About Go, the Ancient Game in Which AI Bested a Master 10 March 2016, by Youkyung Lee
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Elements of DSAI: Game Tree Search, Learning Architectures
Introduction Games Game Search Evaluation Fns AlphaGo/Zero Summary Quiz References Elements of DSAI AlphaGo Part 2: Game Tree Search, Learning Architectures Search & Learn: A Recipe for AI Action Decisions J¨orgHoffmann Winter Term 2019/20 Hoffmann Elements of DSAI Game Tree Search, Learning Architectures 1/49 Introduction Games Game Search Evaluation Fns AlphaGo/Zero Summary Quiz References Competitive Agents? Quote AI Introduction: \Single agent vs. multi-agent: One agent or several? Competitive or collaborative?" ! Single agent! Several koalas, several gorillas trying to beat these up. BUT there is only a single acting entity { one player decides which moves to take (who gets into the boat). Hoffmann Elements of DSAI Game Tree Search, Learning Architectures 3/49 Introduction Games Game Search Evaluation Fns AlphaGo/Zero Summary Quiz References Competitive Agents! Quote AI Introduction: \Single agent vs. multi-agent: One agent or several? Competitive or collaborative?" ! Multi-agent competitive! TWO players deciding which moves to take. Conflicting interests. Hoffmann Elements of DSAI Game Tree Search, Learning Architectures 4/49 Introduction Games Game Search Evaluation Fns AlphaGo/Zero Summary Quiz References Agenda: Game Search, AlphaGo Architecture Games: What is that? ! Game categories, game solutions. Game Search: How to solve a game? ! Searching the game tree. Evaluation Functions: How to evaluate a game position? ! Heuristic functions for games. AlphaGo: How does it work? ! Overview of AlphaGo architecture, and changes in Alpha(Go) Zero. Hoffmann Elements of DSAI Game Tree Search, Learning Architectures 5/49 Introduction Games Game Search Evaluation Fns AlphaGo/Zero Summary Quiz References Positioning in the DSAI Phase Model Hoffmann Elements of DSAI Game Tree Search, Learning Architectures 6/49 Introduction Games Game Search Evaluation Fns AlphaGo/Zero Summary Quiz References Which Games? ! No chance element. -

ELF: an Extensive, Lightweight and Flexible Research Platform for Real-Time Strategy Games
ELF: An Extensive, Lightweight and Flexible Research Platform for Real-time Strategy Games Yuandong Tian1 Qucheng Gong1 Wenling Shang2 Yuxin Wu1 C. Lawrence Zitnick1 1Facebook AI Research 2Oculus 1fyuandong, qucheng, yuxinwu, [email protected] [email protected] Abstract In this paper, we propose ELF, an Extensive, Lightweight and Flexible platform for fundamental reinforcement learning research. Using ELF, we implement a highly customizable real-time strategy (RTS) engine with three game environ- ments (Mini-RTS, Capture the Flag and Tower Defense). Mini-RTS, as a minia- ture version of StarCraft, captures key game dynamics and runs at 40K frame- per-second (FPS) per core on a laptop. When coupled with modern reinforcement learning methods, the system can train a full-game bot against built-in AIs end- to-end in one day with 6 CPUs and 1 GPU. In addition, our platform is flexible in terms of environment-agent communication topologies, choices of RL methods, changes in game parameters, and can host existing C/C++-based game environ- ments like ALE [4]. Using ELF, we thoroughly explore training parameters and show that a network with Leaky ReLU [17] and Batch Normalization [11] cou- pled with long-horizon training and progressive curriculum beats the rule-based built-in AI more than 70% of the time in the full game of Mini-RTS. Strong per- formance is also achieved on the other two games. In game replays, we show our agents learn interesting strategies. ELF, along with its RL platform, is open sourced at https://github.com/facebookresearch/ELF. 1 Introduction Game environments are commonly used for research in Reinforcement Learning (RL), i.e. -

