Contrastive Phonological Analysis of Arabic and English
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Study on Unique Pharyngeal and Uvular Consonants in Foreign Accented Arabic
Study on Unique Pharyngeal and Uvular Consonants in Foreign Accented Arabic Yousef A. Alotaibi, Khondaker Abdullah-Al-Mamun, and Ghulam Muhammad Department of Computer Engineering, College of Computer and Information Sciences, King Saud University, Riyadh, Saudi Arabia {yalotaibi, mamun, ghulam}@ccis.ksu.edu.sa common to all Arabic-speaking countries. It is the language Abstract used in the media (television, radio, press, etc.), in official This paper investigates the unique pharyngeal and uvular speeches, in universities and schools, and, generally speaking, consonants of Arabic from the automatic speech recognition in any kind of formal communication situation [4]. (ASR) point of view. Comparisons of the recognition error Arabic texts are almost never fully diacritized and are thus rates for these phonemes are analyzed in five experiments that potentially unsuitable for automatic speech recognition and involve different combinations of native and non-native synthesis [3]. Table 1 shows all Arabic alphabet letters and Arabic speakers. The most three confusing consonants for their correspondences to consonant and semivowel phonemes. every investigated consonant are uncovered and discussed. This table also shows the phonetic description of each Results confirm that these Arabic distinct consonants are a phoneme including the place of articulation. In this paper we major source of difficulty for ASR. While the recognition rate use Language Data Consortium (LDC) WestPoint Modern for certain of these unique consonants such as /H/ can drop MSA database phoneme set rather than International Phonetic below 35% when uttered by non-native speakers, there are Alphabet (IPA). This was decided because we are using advantages to including non-native speakers in ASR. -

How to Get Published in ESOL and Applied Linguistics Serials
How to Get Published in TESOL and Applied Linguistics Serials TESOL Convention & Exhibit (TESOL 2016 Baltimore) Applied Linguistics Editor(s): John Hellermann & Anna Mauranen Editor/Journal E-mail: [email protected] Journal URL: http://applij.oxfordjournals.org/ Journal description: Applied Linguistics publishes research into language with relevance to real-world problems. The journal is keen to help make connections between fields, theories, research methods, and scholarly discourses, and welcomes contributions which critically reflect on current practices in applied linguistic research. It promotes scholarly and scientific discussion of issues that unite or divide scholars in applied linguistics. It is less interested in the ad hoc solution of particular problems and more interested in the handling of problems in a principled way by reference to theoretical studies. Applied linguistics is viewed not only as the relation between theory and practice, but also as the study of language and language-related problems in specific situations in which people use and learn languages. Within this framework the journal welcomes contributions in such areas of current enquiry as: bilingualism and multilingualism; computer-mediated communication; conversation analysis; corpus linguistics; critical discourse analysis; deaf linguistics; discourse analysis and pragmatics; first and additional language learning, teaching, and use; forensic linguistics; language assessment; language planning and policies; language for special purposes; lexicography; literacies; multimodal communication; rhetoric and stylistics; and translation. The journal welcomes both reports of original research and conceptual articles. The Journal’s Forum section is intended to enhance debate between authors and the wider community of applied linguists (see Editorial in 22/1) and affords a quicker turnaround time for short pieces. -

