Basics of Euclidean Geometry
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Orthogonal Projection, Low Rank Approximation, and Orthogonal Bases
Week 11 Orthogonal Projection, Low Rank Approximation, and Orthogonal Bases 11.1 Opening Remarks 11.1.1 Low Rank Approximation * View at edX 463 Week 11. Orthogonal Projection, Low Rank Approximation, and Orthogonal Bases 464 11.1.2 Outline 11.1. Opening Remarks..................................... 463 11.1.1. Low Rank Approximation............................. 463 11.1.2. Outline....................................... 464 11.1.3. What You Will Learn................................ 465 11.2. Projecting a Vector onto a Subspace........................... 466 11.2.1. Component in the Direction of ............................ 466 11.2.2. An Application: Rank-1 Approximation...................... 470 11.2.3. Projection onto a Subspace............................. 474 11.2.4. An Application: Rank-2 Approximation...................... 476 11.2.5. An Application: Rank-k Approximation...................... 478 11.3. Orthonormal Bases.................................... 481 11.3.1. The Unit Basis Vectors, Again........................... 481 11.3.2. Orthonormal Vectors................................ 482 11.3.3. Orthogonal Bases.................................. 485 11.3.4. Orthogonal Bases (Alternative Explanation).................... 488 11.3.5. The QR Factorization................................ 492 11.3.6. Solving the Linear Least-Squares Problem via QR Factorization......... 493 11.3.7. The QR Factorization (Again)........................... 494 11.4. Change of Basis...................................... 498 11.4.1. The Unit Basis Vectors, -

Orthogonal Bases and the -So in Section 4.8 We Discussed the Problem of Finding the Orthogonal Projection P
Orthogonal Bases and the -So In Section 4.8 we discussed the problemR. of finding the orthogonal projection p the vector b into the V of , . , suhspace the vectors , v2 ho If v1 v,, form a for V, and the in x n matrix A has these basis vectors as its column vectors. ilt the orthogonal projection p is given by p = Ax where x is the (unique) solution of the normal system ATAx = A7b. The formula for p takes an especially simple and attractive Form when the ba vectors , . .. , v1 v are mutually orthogonal. DEFINITION Orthogonal Basis An orthogonal basis for the suhspacc V of R” is a basis consisting of vectors , ,v,, that are mutually orthogonal, so that v v = 0 if I j. If in additii these basis vectors are unit vectors, so that v1 . = I for i = 1. 2 n, thct the orthogonal basis is called an orthonormal basis. Example 1 The vectors = (1, 1,0), v2 = (1, —1,2), v3 = (—1,1,1) form an orthogonal basis for . We “normalize” ‘ R3 can this orthogonal basis 1w viding each basis vector by its length: If w1=—- (1=1,2,3), lvii 4.9 Orthogonal Bases and the Gram-Schmidt Algorithm 295 then the vectors /1 I 1 /1 1 ‘\ 1 2” / I w1 0) W2 = —— _z) W3 for . form an orthonormal basis R3 , . ..., v, of the m x ii matrix A Now suppose that the column vectors v v2 form an orthogonal basis for the suhspacc V of R’. Then V}.VI 0 0 v2.v .. -

Variables in Mathematics Education
Variables in Mathematics Education Susanna S. Epp DePaul University, Department of Mathematical Sciences, Chicago, IL 60614, USA http://www.springer.com/lncs Abstract. This paper suggests that consistently referring to variables as placeholders is an effective countermeasure for addressing a number of the difficulties students’ encounter in learning mathematics. The sug- gestion is supported by examples discussing ways in which variables are used to express unknown quantities, define functions and express other universal statements, and serve as generic elements in mathematical dis- course. In addition, making greater use of the term “dummy variable” and phrasing statements both with and without variables may help stu- dents avoid mistakes that result from misinterpreting the scope of a bound variable. Keywords: variable, bound variable, mathematics education, placeholder. 1 Introduction Variables are of critical importance in mathematics. For instance, Felix Klein wrote in 1908 that “one may well declare that real mathematics begins with operations with letters,”[3] and Alfred Tarski wrote in 1941 that “the invention of variables constitutes a turning point in the history of mathematics.”[5] In 1911, A. N. Whitehead expressly linked the concepts of variables and quantification to their expressions in informal English when he wrote: “The ideas of ‘any’ and ‘some’ are introduced to algebra by the use of letters. it was not till within the last few years that it has been realized how fundamental any and some are to the very nature of mathematics.”[6] There is a question, however, about how to describe the use of variables in mathematics instruction and even what word to use for them. -

