Optimizing Caching on Modern Storage Devices with Orthus
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Trusted Docker Containers and Trusted Vms in Openstack
Trusted Docker Containers and Trusted VMs in OpenStack Raghu Yeluri Abhishek Gupta Outline o Context: Docker Security – Top Customer Asks o Intel’s Focus: Trusted Docker Containers o Who Verifies Trust ? o Reference Architecture with OpenStack o Demo o Availability o Call to Action Docker Overview in a Slide.. Docker Hub Lightweight, open source engine for creating, deploying containers Provides work flow for running, building and containerizing apps. Separates apps from where they run.; Enables Micro-services; scale by composition. Underlying building blocks: Linux kernel's namespaces (isolation) + cgroups (resource control) + .. Components of Docker Docker Engine – Runtime for running, building Docker containers. Docker Repositories(Hub) - SaaS service for sharing/managing images Docker Images (layers) Images hold Apps. Shareable snapshot of software. Container is a running instance of image. Orchestration: OpenStack, Docker Swarm, Kubernetes, Mesos, Fleet, Project Docker Layers Atomic, Lattice… Docker Security – 5 key Customer Asks 1. How do you know that the Docker Host Integrity is there? o Do you trust the Docker daemon? o Do you trust the Docker host has booted with Integrity? 2. How do you verify Docker Container Integrity o Who wrote the Docker image? Do you trust the image? Did the right Image get launched? 3. Runtime Protection of Docker Engine & Enhanced Isolation o How can Intel help with runtime Integrity? 4. Enterprise Security Features – Compliance, Manageability, Identity authentication.. Etc. 5. OpenStack as a single Control Plane for Trusted VMs and Trusted Docker Containers.. Intel’s Focus: Enable Hardware-based Integrity Assurance for Docker Containers – Trusted Docker Containers Trusted Docker Containers – 3 focus areas o Launch Integrity of Docker Host o Runtime Integrity of Docker Host o Integrity of Docker Images Today’s Focus: Integrity of Docker Host, and how to use it in OpenStack. -

Dm-X: Protecting Volume-Level Integrity for Cloud Volumes and Local
dm-x: Protecting Volume-level Integrity for Cloud Volumes and Local Block Devices Anrin Chakraborti Bhushan Jain Jan Kasiak Stony Brook University Stony Brook University & Stony Brook University UNC, Chapel Hill Tao Zhang Donald Porter Radu Sion Stony Brook University & Stony Brook University & Stony Brook University UNC, Chapel Hill UNC, Chapel Hill ABSTRACT on Amazon’s Virtual Private Cloud (VPC) [2] (which provides The verified boot feature in recent Android devices, which strong security guarantees through network isolation) store deploys dm-verity, has been overwhelmingly successful in elim- data on untrusted storage devices residing in the public cloud. inating the extremely popular Android smart phone rooting For example, Amazon VPC file systems, object stores, and movement [25]. Unfortunately, dm-verity integrity guarantees databases reside on virtual block devices in the Amazon are read-only and do not extend to writable volumes. Elastic Block Storage (EBS). This paper introduces a new device mapper, dm-x, that This allows numerous attack vectors for a malicious cloud efficiently (fast) and reliably (metadata journaling) assures provider/untrusted software running on the server. For in- volume-level integrity for entire, writable volumes. In a direct stance, to ensure SEC-mandated assurances of end-to-end disk setup, dm-x overheads are around 6-35% over ext4 on the integrity, banks need to guarantee that the external cloud raw volume while offering additional integrity guarantees. For storage service is unable to remove log entries documenting cloud storage (Amazon EBS), dm-x overheads are negligible. financial transactions. Yet, without integrity of the storage device, a malicious cloud storage service could remove logs of a coordinated attack. -

