Johnson-Lindenstrauss Dimensionality Reduction on the Simplex
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

1 Lifts of Polytopes
Lecture 5: Lifts of polytopes and non-negative rank CSE 599S: Entropy optimality, Winter 2016 Instructor: James R. Lee Last updated: January 24, 2016 1 Lifts of polytopes 1.1 Polytopes and inequalities Recall that the convex hull of a subset X n is defined by ⊆ conv X λx + 1 λ x0 : x; x0 X; λ 0; 1 : ( ) f ( − ) 2 2 [ ]g A d-dimensional convex polytope P d is the convex hull of a finite set of points in d: ⊆ P conv x1;:::; xk (f g) d for some x1;:::; xk . 2 Every polytope has a dual representation: It is a closed and bounded set defined by a family of linear inequalities P x d : Ax 6 b f 2 g for some matrix A m d. 2 × Let us define a measure of complexity for P: Define γ P to be the smallest number m such that for some C s d ; y s ; A m d ; b m, we have ( ) 2 × 2 2 × 2 P x d : Cx y and Ax 6 b : f 2 g In other words, this is the minimum number of inequalities needed to describe P. If P is full- dimensional, then this is precisely the number of facets of P (a facet is a maximal proper face of P). Thinking of γ P as a measure of complexity makes sense from the point of view of optimization: Interior point( methods) can efficiently optimize linear functions over P (to arbitrary accuracy) in time that is polynomial in γ P . ( ) 1.2 Lifts of polytopes Many simple polytopes require a large number of inequalities to describe. -

Simplicial Complexes
46 III Complexes III.1 Simplicial Complexes There are many ways to represent a topological space, one being a collection of simplices that are glued to each other in a structured manner. Such a collection can easily grow large but all its elements are simple. This is not so convenient for hand-calculations but close to ideal for computer implementations. In this book, we use simplicial complexes as the primary representation of topology. Rd k Simplices. Let u0; u1; : : : ; uk be points in . A point x = i=0 λiui is an affine combination of the ui if the λi sum to 1. The affine hull is the set of affine combinations. It is a k-plane if the k + 1 points are affinely Pindependent by which we mean that any two affine combinations, x = λiui and y = µiui, are the same iff λi = µi for all i. The k + 1 points are affinely independent iff P d P the k vectors ui − u0, for 1 ≤ i ≤ k, are linearly independent. In R we can have at most d linearly independent vectors and therefore at most d+1 affinely independent points. An affine combination x = λiui is a convex combination if all λi are non- negative. The convex hull is the set of convex combinations. A k-simplex is the P convex hull of k + 1 affinely independent points, σ = conv fu0; u1; : : : ; ukg. We sometimes say the ui span σ. Its dimension is dim σ = k. We use special names of the first few dimensions, vertex for 0-simplex, edge for 1-simplex, triangle for 2-simplex, and tetrahedron for 3-simplex; see Figure III.1. -