Improved Policy Networks for Computer Go
Improved Policy Networks for Computer Go Tristan Cazenave Universite´ Paris-Dauphine, PSL Research University, CNRS, LAMSADE, PARIS, FRANCE Abstract. Golois uses residual policy networks to play Go. Two improvements to these residual policy networks are proposed and tested. The first one is to use three output planes. The second one is to add Spatial Batch Normalization. 1 Introduction Deep Learning for the game of Go with convolutional neural networks has been ad- dressed by [2]. It has been further improved using larger networks [7, 10]. AlphaGo [9] combines Monte Carlo Tree Search with a policy and a value network. Residual Networks improve the training of very deep networks [4]. These networks can gain accuracy from considerably increased depth. On the ImageNet dataset a 152 layers networks achieves 3.57% error. It won the 1st place on the ILSVRC 2015 classifi- cation task. The principle of residual nets is to add the input of the layer to the output of each layer. With this simple modification training is faster and enables deeper networks. Residual networks were recently successfully adapted to computer Go [1]. As a follow up to this paper, we propose improvements to residual networks for computer Go. The second section details different proposed improvements to policy networks for computer Go, the third section gives experimental results, and the last section con- cludes. 2 Proposed Improvements We propose two improvements for policy networks. The first improvement is to use multiple output planes as in DarkForest. The second improvement is to use Spatial Batch Normalization. 2.1 Multiple Output Planes In DarkForest [10] training with multiple output planes containing the next three moves to play has been shown to improve the level of play of a usual policy network with 13 layers. -

Unsupervised State Representation Learning in Atari
Unsupervised State Representation Learning in Atari Ankesh Anand⇤ Evan Racah⇤ Sherjil Ozair⇤ Mila, Université de Montréal Mila, Université de Montréal Mila, Université de Montréal Microsoft Research Yoshua Bengio Marc-Alexandre Côté R Devon Hjelm Mila, Université de Montréal Microsoft Research Microsoft Research Mila, Université de Montréal Abstract State representation learning, or the ability to capture latent generative factors of an environment, is crucial for building intelligent agents that can perform a wide variety of tasks. Learning such representations without supervision from rewards is a challenging open problem. We introduce a method that learns state representations by maximizing mutual information across spatially and tem- porally distinct features of a neural encoder of the observations. We also in- troduce a new benchmark based on Atari 2600 games where we evaluate rep- resentations based on how well they capture the ground truth state variables. We believe this new framework for evaluating representation learning models will be crucial for future representation learning research. Finally, we com- pare our technique with other state-of-the-art generative and contrastive repre- sentation learning methods. The code associated with this work is available at https://github.com/mila-iqia/atari-representation-learning 1 Introduction The ability to perceive and represent visual sensory data into useful and concise descriptions is con- sidered a fundamental cognitive capability in humans [1, 2], and thus crucial for building intelligent agents [3]. Representations that concisely capture the true state of the environment should empower agents to effectively transfer knowledge across different tasks in the environment, and enable learning with fewer interactions [4]. -
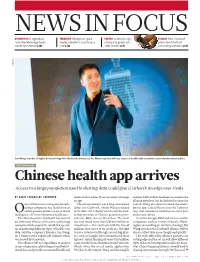
Chinese Health App Arrives Access to a Large Population Used to Sharing Data Could Give Icarbonx an Edge Over Rivals
NEWS IN FOCUS ASTROPHYSICS Legendary CHEMISTRY Deceptive spice POLITICS Scientists spy ECOLOGY New Zealand Arecibo telescope faces molecule offers cautionary chance to green UK plans to kill off all uncertain future p.143 tale p.144 after Brexit p.145 invasive predators p.148 ICARBONX Jun Wang, founder of digital biotechnology firm iCarbonX, showcases the Meum app that will use reams of health data to provide customized medical advice. BIOTECHNOLOGY Chinese health app arrives Access to a large population used to sharing data could give iCarbonX an edge over rivals. BY DAVID CYRANOSKI, SHENZHEN medical advice directly to consumers through another $400 million had been invested in the an app. alliance members, but he declined to name the ne of China’s most intriguing biotech- The announcement was a long-anticipated source. Wang also demonstrated the smart- nology companies has fleshed out an debut for iCarbonX, which Wang founded phone app, called Meum after the Latin for earlier quixotic promise to use artificial in October 2015 shortly after he left his lead- ‘my’, that customers would use to enter data Ointelligence (AI) to revolutionize health care. ership position at China’s genomics pow- and receive advice. The Shenzhen firm iCarbonX has formed erhouse, BGI, also in Shenzhen. The firm As well as Google, IBM and various smaller an ambitious alliance with seven technology has now raised more than US$600 million in companies, such as Arivale of Seattle, Wash- companies from around the world that special- investment — this contrasts with the tens of ington, are working on similar technology. But ize in gathering different types of health-care millions that most of its rivals are thought Wang says that the iCarbonX alliance will be data, said the company’s founder, Jun Wang, to have invested (although several big play- able to collect data more cheaply and quickly. -

