The Role of Second Formant Transitions in the Stop-Semivowel Distinction
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Study on Unique Pharyngeal and Uvular Consonants in Foreign Accented Arabic
Study on Unique Pharyngeal and Uvular Consonants in Foreign Accented Arabic Yousef A. Alotaibi, Khondaker Abdullah-Al-Mamun, and Ghulam Muhammad Department of Computer Engineering, College of Computer and Information Sciences, King Saud University, Riyadh, Saudi Arabia {yalotaibi, mamun, ghulam}@ccis.ksu.edu.sa common to all Arabic-speaking countries. It is the language Abstract used in the media (television, radio, press, etc.), in official This paper investigates the unique pharyngeal and uvular speeches, in universities and schools, and, generally speaking, consonants of Arabic from the automatic speech recognition in any kind of formal communication situation [4]. (ASR) point of view. Comparisons of the recognition error Arabic texts are almost never fully diacritized and are thus rates for these phonemes are analyzed in five experiments that potentially unsuitable for automatic speech recognition and involve different combinations of native and non-native synthesis [3]. Table 1 shows all Arabic alphabet letters and Arabic speakers. The most three confusing consonants for their correspondences to consonant and semivowel phonemes. every investigated consonant are uncovered and discussed. This table also shows the phonetic description of each Results confirm that these Arabic distinct consonants are a phoneme including the place of articulation. In this paper we major source of difficulty for ASR. While the recognition rate use Language Data Consortium (LDC) WestPoint Modern for certain of these unique consonants such as /H/ can drop MSA database phoneme set rather than International Phonetic below 35% when uttered by non-native speakers, there are Alphabet (IPA). This was decided because we are using advantages to including non-native speakers in ASR. -

The Phonetic Nature of Consonants in Modern Standard Arabic
www.sciedupress.com/elr English Linguistics Research Vol. 4, No. 3; 2015 The Phonetic Nature of Consonants in Modern Standard Arabic Mohammad Yahya Bani Salameh1 1 Tabuk University, Saudi Arabia Correspondence: Mohammad Yahya Bani Salameh, Tabuk University, Saudi Arabia. Tel: 966-58-0323-239. E-mail: [email protected] Received: June 29, 2015 Accepted: July 29, 2015 Online Published: August 5, 2015 doi:10.5430/elr.v4n3p30 URL: http://dx.doi.org/10.5430/elr.v4n3p30 Abstract The aim of this paper is to discuss the phonetic nature of Arabic consonants in Modern Standard Arabic (MSA). Although Arabic is a Semitic language, the speech sound system of Arabic is very comprehensive. Data used for this study were collocated from the standard speech of nine informants who are native speakers of Arabic. The researcher used himself as informant, He also benefited from three other Jordanians and four educated Yemenis. Considering the alphabets as the written symbols used for transcribing the phones of actual pronunciation, it was found that the pronunciation of many Arabic sounds has gradually changed from the standard. The study also discussed several related issues including: Phonetic Description of Arabic consonants, classification of Arabic consonants, types of Arabic consonants and distribution of Arabic consonants. Keywords: Modern Standard Arabic (MSA), Arabic consonants, Dialectal variation, Consonants distribution, Consonants classification. 1. Introduction The Arabic language is one of the most important languages of the world. With it is growing importance of Arab world in the International affairs, the importance of Arabic language has reached to the greater heights. Since the holy book Qura'n is written in Arabic, the language has a place of special prestige in all Muslim societies, and therefore more and more Muslims and Asia, central Asia, and Africa are learning the Arabic language, the language of their faith. -

A Phonology of Ganza (Gwàmì Nánà)
A Phonology of Ganza (Gwàmì Nánà) Joshua Smolders SIL International Ganza is a previously undescribed Omotic language of the Mao subgroup, and is the only Omotic language found primarily outside of Ethiopia. This paper presents the results of nearly a year of phonological fieldwork on Ganza in the form of a descriptive phonology. Included are presentations of the consonant and vowel phonemes, syllable structure and phonotactics, notable morphophonemic processes, and an overview of the tone system. Some interesting features of the phonology highlighted in this paper include the existence of a nasalizing glottal stop phoneme, lack of phonemic vowel length, a lexically determined vocalic alternation between ja~e, and the existence of "construct melodies" in the tone system. Given that both Omotic languages in general and especially the Mao subfamily are understudied, this paper provides much-needed data and analysis for the furtherance of Omotic linguistics. 1. Introduction In spite of over forty years of research in Omotic languages and numerous calls for descriptive papers and reference grammars (Hayward 2009:85) to date not a single descriptive paper has ever been published on the Ganza language. Over the past decade many other previously under- described Omotic languages have been covered, such as Dizin (Beachy 2005), Dime (Mulugeta 2008), Sheko (Hellenthal 2010), and Bambassi Mao (Ahland 2012). Several others were known to be in process during the composition of this paper, including Ganza's closest relations Hoozo (Getachew 2015) and Sezo (Girma 2015). Ganza, nevertheless, remains functionally undescribed (see §1.2 for previous research). In this paper I present an initial phonology of Ganza, including a description and analysis of consonant and vowel phonemes, word structure, notable morphophonemic processes, and the tone system. -

