Forecasting with Twitter Data: an Application to Usa Tv Series Audience
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Hunger Games: an Indictment of Reality Television
The Hunger Games: An Indictment of Reality Television An ELA Performance Task The Hunger Games and Reality Television Introductory Classroom Activity (30 minutes) Have students sit in small groups of about 4-5 people. Each group should have someone to record their discussion and someone who will report out orally for the group. Present on a projector the video clip drawing comparisons between The Hunger Games and shows currently on Reality TV: (http://www.youtube.com/watch?v=wdmOwt77D2g) After watching the video clip, ask each group recorder to create two columns on a piece of paper. In one column, the group will list recent or current reality television shows that have similarities to the way reality television is portrayed in The Hunger Games. In the second column, list or explain some of those similarities. To clarify this assignment, ask the following two questions: 1. What are the rules that have been set up for The Hunger Games, particularly those that are intended to appeal to the television audience? 2. Are there any shows currently or recently on television that use similar rules or elements to draw a larger audience? Allow about 5 to 10 minutes for students to work in their small groups to complete their lists. Have students report out on their group work, starting with question #1. Repeat the report out process with question #2. Discuss as a large group the following questions: 1. The narrator in the video clip suggests that entertainments like The Hunger Games “desensitize us” to violence. How true do you think this is? 2. -

Putting National Party Convention
CONVENTIONAL WISDOM: PUTTINGNATIONAL PARTY CONVENTION RATINGS IN CONTEXT Jill A. Edy and Miglena Daradanova J&MC This paper places broadcast major party convention ratings in the broad- er context of the changing media environmentfrom 1976 until 2008 in order to explore the decline in audience for the convention. Broadcast convention ratings are contrasted with convention ratingsfor cable news networks, ratings for broadcast entertainment programming, and ratings Q for "event" programming. Relative to audiences for other kinds of pro- gramming, convention audiences remain large, suggesting that profit- making criteria may have distorted representations of the convention audience and views of whether airing the convention remains worth- while. Over 80 percent of households watched the conventions in 1952 and 1960.... During the last two conventions, ratings fell to below 33 percent. The ratings reflect declining involvement in traditional politics.' Oh, come on. At neither convention is any news to be found. The primaries were effectively over several months ago. The public has tuned out the election campaign for a long time now.... Ratings for convention coverage are abysmal. Yet Shales thinks the networks should cover them in the name of good cit- izenship?2 It has become one of the rituals of presidential election years to lament the declining television audience for the major party conven- tions. Scholars like Thomas Patterson have documented year-on-year declines in convention ratings and linked them to declining participation and rising cynicism among citizens, asking what this means for the future of mass dem~cracy.~Journalists, looking at conventions in much the same way, complain that conventions are little more than four-night political infomercials, devoid of news content and therefore boring to audiences and reporters alike.4 Some have suggested that they are no longer worth airing. -

30 Rock: Complexity, Metareferentiality and the Contemporary Quality Sitcom
30 Rock: Complexity, Metareferentiality and the Contemporary Quality Sitcom Katrin Horn When the sitcom 30 Rock first aired in 2006 on NBC, the odds were against a renewal for a second season. Not only was it pitched against another new show with the same “behind the scenes”-idea, namely the drama series Studio 60 on the Sunset Strip. 30 Rock’s often absurd storylines, obscure references, quick- witted dialogues, and fast-paced punch lines furthermore did not make for easy consumption, and thus the show failed to attract a sizeable amount of viewers. While Studio 60 on the Sunset Strip did not become an instant success either, it still did comparatively well in the Nielson ratings and had the additional advantage of being a drama series produced by a household name, Aaron Sorkin1 of The West Wing (NBC, 1999-2006) fame, at a time when high-quality prime-time drama shows were dominating fan and critical debates about TV. Still, in a rather surprising programming decision NBC cancelled the drama series, renewed the comedy instead and later incorporated 30 Rock into its Thursday night line-up2 called “Comedy Night Done Right.”3 Here the show has been aired between other single-camera-comedy shows which, like 30 Rock, 1 | Aaron Sorkin has aEntwurf short cameo in “Plan B” (S5E18), in which he meets Liz Lemon as they both apply for the same writing job: Liz: Do I know you? Aaron: You know my work. Walk with me. I’m Aaron Sorkin. The West Wing, A Few Good Men, The Social Network. -