Fml-Based Dynamic Assessment Agent for Human-Machine Cooperative System on Game of Go
Accepted for publication in International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems in July, 2017 FML-BASED DYNAMIC ASSESSMENT AGENT FOR HUMAN-MACHINE COOPERATIVE SYSTEM ON GAME OF GO CHANG-SHING LEE* MEI-HUI WANG, SHENG-CHI YANG Department of Computer Science and Information Engineering, National University of Tainan, Tainan, Taiwan *[email protected], [email protected], [email protected] PI-HSIA HUNG, SU-WEI LIN Department of Education, National University of Tainan, Tainan, Taiwan [email protected], [email protected] NAN SHUO, NAOYUKI KUBOTA Dept. of System Design, Tokyo Metropolitan University, Japan [email protected], [email protected] CHUN-HSUN CHOU, PING-CHIANG CHOU Haifong Weiqi Academy, Taiwan [email protected], [email protected] CHIA-HSIU KAO Department of Computer Science and Information Engineering, National University of Tainan, Tainan, Taiwan [email protected] Received (received date) Revised (revised date) Accepted (accepted date) In this paper, we demonstrate the application of Fuzzy Markup Language (FML) to construct an FML- based Dynamic Assessment Agent (FDAA), and we present an FML-based Human–Machine Cooperative System (FHMCS) for the game of Go. The proposed FDAA comprises an intelligent decision-making and learning mechanism, an intelligent game bot, a proximal development agent, and an intelligent agent. The intelligent game bot is based on the open-source code of Facebook’s Darkforest, and it features a representational state transfer application programming interface mechanism. The proximal development agent contains a dynamic assessment mechanism, a GoSocket mechanism, and an FML engine with a fuzzy knowledge base and rule base. -

Understanding & Generalizing Alphago Zero
Under review as a conference paper at ICLR 2019 UNDERSTANDING &GENERALIZING ALPHAGO ZERO Anonymous authors Paper under double-blind review ABSTRACT AlphaGo Zero (AGZ) (Silver et al., 2017b) introduced a new tabula rasa rein- forcement learning algorithm that has achieved superhuman performance in the games of Go, Chess, and Shogi with no prior knowledge other than the rules of the game. This success naturally begs the question whether it is possible to develop similar high-performance reinforcement learning algorithms for generic sequential decision-making problems (beyond two-player games), using only the constraints of the environment as the “rules.” To address this challenge, we start by taking steps towards developing a formal understanding of AGZ. AGZ includes two key innovations: (1) it learns a policy (represented as a neural network) using super- vised learning with cross-entropy loss from samples generated via Monte-Carlo Tree Search (MCTS); (2) it uses self-play to learn without training data. We argue that the self-play in AGZ corresponds to learning a Nash equilibrium for the two-player game; and the supervised learning with MCTS is attempting to learn the policy corresponding to the Nash equilibrium, by establishing a novel bound on the difference between the expected return achieved by two policies in terms of the expected KL divergence (cross-entropy) of their induced distributions. To extend AGZ to generic sequential decision-making problems, we introduce a robust MDP framework, in which the agent and nature effectively play a zero-sum game: the agent aims to take actions to maximize reward while nature seeks state transitions, subject to the constraints of that environment, that minimize the agent’s reward. -

