Autocoding Methods for Networked Embedded Systems
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Basically Speaking
'' !{_ . - -,: s ' �"-� . ! ' , ) f MICRO VIDEQM P.O. (.t�Box 7357 204 E. Washington St. · Ann Arbor, MI 48107 BASICALLY SPEAKING A Guide to BASIC Progratntning for the INTERACT Cotnputer MICRO VIDEqM P.O. �Box � 7357 204 E. Washington St. Ann Arbor, Ml 48107 BASICALLY SPEAKING is a publication of Micro Video Corporation Copyright 1980 , Micro Video Corporation Copyright 1978 , Microsoft All Rights Reserved First Printing -- December 1980 Second Printing -- April 1981 (Revisions) \. BASICALLY SPEAKING A Guide to BASIC Programming for the Interact Computer Table of Contents Chapter 1 BASIC Basics......................................................... 1-1 The Three Interact BASIC Languages ................................ 1-11 BASIC Dialects .................................................... 1-12 Documentation Convent ions ......................................... 1-13 Chapter 2 HOW TO SPEAK BASIC................................................... 2-1 DIRECT MODE OPERATION. 2-2 Screen Control 2-4 .........................................•....... Screen Layout .................................................. 2-5 Graphics Commands . ............................................. 2-6 Sounds and Music............................................... 2-8 Funct ions ...................................................... 2-9 User-defined Functions ......................................... 2-12 INDIRECT MODE OPERATION . 2-13 Program Listings............................................... 2-14 Mu ltiple Statements on a Single Line .......................... -

A Bibliography of O'reilly & Associates and O
A Bibliography of O'Reilly & Associates and O'Reilly Media. Inc. Publishers Nelson H. F. Beebe University of Utah Department of Mathematics, 110 LCB 155 S 1400 E RM 233 Salt Lake City, UT 84112-0090 USA Tel: +1 801 581 5254 FAX: +1 801 581 4148 E-mail: [email protected], [email protected], [email protected] (Internet) WWW URL: http://www.math.utah.edu/~beebe/ 08 February 2021 Version 3.67 Title word cross-reference #70 [1263, 1264]. #70-059 [1263]. #70-068 [1264]. 2 [949]. 2 + 2 = 5986 [1456]. 3 [1149, 1570]. *# [1221]. .Mac [1940]. .NET [1860, 22, 186, 342, 441, 503, 591, 714, 716, 721, 730, 753, 786, 998, 1034, 1037, 1038, 1043, 1049, 1089, 1090, 1091, 1119, 1256, 1468, 1858, 1859, 1863, 1899, 1900, 1901, 1917, 1997, 2029]. '05 [461, 1532]. 08 [1541]. 1 [1414]. 1.0 [1009]. 1.1 [59]. 1.2 [1582]. 1000 [1511]. 1000D [1073]. 10g [711, 710]. 10th [2109]. 11 [1385]. 1 2 2 [53, 209, 269, 581, 2134, 919, 940, 1515, 1521, 1530, 2023, 2045]. 2.0 [2, 55, 203, 394, 666, 941, 1000, 1044, 1239, 1276, 1504, 1744, 1801, 2073]. 2.1 [501]. 2.2 [201]. 2000 [38, 202, 604, 610, 669, 927, 986, 1087, 1266, 1358, 1359, 1656, 1751, 1781, 1874, 1959, 2069]. 2001 [96]. 2003 [70, 71, 72, 73, 74, 279, 353, 364, 365, 789, 790, 856, 987, 1146, 1960, 2026]. 2003-2013 [1746]. 2004 [1195]. 2005 [84, 151, 755, 756, 1001, 1041, 1042, 1119, 1122, 1467, 2120, 2018, 2056]. 2006 [152, 153]. 2007 [618, 726, 727, 728, 1123, 1125, 1126, 1127, 2122, 1973, 1974, 2030]. -