Blacks Reveal TV Loyalty
Page 1 1 of 1 DOCUMENT Advertising Age November 18, 1991 Blacks reveal TV loyalty SECTION: MEDIA; Media Works; Tracking Shares; Pg. 28 LENGTH: 537 words While overall ratings for the Big 3 networks continue to decline, a BBDO Worldwide analysis of data from Nielsen Media Research shows that blacks in the U.S. are watching network TV in record numbers. "Television Viewing Among Blacks" shows that TV viewing within black households is 48% higher than all other households. In 1990, black households viewed an average 69.8 hours of TV a week. Non-black households watched an average 47.1 hours. The three highest-rated prime-time series among black audiences are "A Different World," "The Cosby Show" and "Fresh Prince of Bel Air," Nielsen said. All are on NBC and all feature blacks. "Advertisers and marketers are mainly concerned with age and income, and not race," said Doug Alligood, VP-special markets at BBDO, New York. "Advertisers and marketers target shows that have a broader appeal and can generate a large viewing audience." Mr. Alligood said this can have significant implications for general-market advertisers that also need to reach blacks. "If you are running a general ad campaign, you will underdeliver black consumers," he said. "If you can offset that delivery with those shows that they watch heavily, you will get a small composition vs. the overall audience." Hit shows -- such as ABC's "Roseanne" and CBS' "Murphy Brown" and "Designing Women" -- had lower ratings with black audiences than with the general population because "there is very little recognition that blacks exist" in those shows. -
Weather Has the Bill Has Matter
T H U R S D A Y 161st YEAR • NO. 227 JANUARY 21, 2016 CLEVELAND, TN 16 PAGES • 50¢ A year of project completions ‘State of the City’ eyes present, future By JOYANNA LOVE spur even more economic growth a step closer toward the Spring Banner Senior Staff Writer FIRST OF 2 PARTS along the APD 40 corridor,” Rowland Branch Industrial Park becoming a said. reality. Celebrating the completion of some today. The City Council recently thanked “A conceptual master plan was long-term projects for the city was a He said the successes of the past state Rep. Kevin Brooks for his work revealed last summer, prepared by highlight of Cleveland Mayor Tom year were a result of hard work by city promoting the need for the project on TVA and the Bradley/Cleveland Rowland’s State of the City address. staff and the Cleveland City Council. the state level by asking that the Industrial Development Board,” “Our city achieved several long- The mayor said, “Exit 20 is one of Legislature name the interchange for Rowland said. term goals the past year, making 2015 our most visible missions accom- him. The interchange being constructed an exciting time,” Rowland said. “But plished in 2015. Our thanks go to the “The wider turn spaces will benefit to give access to the new industrial just as exciting, Cleveland is setting Tennessee Department of trucks serving our existing park has been named for Rowland. new goals and continues to move for- Transportation and its contractors for Cleveland/Bradley County Industrial “I was proud and humbled when I ward, looking to the future for growth a dramatic overhaul of this important Park and the future Spring Branch learned this year the new access was and development.” interchange. -

Netflix and the Development of the Internet Television Network
Syracuse University SURFACE Dissertations - ALL SURFACE May 2016 Netflix and the Development of the Internet Television Network Laura Osur Syracuse University Follow this and additional works at: https://surface.syr.edu/etd Part of the Social and Behavioral Sciences Commons Recommended Citation Osur, Laura, "Netflix and the Development of the Internet Television Network" (2016). Dissertations - ALL. 448. https://surface.syr.edu/etd/448 This Dissertation is brought to you for free and open access by the SURFACE at SURFACE. It has been accepted for inclusion in Dissertations - ALL by an authorized administrator of SURFACE. For more information, please contact [email protected]. Abstract When Netflix launched in April 1998, Internet video was in its infancy. Eighteen years later, Netflix has developed into the first truly global Internet TV network. Many books have been written about the five broadcast networks – NBC, CBS, ABC, Fox, and the CW – and many about the major cable networks – HBO, CNN, MTV, Nickelodeon, just to name a few – and this is the fitting time to undertake a detailed analysis of how Netflix, as the preeminent Internet TV networks, has come to be. This book, then, combines historical, industrial, and textual analysis to investigate, contextualize, and historicize Netflix's development as an Internet TV network. The book is split into four chapters. The first explores the ways in which Netflix's development during its early years a DVD-by-mail company – 1998-2007, a period I am calling "Netflix as Rental Company" – lay the foundations for the company's future iterations and successes. During this period, Netflix adapted DVD distribution to the Internet, revolutionizing the way viewers receive, watch, and choose content, and built a brand reputation on consumer-centric innovation. -

