Geometric Approach to Statistical Analysis on the Simplex
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Higher Dimensional Conundra
Higher Dimensional Conundra Steven G. Krantz1 Abstract: In recent years, especially in the subject of harmonic analysis, there has been interest in geometric phenomena of RN as N → +∞. In the present paper we examine several spe- cific geometric phenomena in Euclidean space and calculate the asymptotics as the dimension gets large. 0 Introduction Typically when we do geometry we concentrate on a specific venue in a particular space. Often the context is Euclidean space, and often the work is done in R2 or R3. But in modern work there are many aspects of analysis that are linked to concrete aspects of geometry. And there is often interest in rendering the ideas in Hilbert space or some other infinite dimensional setting. Thus we want to see how the finite-dimensional result in RN changes as N → +∞. In the present paper we study some particular aspects of the geometry of RN and their asymptotic behavior as N →∞. We choose these particular examples because the results are surprising or especially interesting. We may hope that they will lead to further studies. It is a pleasure to thank Richard W. Cottle for a careful reading of an early draft of this paper and for useful comments. 1 Volume in RN Let us begin by calculating the volume of the unit ball in RN and the surface area of its bounding unit sphere. We let ΩN denote the former and ωN−1 denote the latter. In addition, we let Γ(x) be the celebrated Gamma function of L. Euler. It is a helpful intuition (which is literally true when x is an 1We are happy to thank the American Institute of Mathematics for its hospitality and support during this work. -
Properties of Euclidean Space
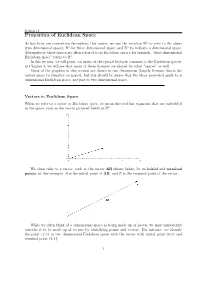
Section 3.1 Properties of Euclidean Space As has been our convention throughout this course, we use the notation R2 to refer to the plane (two dimensional space); R3 for three dimensional space; and Rn to indicate n dimensional space. Alternatively, these spaces are often referred to as Euclidean spaces; for example, \three dimensional Euclidean space" refers to R3. In this section, we will point out many of the special features common to the Euclidean spaces; in Chapter 4, we will see that many of these features are shared by other \spaces" as well. Many of the graphics in this section are drawn in two dimensions (largely because this is the easiest space to visualize on paper), but you should be aware that the ideas presented apply to n dimensional Euclidean space, not just to two dimensional space. Vectors in Euclidean Space When we refer to a vector in Euclidean space, we mean directed line segments that are embedded in the space, such as the vector pictured below in R2: We often refer to a vector, such as the vector AB shown below, by its initial and terminal points; in this example, A is the initial point of AB, and B is the terminal point of the vector. While we often think of n dimensional space as being made up of points, we may equivalently consider it to be made up of vectors by identifying points and vectors. For instance, we identify the point (2; 1) in two dimensional Euclidean space with the vector with initial point (0; 0) and terminal point (2; 1): 1 Section 3.1 In this way, we think of n dimensional Euclidean space as being made up of n dimensional vectors. -

About Symmetries in Physics
LYCEN 9754 December 1997 ABOUT SYMMETRIES IN PHYSICS Dedicated to H. Reeh and R. Stora1 Fran¸cois Gieres Institut de Physique Nucl´eaire de Lyon, IN2P3/CNRS, Universit´eClaude Bernard 43, boulevard du 11 novembre 1918, F - 69622 - Villeurbanne CEDEX Abstract. The goal of this introduction to symmetries is to present some general ideas, to outline the fundamental concepts and results of the subject and to situate a bit the following arXiv:hep-th/9712154v1 16 Dec 1997 lectures of this school. [These notes represent the write-up of a lecture presented at the fifth S´eminaire Rhodanien de Physique “Sur les Sym´etries en Physique” held at Dolomieu (France), 17-21 March 1997. Up to the appendix and the graphics, it is to be published in Symmetries in Physics, F. Gieres, M. Kibler, C. Lucchesi and O. Piguet, eds. (Editions Fronti`eres, 1998).] 1I wish to dedicate these notes to my diploma and Ph.D. supervisors H. Reeh and R. Stora who devoted a major part of their scientific work to the understanding, description and explo- ration of symmetries in physics. Contents 1 Introduction ................................................... .......1 2 Symmetries of geometric objects ...................................2 3 Symmetries of the laws of nature ..................................5 1 Geometric (space-time) symmetries .............................6 2 Internal symmetries .............................................10 3 From global to local symmetries ...............................11 4 Combining geometric and internal symmetries ...............14 -

