Turing Tests in Natural Language Processing And
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

EDUKACJA MUZYCZNA W POLSCE DIAGNOZY, DEBATY, ASPIRACJE „Nek 2” — 15 Grudnia 2010 — Strona 2
„nek_2” — 15 grudnia 2010 — strona 1 EDUKACJA MUZYCZNA W POLSCE DIAGNOZY, DEBATY, ASPIRACJE „nek_2” — 15 grudnia 2010 — strona 2 SERIA WYDAWNICZA Nowa Edukacja Kulturalna. Diagnozy i kierunki zmian REDAKCJA SERII Andrzej Białkowski RECENZJA TOMU Urszula Bobryk FUNDACJA „MUZYKA JEST DLA WSZYSTKICH” ul. Angorska 21/2, 03–913 Warszawa http://www.muzykajest.pl „nek_2” — 15 grudnia 2010 — strona 3 Andrzej Białkowski Mirosław Grusiewicz Marcin Michalak Wybór tekstów Dorota Szwarcman EDUKACJA MUZYCZNA W POLSCE DIAGNOZY, DEBATY, ASPIRACJE FUNDACJA „MUZYKA JEST DLA WSZYSTKICH” WARSZAWA 2010 „nek_2” — 15 grudnia 2010 — strona 4 REDAKCJA Barbara G ˛asior PROJEKT OKŁADKI Artur Popek FOTOGRAFIA NA OKŁADCE Marcin Purchała SKŁAD I ŁAMANIE Artur Drozdowski DRUK Drukarnia „Tekst” S.J. ul. Wspólna 19, 20–344 Lublin Zrealizowano ze srodków´ Ministra Kultury i Dziedzictwa Narodowego we współpracy z Biurem Obchodów CHOPIN 2010 w ramach nurtu działan´ edu- kacyjnych w Roku Chopinowskim. Autorzy dedykuj ˛at˛eprac˛e200-leciu urodzin Fryderyka Chopina w nadziei, iz˙ rocznica stanie si˛ewaznym˙ impulsem dla dalszego rozwoju powszechnej edukacji muzycznej w Polsce. c FUNDACJA „MUZYKA JEST DLA WSZYSTKICH”, WARSZAWA 2010 Wszystkie prawa zastrzezone˙ ISBN: 978-83-931158-1-5 „nek_2” — 15 grudnia 2010 — strona 5 Spis tresci´ Wst˛ep............................................................ 7 Problemy i wyzwania edukacji muzycznej w Polsce . 11 Pakiety do nauczania muzyki w szkołach podstawowych i gimna- zjach ............................................................. 37 Muzyka popularna w teorii i praktyce polskiej edukacji muzycz- nej................................................................ 69 Wybór tekstów Dorota Szwarcman Edukacja muzyczna – dyskurs bez ko ´nca. 105 Rafał Ciesielski Slepy´ zaułek powszechnej edukacji muzycznej . 107 Andrzej Rakowski Powszechna edukacja muzyczna – historia narodowego niepowo- dzenia ............................................................ 119 Wojciech Jankowski Pi˛e´ctez przeciw deprecjacji muzyki w szkole . -

Sölulisti Áfengis 2002.Htm
Vara - Sölulisti áfengis Tímabil 01.01.02 - 31.12.02 Almenn sala, veitingasala, diplósala, risna Nr. Sala (magn) Eining Lítrar Alkóhóllítrar 01. Rauðvín 00001 Sérpöntun-rauðvín 4.073 fl. 2.557,2 325,8 Samtals 4.073 2.557,2 325,8 01.1 Rauðvín - stærri en 750 ml 00044 Mouton Cadet 10 fl. 15,0 1,8 00096 Jean-Claude Pepin Herault 16.557 Box 49.671,0 5.712,2 00097 Jean-Claude Pepin Herault 5.237 Box 26.185,0 3.011,3 00098 Le Cep Merlot 29.331 Box 87.993,0 11.228,1 00105 Vin de Pays de Vaucluse 2.223 Box 6.669,0 800,3 00107 Vin de Pays de Vaucluse 2.056 Box 10.280,0 1.233,6 00162 Pasqua Merlot delle Venezie 24.113 fl. 36.169,5 3.978,6 00165 Riunite Lambrusco 11.752 fl. 17.628,0 1.410,2 00190 Paul Masson Burgundy 4.434 fl. 6.651,0 831,4 03041 Bodegas Hijos de Alberto Gutierrez 2.519 Box 12.595,0 1.574,4 04019 Cotes du Luberon 191 Box 573,0 71,6 04120 Stowells Vin de Pays du Gard 1.669 Box 5.007,0 587,0 04121 Le Piat d'Or 233 fl. 233,0 28,0 04122 Cep Or Syrah Rouge 246 Box 738,0 92,3 04319 Ronco Vino da Tavola Rosso 123 Box 615,0 70,7 06607 Delicato Cabernet Sauvignon 41 fl. 61,5 8,0 06926 Barramundi Shiraz Merlot 6.865 Box 20.595,0 2.574,4 07052 Rene Barbier Tinto Anejo 842 Box 2.526,0 315,8 07154 Pasqua Cabernet Merlot Venezie 2.326 Box 6.978,0 837,4 07192 Fratelli Cei Chianti 1.218 fl. -