Nickelodeon's Groundbreaking Hit Comedy Icarly Concludes Its Five-Season Run with a Special Hour-Long Series Finale Event, Friday, Nov
Nickelodeon's Groundbreaking Hit Comedy iCarly Concludes Its Five-season Run With A Special Hour-long Series Finale Event, Friday, Nov. 23, At 8 P.M. (ET/PT) Carly Shay's Air Force Colonel Father Appears for First Time in Emotional Culmination of Beloved Series SANTA MONICA, Calif., Nov. 14, 2012 /PRNewswire/ -- Nickelodeon's groundbreaking and beloved hit comedy, iCarly, which has entertained millions of kids and made random dancing and spaghetti tacos pop culture phenomenons, will end its five- season run with an unforgettable hour-long series finale event on Nickelodeon Friday, Nov. 23, at 8 p.m. (ET/PT) . (Photo: http://photos.prnewswire.com/prnh/20121114/NY13645 ) In "iGoodbye," Spencer (Jerry Trainor) offers to take Carly (Miranda Cosgrove) to the Air Force father-daughter dance when their dad, Colonel Shay, isn't able to accompany her because of his overseas deployment. When Spencer gets sick and can't take her, Freddie (Nathan Kress) and Gibby (Noah Munck) try to cheer Carly up by offering to go with her. Colonel Shay surprises everyone when he arrives just in time to take Carly to the dance. When they return from their wonderful evening together, Carly is disappointed to learn her dad must return to Italy that evening and she is faced with a very difficult decision. "iCarly has been a truly definitional show that was the first to connect the web and TV into the fabric of its story-telling, and we are so very proud of it and everyone who worked on it," said Cyma Zarghami, President, Nickelodeon Group. -

