NB3: a Multilateral Negotiation Algorithm for Large, Non-Linear Agreement Spaces with Limited Time
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
The Negotiation Process
GW Law Faculty Publications & Other Works Faculty Scholarship 2003 The Negotiation Process Charles B. Craver George Washington University Law School, [email protected] Follow this and additional works at: https://scholarship.law.gwu.edu/faculty_publications Part of the Law Commons Recommended Citation Charles B. Craver, The Negotiation Process, 27 Am. J. Trial Advoc. 271 (2003). This Article is brought to you for free and open access by the Faculty Scholarship at Scholarly Commons. It has been accepted for inclusion in GW Law Faculty Publications & Other Works by an authorized administrator of Scholarly Commons. For more information, please contact [email protected]. THE NEGOTIATION PROCESS1 By Charles B. Craver2 I. INTRODUCTION Lawyers negotiate constantly. They negotiate on the telephone, in person, through the mail, and through fax and e-mail transmissions, They even negotiate when they do not realize they are negotiating. They negotiate with their own partners, associates, legal assistants, and secretaries; they negotiate with prospective clients and with current clients. They then negotiate on behalf of clients with outside parties as they try to resolve conflicts or structure business arrangements of various kinds. Most attorneys have not formally studied the negotiation process. Few have taken law school courses pertaining to this critical lawyering skill, and most have not read the leading books and articles discussing this topic. Although they regularly employ their bargaining skills, few actually understand the nuances of the bargaining process. When they prepare for bargaining encounters, they devote hours to the factual, legal, economic, and, where relevant, political issues. Most lawyers devote no more than ten to fifteen minutes on their actual negotiation strategy. -

Reasons to Buy: Contaminated Products & Recall Insurance
Casualty Reasons to Buy: Contaminated Products & Recall Insurance Almost any company involved in the food and beverage industry supply chain may be exposed to an accidental contamination and or recall exposure. Also, there is the possibility that a company’s particular brand may be the target of a malicious threat or extortion, either internally or from a third party. The potential financial impact of a product recall, as well as the lasting impact on brand reputation can be of serious concern to a company and its shareholders. AIG Contaminated Products & Recall Insurance not only protects against loss of gross profits and rehabilitation costs following either accidental or malicious contamination, but also provides the crisis management planning and loss prevention services of leading international crisis management specialists in food safety, brand & reputation impacts and extortion. Cover Cover is triggered by the recall of a product caused by: Accidental Contamination Any accidental or unintentional contamination, impairment or mislabeling which occurs during Cover Includes: or as a result of its production, preparation, manufacturing, packaging or distribution; provided • Recall costs that the use or consumption of such product has resulted in or would result in a manifestation of bodily injury, sickness, disease or death of any person within 120 days after consumption or use. • Business interruption (lost gross profit) Malicious Tampering • Rehabilitation costs Any actual, alleged or threatened, intentional, malicious and wrongful alteration or • Consultancy costs contamination of the Insured’s product so as to render it unfit or dangerous for use or consumption or to create such impression to the public, whether caused by employees or not. -
Lab Activity and Assignment #2
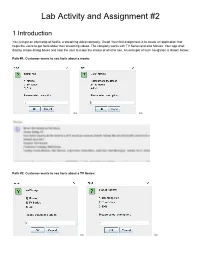
Lab Activity and Assignment #2 1 Introduction You just got an internship at Netfliz, a streaming video company. Great! Your first assignment is to create an application that helps the users to get facts about their streaming videos. The company works with TV Series and also Movies. Your app shall display simple dialog boxes and help the user to make the choice of what to see. An example of such navigation is shown below: Path #1: Customer wants to see facts about a movie: >> >> Path #2: Customer wants to see facts about a TV Series: >> >> >> >> Your app shall read the facts about a Movie or a TV Show from text files (in some other course you will learn how to retrieve this information from a database). They are provided at the end of this document. As part of your lab, you should be creating all the classes up to Section 3 (inclusive). As part of your lab you should be creating the main Netfliz App and making sure that your code does as shown in the figures above. The Assignment is due on March 8th. By doing this activity, you should be practicing the concept and application of the following Java OOP concepts Class Fields Class Methods Getter methods Setter methods encapsulation Lists String class Split methods Reading text Files Scanner class toString method Override superclass methods Scanner Class JOptionPane Super-class sub-class Inheritance polymorphism Class Object Class Private methods Public methods FOR loops WHILE Loops Aggregation Constructors Extending Super StringBuilder Variables IF statements User Input And much more.. -

