Unicode Ein Kompakter Überblick Des Standards Geschichte, 1
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Frequently Asked Questions and Selected Resources on Cyrillic Multilingual Computing
Frequently Asked Questions and Selected Resources on Cyrillic Multilingual Computing Kevin S. Hawkins SUMMARY. The persistence of multiple standards, both de jure and de facto, for handling text on the computer is perhaps the most perplexing problem facing those who wish to use a computer in more than one lan- guage, or even to provide access to data across more than one operating system and application platform. Using Cyrillic as an example, this ar- ticle attempts to answer questions commonly asked by non-expert computer users who wish to work in more than one language. [Article copies available for a fee from The Haworth Document Delivery Service: 1-800-HAWORTH. E-mail address: <[email protected]> Website: <http://www.HaworthPress.com> © 2005 by The Haworth Press, Inc. All rights reserved.] Kevin S. Hawkins, MS, is Electronic Publishing Librarian, Scholarly Publishing Office, University Library, University of Michigan. Address correspondence to: Kevin S. Hawkins, 300 Hatcher Graduate Library North, 920 North University Avenue, Ann Arbor, MI 48109-1205 USA (E-mail: kshawkin@ umich.edu). The author wishes to thank David Dubin and the other members of the GSLIS Re- search Writing Group at the University of Illinois at Urbana-Champaign for their com- prehensive advice, and Troy Williams, Benjamin Rifkin, Michael Brewer, David Dubin, Tatiana Poliakevitch, Irina Roskin, Peter Houtzagers, and Uladzimir Katkouski for their specific corrections and suggestions. [Haworth co-indexing entry note]: “Frequently Asked Questions and Selected Resources on Cyrillic Multilingual Computing.” Hawkins, Kevin S. Co-published simultaneously in Slavic & East European Infor- mation Resources (The Haworth Information Press, an imprint of The Haworth Press, Inc.) Vol. -

Sample Chapter 3
108_GILLAM.ch03.fm Page 61 Monday, August 19, 2002 1:58 PM 3 Architecture: Not Just a Pile of Code Charts f you’re used to working with ASCII or other similar encodings designed I for European languages, you’ll find Unicode noticeably different from those other standards. You’ll also find that when you’re dealing with Unicode text, various assumptions you may have made in the past about how you deal with text don’t hold. If you’ve worked with encodings for other languages, at least some characteristics of Unicode will be familiar to you, but even then, some pieces of Unicode will be unfamiliar. Unicode is more than just a big pile of code charts. To be sure, it includes a big pile of code charts, but Unicode goes much further. It doesn’t just take a bunch of character forms and assign numbers to them; it adds a wealth of infor- mation on what those characters mean and how they are used. Unlike virtually all other character encoding standards, Unicode isn’t de- signed for the encoding of a single language or a family of closely related lan- guages. Rather, Unicode is designed for the encoding of all written languages. The current version doesn’t give you a way to encode all written languages (and in fact, this concept is such a slippery thing to define that it probably never will), but it does provide a way to encode an extremely wide variety of lan- guages. The languages vary tremendously in how they are written, so Unicode must be flexible enough to accommodate all of them. -

