FML-Based Prediction Agent and Its Application to Game of Go
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Residual Networks for Computer Go
IEEE TCIAIG 1 Residual Networks for Computer Go Tristan Cazenave Universite´ Paris-Dauphine, PSL Research University, CNRS, LAMSADE, 75016 PARIS, FRANCE Deep Learning for the game of Go recently had a tremendous success with the victory of AlphaGo against Lee Sedol in March 2016. We propose to use residual networks so as to improve the training of a policy network for computer Go. Training is faster than with usual convolutional networks and residual networks achieve high accuracy on our test set and a 4 dan level. Index Terms—Deep Learning, Computer Go, Residual Networks. I. INTRODUCTION Input EEP Learning for the game of Go with convolutional D neural networks has been addressed by Clark and Storkey [1]. It has been further improved by using larger networks [2]. Learning multiple moves in a row instead of only one Convolution move has also been shown to improve the playing strength of Go playing programs that choose moves according to a deep neural network [3]. Then came AlphaGo [4] that combines ReLU Monte Carlo Tree Search (MCTS) with a policy and a value network. Deep neural networks are good at recognizing shapes in the game of Go. However they have weaknesses at tactical search Output such as ladders and life and death. The way it is handled in AlphaGo is to give as input to the network the results of Fig. 1. The usual layer for computer Go. ladders. Reading ladders is not enough to understand more complex problems that require search. So AlphaGo combines deep networks with MCTS [5]. It learns a value network the last section concludes. -
![Arxiv:1701.07274V3 [Cs.LG] 15 Jul 2017](https://docslib.b-cdn.net/cover/8220/arxiv-1701-07274v3-cs-lg-15-jul-2017-78220.webp)
Arxiv:1701.07274V3 [Cs.LG] 15 Jul 2017
DEEP REINFORCEMENT LEARNING:AN OVERVIEW Yuxi Li ([email protected]) ABSTRACT We give an overview of recent exciting achievements of deep reinforcement learn- ing (RL). We discuss six core elements, six important mechanisms, and twelve applications. We start with background of machine learning, deep learning and reinforcement learning. Next we discuss core RL elements, including value func- tion, in particular, Deep Q-Network (DQN), policy, reward, model, planning, and exploration. After that, we discuss important mechanisms for RL, including atten- tion and memory, in particular, differentiable neural computer (DNC), unsuper- vised learning, transfer learning, semi-supervised learning, hierarchical RL, and learning to learn. Then we discuss various applications of RL, including games, in particular, AlphaGo, robotics, natural language processing, including dialogue systems (a.k.a. chatbots), machine translation, and text generation, computer vi- sion, neural architecture design, business management, finance, healthcare, Indus- try 4.0, smart grid, intelligent transportation systems, and computer systems. We mention topics not reviewed yet. After listing a collection of RL resources, we present a brief summary, and close with discussions. arXiv:1701.07274v3 [cs.LG] 15 Jul 2017 1 CONTENTS 1 Introduction5 2 Background6 2.1 Machine Learning . .7 2.2 Deep Learning . .8 2.3 Reinforcement Learning . .9 2.3.1 Problem Setup . .9 2.3.2 Value Function . .9 2.3.3 Temporal Difference Learning . .9 2.3.4 Multi-step Bootstrapping . 10 2.3.5 Function Approximation . 11 2.3.6 Policy Optimization . 12 2.3.7 Deep Reinforcement Learning . 12 2.3.8 RL Parlance . 13 2.3.9 Brief Summary . -