Negotiating Types of Negotiation
Negotiating What would you do? Alice realizes that this situation with Manuel is similar to negotiations she has faced in other aspects When Alice started recruiting Manuel, she knew of her life. To figure out what to do, she needs to he'd provide the high-profile expertise the determine her best alternative to a negotiated company needed—and she knew he'd be agreement, called a BATNA. Knowing her BATNA expensive. means knowing what she will do or what will But his demands seem to be escalating out of happen if she does not reach agreement in the control. So far, Alice has upped the already-high negotiation at hand. For example, Alice should set salary, added extra vacation time, and increased clear limits on what she's willing to offer Manuel his number of stock options. Now Manuel is and analyze the consequences if she is turned down. asking for an extra performance-based bonus. Would she really be happy choosing a different option for her needs, or is it worth upping the ante to Alice has reviewed the list of other candidates. get exactly what she wants? After she has The closest qualified applicant is very eager for the job, but lacks the experience that Manuel determined her BATNA, she should then figure out would bring. her reservation price, or her "walk-away" number. What's the least favorable point at which she'd Alice prefers Manuel, but she is uncomfortable accept the arrangement with Manuel? Once she with his increasing demands. Should she say knows her BATNA and reservation price, she "no" on principle and risk losing him? Or should should use those as her thresholds in her she agree to his latest request and hope it will be the last? negotiations and not be swayed by Manuel's other demands. -

The Negotiation Checklist: How to Win the Battle Before It Begins
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by School of Hotel Administration, Cornell University Cornell University School of Hotel Administration The Scholarly Commons Articles and Chapters School of Hotel Administration Collection 2-1997 The Negotiation Checklist: How To Win The Battle Before It Begins Tony L. Simons Cornell University, [email protected] Thomas M. Tripp Washington State University Follow this and additional works at: https://scholarship.sha.cornell.edu/articles Part of the Hospitality Administration and Management Commons Recommended Citation Simons, T., & Tripp, T. T. (1997). The negotiation checklist: How to win the battle before it begins. Cornell Hotel and Restaurant Administration Quarterly, 38(1), 14-23. Retrieved [insert date], from Cornell University, School of Hospitality Administration site: http://scholarship.sha.cornell.edu/articles/671/ This Article or Chapter is brought to you for free and open access by the School of Hotel Administration Collection at The Scholarly Commons. It has been accepted for inclusion in Articles and Chapters by an authorized administrator of The Scholarly Commons. For more information, please contact [email protected]. If you have a disability and are having trouble accessing information on this website or need materials in an alternate format, contact [email protected] for assistance. The Negotiation Checklist: How To Win The Battle Before It Begins Abstract Being well-prepared going into a negotiation is key to being successful when you come out. This negotiation checklist is a tool that can maximize your preparation effectiveness and efficiency. Keywords negotiation, hiring decisions, BATNA Disciplines Hospitality Administration and Management Comments Required Publisher Statement © Cornell University. -

Tales of the Bazaar: Interest-Based Negotiation Across Cultures
In Practice Tales of the Bazaar: Interest-Based Negotiation Across Cultures Jeffrey M. Senger Interest-based negotiation, as popularized by Fisher, Ury, and Patton (1991), is a favored negotiation style of many people in the United States and other parts of the developed world. The author, an American attorney who has traveled widely, assesses how that approach works in different cul- tural contexts. Using illustrations from his own experiences, the author shows how interest-based techniques work successfully, as well as the limi- tations of this approach in some situations. An American traveling abroad can experience negotiation in a vast array of cultures, some of which approach a state of nature. Particularly in devel- oping countries, many people negotiate for just about everything. While the fixed price system of commerce is typical in the U.S. and Western Europe, it simply does not exist in many other parts of the world. Even the simplest things we take for granted, such as a meter in a taxicab, are nowhere to be found, and negotiation is forced into almost every transaction. As a teacher of negotiation, as well as a lifelong student of it, I have found overseas travel to provide an amazing education in the field. Both my background and my current practice center largely on “interest-based negoti- ation” (Fisher, Ury, and Patton, 1991). My formal training is in the legal profession, where I first studied negotiation under Roger Fisher. I now con- duct negotiation and mediation training programs for the U.S. Justice Jeffrey M. Senger is Deputy Senior Counsel for Dispute Resolution for the United States Depart- ment of Justice, 950 Pennsylvania Ave. -