I18n, M17n, Unicode, and All That
I18N, M17N, UNICODE, AND ALL THAT Tim Bray General-Purpose Web Geek Sun Microsystems /[a-zA-Z]+/ This is probably a bug. The Problems We Have To Solve Identifying characters Storage Byte⇔character mapping Transfer Good string API Published in 1996; it has 74 major sections, most of which discuss whole families of writing systems. www.w3.org/TR/charmod Identifying Characters 1,1 17 “Planes”14,1 each with 64k code points: U+0000 – U+10FFFF BMP 12 Unicode Code Points 0 0000 1 0000 Basic Multilingual Plane 2 0000 Dead Languages & Math 3 0000 Han Characters 4 0000 5 0000 Non-BMP 6 0000 7 0000 99,024 characters defined in Unicode 5.0 “Astral” Planes 8 0000 9 0000 A 0000 B 0000 C 0000 D 0000 E 0000 Language F 0000 10 0000 Private Use T ags The Basic Multilingual Plane (BMP) U+0000 – U+FFFF 0000 Alphabets 1000 2000 3000 Punctuation 4000 Asian-language Support 5000 Han Characters 6000 7000 8000 9000 A000 Y B000 i Hangul C000 D000 E000 (*: Legacy-Compatibility junk)Surrogates F000 Private Use * Unicode Character Database 00C8;LATIN CAPITAL LETTER E WITH GRAVE;Lu;0;L;0045 0300;;;;N;LATIN CAPITAL LETTER E GRAVE;;;00E8; “Character #200 is LATIN CAPITAL LETTER E WITH GRAVE, a lower-case letter, combining class 0, renders L-to-R, can be composed by U+0045/U+0300, had a differentÈ name in Unicode 1, isn’t a number, lowercase is U+00E8.” www.unicode.org/Public/Unidata $ U+0024 DOLLAR SIGN Ž U+017D LATIN CAPITAL LETTER Z WITH CARON ® U+00AE REGISTERED SIGN ή U+03AE GREEK SMALL LETTER ETA WITH TONOS Ж U+0416 CYRILLIC CAPITAL LETTER ZHE א U+05D0 HEBREW LETTER -

How to Access Alternate Glyphs
HOW TO ACCESS ALTERNATE GLYPHS Access Alternate at Photoshop/Illustrator There are three ways to insert alternate glyphs: • The Selection in-context menu lets you view and insert glyphs available for a selected character. • The Glyphs panel lets you view and insert glyphs from any typeface. • The OpenType panel lets you set up rules for using glyphs. For example, you can specify that you want to use ligatures, titling characters, and fractions in a given text block. Using the OpenType panel is easier than inserting glyphs one at a time and ensures a more consistent result. However, the panel works only with OpenType fonts. Replace a character with on-canvas alternate glyphs Introduced in Illustrator CC 2017 release When you're working on a type object, you can select a character to quickly view alternate glyphs right next to it in the in-context menu. Simply click the alternate glyph to replace the character with it. In-context alternate glyphs Note: Illustrator displays a maximum of five alternate glyphs for a selected character on the canvas. If more than five alternatives are available, Illustrator displays the icon to the right of the displayed alternate glyphs. Click the icon to open the Glyphs panel and view more alternatives. Glyphs panel overview You use the Glyphs panel (Window > Type > Glyphs) to view the glyphs in a font and insert specific glyphs in your document. By default, the Glyphs panel displays all the glyphs for the currently selected font. You can change the font by selecting a different font family and style at the bottom of the panel. -

Multiple-Policy Character Annotation Based on CHISE
Multiple-policy Character Annotation based on CHISE Multiple-policy Character Annotation based on CHISE Tomohiko Morioka* Abstract This paper describes a knowledge based character processing model to resolve some problems of coded character model. Currently, in the field of information processing of digital texts, each character is represented and processed by the “Coded Character Model.” In this model, each character is defined and shared using a coded character set (code) and represented by a code-point (integer) of the code. In other words, when knowledge about characters is defined (standardized) in a specification of a coded character set, then there is no need to store large and detailed knowledge about characters into computers for basic text processing. In terms of flexibility, however, the coded character model has some problems, because it assumes a finite set of characters, with each character of the set having a stable concept shared in the community. However, real character usage is not so static and stable. Especially in Chinese characters, it is not so easy to select a finite set of characters which covers all usages. To resolve these problems, we have proposed the “Chaon” model. This is a new model of character processing based on character ontology. This report briefly describes the Chaon model and the CHISE (Character Information Service Environment) project, and focuses on how to represent Chinese characters and their glyphs in the context of multiple unification rules. 1 Introduction Digital texts are usually represented by sequences of coded characters, defined in major coded character sets for information interchange, such as UCS1 (Unicode). -