More About NAVLIPI: the World's First (And Only) Truly Phonemic Alphabet
Excerpts from NAVLIPI: The World’ s First (and Only) Truly Phonemic Alphabet | NAVLIPI.com The Specifics MORE ABOUT NAVLIPI What are the requirements or guiding principles for a truly universal phonetic or phonemic alphabet, one that addresses all the world’ s languages? How does NAVLIPI meet them? Navlipi was designed on the following 10 guiding principles, which were thought to be the minimum requirements for a universal world script: (1) Universality and completeness: Universality and the associated property, completeness, imply being able to represent, systematically and scientifically, every single phone and tone found in the world’ s major languages. This is really a minimum requirement for any universal orthography. It implies that the script must above all be a universal and accurate phonetic (phonic) script. (2) Recognizability: Recognizability necessarily means the use of the Roman “”alphabet (script) as a basis, since historical happenstance has rendered this particular orthography ubiquitous in all corners of the world. Thus, for instance, a highly scientific and easily keyboarded orthography based purely on geometric shapes, as presented as an exercise further below, would be useless in terms of recognizability. Lack of recognizability, and distinctiveness are two major deficiencies of the “”alphabet of the International Phonetic Association (IPA, based in London, England). For example, in the IPA, many glyphs (letters) appear to be straight from outer space! And the many very similar IPA glyphs, are highly confusing, even to the expert. Examples among these are the various inverted and rotated e’s and a’s, the inverted/rotated/hooked, etc. variants of r and R used to represent the various alveolar trills, flaps or uvular “’”r s , and the variants of n with inward/outward hooks, etc. -
Grammar Chapter 1.Pdf
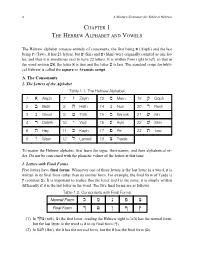
4 A Modern Grammar for Biblical Hebrew CHAPTER 1 THE HEBREW ALPHABET AND VOWELS Aleph) and the last) א The Hebrew alphabet consists entirely of consonants, the first being -Shin) were originally counted as one let) שׁ Sin) and) שׂ Taw). It has 23 letters, but) ת being ter, and thus it is sometimes said to have 22 letters. It is written from right to left, so that in -is last. The standard script for bibli שׁ is first and the letter א the letter ,אשׁ the word written cal Hebrew is called the square or Aramaic script. A. The Consonants 1. The Letters of the Alphabet Table 1.1. The Hebrew Alphabet Qoph ק Mem 19 מ Zayin 13 ז Aleph 7 א 1 Resh ר Nun 20 נ Heth 14 ח Beth 8 ב 2 Sin שׂ Samek 21 ס Teth 15 ט Gimel 9 ג 3 Shin שׁ Ayin 22 ע Yod 16 י Daleth 10 ד 4 Taw ת Pe 23 פ Kaph 17 כ Hey 11 ה 5 Tsade צ Lamed 18 ל Waw 12 ו 6 To master the Hebrew alphabet, first learn the signs, their names, and their alphabetical or- der. Do not be concerned with the phonetic values of the letters at this time. 2. Letters with Final Forms Five letters have final forms. Whenever one of these letters is the last letter in a word, it is written in its final form rather than its normal form. For example, the final form of Tsade is It is important to realize that the letter itself is the same; it is simply written .(צ contrast) ץ differently if it is the last letter in the word. -