Rating the Audience: the Business of Media
Balnaves, Mark, Tom O'Regan, and Ben Goldsmith. "Bibliography." Rating the Audience: The Business of Media. London: Bloomsbury Academic, 2011. 256–267. Bloomsbury Collections. Web. 2 Oct. 2021. <>. Downloaded from Bloomsbury Collections, www.bloomsburycollections.com, 2 October 2021, 14:23 UTC. Copyright © Mark Balnaves, Tom O'Regan and Ben Goldsmith 2011. You may share this work for non-commercial purposes only, provided you give attribution to the copyright holder and the publisher, and provide a link to the Creative Commons licence. Bibliography Adams, W.J. (1994), ‘Changes in ratings patterns for prime time before, during, and after the introduction of the people meter’, Journal of Media Economics , 7: 15–28. Advertising Research Foundation (2009), ‘On the road to a new effectiveness model: Measuring emotional responses to television advertising’, Advertising Research Foundation, http://www.thearf.org [accessed 5 July 2011]. Andrejevic, M. (2002), ‘The work of being watched: Interactive media and the exploitation of self-disclosure’, Critical Studies in Media Communication , 19(2): 230–48. Andrejevic, M. (2003), ‘Tracing space: Monitored mobility in the era of mass customization’, Space and Culture , 6(2): 132–50. Andrejevic, M. (2005), ‘The work of watching one another: Lateral surveillance, risk, and governance’, Surveillance and Society , 2(4): 479–97. Andrejevic, M. (2006), ‘The discipline of watching: Detection, risk, and lateral surveillance’, Critical Studies in Media Communication , 23(5): 392–407. Andrejevic, M. (2007), iSpy: Surveillance and Power in the Interactive Era , Lawrence, KS: University Press of Kansas. Andrews, K. and Napoli, P.M. (2006), ‘Changing market information regimes: a case study of the transition to the BookScan audience measurement system in the US book publishing industry’, Journal of Media Economics , 19(1): 33–54. -
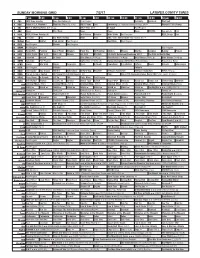
Sunday Morning Grid 7/2/17 Latimes.Com/Tv Times
SUNDAY MORNING GRID 7/2/17 LATIMES.COM/TV TIMES 7 am 7:30 8 am 8:30 9 am 9:30 10 am 10:30 11 am 11:30 12 pm 12:30 2 CBS CBS News Sunday Face the Nation (N) Paid Program Celebrity Hot Seat PGA Golf 4 NBC Today in L.A. Weekend Meet the Press (N) (TVG) NBC4 News Paid Swimming U.S. National Championships. (N) Å Women’s PGA Champ. 5 CW KTLA 5 Morning News at 7 (N) Å KTLA News at 9 In Touch Paid Program 7 ABC News This Week News News News XTERRA Eye on L.A. Paid 9 KCAL KCAL 9 News Sunday (N) Joel Osteen Schuller Mike Webb Paid Program REAL-Diego Paid 11 FOX In Touch Paid Fox News Sunday News Paid 2017 U.S. Senior Open Final Round. (N) Å 13 MyNet Paid Matter Fred Jordan Paid Program Best Buys Paid Program 18 KSCI Paid Program Church Paid Program 22 KWHY Paid Program Paid Program 24 KVCR Paint With Painting Joy of Paint Wyland’s Paint This Oil Painting Kitchen Mexico Martha Cooking Baking Project 28 KCET 1001 Nights Bali (TVG) Bali (TVG) Edisons Biz Kid$ Biz Kid$ Ed Slott’s Retirement Roadmap 2017 The Path to Wealth-May 30 ION Jeremiah Youseff In Touch Blue Bloods (TV14) Å Blue Bloods (TV14) Å Blue Bloods (TV14) Å Blue Bloods (TV14) Å 34 KMEX Conexión Paid Program Como Dice el Dicho (N) Duro pero seguro (1978) María Elena Velasco. Recuerda y Gana 40 KTBN James Win Walk Prince Carpenter Jesse In Touch PowerPoint It Is Written Jeffress Super Kelinda John Hagee 46 KFTR Paid Program Película Película 50 KOCE Odd Squad Odd Squad Martha Cyberchase Clifford-Dog WordGirl Antiques Roadshow Antiques Roadshow NOVA (TVG) Å 52 KVEA Hoy en la Copa Confed Un Nuevo Día Edición Especial (N) Copa Copa FIFA Confederaciones Rusia 2017 Chile contra Alemania. -

2020 Commencement Program
JAPANESE GREETING KOREAN GREETING ДОБРО ПОЖАЛОВАТЬ! ABUHAY M Семьям и друзьям наших Sa pamilya at mga kaibigan выпускников: ng mga magsisipagtapos: Сегодня является Ang araw na ito ay особенно важным днем natatangi para sa Colegio ng для нашего колледжа. Occidental. Sa araw na ito 134 Сегодня мы гордимся nais naming ipaabot ang женщинами и мужчинами, pag-papahalaga sa lahat ng 134 получающими их magsisipagtapos upang дипломы как глава 134- maging kabahagi ng 134 na летней истории этого taon sa kasaysayan ng ating заведения. Сегодня мы institusyon. Sa araw na ito собираемся отметить tayo’y magsama-sama upang кульминацию их трудов и ipagdiwang ang hangganan решительности, отметить ng kanilang mga pagsisikap at это важнейшее в жизни pagtitiyaga, upang itakda достижение, и пожелать itong isang makahulugang им больших успехов в bahagi ng kanilang buhay, at будущем. Мы рады, что upang ipaabot ang pagbati na Вы сегодня приехали к sana’y makamtan nila ang нам и вашим выпускникам. matagumpay na kinabukasan. Они находят величайшее Kaming lahat, kasama ng удовольствие в том, что mga magsisipagtapos ay Вы гордитесь их nasisiyahan sa inyong pagdalo достижениями. Они sa araw na ito. Ikalulugod знают, что сегодня они nilang matanggap ang inyong исполнились ващи pagpuri sa kanilang mga надежды. nakamtang tagumpay. Sa Мы собираемся как araw na ito ng pagtatapos Оксидентельская семья batid nilang naisakatuparan отметить этот важный nila ang iyong mga pangarap день в жизни наших at gayon din ang sa kanila. студентов и желать им Tayo’y magsama-sama успехов в будущем. Если bilang isang pamilya ng Вы сегодня посещаете Occidental upang ipagdiwang наш кампус первый раз, itong pinakamahalagang или Вы часто посещали bahagi ng buhay ng ating нас, мы радостно mga mag-aaral at naisin ang принимаем Вас. -