Degrees of Freedom in Quadratic Goodness of Fit
Submitted to the Annals of Statistics DEGREES OF FREEDOM IN QUADRATIC GOODNESS OF FIT By Bruce G. Lindsay∗, Marianthi Markatouy and Surajit Ray Pennsylvania State University, Columbia University, Boston University We study the effect of degrees of freedom on the level and power of quadratic distance based tests. The concept of an eigendepth index is introduced and discussed in the context of selecting the optimal de- grees of freedom, where optimality refers to high power. We introduce the class of diffusion kernels by the properties we seek these kernels to have and give a method for constructing them by exponentiating the rate matrix of a Markov chain. Product kernels and their spectral decomposition are discussed and shown useful for high dimensional data problems. 1. Introduction. Lindsay et al. (2008) developed a general theory for good- ness of fit testing based on quadratic distances. This class of tests is enormous, encompassing many of the tests found in the literature. It includes tests based on characteristic functions, density estimation, and the chi-squared tests, as well as providing quadratic approximations to many other tests, such as those based on likelihood ratios. The flexibility of the methodology is particularly important for enabling statisticians to readily construct tests for model fit in higher dimensions and in more complex data. ∗Supported by NSF grant DMS-04-05637 ySupported by NSF grant DMS-05-04957 AMS 2000 subject classifications: Primary 62F99, 62F03; secondary 62H15, 62F05 Keywords and phrases: Degrees of freedom, eigendepth, high dimensional goodness of fit, Markov diffusion kernels, quadratic distance, spectral decomposition in high dimensions 1 2 LINDSAY ET AL. -
![Arxiv:1910.10745V1 [Cond-Mat.Str-El] 23 Oct 2019 2.2 Symmetry-Protected Time Crystals](https://docslib.b-cdn.net/cover/4942/arxiv-1910-10745v1-cond-mat-str-el-23-oct-2019-2-2-symmetry-protected-time-crystals-304942.webp)
Arxiv:1910.10745V1 [Cond-Mat.Str-El] 23 Oct 2019 2.2 Symmetry-Protected Time Crystals
A Brief History of Time Crystals Vedika Khemania,b,∗, Roderich Moessnerc, S. L. Sondhid aDepartment of Physics, Harvard University, Cambridge, Massachusetts 02138, USA bDepartment of Physics, Stanford University, Stanford, California 94305, USA cMax-Planck-Institut f¨urPhysik komplexer Systeme, 01187 Dresden, Germany dDepartment of Physics, Princeton University, Princeton, New Jersey 08544, USA Abstract The idea of breaking time-translation symmetry has fascinated humanity at least since ancient proposals of the per- petuum mobile. Unlike the breaking of other symmetries, such as spatial translation in a crystal or spin rotation in a magnet, time translation symmetry breaking (TTSB) has been tantalisingly elusive. We review this history up to recent developments which have shown that discrete TTSB does takes place in periodically driven (Floquet) systems in the presence of many-body localization (MBL). Such Floquet time-crystals represent a new paradigm in quantum statistical mechanics — that of an intrinsically out-of-equilibrium many-body phase of matter with no equilibrium counterpart. We include a compendium of the necessary background on the statistical mechanics of phase structure in many- body systems, before specializing to a detailed discussion of the nature, and diagnostics, of TTSB. In particular, we provide precise definitions that formalize the notion of a time-crystal as a stable, macroscopic, conservative clock — explaining both the need for a many-body system in the infinite volume limit, and for a lack of net energy absorption or dissipation. Our discussion emphasizes that TTSB in a time-crystal is accompanied by the breaking of a spatial symmetry — so that time-crystals exhibit a novel form of spatiotemporal order. -

THE DIMENSION of a VECTOR SPACE 1. Introduction This Handout
THE DIMENSION OF A VECTOR SPACE KEITH CONRAD 1. Introduction This handout is a supplementary discussion leading up to the definition of dimension of a vector space and some of its properties. We start by defining the span of a finite set of vectors and linear independence of a finite set of vectors, which are combined to define the all-important concept of a basis. Definition 1.1. Let V be a vector space over a field F . For any finite subset fv1; : : : ; vng of V , its span is the set of all of its linear combinations: Span(v1; : : : ; vn) = fc1v1 + ··· + cnvn : ci 2 F g: Example 1.2. In F 3, Span((1; 0; 0); (0; 1; 0)) is the xy-plane in F 3. Example 1.3. If v is a single vector in V then Span(v) = fcv : c 2 F g = F v is the set of scalar multiples of v, which for nonzero v should be thought of geometrically as a line (through the origin, since it includes 0 · v = 0). Since sums of linear combinations are linear combinations and the scalar multiple of a linear combination is a linear combination, Span(v1; : : : ; vn) is a subspace of V . It may not be all of V , of course. Definition 1.4. If fv1; : : : ; vng satisfies Span(fv1; : : : ; vng) = V , that is, if every vector in V is a linear combination from fv1; : : : ; vng, then we say this set spans V or it is a spanning set for V . Example 1.5. In F 2, the set f(1; 0); (0; 1); (1; 1)g is a spanning set of F 2. -

Higher Dimensional Conundra
Higher Dimensional Conundra Steven G. Krantz1 Abstract: In recent years, especially in the subject of harmonic analysis, there has been interest in geometric phenomena of RN as N → +∞. In the present paper we examine several spe- cific geometric phenomena in Euclidean space and calculate the asymptotics as the dimension gets large. 0 Introduction Typically when we do geometry we concentrate on a specific venue in a particular space. Often the context is Euclidean space, and often the work is done in R2 or R3. But in modern work there are many aspects of analysis that are linked to concrete aspects of geometry. And there is often interest in rendering the ideas in Hilbert space or some other infinite dimensional setting. Thus we want to see how the finite-dimensional result in RN changes as N → +∞. In the present paper we study some particular aspects of the geometry of RN and their asymptotic behavior as N →∞. We choose these particular examples because the results are surprising or especially interesting. We may hope that they will lead to further studies. It is a pleasure to thank Richard W. Cottle for a careful reading of an early draft of this paper and for useful comments. 1 Volume in RN Let us begin by calculating the volume of the unit ball in RN and the surface area of its bounding unit sphere. We let ΩN denote the former and ωN−1 denote the latter. In addition, we let Γ(x) be the celebrated Gamma function of L. Euler. It is a helpful intuition (which is literally true when x is an 1We are happy to thank the American Institute of Mathematics for its hospitality and support during this work. -