A Partition Property of Simplices in Euclidean Space
JOURNAL OF THE AMERICAN MATHEMATICAL SOCIETY Volume 3, Number I, January 1990 A PARTITION PROPERTY OF SIMPLICES IN EUCLIDEAN SPACE P. FRANKL AND V. RODL 1. INTRODUCTION AND STATEMENT OF THE RESULTS Let ]Rn denote n-dimensional Euclidean space endowed with the standard metric. For x, y E ]Rn , their distance is denoted by Ix - yl. Definition 1.1 [E]. A subset B of ]Rd is called Ramsey if for every r ~ 2 there exists some n = n(r, B) with the following partition property. For every partition ]Rn = V; u ... U ~ , there exists some j, 1::::; j ::::; r, and Bj C fj such that B is congruent to Bj • In a series of papers, Erdos et al. [E] have investigated this property. They have shown that all Ramsey sets are spherical, that is, every Ramsey set is con- tained in an appropriate sphere. On the other hand, they have shown that the vertex set (and, therefore, all its subsets) of bricks (d-dimensional paral- lelepipeds) is Ramsey. The simplest sets that are spherical but cannot be embedded into the vertex set of a brick are the sets of obtuse triangles. In [FR 1], it is shown that they are indeed Ramsey, using Ramsey's Theorem (cf. [G2]) and the Product Theorem of [E]. The aim of the present paper is twofold. First, we want to show that the vertex set of every nondegenerate simplex in any dimension is Ramsey. Second, we want to show that for both simplices and bricks, and even for their products, one can in fact choose n(r, B) = c(B)logr, where c(B) is an appropriate positive constant. -