Montgomery County Department of Liquor Control
Montgomery County Department of Liquor Control September 2016 Newslink Montgomery County Department of Liquor Control Labor Day Holiday Schedule Monday, September 5, 2016 Administrative Offices, Ordering Section, Cashier’s, Communication Center and Licensing Offices will be closed Warehouse: All deliveries will be made as normal; there will be no receiving or pick-ups DLC Retail Stores will be open from 10 AM – 6 PM Ordering Deadline for Tuesday, September 6, 2016 Deliveries If a business has a Tuesday delivery, please note that all orders must be placed by Monday, September 5th at 5:30 AM due to the holiday. FREE Alcohol Law Education and Regulatory Training (ALERT) The Montgomery County Department of Liquor Control offers a free training designed to educate Montgomery County servers, sellers, management and owners on alcohol beverage regulatory compliance. Learn how to develop responsible alcohol policies, review issues identified by enforcement agencies and have an opportunity to meet for networking among peers and county officials. ALERT is FREE and offered twice a month (second and fourth Monday of every month) 10 AM - 1 PM 201 Edison Park Drive Gaithersburg, MD 20878 To register, email [email protected] This is not the state alcohol awareness class, this class compliments it Montgomery County Department of Liquor Control 201 Edison Park Drive, Gaithersburg, MD 20878 / 240-777-1900 / www.montgomerycountymd.gov/dlc For General County (Non-DLC) Information Call 311 / www.montgomerycountymd.gov/311 Montgomery County Department of Liquor Control Bulletin Board Alcohol Awareness Trainings: All alcoholic license establishments are required by law to have a state approved alcohol awareness certified person (licensee or person employed in a supervisory capacity) on the licensed premise during all hours in which alcoholic beverages are served. -

American Way Made in the USA, Domestic Vodka Celebrates Range and Diversity
MADE WITH MORE THAN 100% AGAVE Citrus trees grow throughout our Casa in Mexico, giving fresh citrus-y notes to our tequila during its 100% all-natural fermentation process. So you get an award-winning tequila that’s as great as the people you pour it for. Almost. VIBE TOGETHER ENJOY 100% RESPONSIBLY Alc. 40% by Vol. (80 Proof) Tequila Imported by Brown-Forman, KY ©2019 105709_eJ_TradePrint_8.5x11.indd 1 4/4/19 1:52 PM MAY 2019 ALABAMA Select Spirits PUBLISHED BY Dear Licensees: American Wine & Spirits, LLC MADE WITH PO Box 380832 Alabama is commemorating its 200th birthday this year! Beauty, history and I hope you are Birmingham, Al 35283 continuing to enjoy editions of American Wine and Spirits and are finding the information [email protected] beneficial to your business. The Board, our employees and I, realize that you are essential to our success and hope that our services and products are meeting your needs. We are very CREATIVE DIRECTOR happy to announce the launch of SANA, a new online ordering service for licensees. The new MORE THAN Pilar Taylor site is an intuitive and updated platform that offers many new options when ordering products. Some of the updates include: real-time inventory, running spend totals, easy product search, CONTRIBUTING WRITER auto saved orders, ordering directly from our wholesale warehouse and setting pick up dates. Norma Butterworth-McKittrick We have launched in two test markets and have enjoyed great success so far. Our 13-week launch schedule should provide for full access to all licensees by the printing of this price book. -