Handout on Phonemics
Structure of Spanish, LIGN 143 Spring 2012, Moore Spanish Phonemics 1. Phonemes Consonant Phonemes bilab labiodental dental alveolar palato-alveoal palatal velar Stops vl. /p/ /t̪/ /k/ vd. /b/ /d̪/ /g/ Fricatives vl. /f/ /s/ /x/ Affricates vl. /č/ nasals /m/ /n/ /ñ/ laterals /l/ taps/trills /r/ semivowels /w/ /y/ Vowel Phonemes Front Central Back High /i/ /u/ Mid /e/ /o/ Low /a/ Structure of Spanish, LIGN 143 Spring 2012, Moore 2. Allophones phoneme allophones rules /k/ [k̪], [k] Palatalization /b/ [β], [b] Stop-Fricative /d/ [ð], [d] Stop-Fricative /g/ [γ], [g], [γ ̪], [g ̪] Stop-Fricative, Palatalization /s/ [z], [s], [z̪], [s̪] s-Voicing, Alveolar Fronting /x/ [x̪], [x] Palatalization /n/ [m], [ɱ], [n̪], [n], [ñ], [ŋ ̪], [ŋ] Nasal Assimilation /l/ [l], [l], [ʎ] Lateral Assimilation /r/ [r],̃ [r] r-Strengthening, Tap Deletion /y/ [ŷ], [ɏ], [y] y-Strengthening, Stop-Fricative 3. Rules The rules should be applied in the order in which they are listed here (in some cases the order is crucial, in some cases it is not). SYLLABIFICATION Construct syllables from right to left. First put as much as you can into the nucleus (a vowel, diphthong, or a triphthong), add any free material on the right to the coda, then add a maximal onset, so long as the result is a possible onset. Examples: σ σ / \ / | \ O N O N C | | | | | soplar ‘blow’ /s o p l a r/ → s o . p l a r Structure of Spanish, LIGN 143 Spring 2012, Moore σ σ / \ / | \ O N O N C | | | | | peines ‘combs’ /p e y n e s/ → p ey . -

Arabic and English Consonants: a Phonetic and Phonological Investigation
Advances in Language and Literary Studies ISSN: 2203-4714 Vol. 6 No. 6; December 2015 Flourishing Creativity & Literacy Australian International Academic Centre, Australia Arabic and English Consonants: A Phonetic and Phonological Investigation Mohammed Shariq College of Science and Arts, Methnab, Qassim University, Saudi Arabia E-mail: [email protected] Doi:10.7575/aiac.alls.v.6n.6p.146 Received: 18/07/2015 URL: http://dx.doi.org/10.7575/aiac.alls.v.6n.6p.146 Accepted: 15/09/2015 Abstract This paper is an attempt to investigate the actual pronunciation of the consonants of Arabic and English with the help of phonetic and phonological tools like manner of the articulation, point of articulation, and their distribution at different positions in Arabic and English words. A phonetic and phonological analysis of the consonants of Arabic and English can be useful in overcoming the hindrances that confront the Arab EFL learners. The larger aim is to bring about pedagogical changes that can go a long way in improving pronunciation and ensuring the occurrence of desirable learning outcomes. Keywords: Phonetics, Phonology, Pronunciation, Arabic Consonants, English Consonants, Manner of articulation, Point of articulation 1. Introduction Cannorn (1967) and Ekundare (1993) define phonetics as sounds which is the basis of human speech as an acoustic phenomenon. It has a source of vibration somewhere in the vocal apparatus. According to Varshney (1995), Phonetics is the scientific study of the production, transmission and reception of speech sounds. It studies the medium of spoken language. On the other hand, Phonology concerns itself with the evolution, analysis, arrangement and description of the phonemes or meaningful sounds of a language (Ramamurthi, 2004). -