The Phonetic Nature of Consonants in Modern Standard Arabic
www.sciedupress.com/elr English Linguistics Research Vol. 4, No. 3; 2015 The Phonetic Nature of Consonants in Modern Standard Arabic Mohammad Yahya Bani Salameh1 1 Tabuk University, Saudi Arabia Correspondence: Mohammad Yahya Bani Salameh, Tabuk University, Saudi Arabia. Tel: 966-58-0323-239. E-mail: [email protected] Received: June 29, 2015 Accepted: July 29, 2015 Online Published: August 5, 2015 doi:10.5430/elr.v4n3p30 URL: http://dx.doi.org/10.5430/elr.v4n3p30 Abstract The aim of this paper is to discuss the phonetic nature of Arabic consonants in Modern Standard Arabic (MSA). Although Arabic is a Semitic language, the speech sound system of Arabic is very comprehensive. Data used for this study were collocated from the standard speech of nine informants who are native speakers of Arabic. The researcher used himself as informant, He also benefited from three other Jordanians and four educated Yemenis. Considering the alphabets as the written symbols used for transcribing the phones of actual pronunciation, it was found that the pronunciation of many Arabic sounds has gradually changed from the standard. The study also discussed several related issues including: Phonetic Description of Arabic consonants, classification of Arabic consonants, types of Arabic consonants and distribution of Arabic consonants. Keywords: Modern Standard Arabic (MSA), Arabic consonants, Dialectal variation, Consonants distribution, Consonants classification. 1. Introduction The Arabic language is one of the most important languages of the world. With it is growing importance of Arab world in the International affairs, the importance of Arabic language has reached to the greater heights. Since the holy book Qura'n is written in Arabic, the language has a place of special prestige in all Muslim societies, and therefore more and more Muslims and Asia, central Asia, and Africa are learning the Arabic language, the language of their faith. -

A Phonology of Ganza (Gwàmì Nánà)
A Phonology of Ganza (Gwàmì Nánà) Joshua Smolders SIL International Ganza is a previously undescribed Omotic language of the Mao subgroup, and is the only Omotic language found primarily outside of Ethiopia. This paper presents the results of nearly a year of phonological fieldwork on Ganza in the form of a descriptive phonology. Included are presentations of the consonant and vowel phonemes, syllable structure and phonotactics, notable morphophonemic processes, and an overview of the tone system. Some interesting features of the phonology highlighted in this paper include the existence of a nasalizing glottal stop phoneme, lack of phonemic vowel length, a lexically determined vocalic alternation between ja~e, and the existence of "construct melodies" in the tone system. Given that both Omotic languages in general and especially the Mao subfamily are understudied, this paper provides much-needed data and analysis for the furtherance of Omotic linguistics. 1. Introduction In spite of over forty years of research in Omotic languages and numerous calls for descriptive papers and reference grammars (Hayward 2009:85) to date not a single descriptive paper has ever been published on the Ganza language. Over the past decade many other previously under- described Omotic languages have been covered, such as Dizin (Beachy 2005), Dime (Mulugeta 2008), Sheko (Hellenthal 2010), and Bambassi Mao (Ahland 2012). Several others were known to be in process during the composition of this paper, including Ganza's closest relations Hoozo (Getachew 2015) and Sezo (Girma 2015). Ganza, nevertheless, remains functionally undescribed (see §1.2 for previous research). In this paper I present an initial phonology of Ganza, including a description and analysis of consonant and vowel phonemes, word structure, notable morphophonemic processes, and the tone system. -

Corpus-Based Contrastive Studies: Beginnings, Developments and Directions
Corpus-based contrastive studies Corpus-based contrastive studies: Beginnings, developments and directions Hilde Hasselgård University of Oslo This article outlines the beginnings of corpus-based contrastive studies with special reference to the development of parallel corpora that took place in Scandinavia in the early 1990s under the direction of Stig Johansson. It then discusses multilingual corpus types and methodological issues of their exploration, including the tertium comparationis for contrastive studies based on different types of corpora. Some glimpses are offered of recent developments and current trends in the field, including the widening scope of corpus-based contrastive analysis, concerning language pairs as well as the kinds of topics studied and the methods used. The paper ends by identifying and discussing some challenges for the field and indicating prospects and directions for its future. Keywords: contrastive analysis, multilingual corpus, parallel corpus, comparable corpus, tertium comparationis 1. Introduction When multilingual corpora entered the scene in the early 1990s, they represented a new development in corpus linguistics, which had been predominantly monolingual until then, as well as in contrastive studies, which got a more solid empirical basis, new methods and a general boost. Contrastive analysis used to be considered an applied discipline of linguistics, closely associated with language teaching (Johansson 2007: 1). This is apparent, for example, in Lado’s famous lines “…in the comparison between native and foreign language lies the key to ease or difficulty in foreign language learning …” (1957: 1). A similar view is found in McArthur’s definition of contrastive analysis as “a branch of linguistics that describes similarities and differences among two or more languages […], especially in order to improve language teaching and translation” (1992: 261). -