ELF: an Extensive, Lightweight and Flexible Research Platform for Real-Time Strategy Games
ELF: An Extensive, Lightweight and Flexible Research Platform for Real-time Strategy Games Yuandong Tian1 Qucheng Gong1 Wenling Shang2 Yuxin Wu1 C. Lawrence Zitnick1 1Facebook AI Research 2Oculus 1fyuandong, qucheng, yuxinwu, [email protected] [email protected] Abstract In this paper, we propose ELF, an Extensive, Lightweight and Flexible platform for fundamental reinforcement learning research. Using ELF, we implement a highly customizable real-time strategy (RTS) engine with three game environ- ments (Mini-RTS, Capture the Flag and Tower Defense). Mini-RTS, as a minia- ture version of StarCraft, captures key game dynamics and runs at 40K frame- per-second (FPS) per core on a laptop. When coupled with modern reinforcement learning methods, the system can train a full-game bot against built-in AIs end- to-end in one day with 6 CPUs and 1 GPU. In addition, our platform is flexible in terms of environment-agent communication topologies, choices of RL methods, changes in game parameters, and can host existing C/C++-based game environ- ments like ALE [4]. Using ELF, we thoroughly explore training parameters and show that a network with Leaky ReLU [17] and Batch Normalization [11] cou- pled with long-horizon training and progressive curriculum beats the rule-based built-in AI more than 70% of the time in the full game of Mini-RTS. Strong per- formance is also achieved on the other two games. In game replays, we show our agents learn interesting strategies. ELF, along with its RL platform, is open sourced at https://github.com/facebookresearch/ELF. 1 Introduction Game environments are commonly used for research in Reinforcement Learning (RL), i.e. -

Improved Policy Networks for Computer Go
Improved Policy Networks for Computer Go Tristan Cazenave Universite´ Paris-Dauphine, PSL Research University, CNRS, LAMSADE, PARIS, FRANCE Abstract. Golois uses residual policy networks to play Go. Two improvements to these residual policy networks are proposed and tested. The first one is to use three output planes. The second one is to add Spatial Batch Normalization. 1 Introduction Deep Learning for the game of Go with convolutional neural networks has been ad- dressed by [2]. It has been further improved using larger networks [7, 10]. AlphaGo [9] combines Monte Carlo Tree Search with a policy and a value network. Residual Networks improve the training of very deep networks [4]. These networks can gain accuracy from considerably increased depth. On the ImageNet dataset a 152 layers networks achieves 3.57% error. It won the 1st place on the ILSVRC 2015 classifi- cation task. The principle of residual nets is to add the input of the layer to the output of each layer. With this simple modification training is faster and enables deeper networks. Residual networks were recently successfully adapted to computer Go [1]. As a follow up to this paper, we propose improvements to residual networks for computer Go. The second section details different proposed improvements to policy networks for computer Go, the third section gives experimental results, and the last section con- cludes. 2 Proposed Improvements We propose two improvements for policy networks. The first improvement is to use multiple output planes as in DarkForest. The second improvement is to use Spatial Batch Normalization. 2.1 Multiple Output Planes In DarkForest [10] training with multiple output planes containing the next three moves to play has been shown to improve the level of play of a usual policy network with 13 layers. -
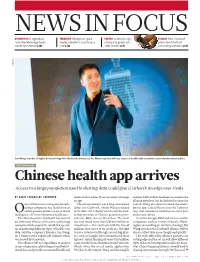
Chinese Health App Arrives Access to a Large Population Used to Sharing Data Could Give Icarbonx an Edge Over Rivals
NEWS IN FOCUS ASTROPHYSICS Legendary CHEMISTRY Deceptive spice POLITICS Scientists spy ECOLOGY New Zealand Arecibo telescope faces molecule offers cautionary chance to green UK plans to kill off all uncertain future p.143 tale p.144 after Brexit p.145 invasive predators p.148 ICARBONX Jun Wang, founder of digital biotechnology firm iCarbonX, showcases the Meum app that will use reams of health data to provide customized medical advice. BIOTECHNOLOGY Chinese health app arrives Access to a large population used to sharing data could give iCarbonX an edge over rivals. BY DAVID CYRANOSKI, SHENZHEN medical advice directly to consumers through another $400 million had been invested in the an app. alliance members, but he declined to name the ne of China’s most intriguing biotech- The announcement was a long-anticipated source. Wang also demonstrated the smart- nology companies has fleshed out an debut for iCarbonX, which Wang founded phone app, called Meum after the Latin for earlier quixotic promise to use artificial in October 2015 shortly after he left his lead- ‘my’, that customers would use to enter data Ointelligence (AI) to revolutionize health care. ership position at China’s genomics pow- and receive advice. The Shenzhen firm iCarbonX has formed erhouse, BGI, also in Shenzhen. The firm As well as Google, IBM and various smaller an ambitious alliance with seven technology has now raised more than US$600 million in companies, such as Arivale of Seattle, Wash- companies from around the world that special- investment — this contrasts with the tens of ington, are working on similar technology. But ize in gathering different types of health-care millions that most of its rivals are thought Wang says that the iCarbonX alliance will be data, said the company’s founder, Jun Wang, to have invested (although several big play- able to collect data more cheaply and quickly. -

