Towards the Discovery of Temporal Patterns in Music Listening Using Last.Fm Profiles
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

CS229 Project Report: Automated Photo Tagging in Facebook
CS229 Project Report: Automated photo tagging in Facebook Sebastian Schuon, Harry Robertson, Hao Zou schuon, harry.robertson, haozou @stanford.edu Abstract We examine the problem of automatically identifying and tagging users in photos on a social networking environment known as Facebook. The presented au- tomatic facial tagging system is split into three subsys- tems: obtaining image data from Facebook, detecting faces in the images and recognizing the faces to match faces to individuals. Firstly, image data is extracted from Facebook by interfacing with the Facebook API. Secondly, the Viola-Jones’ algorithm is used for locat- ing and detecting faces in the obtained images. Fur- thermore an attempt to filter false positives within the Figure 1: Schematic of the Facebook crawler face set is made using LLE and Isomap. Finally, facial recognition (using Fisherfaces and SVM) is performed on the resulting face set. This allows us to match faces 2 Collecting data from Facebook to people, and therefore tag users on images in Face- book. The proposed system accomplishes a recogni- To implement an automatic image tagging system, one tion accuracy of close to 40%, hence rendering such first has to acquire the image data. For the platform we systems feasible for real world usage. have chosen to work on, namely Facebook, this task used to be very sophisticated, if not impossible. But with the recent publication of an API to their platform, this has been greatly simplified. The API allows third party applications to integrate into their platform and 1 Introduction most importantly to access their databases (for details see figure 1 and [3]). -

Uila Supported Apps
Uila Supported Applications and Protocols updated Oct 2020 Application/Protocol Name Full Description 01net.com 01net website, a French high-tech news site. 050 plus is a Japanese embedded smartphone application dedicated to 050 plus audio-conferencing. 0zz0.com 0zz0 is an online solution to store, send and share files 10050.net China Railcom group web portal. This protocol plug-in classifies the http traffic to the host 10086.cn. It also 10086.cn classifies the ssl traffic to the Common Name 10086.cn. 104.com Web site dedicated to job research. 1111.com.tw Website dedicated to job research in Taiwan. 114la.com Chinese web portal operated by YLMF Computer Technology Co. Chinese cloud storing system of the 115 website. It is operated by YLMF 115.com Computer Technology Co. 118114.cn Chinese booking and reservation portal. 11st.co.kr Korean shopping website 11st. It is operated by SK Planet Co. 1337x.org Bittorrent tracker search engine 139mail 139mail is a chinese webmail powered by China Mobile. 15min.lt Lithuanian news portal Chinese web portal 163. It is operated by NetEase, a company which 163.com pioneered the development of Internet in China. 17173.com Website distributing Chinese games. 17u.com Chinese online travel booking website. 20 minutes is a free, daily newspaper available in France, Spain and 20minutes Switzerland. This plugin classifies websites. 24h.com.vn Vietnamese news portal 24ora.com Aruban news portal 24sata.hr Croatian news portal 24SevenOffice 24SevenOffice is a web-based Enterprise resource planning (ERP) systems. 24ur.com Slovenian news portal 2ch.net Japanese adult videos web site 2Shared 2shared is an online space for sharing and storage. -