More About NAVLIPI: the World's First (And Only) Truly Phonemic Alphabet
Excerpts from NAVLIPI: The World’ s First (and Only) Truly Phonemic Alphabet | NAVLIPI.com The Specifics MORE ABOUT NAVLIPI What are the requirements or guiding principles for a truly universal phonetic or phonemic alphabet, one that addresses all the world’ s languages? How does NAVLIPI meet them? Navlipi was designed on the following 10 guiding principles, which were thought to be the minimum requirements for a universal world script: (1) Universality and completeness: Universality and the associated property, completeness, imply being able to represent, systematically and scientifically, every single phone and tone found in the world’ s major languages. This is really a minimum requirement for any universal orthography. It implies that the script must above all be a universal and accurate phonetic (phonic) script. (2) Recognizability: Recognizability necessarily means the use of the Roman “”alphabet (script) as a basis, since historical happenstance has rendered this particular orthography ubiquitous in all corners of the world. Thus, for instance, a highly scientific and easily keyboarded orthography based purely on geometric shapes, as presented as an exercise further below, would be useless in terms of recognizability. Lack of recognizability, and distinctiveness are two major deficiencies of the “”alphabet of the International Phonetic Association (IPA, based in London, England). For example, in the IPA, many glyphs (letters) appear to be straight from outer space! And the many very similar IPA glyphs, are highly confusing, even to the expert. Examples among these are the various inverted and rotated e’s and a’s, the inverted/rotated/hooked, etc. variants of r and R used to represent the various alveolar trills, flaps or uvular “’”r s , and the variants of n with inward/outward hooks, etc. -
Grammar Chapter 1.Pdf
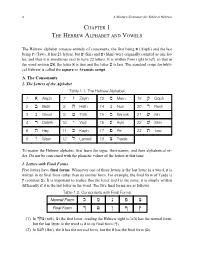
4 A Modern Grammar for Biblical Hebrew CHAPTER 1 THE HEBREW ALPHABET AND VOWELS Aleph) and the last) א The Hebrew alphabet consists entirely of consonants, the first being -Shin) were originally counted as one let) שׁ Sin) and) שׂ Taw). It has 23 letters, but) ת being ter, and thus it is sometimes said to have 22 letters. It is written from right to left, so that in -is last. The standard script for bibli שׁ is first and the letter א the letter ,אשׁ the word written cal Hebrew is called the square or Aramaic script. A. The Consonants 1. The Letters of the Alphabet Table 1.1. The Hebrew Alphabet Qoph ק Mem 19 מ Zayin 13 ז Aleph 7 א 1 Resh ר Nun 20 נ Heth 14 ח Beth 8 ב 2 Sin שׂ Samek 21 ס Teth 15 ט Gimel 9 ג 3 Shin שׁ Ayin 22 ע Yod 16 י Daleth 10 ד 4 Taw ת Pe 23 פ Kaph 17 כ Hey 11 ה 5 Tsade צ Lamed 18 ל Waw 12 ו 6 To master the Hebrew alphabet, first learn the signs, their names, and their alphabetical or- der. Do not be concerned with the phonetic values of the letters at this time. 2. Letters with Final Forms Five letters have final forms. Whenever one of these letters is the last letter in a word, it is written in its final form rather than its normal form. For example, the final form of Tsade is It is important to realize that the letter itself is the same; it is simply written .(צ contrast) ץ differently if it is the last letter in the word. -

Token-Based Typology and Word Order Entropy: a Study Based On
Linguistic Typology 2019; 23(3): 533–572 Natalia Levshina* Token-based typology and word order entropy: A study based on Universal Dependencies https://doi.org/10.1515/lingty-2019-0025 Received December 27, 2017; revised March 15, 2019 Abstract: The present paper discusses the benefits and challenges of token-based typology, which takes into account the frequencies of words and constructions in language use. This approach makes it possible to introduce new criteria for language classification, which would be difficult or impossible to achieve with the traditional, type-based approach. This point is illustrated by several quantita- tive studies of word order variation, which can be measured as entropy at differ- ent levels of granularity. I argue that this variation can be explained by general functional mechanisms and pressures, which manifest themselves in language use, such as optimization of processing (including avoidance of ambiguity) and grammaticalization of predictable units occurring in chunks. The case studies are based on multilingual corpora, which have been parsed using the Universal Dependencies annotation scheme. Keywords: corpora, word order, frequency, Universal Dependencies, entropy, token-based typology, language classification 1 Token-based typology and word order variation This paper discusses the role of usage frequencies with regard to the fundamen- tal goals of typology: language classification, and identification and explanation of cross-linguistic generalizations (cf. Croft 2003: 1–2). In most typological research, languages have been treated as single data points with a categorical value (e.g. OV or VO, prepositional or postpositional). The overwhelming major- ity of typological universals (e.g. the ones found in The Universals Archive at the University of Konstanz)1 are of this kind. -