1 Euclidean Vector Space and Euclidean Affi Ne Space
Profesora: Eugenia Rosado. E.T.S. Arquitectura. Euclidean Geometry1 1 Euclidean vector space and euclidean a¢ ne space 1.1 Scalar product. Euclidean vector space. Let V be a real vector space. De…nition. A scalar product is a map (denoted by a dot ) V V R ! (~u;~v) ~u ~v 7! satisfying the following axioms: 1. commutativity ~u ~v = ~v ~u 2. distributive ~u (~v + ~w) = ~u ~v + ~u ~w 3. ( ~u) ~v = (~u ~v) 4. ~u ~u 0, for every ~u V 2 5. ~u ~u = 0 if and only if ~u = 0 De…nition. Let V be a real vector space and let be a scalar product. The pair (V; ) is said to be an euclidean vector space. Example. The map de…ned as follows V V R ! (~u;~v) ~u ~v = x1x2 + y1y2 + z1z2 7! where ~u = (x1; y1; z1), ~v = (x2; y2; z2) is a scalar product as it satis…es the …ve properties of a scalar product. This scalar product is called standard (or canonical) scalar product. The pair (V; ) where is the standard scalar product is called the standard euclidean space. 1.1.1 Norm associated to a scalar product. Let (V; ) be a real euclidean vector space. De…nition. A norm associated to the scalar product is a map de…ned as follows V kk R ! ~u ~u = p~u ~u: 7! k k Profesora: Eugenia Rosado, E.T.S. Arquitectura. Euclidean Geometry.2 1.1.2 Unitary and orthogonal vectors. Orthonormal basis. Let (V; ) be a real euclidean vector space. De…nition. -

Kind of Quantity’
NIST Technical Note 2034 Defning ‘kind of quantity’ David Flater This publication is available free of charge from: https://doi.org/10.6028/NIST.TN.2034 NIST Technical Note 2034 Defning ‘kind of quantity’ David Flater Software and Systems Division Information Technology Laboratory This publication is available free of charge from: https://doi.org/10.6028/NIST.TN.2034 February 2019 U.S. Department of Commerce Wilbur L. Ross, Jr., Secretary National Institute of Standards and Technology Walter Copan, NIST Director and Undersecretary of Commerce for Standards and Technology Certain commercial entities, equipment, or materials may be identifed in this document in order to describe an experimental procedure or concept adequately. Such identifcation is not intended to imply recommendation or endorsement by the National Institute of Standards and Technology, nor is it intended to imply that the entities, materials, or equipment are necessarily the best available for the purpose. National Institute of Standards and Technology Technical Note 2034 Natl. Inst. Stand. Technol. Tech. Note 2034, 7 pages (February 2019) CODEN: NTNOEF This publication is available free of charge from: https://doi.org/10.6028/NIST.TN.2034 NIST Technical Note 2034 1 Defning ‘kind of quantity’ David Flater 2019-02-06 This publication is available free of charge from: https://doi.org/10.6028/NIST.TN.2034 Abstract The defnition of ‘kind of quantity’ given in the International Vocabulary of Metrology (VIM), 3rd edition, does not cover the historical meaning of the term as it is most commonly used in metrology. Most of its historical meaning has been merged into ‘quantity,’ which is polysemic across two layers of abstraction. -