Z1. Z2 Bar Premium Internacional All Inclusive
Z1. Z2 BAR PREMIUM INTERNACIONAL ALL INCLUSIVE PREMIUM BAR INTERNACIONAL PARA HUESPEDES ALL INCLUSIVE APERITIVOS /APERITIF Martini extra seco, Martini rojo dulce, Campari, Doubonet rojo, Jerez Tío Pepe Extra dry Martini, red sweet martini, white sweet Martini, Campari, red Dubonet, Tio Pepe La barra en eventos privados tiene duración de 4 Sherry hrs. Los precios que se mencionan a continuación son por extensión de horario por hora por persona pesos 1er hora adicional $ 286 TEQUILA 2da hora adicional $ 247 Tequila Cuervo Especial, Tequila 100 Años reposado etiqueta azul, Jimador reposado, 3er hora adicional $ 208 Cazadores reposado, Herradura blanco, Herradura reposado, Herradura añejo, Agregar 16% IVA y 15% servicio Tequila 1800 añejo, Don Julio Blanco, Don Julio reposado, Don Julio Añejo Cuervo Precios por persona tradicional reposado, Cuervo 1800 Tequila Cuervo Especial, Tequila 100 Años white, Tequila 100 Años blue label settled, PREMIUM BAR FOR ALL INCLUSIVE GUESTS. Jimador white, Jimador settled, Cazadores settled, Herradura white, Herradura settled, In private events the bar if for 4 hours. The prices Herradura mature, Tequila 1800 mature, Don Julio white, Don Julio settled, Don Julio are for bar extension, per hour per person mature, Cuervo tradicional settled, Cuervo 1800 pesos 1st hour (additional) $286 2nd hour (additional) $247 RON / RUM 3rd. hour (additional) $208 Ron Bacardí blanco, Bacardí añejo, Ron Malibu, Ron Bacardi Solera, Appleton especial, Appleton state Appleton blanco, Havana Añejo, Capitán Morgan Add 16% tax and -

2017 Results 2018 Results
20172018 RESULTSRESULTS 100% Agave Tequila Silver/Blanco Genever Aquavit 100% Agave Tequila Reposado Flavored/Infused Gin Straight Bourbon Whiskey Aquavit 100% Agave Mezcal Cocktail Syrup & Cordial 100% Agave Tequila Anejo Absinthe (blanche/verte) Other Whiskey Gin Flavor/Infused Tequila Individual Bottle Design 100% Agave Tequila Extra Anejo Liqueur Flavored/Infused Whiskey Flavor/Infused Gin Rum Series Bottle Design 100% Agave Mezcal Silver/Blanco Pre-Mixed Cocktail (RTD) Individual Bottle Design Soju/Shochu/Baijiu Flavor/Infused Rum Flavored/Infused Tequila/Mezcal Other Miscellaneous Spirit Series Bottle Design BitterVodka MixerCognac Aperitivo/AperitifFlavor/Infused Vodka Syrup/CordialGrappa AmaroStraight Bourbon Whiskey GarnishEau-de-Vie/Fruit Brandy (non-calvados) VermouthFlavor/Infused Whiskey RumOther Brandy ArmagnacOther Whiskey Flavored/InfusedApertifs/Bitters Rum Cognac100% Agave Tequila Silver/Blanco Soju/ShochuLiqueur Brandy Vodka 100% Agave Tequila Reposado Pre-Mixed Cocktails (RTD) Consumers’ Choice Consumers’ Choice Other Brandy Flavored/Infused Vodka Awards 100% Agave Tequila Anejo Mixer` Awards Gin Other Vodka BACK TO CATEGORIES SIP AWARDS | 2018 SPIRIT RESULTS 100% AGAVE TEQUILA SILVER/ DOUBLE GOLD SILVER BLANCO Luxco Inc Suerte Tequila El Mayor Tequila Blanco Suerte Tequila Blanco BEST OF CLASS - PLATINUM www.luxco.com www.drinksuerte.com United States | 40.0% | $24.99 @suertetequila Destilería Casa de Piedra Mexico | 40.0% | $29.99 Tequila Terraneo Organico Juan More Time Tequila www.cobalto.destileriacasadepiedra.com Juan More Time Tequila Blanco - Artesanal & Heaven Hill Brands @organictequilas Organic Lunazul Tequila Blanco Mexico | 40.0% | $64.99 www.juanmoretimetequila.com www.heavenhill.com @juanmoretime_tequila United States | 40.0% | $19.99 Mexico | 40.0% | $49.00 PLATINUM Silver/Blanco Tequila 100% Agave Suave Spirits INternational LLC Lovely Rita Spirits Inc. -