Euclidean Space - Wikipedia, the Free Encyclopedia Page 1 of 5
Euclidean space - Wikipedia, the free encyclopedia Page 1 of 5 Euclidean space From Wikipedia, the free encyclopedia In mathematics, Euclidean space is the Euclidean plane and three-dimensional space of Euclidean geometry, as well as the generalizations of these notions to higher dimensions. The term “Euclidean” distinguishes these spaces from the curved spaces of non-Euclidean geometry and Einstein's general theory of relativity, and is named for the Greek mathematician Euclid of Alexandria. Classical Greek geometry defined the Euclidean plane and Euclidean three-dimensional space using certain postulates, while the other properties of these spaces were deduced as theorems. In modern mathematics, it is more common to define Euclidean space using Cartesian coordinates and the ideas of analytic geometry. This approach brings the tools of algebra and calculus to bear on questions of geometry, and Every point in three-dimensional has the advantage that it generalizes easily to Euclidean Euclidean space is determined by three spaces of more than three dimensions. coordinates. From the modern viewpoint, there is essentially only one Euclidean space of each dimension. In dimension one this is the real line; in dimension two it is the Cartesian plane; and in higher dimensions it is the real coordinate space with three or more real number coordinates. Thus a point in Euclidean space is a tuple of real numbers, and distances are defined using the Euclidean distance formula. Mathematicians often denote the n-dimensional Euclidean space by , or sometimes if they wish to emphasize its Euclidean nature. Euclidean spaces have finite dimension. Contents 1 Intuitive overview 2 Real coordinate space 3 Euclidean structure 4 Topology of Euclidean space 5 Generalizations 6 See also 7 References Intuitive overview One way to think of the Euclidean plane is as a set of points satisfying certain relationships, expressible in terms of distance and angle. -
![Arxiv:1704.03334V1 [Physics.Gen-Ph] 8 Apr 2017 Oin Ffltsaeadtime](https://docslib.b-cdn.net/cover/3310/arxiv-1704-03334v1-physics-gen-ph-8-apr-2017-oin-f-tsaeadtime-1063310.webp)
Arxiv:1704.03334V1 [Physics.Gen-Ph] 8 Apr 2017 Oin Ffltsaeadtime
WHAT DO WE KNOW ABOUT THE GEOMETRY OF SPACE? B. E. EICHINGER Department of Chemistry, University of Washington, Seattle, Washington 98195-1700 Abstract. The belief that three dimensional space is infinite and flat in the absence of matter is a canon of physics that has been in place since the time of Newton. The assumption that space is flat at infinity has guided several modern physical theories. But what do we actually know to support this belief? A simple argument, called the ”Telescope Principle”, asserts that all that we can know about space is bounded by observations. Physical theories are best when they can be verified by observations, and that should also apply to the geometry of space. The Telescope Principle is simple to state, but it leads to very interesting insights into relativity and Yang-Mills theory via projective equivalences of their respective spaces. 1. Newton and the Euclidean Background Newton asserted the existence of an Absolute Space which is infinite, three dimensional, and Euclidean.[1] This is a remarkable statement. How could Newton know anything about the nature of space at infinity? Obviously, he could not know what space is like at infinity, so what motivated this assertion (apart from Newton’s desire to make space the sensorium of an infinite God)? Perhaps it was that the geometric tools available to him at the time were restricted to the principles of Euclidean plane geometry and its extension to three dimensions, in which infinite space is inferred from the parallel postulate. Given these limited mathematical resources, there was really no other choice than Euclid for a description of the geometry of space within which to formulate a theory of motion of material bodies. -

A CONCISE MINI HISTORY of GEOMETRY 1. Origin And
Kragujevac Journal of Mathematics Volume 38(1) (2014), Pages 5{21. A CONCISE MINI HISTORY OF GEOMETRY LEOPOLD VERSTRAELEN 1. Origin and development in Old Greece Mathematics was the crowning and lasting achievement of the ancient Greek cul- ture. To more or less extent, arithmetical and geometrical problems had been ex- plored already before, in several previous civilisations at various parts of the world, within a kind of practical mathematical scientific context. The knowledge which in particular as such first had been acquired in Mesopotamia and later on in Egypt, and the philosophical reflections on its meaning and its nature by \the Old Greeks", resulted in the sublime creation of mathematics as a characteristically abstract and deductive science. The name for this science, \mathematics", stems from the Greek language, and basically means \knowledge and understanding", and became of use in most other languages as well; realising however that, as a matter of fact, it is really an art to reach new knowledge and better understanding, the Dutch term for mathematics, \wiskunde", in translation: \the art to achieve wisdom", might be even more appropriate. For specimens of the human kind, \nature" essentially stands for their organised thoughts about sensations and perceptions of \their worlds outside and inside" and \doing mathematics" basically stands for their thoughtful living in \the universe" of their idealisations and abstractions of these sensations and perceptions. Or, as Stewart stated in the revised book \What is Mathematics?" of Courant and Robbins: \Mathematics links the abstract world of mental concepts to the real world of physical things without being located completely in either". -