XML in the Development of Component Systems
Data-centric XML Character Sets © 2010 Martin v. Löwis 2010© Martin v. Montag, 3. Mai 2010 Character Sets: Rationale •Computer stores data in sequences of bytes – each byte represents a value in range 0..255 •Text data are intended to denote characters, not numbers •Encoding defines a mechanism to associate bytes and characters •Encoding can only cover finite number of character ↠ character set – Many terminology issues (character set, repertoire, encoding, coded character set, …) © 2010 Martin v. Löwis 2010© Martin v. Datenorientiertes XML 2 Montag, 3. Mai 2010 Character Sets: History • ASCII: American Standard Code for Information Interchange – 7-bit character set, 1963 proposed, 1968 finalized • ANSI X3.4-1968 – 32(34) control characters, 96(94) graphical characters – Also known as CCITT International Alphabet #5 (IA5), ISO 646 • national variants, international reference version • DIN 66003: @ vs. §, [ vs. Ä, \ vs. Ö, ] vs. Ü, … © 2010 Martin v. Löwis 2010© Martin v. Datenorientiertes XML 3 Montag, 3. Mai 2010 Character Sets: History (2) • 8-bit character sets: 190..224 graphic characters • ISO 8859: European/Middle-East alphabets – ISO-8859-1: Western Europe (Latin-1) – ISO-8859-2: Central/Eastern Europe (Latin-2) – ISO-8859-3: Southern Europe (Latin-3) – ISO-8859-4: Northern Europe (Latin-4) – ISO-8859-5: Cyrillic – ISO-8859-6: Arabic – ISO-8859-7: Greek – ISO-8859-8: Hebrew – ISO-8859-9: Turkish (Latin-5; replace Icelandic chars with Turkish) – ISO-8859-10: Nordic (Latin-6; Latin 4 + Inuit, non-Skolt Sami) – ISO-8859-11 (1999): Thai – ISO-8859-13: Baltic Rim (Latin-7) – ISO-8859-14: Celtic (Latin-8) – ISO-8859-15: Western Europe (Latin-9, Latin-1 w/o fraction characters, plus Euro sign, Š, Ž, Œ, Ÿ) – ISO-8859-16: European (Latin-10, omit many symbols in favor of letters) © 2010 Martin v. -

Replacement Draft for TEI P5/CH
1 ODD SUBSET 1.1 Languages and Character Sets The documents which users of these Guidelines may wish to encode encompass all kinds of material, potentially expressed in the full range of written and spoken human languages, including the extinct, the non-existent, and the conjectural. Because of this wide scope, special attention has been paid to two particular aspects of the representation of linguistic information often taken for granted: language identification, and character encoding. Even within a single document, material in many different languages may be encountered. Human culture, and the texts which embody it, is intrinsically multilingual, and shows no sign of ceasing to be so. Traditional philologists and modern computational linguists alike work in a polyglot world, in which code-switching (in the linguistic sense) and accurate representation of differing language systems constitute the norm, not the exception. The current increased interest in studies of linguistic diversity, most notably in the recording and documentation of endangered languages, is one aspect of this long standing tradition. Because of their historical importance, the needs of endangered and even extinct languages must be taken into account when formulating Guidelines and recommendations such as these. Beyond the sheer number and diversity of human languages, it should be remembered that in their written forms they may deploy a huge variety of scripts or writing systems. These scripts are in turn composed of smaller units, which for simplicity we term here characters. A primary goal when encoding a text should be to capture enough information for subsequent users of it correctly to identify both language, script, and constituent characters. -