Interpolar Transnational Art Science States
ART I N AN TA R C T I C A , A SE R I E S O F CO N F E R E N C E S … P. 4 @rt Outsiders September 2008 - 9th year www.art-outsiders.com Tel : +33 (0)1 44 78 75 00 Maison Européenne de la Photographie 5-7 rue de Fourcy – 75 004 Paris M° Saint-Paul ou Pont-Marie / Bus 67, 69, 96 ou 76 I N T E R P O L A R A RT 24 September 2008 - 12 October 2008 with Marko Peljhan and Annick Bureaud, Bureau d’études, Ewen Chardronnet, Andrea Polli, Catherine Rannou. The extreme in the centre by Annick Bure a u d rom the very first polar expeditions, artists have contributed to the imaginary surrounding the FEarth’s “extremities” and their work has fed a sense of the sublime and of romanticism. Such a romantic vision endures, fuelled by adventurers of the extreme, who set out crossing, alone, the antarctic continent, the touching (and a n t h ropomorphic) image of penguins, the deadly beauty of the environment conveyed by thousands of images of “icy white”, and by the fact that Antarctica is now threatened by global warming and our pollution, that this last huge, supposedly virg i n , territory is in danger. To create in or about Antarctica today is as much a political as an artistic act, just as it was in the 19th or early 20th century. Except today the continent faces quite a diff e r ent reality and our approaches are p r obably more varied, more contradictory, more complex; burdened with numerous clichés all the I-TASC - The Arctic Perspective more enduring for being mostly true. -

Preisliste Per 08.08.2012
1200 Wien, Taborstrasse 95, NW-Bahnhof, Tel: +43/1/925 28 05 Ladestrasse 1, Hangartner Fax: +43/1/715 83 97, 969 03 97 [email protected] Mobil: +43/676/325 28 05 www.getraenke-mueller.at Preisliste per 08.08.2012 Menge Artikelname Nettopreis Bruttopreis Alkoholfreie Getränke 0.2 lt. Afri Cola 24 x 0,2 lt 10,90 € 13,08 € 1 lt. Almdudler 12 x 1 lt MW 11,50 € 13,80 € 0.33 lt. Almdudler 24 x 0,33 lt MW 11,40 € 13,68 € 0.33 lt. Almdudler 24x0,33 lt Dose 10,90 € 13,08 € 2 lt. Almdudler 4x2 lt Pet EW 5,99 € 7,19 € 12er Karton Ananassaft Pfanner 1 lt 1,15 € 1,38 € 1 lt. Ananassaft Skipper 12 x 1 lt 12,50 € 15,00 € 1 lt. Apfelsaft Jeden Tag 100 % 12 x 1 lt 7,50 € 9,00 € 0.33 lt. Bitter Lemon FEVER TREE 24x0,33 lt 24,00 € 28,80 € 0.2 lt. Bitter Lemon Schweppes 24 x 0,2 lt EW 12,00 € 14,40 € 1.25 lt. Bitter Lemon Schweppes 6x1,25 lt 7,99 € 9,59 € 0.2 lt. Cappy Orange 24x0,2 lt MW 13,00 € 15,60 € 0.2 lt. Coca Cola 24 x 0,2 lt MW 9,90 € 11,88 € 2 lt. Coca Cola 4x2 lt EW 6,00 € 7,20 € 2 lt. Coca Cola 6 x 2 lt EW 9,00 € 10,80 € 0.33 lt. Coca Cola Classic MW 24x0,33 lt 11,50 € 13,80 € 0.2 lt. -