Heather Parker
“In all gudly haste”: The Formation of Marriage in Scotland, c. 1350-1600 by Heather Parker A thesis presented to the University of Guelph In partial fulfilment of requirements for the degree of Doctor of Philsophy in History Guelph, Ontario, Canada © Heather Parker, March 2012 ABSTRACT “IN ALL GUDLY HASTE”: THE FORMATION OF MARRIAGE IN SCOTLAND, C. 1350-1600 Heather Parker Advisor: University of Guelph, 2012 Elizabeth Ewan This dissertation examines the formation of marriage in Scotland between the mid- fourteenth century and the late sixteenth century. In particular, it focuses on betrothals, marriage negotiations, ritual, and the place that these held in late medieval Scottish society. This study extends to the generation following the Reformation to examine the extent to which the Reformation influenced the marriage planning of wealthy Scots. It concludes that much of the social impact of the Reformation was not reflected in family life until at least a generation after reform. Scottish society and culture was influenced both by contemporary literature, which discussed the role of marriage formation, and by concurrent events involving high-profile marriages. These helped to define the context of marriage for society as a whole. This work relies heavily on the pre-nuptial contracts of lairds (the Scottish gentry) and nobles, which reflected certain aspects of their marriage patterns and strategies. The context and clauses of an extensive group of 272 Scottish marriage contracts from published and archival collections illuminate aspects of the formation of Scottish marriage, such as the land and money that changed hands, the extent to which brides and grooms were influenced by their kin, and the timelines for betrothals. -

Practical Guide to Negotiating in the Military (2Nd Edition) “Let Us Never Negotiate out of Fear
Practical Guide to Negotiating in the Military (2nd edition) “Let us never negotiate out of fear. But, let us never fear to negotiate.” John F Kennedy “In today’s DOD environment, your span of authority is often less than your span of responsibility. In short, you are charged with mission success while working with people you have no direct authority over.” Dr Stefan Eisen TABLE OF CONTENTS 1. Introduction 2 2. Negotiations Defined 2 3. Choices in Conflict Management: The Relationship between Task and People 3 4. Essential Terms 5 5. TIPO Framework 9 6. NPSC: Negotiation Strategy Selection 14 a. Evade 14 b. Comply 15 c. Insist 16 d. Settle 17 e. Cooperative Negotiation Strategy (CNS) 19 7. Common Pitfalls to any Negotiation Strategy 23 8. Summary 24 Appendix 1: Glossary of Common Negotiating Terms 26 Appendix 2: TIPO Worksheet 36 Appendix 3: AFNC Negotiation Worksheets 37 Annex A: AFNC Negotiation Worksheet 38 Annex B: AFNC Negotiation Worksheet (Expanded) 39 Appendix 4: AFNC Negotiation Execution Checklist 44 Appendix 5: AFNC Negotiation Cultural Considerations 45 INTRODUCTION Military leaders do not operate in isolation. Because of our professional duties and our social natures, we constantly interact with others in many contexts. Often the interaction’s purpose is to solve a problem; getting two or more people (or groups of people) to decide on a course of action to accomplish a goal. Virtually every problem solving process we attempt involves some aspect of negotiations. Practically speaking, Air Force personnel engage daily in negotiations with co-workers, supervisors, subordinates, business partners, coalition warfighters, non-governmental organizations, etc. -

Basics of Negotiation
BASICS OF NEGOTIATION J. Alexander Tanford, 2000 1. BASIC PRINCIPLE, WITHOUT WHICH NEGOTIATION IS IMPOSSIBLE Successful negotiation requires compromise from both sides. Both parties must gain something, and both parties must lose something. You must be prepared to give something up to which you believe you are entitled. You cannot expect to defeat your opponent or "win" a negotiation by either the power of your negotiating skills or the compelling force of your logic. This is not to say that good negotiating ability is irrelevant. In most cases, a range of possible outcomes exists. A skilled negotiator often can achieve a settlement near the top of the range. 2. MISCELLANEOUS LEGAL PRINCIPLES, IN NO PARTICULAR ORDER ! Rule 68 provides that a defendant may make a written offer of judgment, and if the plaintiff refuses it, plaintiff becomes liable for all the litigation costs if plaintiff does not do better at trial. ! The judge is permitted to participate in negotiation as long as he or she acts as a catalyst, encouraging settlement but not taking sides. If the judge becomes too actively involved, he or she may become biased against a party who is reluctant to settle, disqualifying the judge from presiding further. ! In most cases in which a settlement is reached, court proceedings can be terminated without obtaining judicial approval. Just file a stipulation of dismissal signed by all parties. See Rule 41. ! Court approval of settlements must be obtained in a few cases, especially if claims by minors are involved. ! A negotiated settlement is a contract, controlled by the law of contracts. -