Disentangling Public Space: Social Media and Internet Activism Thérèse F
thresholds 41 Spring 2013, 82-89 DISENTANGLING PUBLIC SPACE: SOCIAL MEDIA AND INTERNET ACTIVISM THÉRÈSE F. TIERNEY In late 2010, global events began to demonstrate that the unique communication af- fordances of social media could support and empower marginalized groups. As has occurred with previous revolutions, associated technologies are frequently champi- oned as the impetus for social change, reflecting a technological determinist stand- point on the liberatory potential of Western technology. While technology is clearly instrumental in Internet activism, the core processes at work in these movements are social, not technical.1 Setting up a blog in Burma, for example, is helpful only if potential contributors dare to post despite fears of arrest. Technology tends to over- shadow actions on the ground and, more importantly, enjoys short-lived victories as new methods of surveillance and control emerge. Media outlets and platforms focus on current expansions of the prowess and impact of technology; their attention to painstaking, long-term efforts at economic and political reform usually wanes quickly after a revolutionary moment. What motivations exist for labeling the Arab uprisings and other demonstrations as determined by social media effects? Foreign Affairs editor Evgeny Morozov answers “by emphasizing the liberating role of the tools and downplaying the role of human agency, such accounts make Americans feel proud of their own contribution to events in the Middle East.”2 The very appellation “media” in “social media” plays up the role of the technology “and thus overestimates [sic] its . importance.” To what extent do Morozov’s claims hold true? Such assertions prompt a deliberate reflec- tion on the definition of publicness, causing us to question if socio/spatial processes during the uprisings have recontextualized the historical public sphere (Figure 1). -
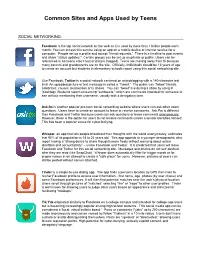
Common Sites and Apps Used by Teens
Common Sites and Apps Used by Teens SOCIAL NETWORKING: Facebook is the top social network on the web as it is used by more than 1 billion people each month. You can access this service using an app on a mobile device or internet service for a computer. People set up a profile and accept “friend requests.” There is a timeline to post events and share “status updates.” Certain groups can be set up as private or public. Users can be referenced in someone else’s text or picture (tagged). Teens are moving away from fb because many parents and grandparents are on the site. Officially, individuals should be 13 years of age to create an account but students in elementary schools report using this social networking site. Like Facebook, Twitter is a social network centered on microblogging with a 140-character text limit. An uploaded picture or text message is called a “Tweet.” The public can “follow” friends, celebrities, causes, businesses or tv shows. You can “tweet” live during a show by using # (hashtag). Students report concerning “subtweets,” which are comments intended for someone to see without mentioning their username, usually with a derogatory tone. Ask.fm is another popular pre-teen social networking website where users can ask other users questions. Users have to create an account to leave or receive comments. Ask.Fm is different than Facebook and Twitter because users can ask questions or leave comments anonymously. However, there is the option for users to not receive comments unless a sender identifies himself. This has been a popular venue for cyber-bullying. -

The Effects of Digital Music Distribution" (2012)
Southern Illinois University Carbondale OpenSIUC Research Papers Graduate School Spring 4-5-2012 The ffecE ts of Digital Music Distribution Rama A. Dechsakda [email protected] Follow this and additional works at: http://opensiuc.lib.siu.edu/gs_rp The er search paper was a study of how digital music distribution has affected the music industry by researching different views and aspects. I believe this topic was vital to research because it give us insight on were the music industry is headed in the future. Two main research questions proposed were; “How is digital music distribution affecting the music industry?” and “In what way does the piracy industry affect the digital music industry?” The methodology used for this research was performing case studies, researching prospective and retrospective data, and analyzing sales figures and graphs. Case studies were performed on one independent artist and two major artists whom changed the digital music industry in different ways. Another pair of case studies were performed on an independent label and a major label on how changes of the digital music industry effected their business model and how piracy effected those new business models as well. I analyzed sales figures and graphs of digital music sales and physical sales to show the differences in the formats. I researched prospective data on how consumers adjusted to the digital music advancements and how piracy industry has affected them. Last I concluded all the data found during this research to show that digital music distribution is growing and could possibly be the dominant format for obtaining music, and the battle with piracy will be an ongoing process that will be hard to end anytime soon. -

Who Pays for Music?
Who Pays For Music? The Honors Program Senior Capstone Project Meg Aman Professor Michael Roberto May 2015 Who Pays For Music Senior Capstone Project for Meg Aman TABLE OF CONTENTS ABSTRACT ....................................................................................................................... 3 LITERATURE REVIEW ................................................................................................ 4 INTRODUCTION ................................................................................................................. 4 MUSIC INDUSTRY BACKGROUND ...................................................................................... 6 THE PROBLEM .................................................................................................................. 8 THE MUSIC INDUSTRY ..................................................................................................... 9 THE CHANGING MUSIC MARKET .................................................................................... 10 HOW CAN MUSIC BE FREE? ........................................................................................... 11 MORE OR LESS MUSIC? .................................................................................................. 12 THE IMPORTANCE OF SAMPLING ..................................................................................... 14 THE NETWORK EFFECTS ................................................................................................. 16 WHY STREAMING AND DIGITAL MUSIC STORES ............................................................ -