Higher Dimensional Conundra
Higher Dimensional Conundra Steven G. Krantz1 Abstract: In recent years, especially in the subject of harmonic analysis, there has been interest in geometric phenomena of RN as N → +∞. In the present paper we examine several spe- cific geometric phenomena in Euclidean space and calculate the asymptotics as the dimension gets large. 0 Introduction Typically when we do geometry we concentrate on a specific venue in a particular space. Often the context is Euclidean space, and often the work is done in R2 or R3. But in modern work there are many aspects of analysis that are linked to concrete aspects of geometry. And there is often interest in rendering the ideas in Hilbert space or some other infinite dimensional setting. Thus we want to see how the finite-dimensional result in RN changes as N → +∞. In the present paper we study some particular aspects of the geometry of RN and their asymptotic behavior as N →∞. We choose these particular examples because the results are surprising or especially interesting. We may hope that they will lead to further studies. It is a pleasure to thank Richard W. Cottle for a careful reading of an early draft of this paper and for useful comments. 1 Volume in RN Let us begin by calculating the volume of the unit ball in RN and the surface area of its bounding unit sphere. We let ΩN denote the former and ωN−1 denote the latter. In addition, we let Γ(x) be the celebrated Gamma function of L. Euler. It is a helpful intuition (which is literally true when x is an 1We are happy to thank the American Institute of Mathematics for its hospitality and support during this work. -

Glossary of Linear Algebra Terms
INNER PRODUCT SPACES AND THE GRAM-SCHMIDT PROCESS A. HAVENS 1. The Dot Product and Orthogonality 1.1. Review of the Dot Product. We first recall the notion of the dot product, which gives us a familiar example of an inner product structure on the real vector spaces Rn. This product is connected to the Euclidean geometry of Rn, via lengths and angles measured in Rn. Later, we will introduce inner product spaces in general, and use their structure to define general notions of length and angle on other vector spaces. Definition 1.1. The dot product of real n-vectors in the Euclidean vector space Rn is the scalar product · : Rn × Rn ! R given by the rule n n ! n X X X (u; v) = uiei; viei 7! uivi : i=1 i=1 i n Here BS := (e1;:::; en) is the standard basis of R . With respect to our conventions on basis and matrix multiplication, we may also express the dot product as the matrix-vector product 2 3 v1 6 7 t î ó 6 . 7 u v = u1 : : : un 6 . 7 : 4 5 vn It is a good exercise to verify the following proposition. Proposition 1.1. Let u; v; w 2 Rn be any real n-vectors, and s; t 2 R be any scalars. The Euclidean dot product (u; v) 7! u · v satisfies the following properties. (i:) The dot product is symmetric: u · v = v · u. (ii:) The dot product is bilinear: • (su) · v = s(u · v) = u · (sv), • (u + v) · w = u · w + v · w. -