Fml-Based Dynamic Assessment Agent for Human-Machine Cooperative System on Game of Go
Accepted for publication in International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems in July, 2017 FML-BASED DYNAMIC ASSESSMENT AGENT FOR HUMAN-MACHINE COOPERATIVE SYSTEM ON GAME OF GO CHANG-SHING LEE* MEI-HUI WANG, SHENG-CHI YANG Department of Computer Science and Information Engineering, National University of Tainan, Tainan, Taiwan *[email protected], [email protected], [email protected] PI-HSIA HUNG, SU-WEI LIN Department of Education, National University of Tainan, Tainan, Taiwan [email protected], [email protected] NAN SHUO, NAOYUKI KUBOTA Dept. of System Design, Tokyo Metropolitan University, Japan [email protected], [email protected] CHUN-HSUN CHOU, PING-CHIANG CHOU Haifong Weiqi Academy, Taiwan [email protected], [email protected] CHIA-HSIU KAO Department of Computer Science and Information Engineering, National University of Tainan, Tainan, Taiwan [email protected] Received (received date) Revised (revised date) Accepted (accepted date) In this paper, we demonstrate the application of Fuzzy Markup Language (FML) to construct an FML- based Dynamic Assessment Agent (FDAA), and we present an FML-based Human–Machine Cooperative System (FHMCS) for the game of Go. The proposed FDAA comprises an intelligent decision-making and learning mechanism, an intelligent game bot, a proximal development agent, and an intelligent agent. The intelligent game bot is based on the open-source code of Facebook’s Darkforest, and it features a representational state transfer application programming interface mechanism. The proximal development agent contains a dynamic assessment mechanism, a GoSocket mechanism, and an FML engine with a fuzzy knowledge base and rule base. -

Residual Networks for Computer Go Tristan Cazenave
Residual Networks for Computer Go Tristan Cazenave To cite this version: Tristan Cazenave. Residual Networks for Computer Go. IEEE Transactions on Games, Institute of Electrical and Electronics Engineers, 2018, 10 (1), 10.1109/TCIAIG.2017.2681042. hal-02098330 HAL Id: hal-02098330 https://hal.archives-ouvertes.fr/hal-02098330 Submitted on 12 Apr 2019 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. IEEE TCIAIG 1 Residual Networks for Computer Go Tristan Cazenave Universite´ Paris-Dauphine, PSL Research University, CNRS, LAMSADE, 75016 PARIS, FRANCE Deep Learning for the game of Go recently had a tremendous success with the victory of AlphaGo against Lee Sedol in March 2016. We propose to use residual networks so as to improve the training of a policy network for computer Go. Training is faster than with usual convolutional networks and residual networks achieve high accuracy on our test set and a 4 dan level. Index Terms—Deep Learning, Computer Go, Residual Networks. I. INTRODUCTION Input EEP Learning for the game of Go with convolutional D neural networks has been addressed by Clark and Storkey [1]. It has been further improved by using larger networks [2]. -