Language Index
Cambridge University Press 978-0-521-86573-9 - Endangered Languages: An Introduction Sarah G. Thomason Index More information Language index ||Gana, 106, 110 Bininj, 31, 40, 78 Bitterroot Salish, see Salish-Pend d’Oreille. Abenaki, Eastern, 96, 176; Western, 96, 176 Blackfoot, 74, 78, 90, 96, 176 Aboriginal English (Australia), 121 Bosnian, 87 Aboriginal languages (Australia), 9, 17, 31, 56, Brahui, 63 58, 62, 106, 110, 132, 133 Breton, 25, 39, 179 Afro-Asiatic languages, 49, 175, 180, 194, 198 Bulgarian, 194 Ainu, 10 Buryat, 19 Akkadian, 1, 42, 43, 177, 194 Bushman, see San. Albanian, 28, 40, 66, 185; Arbëresh Albanian, 28, 40; Arvanitika Albanian, 28, 40, 66, 72 Cacaopera, 45 Aleut, 50–52, 104, 155, 183, 188; see also Bering Carrier, 31, 41, 170, 174 Aleut, Mednyj Aleut Catalan, 192 Algic languages, 97, 109, 176; see also Caucasian languages, 148 Algonquian languages, Ritwan languages. Celtic languages, 25, 46, 179, 183, Algonquian languages, 57, 62, 95–97, 101, 104, 185 108, 109, 162, 166, 176, 187, 191 Central Torres Strait, 9 Ambonese Malay, see Malay. Chadic languages, 175 Anatolian languages, 43 Chantyal, 31, 40 Apache, 177 Chatino, Zenzontepec, 192 Apachean languages, 177 Chehalis, Lower, see Lower Chehalis. Arabic, 1, 19, 22, 37, 43, 49, 63, 65, 101, 194; Chehalis, Upper, see Upper Chehalis. Classical Arabic, 8, 103 Cheyenne, 96, 176 Arapaho, 78, 96, 176; Northern Arapaho, 73, 90, Chinese languages (“dialects”), 22, 35, 37, 41, 92 48, 69, 101, 196; Mandarin, 35; Arawakan languages, 81 Wu, 118; see also Putonghua, Arbëresh, see Albanian. Chinook, Clackamas, see Clackamas Armenian, 185 Chinook. -

Handout on Phonemics
Structure of Spanish, LIGN 143 Spring 2012, Moore Spanish Phonemics 1. Phonemes Consonant Phonemes bilab labiodental dental alveolar palato-alveoal palatal velar Stops vl. /p/ /t̪/ /k/ vd. /b/ /d̪/ /g/ Fricatives vl. /f/ /s/ /x/ Affricates vl. /č/ nasals /m/ /n/ /ñ/ laterals /l/ taps/trills /r/ semivowels /w/ /y/ Vowel Phonemes Front Central Back High /i/ /u/ Mid /e/ /o/ Low /a/ Structure of Spanish, LIGN 143 Spring 2012, Moore 2. Allophones phoneme allophones rules /k/ [k̪], [k] Palatalization /b/ [β], [b] Stop-Fricative /d/ [ð], [d] Stop-Fricative /g/ [γ], [g], [γ ̪], [g ̪] Stop-Fricative, Palatalization /s/ [z], [s], [z̪], [s̪] s-Voicing, Alveolar Fronting /x/ [x̪], [x] Palatalization /n/ [m], [ɱ], [n̪], [n], [ñ], [ŋ ̪], [ŋ] Nasal Assimilation /l/ [l], [l], [ʎ] Lateral Assimilation /r/ [r],̃ [r] r-Strengthening, Tap Deletion /y/ [ŷ], [ɏ], [y] y-Strengthening, Stop-Fricative 3. Rules The rules should be applied in the order in which they are listed here (in some cases the order is crucial, in some cases it is not). SYLLABIFICATION Construct syllables from right to left. First put as much as you can into the nucleus (a vowel, diphthong, or a triphthong), add any free material on the right to the coda, then add a maximal onset, so long as the result is a possible onset. Examples: σ σ / \ / | \ O N O N C | | | | | soplar ‘blow’ /s o p l a r/ → s o . p l a r Structure of Spanish, LIGN 143 Spring 2012, Moore σ σ / \ / | \ O N O N C | | | | | peines ‘combs’ /p e y n e s/ → p ey . -