Unicode Introduction Ken Zook October 20, 2008 Contents 1 Unicode Introduction
Unicode introduction Ken Zook October 20, 2008 Contents 1 Unicode introduction .................................................................................................. 1 2 Unicode properties (slide 1) ........................................................................................ 1 3 Unicode code space (slide 2) ...................................................................................... 2 4 Encoding Unicode (slide 3) ........................................................................................ 2 5 Private Use Area (slide 4) ........................................................................................... 3 6 Canonical equivalence (slide 6) .................................................................................. 4 7 Normalization (NFD) (slide 7).................................................................................... 5 8 Normalization (NFC) (slide 8) .................................................................................... 6 9 Case conversion (slides 9–12) .................................................................................... 7 10 Smart rendering: Arabic (slide 13) ......................................................................... 9 11 Smart rendering: Burmese (slide 14) ...................................................................... 9 12 Smart rendering: Tamil (slide 15) ........................................................................... 9 13 FieldWorks rendering ............................................................................................ -
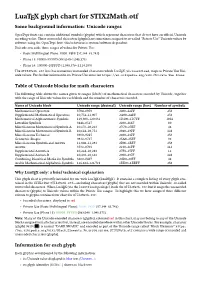
Luatex Glyph Chart for Stix2math.Otf Some Background Information: Unicode Ranges
LuaTEX glyph chart for STIX2Math.otf Some background information: Unicode ranges OpenType fonts can contain additional symbols (glyphs) which represent characters that do not have an official Unicode encoding value. These unencoded characters (glyphs) are sometimes assigned to so-called “Private Use” Unicode values by software using the OpenType font: this behaviour is system/software dependent. Unicode sets aside three ranges of values for Private Use: • Basic Multilingual Plane: E000–F8FF (57,344–63,743) • Plane 15: F0000–FFFFD (983,040–1,048,573) • Plane 16: 100000–10FFFD (1,048,576–1,114,109) The STIX2Math.otf font has numerous unencoded characters which LuaTEX, via luaotfload, maps to Private Use Uni- code values. For further information on Private Use areas see https://en.wikipedia.org/wiki/Private_Use_Areas. Table of Unicode blocks for math characters The following table shows the names given to ranges (blocks) of mathematical characters encoded by Unicode, together with the range of Unicode values for each block and the number of characters encoded. Name of Unicode block Unicode range (decimal) Unicode range (hex) Number of symbols Mathematical Operators 8704–8959 2200–22FF 256 Supplemental Mathematical Operators 10,752–11,007 2A00–2AFF 256 Mathematical Alphanumeric Symbols 119,808–120,831 1D400–1D7FF 1024 Letterlike Symbols 8848–8527 2100–214F 80 Miscellaneous Mathematical Symbols-A 10,176–10,223 27C0–27EF 48 Miscellaneous Mathematical Symbols-B 10,624–10,751 2980–29FF 128 Miscellaneous Technical 8960–9215 2300–23FF 256 Geometric Shapes 9632–9727 25A0–25FF 96 Miscellaneous Symbols and Arrows 11,008–11,263 2B00–2BFF 256 Arrows 8592–8703 2190–21FF 112 Supplemental Arrows-A 10,224–10,239 27F0–27FF 16 Supplemental Arrows-B 10,496–10,623 2900–297F 128 Combining Diacritical Marks for Symbols 8400–8447 20D0–20FF 48 Arabic Mathematical Alphabetic Symbols 126,464–126,719 1EE00–1EEFF 256 Why LuaTEX only: a brief technical explanation This glyph chart is primarily intended for use with LuaTEX (LuaLATEX). -

Data-Centric XML
© 2006 Martin v. Löwis Data-centric XML Character Sets Character Sets: Rationale •Computer stores data in sequences of bytes – each byte represents a value in range 0..255 •Text data are intended to denote characters, not numbers •Encoding defines a mechanism to associate bytes and characters •Encoding can only cover finite number of character ↠ character set – Many terminology issues (character set, repertoire, encoding, coded character set, …) . Löwis © 2006 Martin v Datenorientiertes XML 2 Character Sets: History • ASCII: American Standard Code for Information Interchange – 7-bit character set, 1963 proposed, 1968 finalized • ANSI X3.4-1986 – 32(34) control characters, 96(94) graphical characters – Also known as CCITT International Alphabet #5 (IA5), ISO 646 • national variants, international reference version • DIN 66003: @ vs. §, [ vs. Ä, \ vs. Ö, ] vs. Ü, … . Löwis © 2006 Martin v Datenorientiertes XML 3 Character Sets: History (2) • 8-bit character sets: 190..224 graphic characters • ISO 8859: European/Middle-East alphabets – ISO-8859-1: Western Europe (Latin-1) – ISO-8859-2: Central/Eastern Europe (Latin-2) – ISO-8859-3: Southern Europe (Latin-3) – ISO-8859-4: Northern Europe (Latin-4) – ISO-8859-5: Cyrillic – ISO-8859-6: Arabic – ISO-8859-7: Greek – ISO-8859-8: Hebrew – ISO-8859-9: Turkish (Latin-5; replace Icelandic chars with Turkish) – ISO-8859-10: Nordic (Latin-6; Latin 4 + Inuit, non-Skolt Sami) – ISO-8859-11 (1999): Thai – ISO-8859-13: Baltic Rim (Latin-7) – ISO-8859-14: Celtic (Latin-8) – ISO-8859-15: Western Europe (Latin-9, Latin-1 w/o fraction characters, plus Euro sign, Š, Ž, Œ, Ÿ) . Löwis – ISO-8859-16: European (Latin-10, omit many symbols in favor of letters) © 2006 Martin v Datenorientiertes XML 4 Character Sets: History (3) • Many proprietary 8-bit characters sets: – IBM code pages (e.g. -