Spy on Me #2 – Artistic Manoevres for the Digital Present
Spy on Me Artistic Manoeuvres for the Digital Present #2 19. –29.3.2020 Spy on Me #2 – Artistic Manoeuvres for the Digital Present 19.–29.3.2020 / HAU1, HAU2, HAU3 We have arrived in the reality of digital transformation. Life with screens, apps and algorithms influences our behaviour, our atten - tion and desires. Meanwhile the idea of the public space and of democracy is being reorganized by digital means. The festival “Spy on Me” goes into its second round after 2018, searching for manoeuvres for the digital present together with Berlin-based and international artists. Performances, interactive spatial installati - ons and discursive events examine the complex effects of the digi - tal transformation of society. In theatre, where live encounters are the focus, we come close to the intermediate spaces of digital life, searching for ways out of feeling powerless and overwhelmed, as currently experienced by many users of internet-based technolo - gies. For it is not just in some future digital utopia, but here, in the midst of this present, that we have to deal with the basic conditi - ons of living together as a society and of planetary survival. Are we at the edge of a great digital darkness or at the decisive tur - ning point of perspective? A Festival by HAU Hebbel am Ufer. Funded by: Hauptstadtkulturfonds. What is our rela - tionship with alien conscious - nesses? As we build rivals to human intelligence, James Bridle looks at our relationship with the planet’s other alien consciousnesses. 5 On 27 June 1835, two masters of the ancient DeepBlue defeated Garry Kasparov at chess, prise, strangeness and even horror that Chinese game of Go faced off in a match up to that point a game with Go-like status as AlphaGo evokes will become a feature of more which was the culmination of a years-long a bastion of human imagination and mental and more areas of our lives. -

Move Prediction in Gomoku Using Deep Learning
VW<RXWK$FDGHPLF$QQXDO&RQIHUHQFHRI&KLQHVH$VVRFLDWLRQRI$XWRPDWLRQ :XKDQ&KLQD1RYHPEHU Move Prediction in Gomoku Using Deep Learning Kun Shao, Dongbin Zhao, Zhentao Tang, and Yuanheng Zhu The State Key Laboratory of Management and Control for Complex Systems, Institute of Automation, Chinese Academy of Sciences Beijing 100190, China Emails: [email protected]; [email protected]; [email protected]; [email protected] Abstract—The Gomoku board game is a longstanding chal- lenge for artificial intelligence research. With the development of deep learning, move prediction can help to promote the intelli- gence of board game agents as proven in AlphaGo. Following this idea, we train deep convolutional neural networks by supervised learning to predict the moves made by expert Gomoku players from RenjuNet dataset. We put forward a number of deep neural networks with different architectures and different hyper- parameters to solve this problem. With only the board state as the input, the proposed deep convolutional neural networks are able to recognize some special features of Gomoku and select the most likely next move. The final neural network achieves the accuracy of move prediction of about 42% on the RenjuNet dataset, which reaches the level of expert Gomoku players. In addition, it is promising to generate strong Gomoku agents of human-level with the move prediction as a guide. Keywords—Gomoku; move prediction; deep learning; deep convo- lutional network Fig. 1. Example of positions from a game of Gomoku after 58 moves have passed. It can be seen that the white win the game at last. I. -

ELF Opengo: an Analysis and Open Reimplementation of Alphazero
ELF OpenGo: An Analysis and Open Reimplementation of AlphaZero Yuandong Tian 1 Jerry Ma * 1 Qucheng Gong * 1 Shubho Sengupta * 1 Zhuoyuan Chen 1 James Pinkerton 1 C. Lawrence Zitnick 1 Abstract However, these advances in playing ability come at signifi- The AlphaGo, AlphaGo Zero, and AlphaZero cant computational expense. A single training run requires series of algorithms are remarkable demonstra- millions of selfplay games and days of training on thousands tions of deep reinforcement learning’s capabili- of TPUs, which is an unattainable level of compute for the ties, achieving superhuman performance in the majority of the research community. When combined with complex game of Go with progressively increas- the unavailability of code and models, the result is that the ing autonomy. However, many obstacles remain approach is very difficult, if not impossible, to reproduce, in the understanding of and usability of these study, improve upon, and extend. promising approaches by the research commu- In this paper, we propose ELF OpenGo, an open-source nity. Toward elucidating unresolved mysteries reimplementation of the AlphaZero (Silver et al., 2018) and facilitating future research, we propose ELF algorithm for the game of Go. We then apply ELF OpenGo OpenGo, an open-source reimplementation of the toward the following three additional contributions. AlphaZero algorithm. ELF OpenGo is the first open-source Go AI to convincingly demonstrate First, we train a superhuman model for ELF OpenGo. Af- superhuman performance with a perfect (20:0) ter running our AlphaZero-style training software on 2,000 record against global top professionals. We ap- GPUs for 9 days, our 20-block model has achieved super- ply ELF OpenGo to conduct extensive ablation human performance that is arguably comparable to the 20- studies, and to identify and analyze numerous in- block models described in Silver et al.(2017) and Silver teresting phenomena in both the model training et al.(2018). -

