Efficient Democratic Decisions Via Nondeterministic Proportional
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
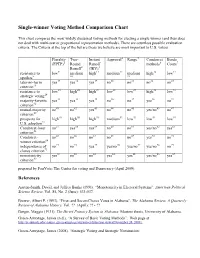
Single-Winner Voting Method Comparison Chart
Single-winner Voting Method Comparison Chart This chart compares the most widely discussed voting methods for electing a single winner (and thus does not deal with multi-seat or proportional representation methods). There are countless possible evaluation criteria. The Criteria at the top of the list are those we believe are most important to U.S. voters. Plurality Two- Instant Approval4 Range5 Condorcet Borda (FPTP)1 Round Runoff methods6 Count7 Runoff2 (IRV)3 resistance to low9 medium high11 medium12 medium high14 low15 spoilers8 10 13 later-no-harm yes17 yes18 yes19 no20 no21 no22 no23 criterion16 resistance to low25 high26 high27 low28 low29 high30 low31 strategic voting24 majority-favorite yes33 yes34 yes35 no36 no37 yes38 no39 criterion32 mutual-majority no41 no42 yes43 no44 no45 yes/no 46 no47 criterion40 prospects for high49 high50 high51 medium52 low53 low54 low55 U.S. adoption48 Condorcet-loser no57 yes58 yes59 no60 no61 yes/no 62 yes63 criterion56 Condorcet- no65 no66 no67 no68 no69 yes70 no71 winner criterion64 independence of no73 no74 yes75 yes/no 76 yes/no 77 yes/no 78 no79 clones criterion72 81 82 83 84 85 86 87 monotonicity yes no no yes yes yes/no yes criterion80 prepared by FairVote: The Center for voting and Democracy (April 2009). References Austen-Smith, David, and Jeffrey Banks (1991). “Monotonicity in Electoral Systems”. American Political Science Review, Vol. 85, No. 2 (June): 531-537. Brewer, Albert P. (1993). “First- and Secon-Choice Votes in Alabama”. The Alabama Review, A Quarterly Review of Alabama History, Vol. ?? (April): ?? - ?? Burgin, Maggie (1931). The Direct Primary System in Alabama. -

Crowdsourcing Applications of Voting Theory Daniel Hughart
Crowdsourcing Applications of Voting Theory Daniel Hughart 5/17/2013 Most large scale marketing campaigns which involve consumer participation through voting makes use of plurality voting. In this work, it is questioned whether firms may have incentive to utilize alternative voting systems. Through an analysis of voting criteria, as well as a series of voting systems themselves, it is suggested that though there are no necessarily superior voting systems there are likely enough benefits to alternative systems to encourage their use over plurality voting. Contents Introduction .................................................................................................................................... 3 Assumptions ............................................................................................................................... 6 Voting Criteria .............................................................................................................................. 10 Condorcet ................................................................................................................................. 11 Smith ......................................................................................................................................... 14 Condorcet Loser ........................................................................................................................ 15 Majority ................................................................................................................................... -
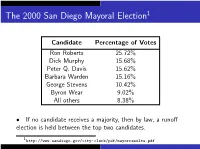
The Plurality-With-Elimination Method (PWE)
The 2000 San Diego Mayoral Election1 Candidate Percentage of Votes Ron Roberts 25.72% Dick Murphy 15.68% Peter Q. Davis 15.62% Barbara Warden 15.16% George Stevens 10.42% Byron Wear 9.02% All others 8.38% • If no candidate receives a majority, then by law, a runoff election is held between the top two candidates. 1http://www.sandiego.gov/city-clerk/pdf/mayorresults.pdf Example: The 2000 San Diego Mayoral Election Practical problems with this system: I Runoff elections cost time and money I Ties (or near-ties) for second place I Preference ballots provide a method of holding an “instant-runoff" election: the Plurality-with-Elimination Method (PWE). 2. If no candidate has received a majority, then eliminate the candidate with the fewest first-place votes. 3. Repeat steps 1 and 2 until some candidate has a majority, then declare that candidate the winner. The Plurality-with-Elimination Method (x1.4) 1. Count the first-place votes. If some candidate receives a majority of the first-place votes, then that candidate is the winner. 3. Repeat steps 1 and 2 until some candidate has a majority, then declare that candidate the winner. The Plurality-with-Elimination Method (x1.4) 1. Count the first-place votes. If some candidate receives a majority of the first-place votes, then that candidate is the winner. 2. If no candidate has received a majority, then eliminate the candidate with the fewest first-place votes. The Plurality-with-Elimination Method (x1.4) 1. Count the first-place votes. If some candidate receives a majority of the first-place votes, then that candidate is the winner. -