Providing User Security Guarantees in Public Infrastructure Clouds
1 Providing User Security Guarantees in Public Infrastructure Clouds Nicolae Paladi, Christian Gehrmann, and Antonis Michalas Abstract—The infrastructure cloud (IaaS) service model offers improved resource flexibility and availability, where tenants – insulated from the minutiae of hardware maintenance – rent computing resources to deploy and operate complex systems. Large-scale services running on IaaS platforms demonstrate the viability of this model; nevertheless, many organizations operating on sensitive data avoid migrating operations to IaaS platforms due to security concerns. In this paper, we describe a framework for data and operation security in IaaS, consisting of protocols for a trusted launch of virtual machines and domain-based storage protection. We continue with an extensive theoretical analysis with proofs about protocol resistance against attacks in the defined threat model. The protocols allow trust to be established by remotely attesting host platform configuration prior to launching guest virtual machines and ensure confidentiality of data in remote storage, with encryption keys maintained outside of the IaaS domain. Presented experimental results demonstrate the validity and efficiency of the proposed protocols. The framework prototype was implemented on a test bed operating a public electronic health record system, showing that the proposed protocols can be integrated into existing cloud environments. Index Terms—Security; Cloud Computing; Storage Protection; Trusted Computing F 1 INTRODUCTION host level. While support data encryption at rest is offered by several cloud providers and can be configured by tenants Cloud computing has progressed from a bold vision to mas- in their VM instances, functionality and migration capabil- sive deployments in various application domains. However, ities of such solutions are severely restricted. -

NOVA: a Log-Structured File System for Hybrid Volatile/Non
NOVA: A Log-structured File System for Hybrid Volatile/Non-volatile Main Memories Jian Xu and Steven Swanson, University of California, San Diego https://www.usenix.org/conference/fast16/technical-sessions/presentation/xu This paper is included in the Proceedings of the 14th USENIX Conference on File and Storage Technologies (FAST ’16). February 22–25, 2016 • Santa Clara, CA, USA ISBN 978-1-931971-28-7 Open access to the Proceedings of the 14th USENIX Conference on File and Storage Technologies is sponsored by USENIX NOVA: A Log-structured File System for Hybrid Volatile/Non-volatile Main Memories Jian Xu Steven Swanson University of California, San Diego Abstract Hybrid DRAM/NVMM storage systems present a host of opportunities and challenges for system designers. These sys- Fast non-volatile memories (NVMs) will soon appear on tems need to minimize software overhead if they are to fully the processor memory bus alongside DRAM. The result- exploit NVMM’s high performance and efficiently support ing hybrid memory systems will provide software with sub- more flexible access patterns, and at the same time they must microsecond, high-bandwidth access to persistent data, but provide the strong consistency guarantees that applications managing, accessing, and maintaining consistency for data require and respect the limitations of emerging memories stored in NVM raises a host of challenges. Existing file sys- (e.g., limited program cycles). tems built for spinning or solid-state disks introduce software Conventional file systems are not suitable for hybrid mem- overheads that would obscure the performance that NVMs ory systems because they are built for the performance char- should provide, but proposed file systems for NVMs either in- acteristics of disks (spinning or solid state) and rely on disks’ cur similar overheads or fail to provide the strong consistency consistency guarantees (e.g., that sector updates are atomic) guarantees that applications require. -

Linux Kernal II 9.1 Architecture
Page 1 of 7 Linux Kernal II 9.1 Architecture: The Linux kernel is a Unix-like operating system kernel used by a variety of operating systems based on it, which are usually in the form of Linux distributions. The Linux kernel is a prominent example of free and open source software. Programming language The Linux kernel is written in the version of the C programming language supported by GCC (which has introduced a number of extensions and changes to standard C), together with a number of short sections of code written in the assembly language (in GCC's "AT&T-style" syntax) of the target architecture. Because of the extensions to C it supports, GCC was for a long time the only compiler capable of correctly building the Linux kernel. Compiler compatibility GCC is the default compiler for the Linux kernel source. In 2004, Intel claimed to have modified the kernel so that its C compiler also was capable of compiling it. There was another such reported success in 2009 with a modified 2.6.22 version of the kernel. Since 2010, effort has been underway to build the Linux kernel with Clang, an alternative compiler for the C language; as of 12 April 2014, the official kernel could almost be compiled by Clang. The project dedicated to this effort is named LLVMLinxu after the LLVM compiler infrastructure upon which Clang is built. LLVMLinux does not aim to fork either the Linux kernel or the LLVM, therefore it is a meta-project composed of patches that are eventually submitted to the upstream projects. -