WTX Microstream EN Manual-1
WTX MicroStream First Multiroom Plug & Play Audiophile Streamer What is the WTX-MicroStream The WTX-Microstream is an innovative wireless HiFi streamer which can be used with any amplier, HiFi sytem, soundbar, home theater into your home wi network. This system is multiroom. You can play your own music (PC/MAC, NAS), enjoy streaming services like Spotify, Tidal, Qobuz, etc... or radio service. The WTX-Microstream has an open interface with upgradable capability for future services and evolutions. Android and IOS apps will be available soon. What you will nd in the gift box - The WTX MicroStream x1 - The power adapter x1 - The EC plug x1 - The UK plug x1 - The US plug x1 Interface Wi-Fi led WPS button indicator for association Left channel Power supply To plug on your HiFi, active speaker, soundbar... Right channel Download your App / Android or Apple - To control your WTX-Microstreamer, please download on the App Store (if you are using Apple devices) or on Google Play (if you you are using an Android device). The name of the App is ADVANCE PLAYSTREAM How to connect your WTX MicroStream with WPS - Make sure your phone connect to your Wi-Fi home network. - Run ADVANCE PLAYSTREAM App and choose Add Device. - Type your password of your router in ADVANCE PLAYSTREAM App. - Press WPS button on WTX MicroStream How to connect your WTX MicroStream without WPS - Make sure your phone connect to your Wi-Fi home network. - Run ADVANCE PLAYSTREAM App and choose Add Device. - Enter “Setting” ->”WLAN” ->directly connect WTX MicroStreamer - Type your password of your router in ADVANCE PLAYSTREAM App. -

My Bloody Valentine's Loveless David R
Florida State University Libraries Electronic Theses, Treatises and Dissertations The Graduate School 2006 My Bloody Valentine's Loveless David R. Fisher Follow this and additional works at the FSU Digital Library. For more information, please contact [email protected] THE FLORIDA STATE UNIVERSITY COLLEGE OF MUSIC MY BLOODY VALENTINE’S LOVELESS By David R. Fisher A thesis submitted to the College of Music In partial fulfillment of the requirements for the degree of Master of Music Degree Awarded: Spring Semester, 2006 The members of the Committee approve the thesis of David Fisher on March 29, 2006. ______________________________ Charles E. Brewer Professor Directing Thesis ______________________________ Frank Gunderson Committee Member ______________________________ Evan Jones Outside Committee M ember The Office of Graduate Studies has verified and approved the above named committee members. ii TABLE OF CONTENTS List of Tables......................................................................................................................iv Abstract................................................................................................................................v 1. THE ORIGINS OF THE SHOEGAZER.........................................................................1 2. A BIOGRAPHICAL ACCOUNT OF MY BLOODY VALENTINE.………..………17 3. AN ANALYSIS OF MY BLOODY VALENTINE’S LOVELESS...............................28 4. LOVELESS AND ITS LEGACY...................................................................................50 BIBLIOGRAPHY..............................................................................................................63 -