Linear Algebra Handout
Artificial Intelligence: 6.034 Massachusetts Institute of Technology April 20, 2012 Spring 2012 Recitation 10 Linear Algebra Review • A vector is an ordered list of values. It is often denoted using angle brackets: ha; bi, and its variable name is often written in bold (z) or with an arrow (~z). We can refer to an individual element of a vector using its index: for example, the first element of z would be z1 (or z0, depending on how we're indexing). Each element of a vector generally corresponds to a particular dimension or feature, which could be discrete or continuous; often you can think of a vector as a point in Euclidean space. p 2 2 2 • The magnitude (also called norm) of a vector x = hx1; x2; :::; xni is x1 + x2 + ::: + xn, and is denoted jxj or kxk. • The sum of a set of vectors is their elementwise sum: for example, ha; bi + hc; di = ha + c; b + di (so vectors can only be added if they are the same length). The dot product (also called scalar product) of two vectors is the sum of their elementwise products: for example, ha; bi · hc; di = ac + bd. The dot product x · y is also equal to kxkkyk cos θ, where θ is the angle between x and y. • A matrix is a generalization of a vector: instead of having just one row or one column, it can have m rows and n columns. A square matrix is one that has the same number of rows as columns. A matrix's variable name is generally a capital letter, often written in bold. -
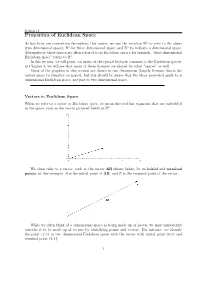
Properties of Euclidean Space
Section 3.1 Properties of Euclidean Space As has been our convention throughout this course, we use the notation R2 to refer to the plane (two dimensional space); R3 for three dimensional space; and Rn to indicate n dimensional space. Alternatively, these spaces are often referred to as Euclidean spaces; for example, \three dimensional Euclidean space" refers to R3. In this section, we will point out many of the special features common to the Euclidean spaces; in Chapter 4, we will see that many of these features are shared by other \spaces" as well. Many of the graphics in this section are drawn in two dimensions (largely because this is the easiest space to visualize on paper), but you should be aware that the ideas presented apply to n dimensional Euclidean space, not just to two dimensional space. Vectors in Euclidean Space When we refer to a vector in Euclidean space, we mean directed line segments that are embedded in the space, such as the vector pictured below in R2: We often refer to a vector, such as the vector AB shown below, by its initial and terminal points; in this example, A is the initial point of AB, and B is the terminal point of the vector. While we often think of n dimensional space as being made up of points, we may equivalently consider it to be made up of vectors by identifying points and vectors. For instance, we identify the point (2; 1) in two dimensional Euclidean space with the vector with initial point (0; 0) and terminal point (2; 1): 1 Section 3.1 In this way, we think of n dimensional Euclidean space as being made up of n dimensional vectors. -

The Simplex Algorithm in Dimension Three1
The Simplex Algorithm in Dimension Three1 Volker Kaibel2 Rafael Mechtel3 Micha Sharir4 G¨unter M. Ziegler3 Abstract We investigate the worst-case behavior of the simplex algorithm on linear pro- grams with 3 variables, that is, on 3-dimensional simple polytopes. Among the pivot rules that we consider, the “random edge” rule yields the best asymptotic behavior as well as the most complicated analysis. All other rules turn out to be much easier to study, but also produce worse results: Most of them show essentially worst-possible behavior; this includes both Kalai’s “random-facet” rule, which is known to be subexponential without dimension restriction, as well as Zadeh’s de- terministic history-dependent rule, for which no non-polynomial instances in general dimensions have been found so far. 1 Introduction The simplex algorithm is a fascinating method for at least three reasons: For computa- tional purposes it is still the most efficient general tool for solving linear programs, from a complexity point of view it is the most promising candidate for a strongly polynomial time linear programming algorithm, and last but not least, geometers are pleased by its inherent use of the structure of convex polytopes. The essence of the method can be described geometrically: Given a convex polytope P by means of inequalities, a linear functional ϕ “in general position,” and some vertex vstart, 1Work on this paper by Micha Sharir was supported by NSF Grants CCR-97-32101 and CCR-00- 98246, by a grant from the U.S.-Israeli Binational Science Foundation, by a grant from the Israel Science Fund (for a Center of Excellence in Geometric Computing), and by the Hermann Minkowski–MINERVA Center for Geometry at Tel Aviv University. -