Arrow's Impossibility Theorem
Arrow’s Impossibility Theorem Some announcements • Final reflections due on Monday. • You now have all of the methods and so you can begin analyzing the results of your election. Today’s Goals • We will discuss various fairness criteria and how the different voting methods violate these criteria. Last Time We have so far discussed the following voting methods. • Plurality Method (Majority Method) • Borda Count Method • Plurality-with-Elimination Method (IRV) • Pairwise Comparison Method • Method of Least Worst Defeat • Ranked Pairs Method • Approval Voting Fairness Criteria The following fairness criteria were developed by Kenneth Arrow, an economist in the 1940s. Economists are often interested in voting theories because of their impact on game theory. The mathematician John Nash (the subject of A Beautiful Mind) won the Nobel Prize in economics for his contributions to game theory. The Majority Criterion A majority candidate should always be the winner. Note that this does not say that a candidate must have a majority to win, only that such a candidate should not lose. Plurality, IRV, Pairwise Comparison, LWD, and Ranked Pairs all satisfy the Majority Criterion. The Majority Criterion The Borda Count Method violates the Majority Criterion. Number of voters 6 2 3 1st A B C 2nd B C D 3rd C D B 4th D A A Even though A had a majority of votes it only has 29 points. B is the winner with 32 points. Moral: Borda Count punishes polarizing candidates. The Condorcet Criterion A Condorcet candidate should always be the winner. Recall that a Condorcet Candidate is one that beats all other candidates in a head-to-head (pairwise) comparison. -

Borda Count, Pairwise Comparison, Approval Voting, Fairness Criteria
Day 2: Borda count, Pairwise Comparison, Approval Voting, Fairness Criteria Recall: Consider the voting system below. Who is the winner under the IRV method? 10 of the voters who had originally voted in the order Brown, Adams, Carter change their vote to favor the presumed winner changing those votes to Adams, Brown, Carter. Who is the winner under the IRV method? Monotonicity Criterion If voters change their votes to increase the preference for a candidate, it should not harm that candidate’s chances of winning. Boda count: (Another voting method, named for Jean-Charles de Borda) In this method, points are assigned to candidates based on their ranking; 1 point for last choice, 2 points for second-to-last choice, and so on. The point values for all ballots are totaled, and the candidate with the largest point total is the winner. Ex1) A camping club is deciding where to go on their next trip. The preference table is shown below, Find the winner under Borda count method. A = Arches, G = Grand Canyon, Y = Yosemite, Z = Zion Number of voters 12 5 4 9 6 10 1st Choice Y G Z A A Z 2nd Choice Z Y A Y Z G 3rd Choice G A G G Y A 4th Choice A Z Y Z G Y Since there are 4 choices 1th Place gets 4 points 2th Place gets 3 points 3th Place gets 2 points 4th Place gets 1point Number of voters 12 5 4 9 6 10 1st Choice Y G Z A A Z 4Point 12.4=48 5.4=20 4.4=16 9.4=36 6.4=24 10.4=40 2nd Choice Z Y A Y Z G 3Point 12.3=36 5.3=15 4.3=12 3rd Choice G A G G Y A 2Point 5.2=1o 10.2=20 4th Choice A Z Y Z G Y 1Point 12.1=12 Total points: Arches = 36 + 24 + 12 +10 +10 +20 +12 = 114 Grand Canyon = 106 Yosemite = 116 Zion = 124 Under the Borda count method Zion is the winner What’s Wrong with Borda Count? One potential flaw of Borda count is a candidate could receive a majority of the first- choice votes and still lose the election. -

