 and Cardinal Manual, 1968 Owners 152 (Archive Box 15 20) North American F-86 Sabre VI instructions, 1958 Pilot operating 152 (Archive Box 15 21) Pilot's Manual for B-25 Mitchell TEST, USAAF 152 (Archive Box 15 23) Cessna 150 Aerobat Pilot's Operati.. -

The Aircraft Flown by 24 Squadron
The Aircraft Flown by 24 Squadron 24 Squadron RAF is currently the Operational Training Squadron for the Lockheed C130J Hercules, based at RAF Brize Norton in Oxfordshire. Apart from a short period as a cadre in 1919, they have been continuously operating for the RFC & RAF since 1915. They started off as a Scout (Fighter) Squadron, developed into a ground attack unit, became a communications specialist with a subsidiary training role, and in 1940 became a transport squadron. I have discovered records of 100 different types being allocated or used by the Squadron, some were trial aircraft used for a few days and others served for several years, and in the case of the Lockheed Hercules decades! In addition many different marks of the same type were operated, these include; 5 Marks of the Avro 504 1 civil and 4 Military marks of the Douglas DC3/ Dakota All 7 marks of the Lockheed Hudson used by the RAF 4 marks of the Lockheed Hercules 5 marks of the Bristol F2B fighter 3 Marks of the Vickers Wellington XXIV Squadron has operated aircraft designed by 39 separate concerns, built in Britain, Belgium, France, Germany, Holland, and the USA. The largest numbers from one maker/ designer are the Airco and De Havilland DH series totalling 22 types or marks, followed by 12 types or marks from Lockheed, and 11 from Avro. The total number of aircraft operated if split down into different marks comes to 137no from the Airspeed “Envoy” to the Wicko “Warferry” Earliest Days 24 Squadron was formed at Hounslow as an offshoot of 17 Squadron on the 1st September 1915 initially under the command of Capt A G Moore. -

Netletter #1389 | May 01, 2018 America West A320-321
NetLetter #1389 | May 01, 2018 America West A320-321 - Registration N622AW Welcome to the NetLetter, an Aviation based newsletter for Air Canada, TCA, CP Air, Canadian Airlines and all other Canadian based airlines that once graced the Canadian skies. The NetLetter is published on the second and fourth weekend of each month. If you are interested in Canadian Aviation History, and vintage aviation photos, especially as it relates to Trans-Canada Air Lines, Air Canada, Canadian Airlines International and their constituent airlines, then we're sure you'll enjoy this newsletter. Our website is located at www.thenetletter.net Please click the links below to visit our NetLetter Archives and for more info about the NetLetter. Coming Events The Canadian Aviation Historical Society (CAHS) will be holding its AGM from May 30 to June 3, 2018 in Calgary, Alberta. Below is a list of scheduled speakers. Speaker Topic Richard De Boer The Spartan Mosquito History to Date Jack McWilliam The Spartan Mosquito Restoration The Places, Planes, and Pilots of the Red Robert Galway Lake Gold Rush Carl Mills Canadian Fighter Pilots In The Korean War Jerry Vernon The Mystery of TCA Flight 3 Will Chabun RCAF Station Saskatoon Bill Cameron Fred McCall 403 Squadron City Of Calgary, an Jim Bell Overview James Winkel Saskatchewan Government Air Services Mark Cote That Lucky Old Son Air Defence Cooperation During the Cold Richard Goette War David Waechter Aeroballistic Testing Of The Avro Arrow Fred Petrie F/L Herb Briggs DFC Bill Zuk Finding Amelia: Amelia Earhart in Canada Allan Snowie The Vimy Flight Shirlee Smith To Be Announced Matheson Air Canada News Starting October 2018, Air Canada will whisk you away to fun in the sun on its new Boeing 737 MAX fleet. -
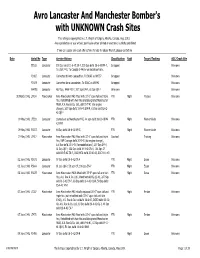
Lancaster and Manchester Bomber's with UNKNOWN Crash Sites