Combining Tactical Search and Deep Learning in the Game of Go
Combining tactical search and deep learning in the game of Go Tristan Cazenave PSL-Universite´ Paris-Dauphine, LAMSADE CNRS UMR 7243, Paris, France [email protected] Abstract Elaborated search algorithms have been developed to solve tactical problems in the game of Go such as capture problems In this paper we experiment with a Deep Convo- [Cazenave, 2003] or life and death problems [Kishimoto and lutional Neural Network for the game of Go. We Muller,¨ 2005]. In this paper we propose to combine tactical show that even if it leads to strong play, it has search algorithms with deep learning. weaknesses at tactical search. We propose to com- Other recent works combine symbolic and deep learn- bine tactical search with Deep Learning to improve ing approaches. For example in image surveillance systems Golois, the resulting Go program. A related work [Maynord et al., 2016] or in systems that combine reasoning is AlphaGo, it combines tactical search with Deep with visual processing [Aditya et al., 2015]. Learning giving as input to the network the results The next section presents our deep learning architecture. of ladders. We propose to extend this further to The third section presents tactical search in the game of Go. other kind of tactical search such as life and death The fourth section details experimental results. search. 2 Deep Learning 1 Introduction In the design of our network we follow previous work [Mad- Deep Learning has been recently used with a lot of success dison et al., 2014; Tian and Zhu, 2015]. Our network is fully in multiple different artificial intelligence tasks. -

(CMPUT) 455 Search, Knowledge, and Simulations
Computing Science (CMPUT) 455 Search, Knowledge, and Simulations James Wright Department of Computing Science University of Alberta [email protected] Winter 2021 1 455 Today - Lecture 22 • AlphaGo - overview and early versions • Coursework • Work on Assignment 4 • Reading: AlphaGo Zero paper 2 AlphaGo Introduction • High-level overview • History of DeepMind and AlphaGo • AlphaGo components and versions • Performance measurements • Games against humans • Impact, limitations, other applications, future 3 About DeepMind • Founded 2010 as a startup company • Bought by Google in 2014 • Based in London, UK, Edmonton (from 2017), Montreal, Paris • Expertise in Reinforcement Learning, deep learning and search 4 DeepMind and AlphaGo • A DeepMind team developed AlphaGo 2014-17 • Result: Massive advance in playing strength of Go programs • Before AlphaGo: programs about 3 levels below best humans • AlphaGo/Alpha Zero: far surpassed human skill in Go • Now: AlphaGo is retired • Now: Many other super-strong programs, including open source Image source: • https://www.nature.com All are based on AlphaGo, Alpha Zero ideas 5 DeepMind and UAlberta • UAlberta has deep connections • Faculty who work part-time or on leave at DeepMind • Rich Sutton, Michael Bowling, Patrick Pilarski, Csaba Szepesvari (all part time) • Many of our former students and postdocs work at DeepMind • David Silver - UofA PhD, designer of AlphaGo, lead of the DeepMind RL and AlphaGo teams • Aja Huang - UofA postdoc, main AlphaGo programmer • Many from the computer Poker group -
![Arxiv:1611.08903V1 [Cs.LG] 27 Nov 2016 20 Percent Increases in Cash Collections [20]](https://docslib.b-cdn.net/cover/1241/arxiv-1611-08903v1-cs-lg-27-nov-2016-20-percent-increases-in-cash-collections-20-2391241.webp)
Arxiv:1611.08903V1 [Cs.LG] 27 Nov 2016 20 Percent Increases in Cash Collections [20]
Should I use TensorFlow? An evaluation of TensorFlow and its potential to replace pure Python implementations in Machine Learning Martin Schrimpf1;2;3 1 Augsburg University 2 Technische Universit¨atM¨unchen 3 Ludwig-Maximilians-Universit¨atM¨unchen Seminar \Human-Machine Interaction and Machine Learning" Supervisor: Elisabeth Andr´e Advisor: Dominik Schiller Abstract. Google's Machine Learning framework TensorFlow was open- sourced in November 2015 [1] and has since built a growing community around it. TensorFlow is supposed to be flexible for research purposes while also allowing its models to be deployed productively [7]. This work is aimed towards people with experience in Machine Learning consider- ing whether they should use TensorFlow in their environment. Several aspects of the framework important for such a decision are examined, such as the heterogenity, extensibility and its computation graph. A pure Python implementation of linear classification is compared with an im- plementation utilizing TensorFlow. I also contrast TensorFlow to other popular frameworks with respect to modeling capability, deployment and performance and give a brief description of the current adaption of the framework. 1 Introduction The rapidly growing field of Machine Learning has been gaining more and more attention, both in academia and in businesses that have realized the added value. For instance, according to a McKinsey report, more than a dozen European banks switched from statistical-modeling approaches to Machine Learning tech- niques and, in some cases, increased their sales of new products by 10 percent and arXiv:1611.08903v1 [cs.LG] 27 Nov 2016 20 percent increases in cash collections [20]. Intelligent machines are used in a variety of domains, including writing news articles [5], finding promising recruits given their CV [9] and many more. -