AI-FML Agent for Robotic Game of Go and Aiot Real-World Co-Learning Applications
AI-FML Agent for Robotic Game of Go and AIoT Real-World Co-Learning Applications Chang-Shing Lee, Yi-Lin Tsai, Mei-Hui Wang, Wen-Kai Kuan, Zong-Han Ciou Naoyuki Kubota Dept. of Computer Science and Information Engineering Dept. of Mechanical Sytems Engineering National University of Tainan Tokyo Metropolitan University Tainan, Tawain Tokyo, Japan [email protected] [email protected] Abstract—In this paper, we propose an AI-FML agent for IEEE CEC 2019 and FUZZ-IEEE 2019. The goal of the robotic game of Go and AIoT real-world co-learning applications. competition is to understand the basic concepts of an FML- The fuzzy machine learning mechanisms are adopted in the based fuzzy inference system, to use the FML intelligent proposed model, including fuzzy markup language (FML)-based decision tool to establish the knowledge base and rule base of genetic learning (GFML), eXtreme Gradient Boost (XGBoost), the fuzzy inference system, and to optimize the FML knowledge and a seven-layered deep fuzzy neural network (DFNN) with base and rule base through the methodologies of evolutionary backpropagation learning, to predict the win rate of the game of computation and machine learning [2]. Go as Black or White. This paper uses Google AlphaGo Master sixty games as the dataset to evaluate the performance of the fuzzy Machine learning has been a hot topic in research and machine learning, and the desired output dataset were predicted industry and new methodologies keep developing all the time. by Facebook AI Research (FAIR) ELF Open Go AI bot. In Regression, ensemble methods, and deep learning are important addition, we use IEEE 1855 standard for FML to describe the machine learning methods for data scientists [10]. -

When Are We Done with Games?
When Are We Done with Games? Niels Justesen Michael S. Debus Sebastian Risi IT University of Copenhagen IT University of Copenhagen IT University of Copenhagen Copenhagen, Denmark Copenhagen, Denmark Copenhagen, Denmark [email protected] [email protected] [email protected] Abstract—From an early point, games have been promoted designed to erase particular elements of unfairness within the as important challenges within the research field of Artificial game, the players, or their environments. Intelligence (AI). Recent developments in machine learning have We take a black-box approach that ignores some dimensions allowed a few AI systems to win against top professionals in even the most challenging video games, including Dota 2 and of fairness such as learning speed and prior knowledge, StarCraft. It thus may seem that AI has now achieved all of focusing only on perceptual and motoric fairness. Additionally, the long-standing goals that were set forth by the research we introduce the notions of game extrinsic factors, such as the community. In this paper, we introduce a black box approach competition format and rules, and game intrinsic factors, such that provides a pragmatic way of evaluating the fairness of AI vs. as different mechanical systems and configurations within one human competitions, by only considering motoric and perceptual fairness on the competitors’ side. Additionally, we introduce the game. We apply these terms to critically review the aforemen- notion of extrinsic and intrinsic factors of a game competition and tioned AI achievements and observe that game extrinsic factors apply these to discuss and compare the competitions in relation are rarely discussed in this context, and that game intrinsic to human vs.