Which Voting System Is Best for Canada?
Electoral Reform: Which Voting System is Best For Canada? By David Piepgrass While watching the election coverage last Monday night, I was disconcerted by claims from party leaders and even journalists, suggesting that Canadians had “asked” for various things by their voting: “Canadians have asked our party to take the lead” “Canadians have selected a new government.” “Although Canadians have voted for change, they have not given any one party a majority in the House of Commons. They have asked us to cooperate, to work together, and to get on with tackling the real issues that matter to ordinary working people and their families.” - Stephen Harper “Canadians have asked the Conservatives to form a government – in a minority Parliament” “while the people of Canada asked Mr. Harper to form a minority government, the people of Canada also asked New Democrats to balance that government...” - Jack Layton But I voted in the election, and guess what I didn't see on the ballot? I wonder what they based their statements on. Votes vs. Seats (Federal Election 2006) Probably, it was either the popular vote or the Conservatives makeup of the government, but isn't it odd that the Liberals two are different? You can see the dichotomy NDP Percent of vote between the popular vote and the seat allocation Bloc Percent of on the right. It looks like the NDP and Bloc have Other seats somehow confused each other's seats, but actually, 0 5 10 15 20 25 30 35 40 45 as Canadian elections go, this one isn't too bad. -

An Analysis of Random Elections with Large Numbers of Voters Arxiv
An Analysis of Random Elections with Large Numbers of Voters∗ Matthew Harrison-Trainor September 8, 2020 Abstract In an election in which each voter ranks all of the candidates, we consider the head- to-head results between each pair of candidates and form a labeled directed graph, called the margin graph, which contains the margin of victory of each candidate over each of the other candidates. A central issue in developing voting methods is that there can be cycles in this graph, where candidate A defeats candidate B, B defeats C, and C defeats A. In this paper we apply the central limit theorem, graph homology, and linear algebra to analyze how likely such situations are to occur for large numbers of voters. There is a large literature on analyzing the probability of having a majority winner; our analysis is more fine-grained. The result of our analysis is that in elections with the number of voters going to infinity, margin graphs that are more cyclic in a certain precise sense are less likely to occur. 1 Introduction The Condorcet paradox is a situation in social choice theory where every candidate in an election with three or more alternatives would lose, in a head-to-head election, to some other candidate. For example, suppose that in an election with three candidates A, B, and C, and three voters, the voter's preferences are as follows: arXiv:2009.02979v1 [econ.TH] 7 Sep 2020 First choice Second choice Third choice Voter 1 A B C Voter 2 B C A Voter 3 C A B There is no clear winner, for one can argue that A cannot win as two of the three voters prefer C to A, that B cannot win as two of the three voters prefer A to B, and that C cannot win as two of the three voters prefer B to C. -

Formally Verified Invariants of Vote Counting Schemes
Formally Verified Invariants of Vote Counting Schemes ∗ Florrie Verity Dirk Pattinson The Australian National University The Australian National University ABSTRACT system is universally verifiable if any member of the general The correctness of ballot counting in electronically held elec- public has means to determine whether all ballots cast have tions is a cornerstone for establishing trust in the final re- been counted correctly. End-to-end verifiability is usually sult. Vote counting protocols in particular can be formally achieved by complex cryptographic methods and generate specified by as systems of rules, where each rule application receipts that voters can use to verify integrity of their bal- represents the effect of a single action in the tallying process lot, without revealing the ballot content. None of the current that progresses the count. We show that this way of formal- voting systems in existence [16, 4, 11, 5] offers universal ver- ising vote counting protocols is also particularly suitable for ifiability of the tallying in elections that rely on complex, (formally) establishing properties of tallying schemes. The preferential voting schemes such as single transferable vote key notion is that of an invariant: properties that transfer used in the majority of elections in Australia. That is, there from premiss to conclusion of all vote counting rules. We is no way for voters or political parties to verify the correct- show that the rule-based formulation of tallying schemes al- ness of the count. lows us to give transparent formal proofs of properties of the This is mediated, for example by the Australian Elec- respective scheme with relative ease. -

Voting Criteria
Voting Criteria 21-301 2018 30 April 1 Evaluating voting methods In the last session, we learned about different voting methods. In this session, we will focus on the criteria we use to evaluate whether voting methods are doing their jobs; that is, the criteria we use to determine if a voting system is reasonable and fair. We use all notation as in the previous set of notes. 1. Majority Criterion: If a candidate gets > 50% of the first place votes, that candidate should be the winner. This criterion is quite straightforward. If a candidate is preferred by more than half of the voters, this candidate by all rights should win the election. No other candidate could be more satisfactory for more people than the first choice of more than 50% of the voters. It is immediately obvious that the plurality method and the runoff methods will satisfy this criterion, since their method of determining the winner is fundamentally based on first place votes. For other methods, the criterion is less clear. 2. Condorcet Criterion: If a candidate wins every pairwise comparison, then that candidate should be the winner. This should remind you of the Condorcet method for choosing a winner. Of course, it is immediately obvious that if the Condorcet method produces a winner without having to resolve ties, then that candidate wins the election in that method, so clearly the Condorcet method satisfies the Condorcet criterion. However, it is not clear that the other methods will satisfy this criterion; for example, in Hare method, is it possible to eliminate a candidate that would otherwise be a Condorcet winner? 3. -