Firecracker: Lightweight Virtualization for Serverless Applications
Firecracker: Lightweight Virtualization for Serverless Applications Alexandru Agache, Marc Brooker, Andreea Florescu, Alexandra Iordache, Anthony Liguori, Rolf Neugebauer, Phil Piwonka, and Diana-Maria Popa, Amazon Web Services https://www.usenix.org/conference/nsdi20/presentation/agache This paper is included in the Proceedings of the 17th USENIX Symposium on Networked Systems Design and Implementation (NSDI ’20) February 25–27, 2020 • Santa Clara, CA, USA 978-1-939133-13-7 Open access to the Proceedings of the 17th USENIX Symposium on Networked Systems Design and Implementation (NSDI ’20) is sponsored by Firecracker: Lightweight Virtualization for Serverless Applications Alexandru Agache Marc Brooker Andreea Florescu Amazon Web Services Amazon Web Services Amazon Web Services Alexandra Iordache Anthony Liguori Rolf Neugebauer Amazon Web Services Amazon Web Services Amazon Web Services Phil Piwonka Diana-Maria Popa Amazon Web Services Amazon Web Services Abstract vantage over traditional server provisioning processes: mul- titenancy allows servers to be shared across a large num- Serverless containers and functions are widely used for de- ber of workloads, and the ability to provision new func- ploying and managing software in the cloud. Their popularity tions and containers in milliseconds allows capacity to be is due to reduced cost of operations, improved utilization of switched between workloads quickly as demand changes. hardware, and faster scaling than traditional deployment meth- Serverless is also attracting the attention of the research com- ods. The economics and scale of serverless applications de- munity [21,26,27,44,47], including work on scaling out video mand that workloads from multiple customers run on the same encoding [13], linear algebra [20, 53] and parallel compila- hardware with minimal overhead, while preserving strong se- tion [12]. -

A Linux Kernel Scheduler Extension for Multi-Core Systems
A Linux Kernel Scheduler Extension For Multi-Core Systems Aleix Roca Nonell Master in Innovation and Research in Informatics (MIRI) specialized in High Performance Computing (HPC) Facultat d’informàtica de Barcelona (FIB) Universitat Politècnica de Catalunya Supervisor: Vicenç Beltran Querol Cosupervisor: Eduard Ayguadé Parra Presentation date: 25 October 2017 Abstract The Linux Kernel OS is a black box from the user-space point of view. In most cases, this is not a problem. However, for parallel high performance computing applications it can be a limitation. Such applications usually execute on top of a runtime system, itself executing on top of a general purpose kernel. Current runtime systems take care of getting the most of each system core by distributing work among the multiple CPUs of a machine but they are not aware of when one of their threads perform blocking calls (e.g. I/O operations). When such a blocking call happens, the processing core is stalled, leading to performance loss. In this thesis, it is presented the proof-of-concept of a Linux kernel extension denoted User Monitored Threads (UMT). The extension allows a user-space application to be notified of the blocking and unblocking of its threads, making it possible for a core to execute another worker thread while the other is blocked. An existing runtime system (namely Nanos6) is adapted, so that it takes advantage of the kernel extension. The whole prototype is tested on a synthetic benchmarks and an industry mock-up application. The analysis of the results shows, on the tested hardware and the appropriate conditions, a significant speedup improvement. -