CHAPTER TWELVE the Phonemes of German
CHAPTER TWELVE The Phonemes of German THE CONSONANTS At the end of Chapter Eleven it was stated that German has 20 consonant phonemes. In our IPA transcriptions we have been using 22 different consonant symbols, so two of these must not represent phonemes in their own right. When determining the phonemes of a language we are interested in inventory and distribution. The inventory is the set of phonemes. The distribution is a set of statements about the environments in which the phonemes can occur, e.g. at any point in a word, only initially, etc., and the form they take in those environments. With these two factors in mind, let us again list the consonants of German as we have been transcribing them, this time giving, where possible, examples with the consonants in word-initial position, in word-medial position (between vowels), and in word-final position1. Consonant Initially Medially Finally [p] passe ['pas@] Raupen ['RaUp@n] rieb ['Ri:p] [b] Bass ['bas] rauben ['RaUb@n] [t] Tasse ['tas@] baten ['bA:t@n] riet ['Ri:t] [d] das ['das] baden ['bA:d@n] [k] Kasse ['kas@] Haken ['hA:k@n] Sieg ['zi:k] [g] Gasse ['gas@] Hagen ['hA:g@n] [f] fasse ['fas@] Höfe ['hø:fə] reif ['RaIf] [v] was ['vas] Löwe ['lø:və] [s] reißen ['RaIs@n] Reis ['RaIs] [z] Satz ['zats] reisen ['RaIz@n] [S] Schatz ['Sats] rauschen ['RaUS@n] Rausch ['RaUS] [Z] Genie [Ze'ni:] Rage ['RA:Z@] [C] China ['Ci:na] reichen ['RaIC@n] reich ['RaIC] [x] rauchen ['RaUx@n] Rauch ['RaUx] [m] Masse ['mas@] hemmen ['hEm@n] Ramm ['Ram] [n] nasse ['nas@] Hennen ['hEn@n] rann ['Ran] [Î] hängen ['hEÎ@n] rang ['RaÎ] [l] lasse ['las@] Kohle ['ko:l@] will ['vIl] [R] Rasse ['Ras@] bohre ['bo:R@] wirr ['vIR] [7á] wir ['vi:7á] [j] Jacke ['jak@] Koje ['ko:j@] [h] hasse ['has@] 1 This list, with certain minor changes, is taken from Moulton (1962:21). -

Automatic Classification of Nasals and Semivowels
Automatic Classification of Nasals and Semivowels Tarun Pruthi, Carol Y.Espy-Wilson University of Maryland, College Park, MD 20742 E-mail: [email protected], [email protected] ABSTRACT In this paper, we discuss acoustic parameters and a classifier we developed to distinguish between nasals and semivowels. Based on the literature and our own acoustic studies, we use an onset/offset measure to capture the consonantal nature of nasals, and an energy ratio, a low spectral peak measure and a formant density measure to capture the nasal murmur. These acoustic parameters are combined using Support Vector Machine based classifiers. Classification accuracies of 88.6%, 94.9% and 85.0% were obtained for prevocalic, postvocalic and intervocalic sonorant consonants, respectively. The overall classification rate was 92.4% for nasals and 88.1% for semivowels. These results have been obtained for the TIMIT database, which was collected from a large number Figure 1 Phonetic Feature Hierarchy of speakers and contains substantial coarticulatory effects. Normally, cues from three different regions indicate the 1. INTRODUCTION presence of a nasal consonant: abrupt spectral change between the nasal and an adjacent sonorant, vowel We are working on an Event Based Speech recognition nasalisation, and the presence of the nasal murmur. system (EBS) that combines knowledge-based acoustic Fujimura [1],[2] identified four properties which parameters (APs) with a statistical framework for characterize the spectra of nasal murmurs in general: (1) the recognition [6]. In EBS, the speech signal is first segmented existence of a very low first formant that is located at about into the broad classes: vowel, sonorant consonant, strong 300 Hz and is well separated from the upper formant fricative, weak fricative and stop. -
![UKRAINIAN CONSONANT PHONES in the IPA CONTEXT with SPECIAL REFERENCE to /V/ and /Gh/[*] Maksym O](https://docslib.b-cdn.net/cover/4501/ukrainian-consonant-phones-in-the-ipa-context-with-special-reference-to-v-and-gh-maksym-o-2854501.webp)
UKRAINIAN CONSONANT PHONES in the IPA CONTEXT with SPECIAL REFERENCE to /V/ and /Gh/[*] Maksym O
Linguistica ONLINE. Issue 22. Published: August 22, 2019 http://www.phil.muni.cz/linguistica/art/vakulenko/vak-001.pdf ISSN 1801-5336 UKRAINIAN CONSONANT PHONES IN THE IPA CONTEXT WITH SPECIAL REFERENCE TO /v/ AND /gh/[*] Maksym O. Vakulenko (State Science and Technical Library of Ukraine, Ukraine, [email protected]) Abstract: The acoustic and articulatory properties of Ukrainian consonant phones were investigated, and a full set of relevant IPA notations was proposed for these and compiled in a table. Acoustic correspondence of Ukrainian phones to those appearing in European languages was analyzed and discussed. Special attention was paid to the phonemes /v/ (represented in Cyrillic script as “/в/”) and /gh/ (ren- dered in Cyrillic script as “/г/”) that cause the most difficulties in their description. In particular, our experiments and observations suggest that a standard Ukrainian phoneme /v/ is realised as labiodental fricatives [v] and [vj] before vowels and also as sonorant bilabial approximants [β̞ β̞˛ β̞ɔ] between a vowel and a consonant, in the initial position before consonants and after a vowel at the end of a word, and sometimes is devoiced to [v̥ ] in the coda after a voiceless consonant. In some ut- terances after a vowel (before a consonant and in the coda), a strongly rounded bilabial approximant [β̞ɔ] may approach a non-syllabic semivowel [ṷ]. These con- clusions are in good agreement with the consonantal status of the Ukrainian lan- guage and with the general tendencies of sound combinations in the world lan- guages. The findings of this research contribute to better understanding of Ukrain- ian and its special features in comparison with other world languages that may have substantial practical use in various phonetic and translation studies, as well as in modern linguistic technologies aimed at artificial intelligence development, machine translation incorporating text-to-speech conversion, automatic speech analysis, recognition and synthesis, and in other areas of applied linguistics. -