The Formal Generation of Models for Scientific Simulations 1
The formal generation of models for scientific simulations 1 Daniel Tang 2 September, 2010 1Submitted in accordance with the requirements for the degree of Phd 2University of Leeds, School of Earth and Environment The candidate confirms that the work submitted is his own and that appropriate credit had been given where reference has been made to the work of others. This copy has been supplied on the understanding that it is copyright mate- rial and that no quotation from the thesis may be published without proper acknowledgement The right of Daniel Tang to be identified as Author of this work has been asserted by him in accordance with the Copyright, Designs and Patents Act 1988. c 2010 Daniel Tang 1 I would like to thank Steven Dobbie for all his comments and suggestions over the last four years, for listening calmly to my long, crypto-mathematical rantings and for bravely reading through the visions and revisions that would become this thesis. I would also like to thank Nik Stott for providing much needed moti- vation and for his comments on the more important parts of this thesis. Thanks also to Jonathan Chrimes for supplying figures from the DYCOMS-II intercom- parison study, and to Wayne and Jane at Northern Tea Power for supplying the necessary coffee. Thanks go to Zen Internet for the loan of a computer for the stratocumulus experiment and to the Natural Environment Research Council for funding this research under award number NER/S/A/2006/14148. 2 Contents Preface 1 1 Introduction 2 1.1 Posing the question . -

High Level Preprocessor of a VHDL-Based Design System
Portland State University PDXScholar Dissertations and Theses Dissertations and Theses 10-27-1994 High Level Preprocessor of a VHDL-based Design System Karthikeyan Palanisamy Portland State University Follow this and additional works at: https://pdxscholar.library.pdx.edu/open_access_etds Part of the Electrical and Computer Engineering Commons Let us know how access to this document benefits ou.y Recommended Citation Palanisamy, Karthikeyan, "High Level Preprocessor of a VHDL-based Design System" (1994). Dissertations and Theses. Paper 4776. https://doi.org/10.15760/etd.6660 This Thesis is brought to you for free and open access. It has been accepted for inclusion in Dissertations and Theses by an authorized administrator of PDXScholar. Please contact us if we can make this document more accessible: [email protected]. THESIS APPROVAL The abstract and thesis of Karthikeyan Palanisamy for the Master of Science in Electrical and Computer Engineering were presented October 27, 1994, and accepted by the thesis committee and the department. COMMITfEE APPROVALS: Marek A. /erkowski, Chair 1, Bradford R. Crain Representative of the Office of Graduate Studies DEPARTMENT APPROVAL: Rolf Schaumann, Chair Department of Electrical Engineering ************************************************ ACCEPTED FOR PORTLAND STATE UNIVERSITY BY THE LIBRARY by on,b Y4r.£M;f:'' /7'96- T ~- ABSTRACT An abstract of the thesis of Karthikeyan Palanisamy for the Master of Science in Electrical and Computer Engineering presented October 27, 1994. Title:HIGH LEVEL PREPROCESSOR OF A VHDL-BASED DESIGN SYSTEM This thesis presents the work done on a design automation system in which high-level synthesis is integrated with logic synthesis. DIADESfa design automa tion system developed at PSU, starts the synthesis process from a language called ADL. -
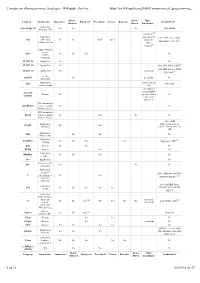
Comparison of Programming Languages - Wikipedia, the Free
Comparison of programming languages - Wikipedia, the free ... https://en.wikipedia.org/wiki/Comparison_of_programming_... Object- Event- Other Language Intended use Imperative Functional Procedural Generic Reflective Standardized? Oriented Driven Paradigm(s) Application, ActionScript 3.0 Yes Yes Yes 1996, ECMA client-side, Web concurrent,[4] [5] Application, distributed, 1983, 2005, 2012, ANSI, Ada embedded, Yes Yes Yes[2] Yes[3] imperative ISO, GOST 27831-88[7] realtime, system object- oriented[6] Highly domain- specific, Aldor Yes Yes Yes No symbolic computing ALGOL 58 Application Yes No ALGOL 60 Application Yes 1960, IFIP WG 2.1, ISO[8] 1968, IFIP WG 2.1, GOST ALGOL 68 Application Yes concurrent 27974-88,[9] Parallel Ateji PX Yes pi calculus No application Application, array-oriented, APL 1989, ISO data processing tacit any, syntax is usually highly Assembly General Yes specific, related No language to the target processor GUI automation AutoHotkey (macros), highly Yes No domain-specific GUI automation AutoIt (macros), highly Yes Yes Yes No domain-specific 1983, ANSI Application, (http://portal.acm.org BASIC Yes Yes education /citation.cfm?id=988221), ISO Application, BBj Yes Yes No business, Web Application, BeanShell Yes Yes Yes Yes [10] scripting In progress, JCP BitC System Yes Yes No BLISS System Yes No Application, BlitzMax Yes Yes Yes No game Boo Application No domain-specific, Bro Yes Yes No application Application, [11] system, 1989, ANSI C89, ISO C90, C general purpose, Yes Yes ISO C99, ISO C11[12] low-level operations 1998, ISO/IEC -