LIQUOR SERVICES SALES PRICE LIST UPDATED Feb 2017 ALL
LIQUOR SERVICES SALES PRICE LIST UPDATED Feb 2017 ALL ORDERS ARE SUBJECT TO: HST 15% ENVIRONMENTAL CHARGES $30 PROCESSING FEE ON ALL ORDERS SOME ITEMS LISTED BELOW ARE SPECIAL ORDER (*) AND REQUIRE 15 “WORKING” DAYS NOTICE PRICE SUBJECT TO CHANGE WITHOUT NOTICE LOCALLY BOTTLED PRODUCT 13299 Quidi Vidi Iceberg (12pk) $34.60 2412 Quidi Vidi 1892 (12pk) $25.40 5545 Quidi Vidi Premium (12pk) $23.90 14317 Quidi Vidi British IPA (12pk)* $27.05 8345 Quidi Vidi Eric’s (12pk)* $25.40 4184 Quidi Vidi Honey Brown (12pk)* $25.40 5543 Quidi Vidi Light (12pk)* $23.90 4671 Storm Irish Red (6pk)* $14.65 4670 Storm Island Gold Ale (6pk)* $14.65 12011 YellowBelly Wexford Wheat (750ml)* $5.70 12012 YellowBelly Fighting Irish Red (750ml)* $5.70 12013 YellowBelly Pale Ale (750ml)* $5.70 3932 NL Screech $27.55 11486 Ragged Rock Rum* $27.05 11500 George Street Spiced Rum* $28.50 1011 Old Sam Dark Rum* $27.55 8091 Shiver Vodka* $27.05 8223 Shiver Gin* $27.05 2113 Cabot Tower Rum* $31.95 8179 Crystal Head Vodka* $49.95 3793 Iceberg Vodka $27.55 6003 Iceberg Gin $27.55 11448 Iceberg Silver Rum* $27.55 6554 Iceberg Gold Rum* $27.55 1957 London Dock Dark Rum* $32.95 1618 Smugglers Cove Dark Rum* $27.05 DOMESTIC BEER Tin (24pk) $55.05 9602 Coors Light (8pk) $18.80 9601 Canadian Light (8pk) 9599 Black Horse (8pk) 9600 Canadian (8pk) 17482 India (8pk)* 6825 Keiths (8pk) $18.80 Keiths (24pk) $56.40 IMPORTED BEER 5554 Guiness Pub Draught (8pk) $24.15 4416 Cider (each)* $4.30 2816 Corona (12pk) $26.60 COOLERS 6747 Smirnoff Ice (12pk) $34.00 2153 Classic/Strawberry (each) -

1,00 L CACHACA 00011007
Artikelnummer Matchcode Artikelgruppe 00011014 Bossa Cachaca 40% - 0,70 l CACHACA 00011023 Cachaca 40% - 1,00 l CACHACA 00011007 Cachaca 51 40% - 0,70 l CACHACA 00011006 Cachaca 51 40% - 1,00 l CACHACA 00011009 Caicara Cachaca 38% - 1,00 l CACHACA 00011,00 Canario Cachaca 40% - 0,70 l CACHACA 00011001 Canario Cachaca 40% - 1,00 l CACHACA 00011008 Ceepers Cachaca 38% 1,00 CACHACA 00011005 Janeiro 40% 0,70 CACHACA 00011026 Leblon Cachaca 40% - 1,0 l CACHACA 00011025 Magnifica Cachaca 40% - 1,00 l CACHACA 00011003 Nega Fulo 41,5% - 1,00 l CACHACA 00011002 Nega Fulo 41,5% - 0,70 l CACHACA 00011024 Nega Fulo Epecial Aged Reserve 43% 0,70 CACHACA 00011010 Pitu Cachaca 40% 0,70 AKTION CACHACA 00011011 Pitu Cachaca 40% 1,00 CACHACA 00011012 Pitu de Ouro 40% 0,70 CACHACA 00011013 Pitu de Ouro 40% 1,00 CACHACA 00011017 Sagatiba Pura 38% Cachaca 1,00 CACHACA 00011022 Sagatiba Pura Cachaca 38% - 0,70 l CACHACA 00011018 Sagatiba Velha Cachaca 38% - 0,70 l CACHACA 00011015 Salvador Cachaca 40% 1,00 CACHACA 00011016 Thoquino Cachaca 40% - 1,00 CACHACA 00011019 Velho Barreiro Cachaca Gold 39% 0,70 CACHACA 00011021 Velho Barreiro Cachaca Gold 40% 1,00 CACHACA 00011020 Velho Barreiro Cachaca ORO 39% 0,70 CACHACA 00016200 Armand de Brignac Blancs de Blancs 12,5% - 0,705 L FRANZ. CHAMP. 00016201 Armand de Brignac Brut Gold 12,5% - 0,705 l FRANZ. CHAMP. 00016199 Armand de Brignac Rose 12,5% - 0,705 l FRANZ. CHAMP. 00017108 Bollinger Champagner 12 % - 0,70 l FRANZ. -
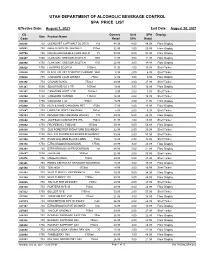
August 2021 SPA Product List
UTAH DEPARTMENT OF ALCOHOLIC BEVERAGE CONTROL SPA PRICE LIST Effective Date: August 1, 2021 End Date: August 28, 2021 CS Current Unit SPA Display Size Product Name Code Retail SPA Retail 005036 750 GLENLIVET 12YR MALT SCOTCH 750ml 48.99 4.00 44.99 Floor Display 005662 750 NAKED GROUSE WHISKEY 750ml 32.99 3.00 29.99 Floor Display 005700 750 MACALLAN DOUBLE CASK GOLD 750ml 59.99 5.00 54.99 Floor Display 006997 1000 CLAN MAC GREGOR SCOTCH 1000ml 14.99 3.00 11.99 Floor Display 006998 1750 CLAN MAC GREGOR SCOTCH 1750ml 22.99 3.00 19.99 Floor Display 008828 1750 LAUDERS SCOTCH 1750ml 21.99 2.00 19.99 Shelf Talker 010550 750 BLACK VELVET TOASTED CARAMEL WHSK 750ml 8.99 2.00 6.99 Shelf Talker 010626 750 CANADIAN CLUB WHISKY 750ml 12.99 3.00 9.99 Floor Display 011296 750 CROWN ROYAL 750ml 29.99 2.00 27.99 Shelf Talker 011347 1000 SEAGRAMS VO 6 YR 1000ml 19.99 3.00 16.99 Floor Display 012287 1000 CANADIAN HOST 3 YR 1000ml 9.95 2.00 7.95 Shelf Talker 012308 1750 CANADIAN HUNTER 1750ml 16.99 2.00 14.99 Shelf Talker 012408 1750 CANADIAN LTD 1750ml 15.95 4.00 11.95 Floor Display 012888 1750 RICH & RARE CANADIAN PET 1750ml 17.99 4.00 13.99 Floor Display 013647 750 LORD CALVERT CANADIAN 750ml 8.99 2.00 6.99 Shelf Talker 014199 1750 PENDLETON CANADIAN WHISKY 1750ml 49.99 5.00 44.99 Floor Display 015648 750 JAMESON CASKMATES IPA 750ml 31.99 2.00 29.99 Shelf Talker 015832 1750 PROPER NO. -