How to Negotiate the Highest Salary (Plus Get All the Perks) EXECUTIVE SUMMARY
OWN YOUR PAYCHECK! How to Negotiate the Highest Salary (Plus Get All the Perks) EXECUTIVE SUMMARY As a business professional, you have the power to make sure your pay is commensurate with the value you now produce or the potential value you likely will produce for your employer. This guide will help you take the steps to make sure you know how to negotiate your salary, whether you are beginning a new job or securing a raise in your current position. The guide is organized in two parts. Part 1 covers the three steps to prepare your assets for effective negotiation: 1. Build a portfolio of “wins” or accomplishments; 2. Adopt an “I am worth it” (not arrogant) mindset; 3. Research your current market value. Part 2 provides instructions to deploy three steps for effective negotiation: 1. Delay negotiating until you have a firm salary offer; 2. Take the lead to start the negotiation process, remembering that your employer expects it; 3. Escalate the conversation in a collegial manner seeking clarity and collaboration to achieve a mutually beneficial outcome. You are the entrepreneur of your career, so own it! Whether you are about to start a new job or you deserve a raise in your current job, use the strategies in this guide to control the outcome of any salary negotiation. Your employer expects you to take the lead. If you do, it will certainly pay off. INTRODUCTION Take Power Over Your Paycheck.! Do you feel like your boss or your potential new employer makes all the decisions about your compensation?! ! Does it seem like you don’t have any control over how much money you take home besides waiting for your next review or hoping you get a good offer? ! ! Wrong. -

Migration, Arts and the Negotiation of Belonging” Ameriquests 16.1 (2020)
Clini, Hornabrook & Keightley “Migration, Arts and the Negotiation of Belonging” AmeriQuests 16.1 (2020) Migration, Arts and the Negotiation of Belonging: An analysis of creative practices within British Asian communities in London and Loughborough Clelia Clini, Jasmine Hornabrook and Emily Keightley This article offers a comparative analysis of the engagement in cultural and creative practices of people of South Asian heritage in the market town of Loughborough, East Midlands, and in the borough of Tower Hamlets in London. Taking the potential of the arts as a means to reinforce social identities, challenge social exclusion and promote intercultural dialogue (McGregor and Ragab 2016: 7-8) as the starting point of our analysis, we argue that creative arts represent, for British Asian communities, an effective means for the preservation of cultural heritage and the negotiation of a diasporic identity in the British context. Loughborough and Tower Hamlets are the two sites where we are conducting the Migrant Memory and the Post-colonial Imagination (MMPI) research project, which investigates the cultural memories of the Partition of British India circulating within South Asian diasporic communities in the UK. Launched in 2017, this is an interdisciplinary project located at the crossroads of memory studies, diaspora, cultural and postcolonial studies, for which we adopt a mixed creative research method which is grounded in ethnography and includes different participatory arts methodologies to elicit and evoke memories of Partition and migration with South Asian groups.1 Following Tolia-Kelly, we posit that using visual and material culture and objects, rather than abstract ideas, is an effective way of triggering memories and can help researchers understand the role of memory in everyday life (2004: 679). -

The Organization of the Kyoto Protocol Negotiations: Lessons for Global Environmental Decision-Making
THE ORGANIZATION OF THE KYOTO PROTOCOL NEGOTIATIONS: LESSONS FOR GLOBAL ENVIRONMENTAL DECISION-MAKING Joanna Jane Depledge Department of Geography University College London Submitted in accordance with the requirements for the degree of PhD University of London, 2001 ProQuest Number: U642941 All rights reserved INFORMATION TO ALL USERS The quality of this reproduction is dependent upon the quality of the copy submitted. In the unlikely event that the author did not send a complete manuscript and there are missing pages, these will be noted. Also, if material had to be removed, a note will indicate the deletion. uest. ProQuest U642941 Published by ProQuest LLC(2016). Copyright of the Dissertation is held by the Author. All rights reserved. This work is protected against unauthorized copying under Title 17, United States Code. Microform Edition © ProQuest LLC. ProQuest LLC 789 East Eisenhower Parkway P.O. Box 1346 Ann Arbor, Ml 48106-1346 ABSTRACT Global negotiations on environmental problems raise complex challenges for diplomacy, such as dealing with complexity, uncertainty and equity dilemmas. Such challenges are particularly acute in the case of climate change. This thesis examines negotiations under the climate change regime, which overcame such challenges to reach agreement on the Kyoto Protocol in December 1997. Using the analogy of negotiation as ‘theatrical performance’, the thesis analyses the organization of the Kyoto Protocol negotiation process and its effectiveness. This is an under-researched topic, despite its importance. Organizational elements are often open to policy manipulation, and can therefore be ‘stage-managed’ to maximize the chances of a successful negotiation. The thesis examines six organizational elements: the negotiation organizers, namely, the presiding officers, bureau and secretariat; rules for the conduct of business and decision-making; negotiating arenas; participation rules for parties and non-state organizations; arrangements for the input of scientific information; and the use of texts and time as negotiating tools.