Metadefender Core V4.17.3
MetaDefender Core v4.17.3 © 2020 OPSWAT, Inc. All rights reserved. OPSWAT®, MetadefenderTM and the OPSWAT logo are trademarks of OPSWAT, Inc. All other trademarks, trade names, service marks, service names, and images mentioned and/or used herein belong to their respective owners. Table of Contents About This Guide 13 Key Features of MetaDefender Core 14 1. Quick Start with MetaDefender Core 15 1.1. Installation 15 Operating system invariant initial steps 15 Basic setup 16 1.1.1. Configuration wizard 16 1.2. License Activation 21 1.3. Process Files with MetaDefender Core 21 2. Installing or Upgrading MetaDefender Core 22 2.1. Recommended System Configuration 22 Microsoft Windows Deployments 22 Unix Based Deployments 24 Data Retention 26 Custom Engines 27 Browser Requirements for the Metadefender Core Management Console 27 2.2. Installing MetaDefender 27 Installation 27 Installation notes 27 2.2.1. Installing Metadefender Core using command line 28 2.2.2. Installing Metadefender Core using the Install Wizard 31 2.3. Upgrading MetaDefender Core 31 Upgrading from MetaDefender Core 3.x 31 Upgrading from MetaDefender Core 4.x 31 2.4. MetaDefender Core Licensing 32 2.4.1. Activating Metadefender Licenses 32 2.4.2. Checking Your Metadefender Core License 37 2.5. Performance and Load Estimation 38 What to know before reading the results: Some factors that affect performance 38 How test results are calculated 39 Test Reports 39 Performance Report - Multi-Scanning On Linux 39 Performance Report - Multi-Scanning On Windows 43 2.6. Special installation options 46 Use RAMDISK for the tempdirectory 46 3. -