Avro Lancaster And Manchester Bomber's with UNKNOWN Crash Sites This listing is copyrighted by L.T. Wright of Calgary, Alberta, Canada, Aug. 2010. Any reproduction or use without permission either printed or electronic is strictly prohibited If you can supply any crash site lcations to help to reduce this list, please contact me Date Serial No Type Service History Classification Raid Target/Tasking SOC/Crash Site EE182 Lancaster 101 Sqn del'd 11-6-43 SR-?, 103 Sqn del'd 26-6-43 PM-?, Scrapped Unknown To USA 7-43, To Canada 1-44 for winterization trails. PD167 Lancaster Converted to Avro Lancastrian, To BOAC as VH737 Scrapped Unknown PD179 Lancaster Converted Avro Lancastrian, To BOAC as VH742 Scrapped Unknown W4798 Lancaster 467 Sqn, RAAF PO-?, 207 Sqn EM-?, 61 Sqn QR-? Unknown Unknown 30 March 1942 L7454 Manchester Avro Manchester MkI fitted with 33'-0" span tail and triple FTR Night Frisians Unknown fins, Retrofitted with twin fins and designated Manchester MkIA, A.V. Roe & Co. Ltd., del'd 5-7-41 (for engine change), 207 Sqn del'd 10-9-41 EM-M, 61 Sqn del'd 24-2- 42 QR-? 09 May 1942 L7533 Lancaster Started out as Manchester MkI, 44 Sqn del'd 28-12-41KM- FTR Night Warnemünde Unknown K, KM-J 09 May 1942 R5557 Lancaster 44 Sqn del'd 24-4-42 KM-G FTR Night Warnemünde Unknown 19 May 1942 L7417 Manchester Avro Manchester MkI fitted with 33'-0" span tail and triple Crashed Training Unknown fins, RAF Cranage del'd 20-5-41 (for engine change), A.V.Roe del'd 25-2-42 (for modifications), 207 Sqn EM-Y, 61 Sqn QR-?, 106 Sqn del'd 19-3-42 ZN-V, 106 Sqn CF del'd 19-5-42 ZN-?, 1660 HCU del'd 20-10-42, SOC 9-11-43 02 June 1942 R5571 Lancaster 97 Sqn del'd 15-5-42 OF-A FTR Night Essen Unknown 02 June 1942 R5844 Lancaster 61 Sqn QR-?, 50 Sqn CF, 106 Sqn ZN-? FTR Night Essen Unknown 06 June 1942 R5833 Manchester Avro Manchester MkIA fitted with 33'-0" span tail and twin FTR Night Gorse Unknown fins, A.V. -
Accidents to Transport Aircraft August 1944 to July 1950 Source Air Ministry "Gazetteer"
Accidents to Transport Aircraft August 1944 to July 1950 source Air Ministry "Gazetteer". Highlighted information not in the original. Red S indicates Secret Crew Pass. Date Reg Type Company Place Route K SI K SI 28/08/44 G-AGIR Dakota BOAC Rabat Port Etienne UK-Lagos 4 9 19/08/44 G-AGKP Mosquito BOAC UK-Stockholm 2 2 29/08/44 G-AGKR Mosquito BOAC UK-Stockholm 0 29/11/44 G-AGBW Lodestar BOAC missing Cairo-Gwelo- 4 7 Juba-Nairobi 21/11/44 G-AGCO Lodestar BOAC non flying G-ADTB Ensign BOAC 08/04/45 KJ992 Dakota BOAC El Adem UK-Cairo 0 0 0 0 01/11/45 G-AGNA Dakota BOAC Basra UK-Karachi 0 0 0 0 15/02/46 G-AGET Sunderland III BOAC Bally, Calcutta UK-Calcutta 0 0 0 0 21/02/46 AL528 Liberator II BOAC Charlottetown, PEI UK-Canada 1 09/03/46 JM722 Sunderland BOAC Rod-el-Farag 0 0 0 0 09/03/46 G-AEUI Short C Class BOAC Rod-el-Farag 0 0 0 0 23/03/46 G-AGLX Lancastrian BOAC near Cocos Islands UK-Australia 5 5 02/04/46 G-AGKX Sunderland BOAC Karachi 0 0 0 0 17/04/46 G-AGHK Dakota BOAC Lugo de Llanera, UK-W Africa 1 Aviedo, Spain 07/08/46 G-AGHS Dakota BOAC Eskhein, Norway UK-Norway 3 2 0 7 07/09/46 G-AHEW York BSAAC Yun Dum near UK-S America 4 20 Bathurst 01/04/46 G-AERZ Rapide Railway A S Belfast Liverpool- 2 4 Belfast 15/08/46 G-AGHT Dakota BOAC Malta Malta-Castel 1 Benito 21/08/46 G-AGMF Lancastrian BOAC St Aubin du Ternay India-UK 8 2 30/08/46 G-AGWJ York BSAAC 1 16/08/46 G-AGUE Avro XIX Railway A S Nr Liverpool Speke 1 2 Airport 19/12/46 G-AGZA Dakota Railway A S Northolt 11/01/47 G-AGJX Dakota BOAC Stowting, nr UK-W Africa 3 2 3 8 Folkestone -

Download the Index
The Aviation Historian® The modern journal of classic aeroplanes and the history of flying Issue Number is indicated by Air Force of Zimbabwe: 11 36–49 bold italic numerals Air France: 21 18, 21–23 “Air-itis”: 13 44–53 INDEX Air National Guard (USA): 9 38–49 Air racing: 7 62–71, 9 24–29 350lb Mystery, a: 5 106–107 Air Registration Board (ARB): 6 126–129 578 Sqn Association: 14 10 to Issues 1–36 Air Service Training Ltd: 29 40–46 748 into Africa: 23 88–98 Air-squall weapon: 18 38–39 1939: Was the RAF Ready for War?: Air traffic control: 21 124–129, 24 6 29 10–21 compiled by Airacobra: Hero of the Soviet Union: 1940: The Battle of . Kent?: 32 10–21 30 18–28 1957 Defence White Paper: 19 10–20, Airbus 20 10–19, 21 10–17 MICK OAKEY A300: 17 130, 28 