The World in 30 Minutes
THE WORLD IN 30 MINUTES Tim Bray RubyKaigi 2007 Sun Microsystems /[a-zA-Z]+/ This is probably a bug. たぶんバグ The Problems We Have To Solve 解決すべき問題 Identifying characters Storage Byte⇔character mapping Transfer Good string API Published in 1996; it has 74 major sections, most of which discuss whole families of writing systems. 1996年刊; 世界の書記体系 についての書籍 www.w3.org/TR/charmod Identifying Characters 文字の識別 1,114,112 Unicode Code Points 17 “Planes” each with 64k code points: U+0000 – U+10FFFF BMP 0 0000 1 0000 Basic Multilingual Plane 2 0000 Dead Languages & Math 3 0000 Han Characters 4 0000 5 0000 Non-BMP 6 0000 7 0000 99,024 characters defined in Unicode 5.0 “Astral” Planes Unicode5.0は99,024文字を定義 8 0000 9 0000 A 0000 B 0000 C 0000 D 0000 E 0000 Language F 0000 10 0000 Private Use T ags The Basic Multilingual Plane (BMP) U+0000 – U+FFFF 0000 Alphabets 1000 2000 3000 Punctuation 4000 Asian-language Support 5000 Han Characters 6000 7000 8000 9000 A000 Y B000 i Hangul C000 D000 E000 (*: Legacy-Compatibility junk)Surrogates F000 Private Use * Unicode Character Database 00C8;LATIN CAPITAL LETTER E WITH GRAVE;Lu;0;L;0045 0300;;;;N;LATIN CAPITAL LETTER E GRAVE;;;00E8; “Character #200 is LATIN CAPITAL LETTER E WITH GRAVE, a lower-case letter, combining class 0, renders L-to-R, can be composed by U+0045/U+0300, had a differentÈ name in Unicode 1, isn’t a number, lowercase is U+00E8.” www.unicode.org/Public/Unidata $ U+0024 DOLLAR SIGN Ž U+017D LATIN CAPITAL LETTER Z WITH CARON ® U+00AE REGISTERED SIGN ή U+03AE GREEK SMALL LETTER ETA WITH TONOS Ж U+0416 -
Ios Internationalization: the Complete Guide Addison-Wesley Mobile Programming Series
iOS Internationalization: The Complete Guide Addison-Wesley Mobile Programming Series Visit informit.com/mobile for a complete list of available publications. he Addison-Wesley Mobile Programming Series is a collection of programming Tguides that explore key mobile programming features and topics in-depth. The sample code in each title is downloadable and can be used in your own projects. Each topic is covered in as much detail as possible with plenty of visual examples, tips, and step-by-step instructions. When you complete one of these titles, you’ll have all the information and code you will need to build that feature into your own mobile application. Make sure to connect with us! informit.com/socialconnect iOS Internationalization: The Complete Guide Shawn E. Larson Upper Saddle River, NJ • Boston • Indianapolis • San Francisco New York • Toronto • Montreal • London • Munich • Paris • Madrid Cape Town • Sydney • Tokyo • Singapore • Mexico City iOS Internationalization: The Complete Guide Editor-in-Chief Copyright © 2015 by Pearson Education, Inc. Mark Taub All rights reserved. Printed in the United States of America. This publication is Senior Acquisitions protected by copyright, and permission must be obtained from the publisher Editor prior to any prohibited reproduction, storage in a retrieval system, or transmis- Trina MacDonald sion in any form or by any means, electronic, mechanical, photocopying, re- Development cording, or likewise. To obtain permission to use material from this work, Editor please submit a written request to Pearson Education, Inc., Permissions De- Sheri Replin partment, One Lake Street, Upper Saddle River, New Jersey 07458, or you may fax your request to (201) 236-3290.