Verifiable Voting Systems
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Open Repository and Bibliography - Luxembourg Chapter 69 Verifiable Voting Systems Thea Peacock1, Peter Y. A. Ryan1, Steve Schneider2 and Zhe Xia2 1 University of Luxembourg 2 University of Surrey 1 Introduction The introduction of technology into voting systems can bring a number of benefits, such as improving accessibility, remote voting and efficient, accurate processing of votes. A voting system which uses electronic technology in any part of processing the votes, from vote capture and transfer through to vote tallying, is known as an `e-voting' system. In addition to the undoubted benefits, the introduction of such technology introduces particular security challenges, some of which are unique to voting systems because of their specific nature and requirements. The key role that voting systems play in democratic elections means that such systems must not only be secure and trustworthy, but must be seen by the electorate to be secure and trustworthy. It is a challenge to reconcile the secrecy of the ballot with demonstrable correctness of the result. There are many general challenges involved in running a voting system securely, that are common to any complex secure system, and any implementation will need to take account of these. Over and above these, we introduce a particular approach to address- ing the challenge of demonstrating trustworthiness, around the key idea of `end-to-end verifiability'. This means that every step of the processing of the votes, from vote casting through to vote tallying, can be independently verified by some agent independent of the voting system itself. -

Chapter 9 Social Choice: the Impossible Dream
Chapter 9 Social Choice: The Impossible Dream For All Practical Purposes: Effective Teaching • Talk to your fellow TA’s during the term and find out how their sessions are set up and how they are going. Talking about student problems and how they were handled can help both you and your colleagues in becoming confident educators. • In this chapter and others involving voting, you will represent candidates by letters such as A, B, C, or D. A good habit to get into early on, in general, is to use capital letters in cases such as this or if multiple-choice responses are requested. You can also impart to students that if lower case letters are used (like “a” or “d”) and their answers are not clear, then it is possible that their response will be marked as incorrect. Chapter Briefing Social choice theory was developed to analyze the various types of voting methods, to discover the potential pitfalls in each, and to attempt to find improved systems of voting. One difficulty you may encounter imparting to students is the need for various voting methods and their mathematical nature. Discussions can start with examining two candidate races and the simplicity of invoking majority rule. When there are three or more candidates, however, different and more complicated voting techniques may be required. Students may have difficulties grasping the differences between the voting methods and in turn the different criterion. Being well prepared by knowing these methods and criterion is essential for successful classroom discussions. In your academic preparation, you may not have encountered the topic of Social Choice. -

Fairness Criteria Voting Methods
VOTING METHODS FAIRNESS CRITERIA Majority Criterion – If a candidate wins by a Majority – receiving more than half of the first majority, then that candidate should win the place votes election by another method. Evaluation – If the majority winner does not win by another Plurality Method – receiving the most first place method, then this criterion is violated. If votes majority winner does win by another method, then it is not violated. Plurality with Elimination – Check first place votes for a majority. If candidate has a majority, then Head-to-head Criterion – If a candidate wins by declared winner. If not, eliminate the candidate head-to-head (pairwise) over every other with the fewest first place votes and recount. candidate, then that candidate should win the Recount. Continue until a candidate wins by a election. Evaluation – If one candidate wins over majority. all others when paired up and does not win by another method, then the criterion is violated. If Borda Count Method – Voters rank candidates on by another method, the head-to-head winner ballot. Assign 1 point to last place, 2 points to next, still wins, then the criterion is not violated. etc. Total points for each candidate. Candidate with the most points wins. Irrelevant Alternatives Criterion – A candidate wins. In a recount the only changes are that one Pairwise Comparison (Head-to-Head) Method – or more of the candidates are removed. Original Voters rank candidates on ballot. Pair up winner should win. Evaluation – A candidate candidates so each is compared with every other. drops out. Look at the 1st place votes.