Software-Defined Software: a Perspective of Machine Learning-Based Software Production
2018 IEEE 38th International Conference on Distributed Computing Systems Software-defined Software: A Perspective of Machine Learning-based Software Production Rubao Lee, Hao Wang, and Xiaodong Zhang Department of Computer Science and Engineering, The Ohio State University {liru, wangh, zhang}@cse.ohio-state.edu Abstract—As the Moore’s Law is ending, and increasingly high have been hidden in the CPU-dominated computing era for two demand of software development continues in the human society, reasons. First, the Moore’s Law can automatically improve the we are facing two serious challenges in the computing field. execution performance by increasing the number of transistors First, the general-purpose computing ecosystem that has been developed for more than 50 years will have to be changed by in CPU chips to enhance the capabilities of on-chip caches and including many diverse devices for various specialties in high computing power. Thus, execution performance continues to performance. Second, human-based software development is not be improved without major software modifications. Second, sustainable to respond the requests from all the fields in the the development of CPU-dominated computing ecosystem for society. We envision that we will enter a time of developing high many years has created multilayer abstractions in a deep quality software by machines, and we name this as Software- defined Software (SDS). In this paper, we will elaborate our software stack, e.g. from IAS, to LLVM, to JAVA/C, and vision, the goals and its roadmap. to JavaScript/Python. This software stack promotes software productivity by connecting programmers at different layers to I. -

When Are We Done with Games?
When Are We Done with Games? Niels Justesen Michael S. Debus Sebastian Risi IT University of Copenhagen IT University of Copenhagen IT University of Copenhagen Copenhagen, Denmark Copenhagen, Denmark Copenhagen, Denmark [email protected] [email protected] [email protected] Abstract—From an early point, games have been promoted designed to erase particular elements of unfairness within the as important challenges within the research field of Artificial game, the players, or their environments. Intelligence (AI). Recent developments in machine learning have We take a black-box approach that ignores some dimensions allowed a few AI systems to win against top professionals in even the most challenging video games, including Dota 2 and of fairness such as learning speed and prior knowledge, StarCraft. It thus may seem that AI has now achieved all of focusing only on perceptual and motoric fairness. Additionally, the long-standing goals that were set forth by the research we introduce the notions of game extrinsic factors, such as the community. In this paper, we introduce a black box approach competition format and rules, and game intrinsic factors, such that provides a pragmatic way of evaluating the fairness of AI vs. as different mechanical systems and configurations within one human competitions, by only considering motoric and perceptual fairness on the competitors’ side. Additionally, we introduce the game. We apply these terms to critically review the aforemen- notion of extrinsic and intrinsic factors of a game competition and tioned AI achievements and observe that game extrinsic factors apply these to discuss and compare the competitions in relation are rarely discussed in this context, and that game intrinsic to human vs.