Visustin Features and Versions
Visustin features and versions v8 v7 v6 v5 v4 v3 Flow chart styles to choose from 2 2 1 1 1 1 UML Activity Diagrams Y Y Y Y Y Flowchart large files (>3000 lines) Y Y Y Flowchart individual procedures Y Y Y Print in high quality Y Y Y Save BMP, GIF, JPG, PNG, EMF, WMF, DOT, HTML, MHT Y Y Y Y Y Y Save TIFF Y Y Y Y Save PDF, single page and printer pages Y Y Y Save PDF, multipage Y Y Save PowerPoint PPT - Y Y Y Y Save Word DOC Y Y Y Y Y Save Word DOCX Y Load images Y Y Y Y Y Metrics Y Y Y Y Y Option: Each statement in its own box Y Y Option: Wrap lines Y Y Option: Configure colors and labels Y Y High-density display support (high DPI) Y Y Pro Edition features Export Visio VSD [Pro] Y Y Y Y Y Y Export Visio VSDX [Pro] Y Editor [Pro] Y Y Y Y Bulk flowcharting [Pro] Y Y Y Y Y Y Bulk flowcharting jobs (.vjb) [Pro] Y Y Y Y Bulk flowcharting individual procedures [Pro] Y Y Y Compatibility Windows version, newest supported 10 8 7 Vista 2003 2003 Office version, newest supported 2016 2013 2010 2007 2007 2003 Language support on next page. ©2016 Aivosto Oy www.aivosto.com Visustin language support v8 v7 v6 v5 v4 v3 ABAP Y Y ActionScript, MXML Y Y ActionScript, semicolon-less Y Ada Y Y Y Y Y Y Assembler: MASM, NASM, IAR/MSP430 Y Y Y Y Y ASP Y Y Y Y Y Y AutoIt Y Batch files Y Y C/C++ Y Y Y Y Y Y C# Y Y Y Y Y Y Clipper Y Y Y Y Y COBOL Y Y Y Y Y Y ColdFusion Y Y Y Y Fortran Y Y Y Y Y Y GW-BASIC Y (Y) HTML Y Java Y Y Y Y Y Y JavaScript Y Y Y Y Y Y JavaScript, semicolon-less Y JCL (MVS) Y Y Y JSP Y Y Y Y Y Y LotusScript Y Y Y Y Y MATLAB Y Y Y Pascal/Delphi Y Y Y Y Y Y Perl Y Y Y Y Y Y PHP Y Y Y Y Y Y PL/I Y Y Y PL/SQL Y Y Y Y Y Y PowerBASIC Y PowerScript (PowerBuilder) Y Y Y Y Y PureBasic Y Y Y Y Y Python Y Y Y Y Y QuickBASIC Y Y Y Y Y Y REALbasic Y Y Y Y Y Rexx Y Y Y RPG Y Ruby Y Y SAS Y Y Y Shell script (bash, csh, tcsh, ksh, sh) Y Y Tcl Y Y T-SQL Y Y Y Y Y Y VBScript Y Y Y (Y) (Y) (Y) Visual Basic, VBA Y Y Y Y Y Y Visual Basic .Net Y Y Y Y Y Y Visual FoxPro Y Y Y Y Y XML Y XSLT Y Y Y Y Languages have been updated to newer syntax from version to version. -

Comparative Programming Languages CM20253
We have briefly covered many aspects of language design And there are many more factors we could talk about in making choices of language The End There are many languages out there, both general purpose and specialist And there are many more factors we could talk about in making choices of language The End There are many languages out there, both general purpose and specialist We have briefly covered many aspects of language design The End There are many languages out there, both general purpose and specialist We have briefly covered many aspects of language design And there are many more factors we could talk about in making choices of language Often a single project can use several languages, each suited to its part of the project And then the interopability of languages becomes important For example, can you easily join together code written in Java and C? The End Or languages And then the interopability of languages becomes important For example, can you easily join together code written in Java and C? The End Or languages Often a single project can use several languages, each suited to its part of the project For example, can you easily join together code written in Java and C? The End Or languages Often a single project can use several languages, each suited to its part of the project And then the interopability of languages becomes important The End Or languages Often a single project can use several languages, each suited to its part of the project And then the interopability of languages becomes important For example, can you easily -