Disco Top 15 Histories
10. Billboard’s Disco Top 15, Oct 1974- Jul 1981 Recording, Act, Chart Debut Date Disco Top 15 Chart History Peak R&B, Pop Action Satisfaction, Melody Stewart, 11/15/80 14-14-9-9-9-9-10-10 x, x African Symphony, Van McCoy, 12/14/74 15-15-12-13-14 x, x After Dark, Pattie Brooks, 4/29/78 15-6-4-2-2-1-1-1-1-1-1-2-3-3-5-5-5-10-13 x, x Ai No Corrida, Quincy Jones, 3/14/81 15-9-8-7-7-7-5-3-3-3-3-8-10 10,28 Ain’t No Stoppin’ Us, McFadden & Whitehead, 5/5/79 14-12-11-10-10-10-10 1,13 Ain’t That Enough For You, JDavisMonsterOrch, 9/2/78 13-11-7-5-4-4-7-9-13 x,89 All American Girls, Sister Sledge, 2/21/81 14-9-8-6-6-10-11 3,79 All Night Thing, Invisible Man’s Band, 3/1/80 15-14-13-12-10-10 9,45 Always There, Side Effect, 6/10/76 15-14-12-13 56,x And The Beat Goes On, Whispers, 1/12/80 13-2-2-2-1-1-2-3-3-4-11-15 1,19 And You Call That Love, Vernon Burch, 2/22/75 15-14-13-13-12-8-7-9-12 x,x Another One Bites The Dust, Queen, 8/16/80 6-6-3-3-2-2-2-3-7-12 2,1 Another Star, Stevie Wonder, 10/23/76 13-13-12-6-5-3-2-3-3-3-5-8 18,32 Are You Ready For This, The Brothers, 4/26/75 15-14-13-15 x,x Ask Me, Ecstasy,Passion,Pain, 10/26/74 2-4-2-6-9-8-9-7-9-13post peak 19,52 At Midnight, T-Connection, 1/6/79 10-8-7-3-3-8-6-8-14 32,56 Baby Face, Wing & A Prayer, 11/6/75 13-5-2-2-1-3-2-4-6-9-14 32,14 Back Together Again, R Flack & D Hathaway, 4/12/80 15-11-9-6-6-6-7-8-15 18,56 Bad Girls, Donna Summer, 5/5/79 2-1-1-1-1-1-1-1-2-2-3-10-13 1,1 Bad Luck, H Melvin, 2/15/75 12-4-2-1-1-1-1-1-1-1-1-1-2-2-3-4-5-5-7-10-15 4,15 Bang A Gong, Witch Queen, 3/10/79 12-11-9-8-15 -

Print Complete Desire Full Song List
R & B /POP /FUNK /BEACH /SOUL /OLDIES /MOTOWN /TOP-40 /RAP /DANCE MUSIC ‘50s/ ‘60s MUSIC ARETHA FRANKLIN: ISLEY BROTHERS: SAM COOK: RESPECT SHOUT TWISTIN THE NIGHT AWAY NATURAL WOMAN JAMES BROWN: YOU SEND ME ARTHUR CONLEY: I FEEL GOOD SMOKEY ROBINSON & THE MIRACLES: SWEET SOUL MUSIC I'T'S A MAN'S MAN'S WORLD OOH BABY BABY DIANA ROSS & THE SUPREMES: PLEASE,PLEASE,PLEASE TAMS: BABY LOVE LLOYD PRICE: BE YOUNG BE FOOLISH BE HAPPY STOP! IN THE NAME OF LOVE STAGGER LEE WHAT KIND OF FOOL YOU CAN’T HURRY LOVE MARY WELLS: TEMPTATIONS: YOU KEEP ME HANGIN ON MY GUY AIN’T TOO PROUD TO BEG DION: MARTHA & THE VANDELLAS: I WISH IT WOULD RAIN RUN AROUND SUE DANCING IN THE STREET MY GIRL DRIFTERS & BEN E. KING: HEATWAVE THE WAY YOU DO THE THINGS YOU DO DANCE WITH ME MARVIN GAYE: THE DOMINOES: I’VE GOT SAND IN MY SHOES AIN’T NOTHING LIKE THE REAL THING SIXTY MINUTE MAN RUBY RUBY HOW SWEET IT IS TO BE LOVED BY YOU TINA TURNER: SATURDAY NIGHT AT THE MOVIES I HEARD IT THROUGH THE GRAPEVINE PROUD MARY STAND BY ME OTIS REDDING: WILSON PICKET: THERE GOES MY BABY DOCK OF THE BAY 634-5789 UNDER THE BOARDWALK THAT’S HOW STRONG MY LOVE IS DON’T LET THE GREEN GRASS FOOL YOU UP ON TH ROOF PLATTERS: IN THE MIDNIGHT HOUR EDDIE FLOYD: WITH THIS RING MUSTANG SALLY KNOCK ON WOOD RAY CHARLES ETTA JAMES: GEORGIA ON MY MIND AT LAST SAM AND DAVE: FOUR TOPS: HOLD ON I'M COMING BABY I NEED YOUR LOVING SOUL MAN CAN'T HELP MYSELF REACH OUT I'LL BE THER R & B /POP /FUNK /BEACH /SOUL /OLDIES /MOTOWN /TOP-40 /RAP /DANCE MUSIC ‘70s MUSIC AL GREEN: I WANT YOU BACK ROD STEWART: LOVE AND HAPPINESS JAMES BROWN: DA YA THINK I’M SEXY? ANITA WARD: GET UP ROLLS ROYCE: RING MY BELL THE PAYBACK CAR WASH BILL WITHERS: JIMMY BUFFETT: SISTER SLEDGE: AIN’T NO SUNSHINE MARGARITAVILLE WE ARE FAMILY BRICK: K.C. -