Vector Differential Calculus
KAMIWAAI – INTERACTIVE 3D SKETCHING WITH JAVA BASED ON Cl(4,1) CONFORMAL MODEL OF EUCLIDEAN SPACE Submitted to (Feb. 28,2003): Advances in Applied Clifford Algebras, http://redquimica.pquim.unam.mx/clifford_algebras/ Eckhard M. S. Hitzer Dept. of Mech. Engineering, Fukui Univ. Bunkyo 3-9-, 910-8507 Fukui, Japan. Email: [email protected], homepage: http://sinai.mech.fukui-u.ac.jp/ Abstract. This paper introduces the new interactive Java sketching software KamiWaAi, recently developed at the University of Fukui. Its graphical user interface enables the user without any knowledge of both mathematics or computer science, to do full three dimensional “drawings” on the screen. The resulting constructions can be reshaped interactively by dragging its points over the screen. The programming approach is new. KamiWaAi implements geometric objects like points, lines, circles, spheres, etc. directly as software objects (Java classes) of the same name. These software objects are geometric entities mathematically defined and manipulated in a conformal geometric algebra, combining the five dimensions of origin, three space and infinity. Simple geometric products in this algebra represent geometric unions, intersections, arbitrary rotations and translations, projections, distance, etc. To ease the coordinate free and matrix free implementation of this fundamental geometric product, a new algebraic three level approach is presented. Finally details about the Java classes of the new GeometricAlgebra software package and their associated methods are given. KamiWaAi is available for free internet download. Key Words: Geometric Algebra, Conformal Geometric Algebra, Geometric Calculus Software, GeometricAlgebra Java Package, Interactive 3D Software, Geometric Objects 1. Introduction The name “KamiWaAi” of this new software is the Romanized form of the expression in verse sixteen of chapter four, as found in the Japanese translation of the first Letter of the Apostle John, which is part of the New Testament, i.e. -
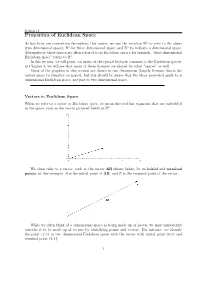
Properties of Euclidean Space
Section 3.1 Properties of Euclidean Space As has been our convention throughout this course, we use the notation R2 to refer to the plane (two dimensional space); R3 for three dimensional space; and Rn to indicate n dimensional space. Alternatively, these spaces are often referred to as Euclidean spaces; for example, \three dimensional Euclidean space" refers to R3. In this section, we will point out many of the special features common to the Euclidean spaces; in Chapter 4, we will see that many of these features are shared by other \spaces" as well. Many of the graphics in this section are drawn in two dimensions (largely because this is the easiest space to visualize on paper), but you should be aware that the ideas presented apply to n dimensional Euclidean space, not just to two dimensional space. Vectors in Euclidean Space When we refer to a vector in Euclidean space, we mean directed line segments that are embedded in the space, such as the vector pictured below in R2: We often refer to a vector, such as the vector AB shown below, by its initial and terminal points; in this example, A is the initial point of AB, and B is the terminal point of the vector. While we often think of n dimensional space as being made up of points, we may equivalently consider it to be made up of vectors by identifying points and vectors. For instance, we identify the point (2; 1) in two dimensional Euclidean space with the vector with initial point (0; 0) and terminal point (2; 1): 1 Section 3.1 In this way, we think of n dimensional Euclidean space as being made up of n dimensional vectors. -

Math 2331 – Linear Algebra 6.2 Orthogonal Sets
6.2 Orthogonal Sets Math 2331 { Linear Algebra 6.2 Orthogonal Sets Jiwen He Department of Mathematics, University of Houston [email protected] math.uh.edu/∼jiwenhe/math2331 Jiwen He, University of Houston Math 2331, Linear Algebra 1 / 12 6.2 Orthogonal Sets Orthogonal Sets Basis Projection Orthonormal Matrix 6.2 Orthogonal Sets Orthogonal Sets: Examples Orthogonal Sets: Theorem Orthogonal Basis: Examples Orthogonal Basis: Theorem Orthogonal Projections Orthonormal Sets Orthonormal Matrix: Examples Orthonormal Matrix: Theorems Jiwen He, University of Houston Math 2331, Linear Algebra 2 / 12 6.2 Orthogonal Sets Orthogonal Sets Basis Projection Orthonormal Matrix Orthogonal Sets Orthogonal Sets n A set of vectors fu1; u2;:::; upg in R is called an orthogonal set if ui · uj = 0 whenever i 6= j. Example 82 3 2 3 2 39 < 1 1 0 = Is 4 −1 5 ; 4 1 5 ; 4 0 5 an orthogonal set? : 0 0 1 ; Solution: Label the vectors u1; u2; and u3 respectively. Then u1 · u2 = u1 · u3 = u2 · u3 = Therefore, fu1; u2; u3g is an orthogonal set. Jiwen He, University of Houston Math 2331, Linear Algebra 3 / 12 6.2 Orthogonal Sets Orthogonal Sets Basis Projection Orthonormal Matrix Orthogonal Sets: Theorem Theorem (4) Suppose S = fu1; u2;:::; upg is an orthogonal set of nonzero n vectors in R and W =spanfu1; u2;:::; upg. Then S is a linearly independent set and is therefore a basis for W . Partial Proof: Suppose c1u1 + c2u2 + ··· + cpup = 0 (c1u1 + c2u2 + ··· + cpup) · = 0· (c1u1) · u1 + (c2u2) · u1 + ··· + (cpup) · u1 = 0 c1 (u1 · u1) + c2 (u2 · u1) + ··· + cp (up · u1) = 0 c1 (u1 · u1) = 0 Since u1 6= 0, u1 · u1 > 0 which means c1 = : In a similar manner, c2,:::,cp can be shown to by all 0. -