10–19, back cover A320 series: 28 18, 34 71 A A400M Atlas: 23 7 À Paris avec les Soviets: 12 98–107 TAH Airbus Industrie: The early political ABC landscape — and an aerospace Robin: 1 72 “proto-Brexit”: 28 10–19 Abbott, Wg Cdr A.H., RAF: 29 44 Airco: see de Havilland Abell, Charles: 18 14 Aircraft carriers (see also Deck landing, Absolute Beginners: 28 80–90 Ships): 3 110–119, 4 10–15, 36–39, Acheson, Dean: 16 58 42–47, 5 70–77, 6 7–8, 118–119, Addams, Wg Cdr James R.W., RAF: Aeronca 7 24–37, 130, 10 52–55, 13 76–89, 26 10–21 Champion: 22 103–104 15 14, 112–119, 19 65–73, Adderley, Sqn Ldr The Hon Michael, RAF: Aeroplane & Armament Experimental 24 70–74, 29 54 34 75 Establishment (A&AEE): 8 20–27, Aircraft Industry Working Party (AIWP): Addison, Maj Syd, Australian Flying 11 107–109, 26 12–13, 122–129 -

Flight Magazine Scale Drawings, Art, Articles and Photos 28
Flight Magazine Scale Drawings, Art, Articles and Photos 28 September 2019 1909 – 1987 Compiled by davidterrell80 for RCGroups.com http://www.rcgroups.com/forums/showthread.php?t =2006237 A.B.C. Robin = http://www.flightglobal.com/pdfarchive/view/1929/1929%20‐%201110.html = http://www.flightglobal.com/pdfarchive/view/1929/1929‐1%20‐%200116.html A.B.C. Robin, Article = http://www.flightglobal.com/pdfarchive/view/1930/untitled0%20‐%200410.html = http://www.flightglobal.com/pdfarchive/view/1929/1929‐ 1%20‐%201636.html A.D.C. Nimbus Martinsyde F.4, Article = http://www.flightglobal.com/pdfarchive/view/1928/1928%20‐%200588.html A.N.E.C monoplane, Photo = http://www.flightglobal.com/pdfarchive/view/1936/1936%20‐%200895.html A.U.T. 18, Photo = http://www.flightglobal.com/pdfarchive/view/1940/1940%20‐%201041.html Aachen Glider = http://www.flightglobal.com/pdfarchive/view/1922/1922%20‐%200607.html Aachen monoplane Glider 1921 = http://www.flightglobal.com/pdfarchive/view/1922/1922%20‐%200591.html Abbott Baynes Cantilever Pou = http://www.flightglobal.com/pdfarchive/view/1936/1936%20‐%202836.html Abrams Explorer = http://www.flightglobal.com/pdfarchive/view/1938/1938%20‐%200098.html Abrams Explorer, Article = http://www.flightglobal.com/pdfarchive/view/1938/1938%20‐%202895.html Abrial A.2 Vautour = http://www.flightglobal.com/pdfarchive/view/1925/1925%20‐%200523.html AEG PE 1, Photo = http://www.flightglobal.com/pdfarchive/view/1957/1957%20‐%200662.html AEG Triplane, Photo = http://www.flightglobal.com/pdfarchive/view/1957/1957%20‐%200662.html -
INDEX to the CANADIAN AEROPHILATELIST - Quarterly Journal of the Canadian Aerophilatelic Society
INDEX to THE CANADIAN AEROPHILATELIST - Quarterly Journal of the Canadian Aerophilatelic Society - This Index catalogues the contents of The Canadian Aerophilatelist , quarterly publication of the Canadian Aerophilatelic Society, beginning with the July 1985 inaugural issue. All Journal articles linked to the collecting, researching and exhibiting interests of aerophilatelists and astrophilatelists are included in the Index, as well as aviation and philately articles of a more general nature. The only content exclusions are advertisements, notices, meeting announcements and the like. The Find function can be utilized to locate articles of interest by entering any relevant name, keyword, phrase or The Air Mails of Canada and Newfoundland catalogue number. For further information on use of the Index contact [email protected] . VOLUME I , NUMBER 1 [ July 1985 - Newsletter # 1 ] TITLES / CONTENTS # COVERS / SOURCES / DETAILS AMCN # PAGE # * List of Members’ Dick Malott / request for members to 1 Collecting Interests state their areas of collecting interest * PIPEX 85 Cover 1 cvr / photocopy of the souvenir cover 2 * ORAPEX 85 Report Kendall Sanford / CAS has 31 members, 2 - 3 details of the four aerophilatelic exhibits * Commemorative 1 cvr / Major E.H. Montgomery / copy CF-8401 3 - 4 D-Day Cover of CFB Comox commemorative cover * Report to FIP Commission Dick Malott / an update on air mail 4 - 5 on Aerophilately collecting in Canada, projects planned * Israphil 85 at Tel Aviv 2 cvrs / commemorative balloon covers 6 - 7 flown to Tiberius