To the Pittsburgh Synagogue Shooting: the Evolution of Gab
Proceedings of the Thirteenth International AAAI Conference on Web and Social Media (ICWSM 2019) From “Welcome New Gabbers” to the Pittsburgh Synagogue Shooting: The Evolution of Gab Reid McIlroy-Young, Ashton Anderson Department of Computer Science, University of Toronto, Canada [email protected], [email protected] Abstract Finally, we conduct an analysis of the shooter’s pro- file and content. After many mass shootings and terror- Gab, an online social media platform with very little content ist attacks, analysts and commentators have often pointed moderation, has recently come to prominence as an alt-right community and a haven for hate speech. We document the out “warning signs”, and speculate that perhaps the attacks evolution of Gab since its inception until a Gab user car- could have been foreseen. The shooter’s anti-Semitic com- ried out the most deadly attack on the Jewish community in ments and references to the synagogue he later attacked are US history. We investigate Gab language use, study how top- an example of this. We compare the shooters’ Gab presence ics evolved over time, and find that the shooters’ posts were with the rest of the Gab user base, and find that while he was among the most consistently anti-Semitic on Gab, but that among the most consistently anti-Semitic users, there were hundreds of other users were even more extreme. still hundreds of active users who were even more extreme. Introduction Related Work The ecosystem of online social media platforms supports a broad diversity of opinions and forms of communication. In the past few years, this has included a steep rise of alt- Our work draws upon three main lines of research: inves- right rhetoric, incendiary content, and trolling behavior. -

Artreview Artreview Asia
mother’s tankstation 41-43 Watling Street, Usher’s Island, Dublin, D08 NP48, Ireland Morley House, 26 Holborn Viaduct, 4th floor, London EC1A 2AT, United Kingdom +353 (1) 6717654 +44 (0) 7412581803 [email protected] [email protected] www.motherstankstation.com www.motherstankstation.com ArtReview ArtReview Asia FEATURE Lee Kit The feeling of being hit head-on... By Anthony Yung ArtReview Asia caught up with Lee Kit in Venice, where he was monitoring the reconstruction of a building – soon to be the site of the Hong Kong Pavilion – opposite the entrance of the Arsenale. His solo exhibition You (you). will open here in less than two months. During the past year, Lee’s experiences of participating in art fairs and exhibitions all over the world – from solo shows in Beijing, Hong Kong, Palermo and Tapei, to group shows at the New Museum and MoMA in New York – have transformed his work methods and expanded the dimensions of his creative practice. Oddly enough, shortly before being invited to represent Hong Kong at the Venice Biennale, he moved to Taipei; so we decided, under the circumstances, that the best approach would be to invite one of his old Hong Kong friends to catch up with him on recent events. Lee’s artistic journey began when he started by painting checked patterns onto cloths, then using these ‘paintings’ in his daily life as tablecloths, curtains or picnic sheets. He washed the cloths, he wiped his mouth with them and in 2004 he used one of them as a ‘flag’ in Hong Kong’s annual 1 July protests (held each year since the 1997 handover, in recent years to symbolise a demand for general freedoms).