50 SIGN on BONUS AFTER 30 DAYS! Call the Circulation Dept
PAGE 8B PRESS & DAKOTAN n FRIDAY, JUNE 12, 2015 MONDAY PRIMETIME/LATE NIGHT JUNE 15, 2015 3:00 3:30 4:00 4:30 5:00 5:30 6:00 6:30 7:00 7:30 8:00 8:30 9:00 9:30 10:00 10:30 11:00 11:30 12:00 12:30 1:00 1:30 BROADCAST STATIONS Arthur Å Odd Wild Cyber- Martha Nightly PBS NewsHour (N) (In Antiques Roadshow Antiques Roadshow Independent Lens The Red BBC Charlie Rose (N) (In Tavis Smi- Tina’s Antiques Roadshow PBS (DVS) Squad Kratts Å chase A Speaks Business Stereo) Å “Vintage St. Louis” Painting by Frank Fight for legal status. Green World Stereo) Å ley (N) Å Ageless “Vintage St. Louis” Å KUSD ^ 8 ^ new film. Report (N) Å Zappa; violin. (N) Å Show News Kitchen KTIV $ 4 $ Meredith Vieira Ellen DeGeneres News 4 News News 4 Ent 2015 Stanley Cup Final: Game 6 -- Lightning at Blackhawks News 4 Tonight Show Seth Meyers Daly Extra (N) Paid Hot Bench Hot Bench Judge Judge KDLT NBC KDLT The Big 2015 Stanley Cup Final Game 6 -- Tampa Bay Lightning at Chicago KDLT The Tonight Show Late Night With Seth Last Call KDLT (Off Air) NBC Å Å Judy Å Judy Å News Nightly News Bang Blackhawks. If necessary. If game is not necessary, “American Ninja News Å Starring Jimmy Fallon Meyers (N) (In Ste- With Car- News Å KDLT % 5 % (N) Å News (N) (N) Å Theory Warrior” and “The Island” will air. (N) Å (N) Å reo) Å son Daly KCAU ) 6 ) Dr. -

Contentious Comedy
1 Contentious Comedy: Negotiating Issues of Form, Content, and Representation in American Sitcoms of the Post-Network Era Thesis by Lisa E. Williamson Submitted for the Degree of Doctor of Philosophy The University of Glasgow Department of Theatre, Film and Television Studies 2008 (Submitted May 2008) © Lisa E. Williamson 2008 2 Abstract Contentious Comedy: Negotiating Issues of Form, Content, and Representation in American Sitcoms of the Post-Network Era This thesis explores the way in which the institutional changes that have occurred within the post-network era of American television have impacted on the situation comedy in terms of form, content, and representation. This thesis argues that as one of television’s most durable genres, the sitcom must be understood as a dynamic form that develops over time in response to changing social, cultural, and institutional circumstances. By providing detailed case studies of the sitcom output of competing broadcast, pay-cable, and niche networks, this research provides an examination of the form that takes into account both the historical context in which it is situated as well as the processes and practices that are unique to television. In addition to drawing on existing academic theory, the primary sources utilised within this thesis include journalistic articles, interviews, and critical reviews, as well as supplementary materials such as DVD commentaries and programme websites. This is presented in conjunction with a comprehensive analysis of the textual features of a number of individual programmes. By providing an examination of the various production and scheduling strategies that have been implemented within the post-network era, this research considers how differentiation has become key within the multichannel marketplace.