Basics of Euclidean Geometry
This is page 162 Printer: Opaque this 6 Basics of Euclidean Geometry Rien n'est beau que le vrai. |Hermann Minkowski 6.1 Inner Products, Euclidean Spaces In a±ne geometry it is possible to deal with ratios of vectors and barycen- ters of points, but there is no way to express the notion of length of a line segment or to talk about orthogonality of vectors. A Euclidean structure allows us to deal with metric notions such as orthogonality and length (or distance). This chapter and the next two cover the bare bones of Euclidean ge- ometry. One of our main goals is to give the basic properties of the transformations that preserve the Euclidean structure, rotations and re- ections, since they play an important role in practice. As a±ne geometry is the study of properties invariant under bijective a±ne maps and projec- tive geometry is the study of properties invariant under bijective projective maps, Euclidean geometry is the study of properties invariant under certain a±ne maps called rigid motions. Rigid motions are the maps that preserve the distance between points. Such maps are, in fact, a±ne and bijective (at least in the ¯nite{dimensional case; see Lemma 7.4.3). They form a group Is(n) of a±ne maps whose corresponding linear maps form the group O(n) of orthogonal transformations. The subgroup SE(n) of Is(n) corresponds to the orientation{preserving rigid motions, and there is a corresponding 6.1. Inner Products, Euclidean Spaces 163 subgroup SO(n) of O(n), the group of rotations. -

Chapter 1 Euclidean Space
Euclidean space 1 Chapter 1 Euclidean space A. The basic vector space We shall denote by R the ¯eld of real numbers. Then we shall use the Cartesian product Rn = R £ R £ ::: £ R of ordered n-tuples of real numbers (n factors). Typical notation for x 2 Rn will be x = (x1; x2; : : : ; xn): Here x is called a point or a vector, and x1, x2; : : : ; xn are called the coordinates of x. The natural number n is called the dimension of the space. Often when speaking about Rn and its vectors, real numbers are called scalars. Special notations: R1 x 2 R x = (x1; x2) or p = (x; y) 3 R x = (x1; x2; x3) or p = (x; y; z): We like to draw pictures when n = 1, 2, 3; e.g. the point (¡1; 3; 2) might be depicted as 2 Chapter 1 We de¯ne algebraic operations as follows: for x, y 2 Rn and a 2 R, x + y = (x1 + y1; x2 + y2; : : : ; xn + yn); ax = (ax1; ax2; : : : ; axn); ¡x = (¡1)x = (¡x1; ¡x2;:::; ¡xn); x ¡ y = x + (¡y) = (x1 ¡ y1; x2 ¡ y2; : : : ; xn ¡ yn): We also de¯ne the origin (a/k/a the point zero) 0 = (0; 0;:::; 0): (Notice that 0 on the left side is a vector, though we use the same notation as for the scalar 0.) Then we have the easy facts: x + y = y + x; (x + y) + z = x + (y + z); 0 + x = x; in other words all the x ¡ x = 0; \usual" algebraic rules 1x = x; are valid if they make (ab)x = a(bx); sense a(x + y) = ax + ay; (a + b)x = ax + bx; 0x = 0; a0 = 0: Schematic pictures can be very helpful. -

Johnson-Lindenstrauss Dimensionality Reduction on the Simplex
Dimensionality Reduction on the Simplex Rasmus J. Kyng Jeff M. Phillips Suresh Venkatasubramanian Abstract For many problems in data analysis, the natural way to model objects is as a probability distribution over a finite and discrete domain. Probability distributions over such domains can be represented as points on a (high-dimensional) simplex, and thus many inference questions involving distributions can be viewed geometrically as manipulating points on a simplex. The dimensionality of these points makes analysis difficult, and thus a key goal is to reduce the dimensionality of the data while still preserving the distributional structure. In this paper, we propose an algorithm for dimensionality reduction on the simplex,mapping a set of high-dimensional distributions to a space of lower-dimensional distributions, whilst approximately preserving the pairwise Hellinger distance between distributions. By introducing a restriction on the input data to distributions that are in some sense quite smooth, we can map n points on the d-simplex to the simplex of O(e−2 logn) dimensions with e-distortion with high probability. Our techniques rely on classical Johnson and Lindenstrauss dimensionality reduction methods for Euclidean point sets and require the same number of random bits as non-sparse methods proposed by Achlioptas for database-friendly dimensionality reduction. 1 Introduction In many applications, data is represented natively not as a vector in a normed space, but as a distribution over a finite and discrete support. A document (or even a topic) is represented as a distribution over words [27, 21, 9], an image is represented as distribution over scale-invariant fingerprints [25, 12], and audio signals are represented as distributions over frequencies [16]. -