How to Integrate Phonetic and Linguistic Knowledge in a Text-To-Phoneme Conversion Task: a Syllabic TPC Tool for French
INTERSPEECH 2004 -- ICSLP 8th International Conference on Spoken ISCA Archive Language Processing http://www.isca-speech.org/archive ICC Jeju, Jeju Island, Korea October 4-8, 2004 How to Integrate Phonetic and Linguistic Knowledge in a Text-to-Phoneme Conversion Task: A Syllabic TPC Tool for French Nicole Beringer IDSIA: Dalle Molle Institute for Artificial Intelligence Galleria 2, 6928 Manno-Lugano, Switzerland [email protected] Abstract considered that the morphological decomposition is dif- ficult and has a high error rate. It was recently shown [1] The goal of this work is to present a text-to-phoneme con- that the performance of a syllable-based TPC is compa- version (TPC) check tool for generating dictionaries us- rable to the morpheme based one but that it is not as error able for Speech Synthesis and Speech Recognition which 1 prone in its implementation. includes phonetic and linguistic knowledge . This consideration was taken into account for this The aim is to improve and accelerate the task of pro- work to develop a TPC tool and a TPC checker for ducing canonic pronunciation dictionaries in languages French. The work resulted in two main parts: where no simple text-to-phoneme conversion is possible. The prototype was developed for a French syllable- a TPC tool for French, which includes syllabic based text-to-phoneme task but it is portable to other lan- • knowledge of French (SAM-PA Version [4]) guages. a TPC check tool, which checks whether a • 1. Introduction phoneme string is a possible syllable for French or not. In Speech Synthesis as well as in Automatic Speech Recognition (ASR) the phonetic transcript of the ortho- The former was developed analogously to the P-TRA graphic word form is needed. -

On the Phonological and Orthographic Developments of Affricates in English
Taiwan Journal of Linguistics Vol. 14.2, 105-132, 2016 DOI: 10.6519/TJL.2016.14(2).4 ON THE PHONOLOGICAL AND ORTHOGRAPHIC DEVELOPMENTS OF AFFRICATES IN ENGLISH Abdullah Hamid Alhjouj Al-Hussein Bin Talal University ABSTRACT This paper aims at looking into some aspects of the developments of phonological and orthographic affricates in English. Some of the diachronic developments of this class of sounds in all three main periods of the history of the English language are scanned. The palatalisation of velar plosives in Old English and that of alveolar plosives in Middle English and Modern English played a key role in the introduction and development of affricates. Another source of affricates is loanwords, particularly from French in the era of Middle English. The number of the orthographic representations of the two affricate phonemes in Old English at the time of first introduction was noticeably small, but there was a significant increase in number in Middle and Modern English. Key words: affricates, Old English, Middle English, Modern English, phonological, orthographic 105 Abdullah Hamid Alhjouj 1. INTRODUCTION It can be easily noticed that the discussion of affricates in English is scattered across different sources for each of the three main periods of the history of English. The discussion of affrication in different periods of English is often done as if the general principles of the process in each period were unrelated to those of another. This article scans the causes of the introduction and of aspects of the developments of affricates in Old English (henceforth, OE before Old English data), Middle English (henceforth, ME before Middle English data), and Modern English (henceforth, ModE before Modern English data) in a single piece of work.