CLIFFORD ALGEBRAS Property, Then There Is a Unique Isomorphism (V ) (V ) Intertwining the Two Inclusions of V
CHAPTER 2 Clifford algebras 1. Exterior algebras 1.1. Definition. For any vector space V over a field K, let T (V ) = k k k Z T (V ) be the tensor algebra, with T (V ) = V V the k-fold tensor∈ product. The quotient of T (V ) by the two-sided⊗···⊗ ideal (V ) generated byL all v w + w v is the exterior algebra, denoted (V ).I The product in (V ) is usually⊗ denoted⊗ α α , although we will frequently∧ omit the wedge ∧ 1 ∧ 2 sign and just write α1α2. Since (V ) is a graded ideal, the exterior algebra inherits a grading I (V )= k(V ) ∧ ∧ k Z M∈ where k(V ) is the image of T k(V ) under the quotient map. Clearly, 0(V )∧ = K and 1(V ) = V so that we can think of V as a subspace of ∧(V ). We may thus∧ think of (V ) as the associative algebra linearly gener- ated∧ by V , subject to the relations∧ vw + wv = 0. We will write φ = k if φ k(V ). The exterior algebra is commutative | | ∈∧ (in the graded sense). That is, for φ k1 (V ) and φ k2 (V ), 1 ∈∧ 2 ∈∧ [φ , φ ] := φ φ + ( 1)k1k2 φ φ = 0. 1 2 1 2 − 2 1 k If V has finite dimension, with basis e1,...,en, the space (V ) has basis ∧ e = e e I i1 · · · ik for all ordered subsets I = i1,...,ik of 1,...,n . (If k = 0, we put { } k { n } e = 1.) In particular, we see that dim (V )= k , and ∅ ∧ n n dim (V )= = 2n. -

Guide for the Use of the International System of Units (SI)
Guide for the Use of the International System of Units (SI) m kg s cd SI mol K A NIST Special Publication 811 2008 Edition Ambler Thompson and Barry N. Taylor NIST Special Publication 811 2008 Edition Guide for the Use of the International System of Units (SI) Ambler Thompson Technology Services and Barry N. Taylor Physics Laboratory National Institute of Standards and Technology Gaithersburg, MD 20899 (Supersedes NIST Special Publication 811, 1995 Edition, April 1995) March 2008 U.S. Department of Commerce Carlos M. Gutierrez, Secretary National Institute of Standards and Technology James M. Turner, Acting Director National Institute of Standards and Technology Special Publication 811, 2008 Edition (Supersedes NIST Special Publication 811, April 1995 Edition) Natl. Inst. Stand. Technol. Spec. Publ. 811, 2008 Ed., 85 pages (March 2008; 2nd printing November 2008) CODEN: NSPUE3 Note on 2nd printing: This 2nd printing dated November 2008 of NIST SP811 corrects a number of minor typographical errors present in the 1st printing dated March 2008. Guide for the Use of the International System of Units (SI) Preface The International System of Units, universally abbreviated SI (from the French Le Système International d’Unités), is the modern metric system of measurement. Long the dominant measurement system used in science, the SI is becoming the dominant measurement system used in international commerce. The Omnibus Trade and Competitiveness Act of August 1988 [Public Law (PL) 100-418] changed the name of the National Bureau of Standards (NBS) to the National Institute of Standards and Technology (NIST) and gave to NIST the added task of helping U.S.