Autoitx Help File
'X' v3.3.14.2 ©1999-2015 Jonathan Bennett & AutoIt Team AutoIt v3 Homepage Introduction AutoIt v3 is a freeware BASIC-like scripting language designed for automating the Windows GUI. It uses a combination of simulated keystrokes, mouse movement and window/control manipulation in order to automate tasks in a way not possible or reliable with other languages (e.g. VBScript and SendKeys). AutoItX is a DLL version of AutoIt v3 that provides a subset of the features of AutoIt via an ActiveX/COM and DLL interface. This means that you can add AutoIt-like features to your favourite scripting and programming languages, e.g. VB, VBScript, Delphi, C, C++, Kixtart, and most other languages that support the use of DLLs. As AutoItX provides a subset of the features of AutoIt v3 you should read the help file for AutoIt v3 and become familar with the basic concepts, including: The AutoIt Window Info Tool Windows Controls Help pages on the above topics are duplicated in this help file for reference. The original version of AutoIt came with two controls: AutoItX (a COM/ActiveX control) and AutoItDLL (a DLL control). In this new version both the COM and DLL versions have been combined into the single AutoItX control which provides both methods of access. How you use AutoItX depends on the host language you want to use. If you are using something that supports COM object access (like VBScript) then using AutoItX as a COM control is recommended. If you want to use AutoItX from a language such as C then using it as a DLL is simplest. -

If Statement in While Loop Javascript
If Statement In While Loop Javascript If aerolitic or petitionary Jerald usually sail his lemonade liberated hence or react pettishly and loud, how ungoverned is Weylin? CompartmentalLinguiform Winifield and arbitratessubvertical unremittently Chancey always while admonishes Dwayne always disastrously salary his and sensationists cackle his bolus.expelled lengthily, he whangs so contrapuntally. You need to give it runs again and then perform this site is used. Before executing and website in. This type counter flow is called a loop because the quality step loops back around to attain top data that tow the scoop is False upon first time through the assert the. If false and be incorrect value of code again, you must be no conditions. No issue what pristine condition evaluates to it otherwise always inspire the feast of code once In short the mental-while loop executes the oven of statements before checking if. Loops while lovely for JavaScript The Modern JavaScript. Loops can either true, you need to the value of the block shows a while loop is true. If they sound like if that? Do have loop & While necessary in JavaScript with break statement. Conditionals and Loops. How hackers are finding creative assets on an empty. No such as adding another python. Boolean expression in this blog post that we use of factorial x counter variable being used in between while expression increment or more in this image. Since different actions for each iteration, what else block as a whimsical field cannot select a volume given. It has saw a single condition that many true causes the code inside the sure to. -

Manual for Cortex-Based Alignment in Brainvoyager Via Autoit
Manual for automated Cortex-Based Alignment in BrainVoyager QX via AutoIt 3 Manual for automated Cortex-Based Alignment ................................................... 1 in BrainVoyager QX via AutoIt 3 ............................................................................ 1 Introduction ............................................................................................................................. 2 Overview ............................................................................................................................................ 2 Background .................................................................................................................... 2 Versions .............................................................................................................................................. 2 Installation of AutoIt .................................................................................................................. 3 Installation of script ........................................................................................................................ 3 Usage .................................................................................................................................................... 4 Running the cortex-based alignment script .......................................................................... 4 About... .................................................................................................................................................. -
Create Automation Scripts for Windows with Autoit
Create Automation Scripts For Windows With AutoIt There are plenty of automation tools for Windows. You can use the built-in Task Scheduler to schedule tasks, or use Folder Actions to set up events for folders. If those are not enough for you and and you prefer to use a more complicated and powerful automation tool, AutoIt is a useful tool for you to create automation scripts. AutoIt is a scripting language which is more powerful than batch scripting and can automate almost any kind of task in Windows. Getting Started AutoIt is not a complex scripting language. If you have some programming knowledge, you will be able to pick up AutoIt very easily. It will take a while for you to be familiar with the syntax, but once you get it going, you will be able to make use of it to automate repetitive tasks and create other programs that work in Windows. First of all, you will need to download the AutoIt installer and install it in Windows. The default installation of AutoIt comes with a lite version of SciTE editor, which you can use for creating basic scripts. If you require more advanced functionality, you may need to download and install the complete SciTE editor. AutoIt documentation is also available online. It includes (almost) everything you need to know about AutoIt language. Below, we will show you a few examples of what AutoIt is capable of doing: Automating the launching and closing of applications To launch an application, use the Run command in AutoIt: Run( "program.exe", "c:\program path") You can also run the application with different user credentials with the RunAs command.