Variation in Phonological Error in Interlanguage Talk
I Variation in Phonological Error in Interlanguage Talk Jennifer Jenkins A thesis for the degree of Doctor of Philosophy Submitted to the Institute of Education of the University of London October 1995 © 2 Abstract The research begins with an examination of the problems attending the growth in the use of English as a lingua franc&between non-native speakers. It is argued that vanable first-language specific phonological 'errors' generate much of the miscommunication that is a characteristic of such interlanguage talk (ILT), original support for this claim being provided by a pilot study involving non-native speaker postgraduate students. Following a brief reappraisal of the place of language transfer in second language acquisition, its role in interlanguage (IL) phonology is examined in detail. Phonological transfer is revealed as a central and complex feature of the developing IL The theoretical position is exemplified by a selection of phonological transfer errors drawn from ILT classroom observation, such errors being redefmed in seriousness according to a taxonomy of new criteria based essentially on their effects on ILT communication. The extensive variation to which these taxonomic errorS are subject is discussed in the light of current theories of IL variation, and Accommodation Theory is concluded to have the greatest potential to account for phonological transfer or variation in ILT. The motivations underlying the accommodative processes of convergence and divergence are discussed and the framework is then extended to a motivation considered more salient in ILT: that of interlocutor comprehensibility. Two empirical studies investigate phonological variation in ILT from an accommodation perspective, the findings leading to the conclusion that while accommodation has an essential role in determining phonological error in ILT, its linguistic manifestation is usually one of suppression and non-suppression rather than of traditional convergence and divergence. -

Contrastive Analysis and Learner Language: a Corpus-Based Approach
Contrastive analysis and learner language: A corpus-based approach Stig Johansson University of Oslo 2008 Contrastive analysis and learner language Preface The present text has grown out of several years’ work on the English-Norwegian Parallel Corpus (ENPC), as presented in my recent monograph Seeing through Multilingual Corpora: On the use of corpora in contrastive studies (Benjamins 2007). It differs from the previous book in having been prepared as a textbook for an undergraduate course on ‘Contrastive analysis and learner language’. Though there is some overlap between the two texts, the coverage in the textbook is wider. The main difference is that the emphasis is both on contrastive analysis and on the study of learner language, with the aim of showing how these fields are connected. The textbook is intended to be used in combination with a selection of papers on individual topics, some of which go beyond corpus analysis. I am grateful to my co-workers in the project leading to the ENPC, in particular: Knut Hofland, University of Bergen, and Jarle Ebeling and Signe Oksefjell Ebeling, University of Oslo. Signe Oksefjell Ebeling has designed a net-based course to go with the text. For comments on the text, I am grateful to my colleagues Kristin Bech and Hilde Hasselgård, University of Oslo. I am also grateful to the students who have attended my courses and whose work I have drawn on in preparing this book. Oslo, March 2008 Stig Johansson 2 Stig Johansson Contents 1. Introduction 9 1.1 What is contrastive analysis? 1.2 Contrastive analysis and language teaching 1.3 Developments 1.4 Theoretical and applied CA 1.5 The problem of equivalence 1.6 Translation studies 1.7 A corpus-based approach 1.8 Types of corpora 1.9 Correspondence vs.