Drink Menu Classic Cocktails Top Shelf $10 / 1.5 Oz $12 / 2 Oz
Drink Menu Classic Cocktails Top Shelf $10 / 1.5 oz $12 / 2 oz Blue Hawaiian Old Fashioned Bacardi / Coconut Rum / Blue Curaçao / Pineapple Juice Woodford Reserve Bourbon / Angostura Bitters / Sugar Fuzzy Bunny Manhattan Cazadores Tequila / Blue Curaçao / Orange Juice / Bar Lime Collingwood Whiskey / Sweet Vermouth / Angostura Bitters Killer Kool-Aid Negroni Iceberg Vodka / Melon Liqueur / Amaretto / Cranberry Juice Bombay Gin / Campari / Sweet Vermouth Tornado Rusty Nail Iceberg Vodka / Sourpuss Apple / Sourpuss Raspberry / Scotch Whiskey / Drambuie Orange Juice / Sprite French Manhattan Zombie Woodford Reserve Bourbon / Chambord Black Raspberry Bacardi Rum / Gold Rum / Dark Rum / Coconut Rum / Apricot Liqueur / Sweet Vermouth / Angostura Bitters Brandy / Pineapple Juice / Sprite / Grenadine Bahama Mama Bacardi Rum / Coconut Rum / Banana Liqueur / Orange Juice / Pineapple Juice / Grenadine Tijuana Lady Martini’s Cazadores Tequila / Galliano / Lime Juice / Angostura Bitters $13 / 2 oz White Freezie Cosmopolitan Sourpuss Raspberry / Banana Liqueur / Sprite Iceberg Vodka. Triple Sec / Cranberry Juice Caribbean Spritzer Peach Kiss White Wine / Triple Sec / Pineapple Juice / Sprite Iceberg Vodka / Peach Schnapps / Orange Juice Pink Lemonade Fizz Lychee Martini Bombay Pink Gin / Sprite / Lemonade Iceberg Vodka / Lychee Liqueur / Cranberry Juice $12 / 2 oz Candy Apple Martini Iceberg Vodka / Sourpuss Apple / Long Island Iced Tea Butterscotch Schnapps / Bar Lime Iceberg Vodka / Bacardi Rum / Bombay Gin / Electric Popsicle Martini Triple Sec