KVM/ARM: Experiences Building the Linux ARM Hypervisor
KVM/ARM: Experiences Building the Linux ARM Hypervisor Christoffer Dall and Jason Nieh fcdall, [email protected] Department of Computer Science, Columbia University Technical Report CUCS-010-13 April 2013 Abstract ization. To address this problem, ARM has introduced hardware virtualization extensions in the newest ARM As ARM CPUs become increasingly common in mo- CPU architectures. ARM has benefited from the hind- bile devices and servers, there is a growing demand sight of x86 in its design. For example, nested page for providing the benefits of virtualization for ARM- tables, not part of the original x86 virtualization hard- based devices. We present our experiences building the ware, are standard in ARM. However, there are impor- Linux ARM hypervisor, KVM/ARM, the first full sys- tant differences between ARM and x86 virtualization ex- tem ARM virtualization solution that can run unmodified tensions such that x86 hypervisor designs may not be guest operating systems on ARM multicore hardware. directly amenable to ARM. These differences may also KVM/ARM introduces split-mode virtualization, allow- impact hypervisor performance, especially for multicore ing a hypervisor to split its execution across CPU modes systems, but have not been evaluated with real hardware. to take advantage of CPU mode-specific features. This allows KVM/ARM to leverage Linux kernel services and We describe our experiences building KVM/ARM, functionality to simplify hypervisor development and the ARM hypervisor in the mainline Linux kernel. maintainability while utilizing recent ARM hardware KVM/ARM is the first hypervisor to leverage ARM virtualization extensions to run application workloads in hardware virtualization support to run unmodified guest guest operating systems with comparable performance operating systems (OSes) on ARM multicore hardware. -

SUSE Linux Enterprise Server 15 SP2 Autoyast Guide Autoyast Guide SUSE Linux Enterprise Server 15 SP2
SUSE Linux Enterprise Server 15 SP2 AutoYaST Guide AutoYaST Guide SUSE Linux Enterprise Server 15 SP2 AutoYaST is a system for unattended mass deployment of SUSE Linux Enterprise Server systems. AutoYaST installations are performed using an AutoYaST control le (also called a “prole”) with your customized installation and conguration data. Publication Date: September 24, 2021 SUSE LLC 1800 South Novell Place Provo, UT 84606 USA https://documentation.suse.com Copyright © 2006– 2021 SUSE LLC and contributors. All rights reserved. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.2 or (at your option) version 1.3; with the Invariant Section being this copyright notice and license. A copy of the license version 1.2 is included in the section entitled “GNU Free Documentation License”. For SUSE trademarks, see https://www.suse.com/company/legal/ . All other third-party trademarks are the property of their respective owners. Trademark symbols (®, ™ etc.) denote trademarks of SUSE and its aliates. Asterisks (*) denote third-party trademarks. All information found in this book has been compiled with utmost attention to detail. However, this does not guarantee complete accuracy. Neither SUSE LLC, its aliates, the authors nor the translators shall be held liable for possible errors or the consequences thereof. Contents 1 Introduction to AutoYaST 1 1.1 Motivation 1 1.2 Overview and Concept 1 I UNDERSTANDING AND CREATING THE AUTOYAST CONTROL FILE 4 2 The AutoYaST Control -
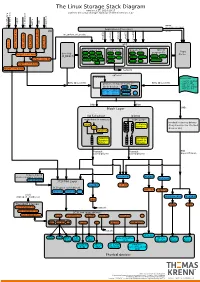
The Linux Storage Stack Diagram
The Linux Storage Stack Diagram version 3.17, 2014-10-17 outlines the Linux storage stack as of Kernel version 3.17 ISCSI USB mmap Fibre Channel Fibre over Ethernet Fibre Channel Fibre Virtual Host Virtual FireWire (anonymous pages) Applications (Processes) LIO malloc vfs_writev, vfs_readv, ... ... stat(2) read(2) open(2) write(2) chmod(2) VFS tcm_fc sbp_target tcm_usb_gadget tcm_vhost tcm_qla2xxx iscsi_target_mod block based FS Network FS pseudo FS special Page ext2 ext3 ext4 proc purpose FS target_core_mod direct I/O NFS coda sysfs Cache (O_DIRECT) xfs btrfs tmpfs ifs smbfs ... pipefs futexfs ramfs target_core_file iso9660 gfs ocfs ... devtmpfs ... ceph usbfs target_core_iblock target_core_pscsi network optional stackable struct bio - sector on disk BIOs (Block I/O) BIOs (Block I/O) - sector cnt devices on top of “normal” - bio_vec cnt block devices drbd LVM - bio_vec index - bio_vec list device mapper mdraid dm-crypt dm-mirror ... dm-cache dm-thin bcache BIOs BIOs Block Layer BIOs I/O Scheduler blkmq maps bios to requests multi queue hooked in device drivers noop Software (they hook in like stacked ... Queues cfq devices do) deadline Hardware Hardware Dispatch ... Dispatch Queue Queues Request Request BIO based Drivers based Drivers based Drivers request-based device mapper targets /dev/nullb* /dev/vd* /dev/rssd* dm-multipath SCSI Mid Layer /dev/rbd* null_blk SCSI upper level drivers virtio_blk mtip32xx /dev/sda /dev/sdb ... sysfs (transport attributes) /dev/nvme#n# /dev/skd* rbd Transport Classes nvme skd scsi_transport_fc network -