A Geometric Introduction to Spacetime and Special Relativity
A GEOMETRIC INTRODUCTION TO SPACETIME AND SPECIAL RELATIVITY. WILLIAM K. ZIEMER Abstract. A narrative of special relativity meant for graduate students in mathematics or physics. The presentation builds upon the geometry of space- time; not the explicit axioms of Einstein, which are consequences of the geom- etry. 1. Introduction Einstein was deeply intuitive, and used many thought experiments to derive the behavior of relativity. Most introductions to special relativity follow this path; taking the reader down the same road Einstein travelled, using his axioms and modifying Newtonian physics. The problem with this approach is that the reader falls into the same pits that Einstein fell into. There is a large difference in the way Einstein approached relativity in 1905 versus 1912. I will use the 1912 version, a geometric spacetime approach, where the differences between Newtonian physics and relativity are encoded into the geometry of how space and time are modeled. I believe that understanding the differences in the underlying geometries gives a more direct path to understanding relativity. Comparing Newtonian physics with relativity (the physics of Einstein), there is essentially one difference in their basic axioms, but they have far-reaching im- plications in how the theories describe the rules by which the world works. The difference is the treatment of time. The question, \Which is farther away from you: a ball 1 foot away from your hand right now, or a ball that is in your hand 1 minute from now?" has no answer in Newtonian physics, since there is no mechanism for contrasting spatial distance with temporal distance. -

Euclidean Space Rn
Tel Aviv University, 2014/15 Analysis-III,IV 1 1 Euclidean space Rn 1a Prerequisites . 1 n 1b Structures on R and their isomorphisms . 5 1c Metric and topology . 20 1d Linearity and continuity . 25 1e Norms of vectors and operators . 26 The n-dimensional space Rn may be treated as a Euclidean space, or just a vector space, etc. Its topology is uniquely determined by algebraic structure. 1a Prerequisites linear algebra You should know the notion of: Forgot? Then see: Vector space (=linear space) [Sh:p.26 \Vector space axioms"] Isomorphism of vector spaces: a linear bijection. Basis of a vector space [Sh:Def.2.1.2 on p.28] Dimension of a finite-dimensional vector space: the number of vectors in every basis. Two finite-dimensional vector spaces are isomorphic if and only if their di- mensions are equal. Subspace of a vector space. Linear operator (=mapping=function) between vector spaces [Sh:3.1] Inner product on a vector space: hx; yi [Sh:p.31 \Inner product properties"] A basis of a subspace, being a linearly independent system, can be extended to a basis of the whole finite-dimensional vector space. topology You should know the notion of: Forgot? Then see: A sequence of points of Rn [Sh:p.36]1 Its convergence, limit [Sh:p.42{43] 1Quote: The only obstacle . is notation . n already denotes the dimension of the Euclidean space where we are working; and furthermore, the vectors can't be denoted with subscripts since a subscript denotes a component of an individual vector. As our work with vectors becomes more intrinsic, vector entries will demand less of our attention, and Tel Aviv University, 2014/15 Analysis-III,IV 2 Mapping Rn ! Rm; continuity (at a point; on a set) [Sh:p.41{48] Subsequence; Bolzano-Weierstrass theorem [Sh:p.52{53] Subset of Rn, its limit points; closed set; bounded set [Sh:p.51] Compact set [Sh:p.54] Open set [Sh:p.191]1 Closure, boundary, interior [Sh:p.311,314] Open cover; Heine-Borel theorem [Sh:p.312] Open ball, closed ball, sphere [Sh:p.50,191{192] Open box, closed box [Sh:p.246] [Sh:Exer.