About Symmetries in Physics
LYCEN 9754 December 1997 ABOUT SYMMETRIES IN PHYSICS Dedicated to H. Reeh and R. Stora1 Fran¸cois Gieres Institut de Physique Nucl´eaire de Lyon, IN2P3/CNRS, Universit´eClaude Bernard 43, boulevard du 11 novembre 1918, F - 69622 - Villeurbanne CEDEX Abstract. The goal of this introduction to symmetries is to present some general ideas, to outline the fundamental concepts and results of the subject and to situate a bit the following arXiv:hep-th/9712154v1 16 Dec 1997 lectures of this school. [These notes represent the write-up of a lecture presented at the fifth S´eminaire Rhodanien de Physique “Sur les Sym´etries en Physique” held at Dolomieu (France), 17-21 March 1997. Up to the appendix and the graphics, it is to be published in Symmetries in Physics, F. Gieres, M. Kibler, C. Lucchesi and O. Piguet, eds. (Editions Fronti`eres, 1998).] 1I wish to dedicate these notes to my diploma and Ph.D. supervisors H. Reeh and R. Stora who devoted a major part of their scientific work to the understanding, description and explo- ration of symmetries in physics. Contents 1 Introduction ................................................... .......1 2 Symmetries of geometric objects ...................................2 3 Symmetries of the laws of nature ..................................5 1 Geometric (space-time) symmetries .............................6 2 Internal symmetries .............................................10 3 From global to local symmetries ...............................11 4 Combining geometric and internal symmetries ...............14 -

A Partition Property of Simplices in Euclidean Space
JOURNAL OF THE AMERICAN MATHEMATICAL SOCIETY Volume 3, Number I, January 1990 A PARTITION PROPERTY OF SIMPLICES IN EUCLIDEAN SPACE P. FRANKL AND V. RODL 1. INTRODUCTION AND STATEMENT OF THE RESULTS Let ]Rn denote n-dimensional Euclidean space endowed with the standard metric. For x, y E ]Rn , their distance is denoted by Ix - yl. Definition 1.1 [E]. A subset B of ]Rd is called Ramsey if for every r ~ 2 there exists some n = n(r, B) with the following partition property. For every partition ]Rn = V; u ... U ~ , there exists some j, 1::::; j ::::; r, and Bj C fj such that B is congruent to Bj • In a series of papers, Erdos et al. [E] have investigated this property. They have shown that all Ramsey sets are spherical, that is, every Ramsey set is con- tained in an appropriate sphere. On the other hand, they have shown that the vertex set (and, therefore, all its subsets) of bricks (d-dimensional paral- lelepipeds) is Ramsey. The simplest sets that are spherical but cannot be embedded into the vertex set of a brick are the sets of obtuse triangles. In [FR 1], it is shown that they are indeed Ramsey, using Ramsey's Theorem (cf. [G2]) and the Product Theorem of [E]. The aim of the present paper is twofold. First, we want to show that the vertex set of every nondegenerate simplex in any dimension is Ramsey. Second, we want to show that for both simplices and bricks, and even for their products, one can in fact choose n(r, B) = c(B)logr, where c(B) is an appropriate positive constant. -

Rotation Matrix - Wikipedia, the Free Encyclopedia Page 1 of 22
Rotation matrix - Wikipedia, the free encyclopedia Page 1 of 22 Rotation matrix From Wikipedia, the free encyclopedia In linear algebra, a rotation matrix is a matrix that is used to perform a rotation in Euclidean space. For example the matrix rotates points in the xy -Cartesian plane counterclockwise through an angle θ about the origin of the Cartesian coordinate system. To perform the rotation, the position of each point must be represented by a column vector v, containing the coordinates of the point. A rotated vector is obtained by using the matrix multiplication Rv (see below for details). In two and three dimensions, rotation matrices are among the simplest algebraic descriptions of rotations, and are used extensively for computations in geometry, physics, and computer graphics. Though most applications involve rotations in two or three dimensions, rotation matrices can be defined for n-dimensional space. Rotation matrices are always square, with real entries. Algebraically, a rotation matrix in n-dimensions is a n × n special orthogonal matrix, i.e. an orthogonal matrix whose determinant is 1: . The set of all rotation matrices forms a group, known as the rotation group or the special orthogonal group. It is a subset of the orthogonal group, which includes reflections and consists of all orthogonal matrices with determinant 1 or -1, and of the special linear group, which includes all volume-preserving transformations and consists of matrices with determinant 1. Contents 1 Rotations in two dimensions 1.1 Non-standard orientation