Effective Cache Apportioning for Performance Isolation Under
Effective Cache Apportioning for Performance Isolation Under Compiler Guidance Bodhisatwa Chatterjee Sharjeel Khan Georgia Institute of Technology Georgia Institute of Technology Atlanta, USA Atlanta, USA [email protected] [email protected] Santosh Pande Georgia Institute of Technology Atlanta, USA [email protected] Abstract cache partitioning to divide the LLC among the co-executing With a growing number of cores per socket in modern data- applications in the system. Ideally, a cache partitioning centers where multi-tenancy of a diverse set of applications scheme obtains overall gains in system performance by pro- must be efficiently supported, effective sharing of the last viding a dedicated region of cache memory to high-priority level cache is a very important problem. This is challenging cache-intensive applications and ensures security against because modern workloads exhibit dynamic phase behaviour cache-sharing attacks by the notion of isolated execution in - their cache requirements & sensitivity vary across different an otherwise shared LLC. Apart from achieving superior execution points. To tackle this problem, we propose Com- application performance and improving system throughput CAS, a compiler guided cache apportioning system that pro- [7, 20, 31], cache partitioning can also serve a variety of pur- vides smart cache allocation to co-executing applications in a poses - improving system power and energy consumption system. The front-end of Com-CAS is primarily a compiler- [6, 23], ensuring fairness in resource allocation [26, 36] and framework equipped with learning mechanisms to predict even enabling worst case execution-time analysis of real-time cache requirements, while the backend consists of allocation systems [18]. -

Embedded Linux Conference Europe 2019
Embedded Linux Conference Europe 2019 Linux kernel debugging: going beyond printk messages Embedded Labworks By Sergio Prado. São Paulo, October 2019 ® Copyright Embedded Labworks 2004-2019. All rights reserved. Embedded Labworks ABOUT THIS DOCUMENT ✗ This document is available under Creative Commons BY- SA 4.0. https://creativecommons.org/licenses/by-sa/4.0/ ✗ The source code of this document is available at: https://e-labworks.com/talks/elce2019 Embedded Labworks $ WHOAMI ✗ Embedded software developer for more than 20 years. ✗ Principal Engineer of Embedded Labworks, a company specialized in the development of software projects and BSPs for embedded systems. https://e-labworks.com/en/ ✗ Active in the embedded systems community in Brazil, creator of the website Embarcados and blogger (Portuguese language). https://sergioprado.org ✗ Contributor of several open source projects, including Buildroot, Yocto Project and the Linux kernel. Embedded Labworks THIS TALK IS NOT ABOUT... ✗ printk and all related functions and features (pr_ and dev_ family of functions, dynamic debug, etc). ✗ Static analysis tools and fuzzing (sparse, smatch, coccinelle, coverity, trinity, syzkaller, syzbot, etc). ✗ User space debugging. ✗ This is also not a tutorial! We will talk about a lot of tools and techniches and have fun with some demos! Embedded Labworks DEBUGGING STEP-BY-STEP 1. Understand the problem. 2. Reproduce the problem. 3. Identify the source of the problem. 4. Fix the problem. 5. Fixed? If so, celebrate! If not, go back to step 1. Embedded Labworks TYPES OF PROBLEMS ✗ We can consider as the top 5 types of problems in software: ✗ Crash. ✗ Lockup. ✗ Logic/implementation error. ✗ Resource leak. ✗ Performance.