University of Southampton Research Repository Eprints Soton
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Functional Annotation of Exon Skipping Event in Human Pora Kim1,*,†, Mengyuan Yang1,†,Keyiya2, Weiling Zhao1 and Xiaobo Zhou1,3,4,*
D896–D907 Nucleic Acids Research, 2020, Vol. 48, Database issue Published online 23 October 2019 doi: 10.1093/nar/gkz917 ExonSkipDB: functional annotation of exon skipping event in human Pora Kim1,*,†, Mengyuan Yang1,†,KeYiya2, Weiling Zhao1 and Xiaobo Zhou1,3,4,* 1School of Biomedical Informatics, The University of Texas Health Science Center at Houston, Houston, TX 77030, USA, 2College of Electronics and Information Engineering, Tongji University, Shanghai, China, 3McGovern Medical School, The University of Texas Health Science Center at Houston, Houston, TX 77030, USA and 4School of Dentistry, The University of Texas Health Science Center at Houston, Houston, TX 77030, USA Received August 13, 2019; Revised September 21, 2019; Editorial Decision October 03, 2019; Accepted October 03, 2019 ABSTRACT been used as therapeutic targets (3–8). For example, MET has lost the binding site of E3 ubiquitin ligase CBL through Exon skipping (ES) is reported to be the most com- exon 14 skipping event (9), resulting in an enhanced expres- mon alternative splicing event due to loss of func- sion level of MET. MET amplification drives the prolifera- tional domains/sites or shifting of the open read- tion of tumor cells. Multiple tyrosine kinase inhibitors, such ing frame (ORF), leading to a variety of human dis- as crizotinib, cabozantinib and capmatinib, have been used eases and considered therapeutic targets. To date, to treat patients with MET exon 14 skipping (10). Another systematic and intensive annotations of ES events example is the dystrophin gene (DMD) in Duchenne mus- based on the skipped exon units in cancer and cular dystrophy (DMD), a progressive neuromuscular dis- normal tissues are not available. -

Triplet Repeat Length Bias and Variation in the Human Transcriptome
Triplet repeat length bias and variation in the human transcriptome Michael Mollaa,1,2, Arthur Delcherb,1, Shamil Sunyaevc, Charles Cantora,d,2, and Simon Kasifa,e aDepartment of Biomedical Engineering and dCenter for Advanced Biotechnology, Boston University, Boston, MA 02215; bCenter for Bioinformatics and Computational Biology, University of Maryland, College Park, MD 20742; cDepartment of Medicine, Division of Genetics, Brigham and Women’s Hospital and Harvard Medical School, Boston, MA 02115; and eCenter for Advanced Genomic Technology, Boston University, Boston, MA 02215 Contributed by Charles Cantor, July 6, 2009 (sent for review May 4, 2009) Length variation in short tandem repeats (STRs) is an important family including Huntington’s disease (10) and hereditary ataxias (11, 12). of DNA polymorphisms with numerous applications in genetics, All Huntington’s patients exhibit an expanded number of copies in medicine, forensics, and evolutionary analysis. Several major diseases the CAG tandem repeat subsequence in the N terminus of the have been associated with length variation of trinucleotide (triplet) huntingtin gene. Moreover, an increase in the repeat length is repeats including Huntington’s disease, hereditary ataxias and spi- anti-correlated to the onset age of the disease (13). Multiple other nobulbar muscular atrophy. Using the reference human genome, we diseases have also been associated with copy number variation of have catalogued all triplet repeats in genic regions. This data revealed tandem repeats (8, 14). Researchers have hypothesized that inap- a bias in noncoding DNA repeat lengths. It also enabled a survey of propriate repeat variation in coding regions could result in toxicity, repeat-length polymorphisms (RLPs) in human genomes and a com- incorrect folding, or aggregation of a protein. -

Spatial Protein Interaction Networks of the Intrinsically Disordered Transcription Factor C(%3$
Spatial protein interaction networks of the intrinsically disordered transcription factor C(%3$ Dissertation zur Erlangung des akademischen Grades Doctor rerum naturalium (Dr. rer. nat.) im Fach Biologie/Molekularbiologie eingereicht an der Lebenswissenschaftlichen Fakultät der Humboldt-Universität zu Berlin Von Evelyn Ramberger, M.Sc. Präsidentin der Humboldt-Universität zu Berlin Prof. Dr.-Ing.Dr. Sabine Kunst Dekan der Lebenswissenschaftlichen Fakultät der Humboldt-Universität zu Berlin Prof. Dr. Bernhard Grimm Gutachter: 1. Prof. Dr. Achim Leutz 2. Prof. Dr. Matthias Selbach 3. Prof. Dr. Gunnar Dittmar Tag der mündlichen Prüfung: 12.8.2020 For T. Table of Contents Selbstständigkeitserklärung ....................................................................................1 List of Figures ............................................................................................................2 List of Tables ..............................................................................................................3 Abbreviations .............................................................................................................4 Zusammenfassung ....................................................................................................6 Summary ....................................................................................................................7 1. Introduction ............................................................................................................8 1.1. Disordered proteins -

(P -Value<0.05, Fold Change≥1.4), 4 Vs. 0 Gy Irradiation
Table S1: Significant differentially expressed genes (P -Value<0.05, Fold Change≥1.4), 4 vs. 0 Gy irradiation Genbank Fold Change P -Value Gene Symbol Description Accession Q9F8M7_CARHY (Q9F8M7) DTDP-glucose 4,6-dehydratase (Fragment), partial (9%) 6.70 0.017399678 THC2699065 [THC2719287] 5.53 0.003379195 BC013657 BC013657 Homo sapiens cDNA clone IMAGE:4152983, partial cds. [BC013657] 5.10 0.024641735 THC2750781 Ciliary dynein heavy chain 5 (Axonemal beta dynein heavy chain 5) (HL1). 4.07 0.04353262 DNAH5 [Source:Uniprot/SWISSPROT;Acc:Q8TE73] [ENST00000382416] 3.81 0.002855909 NM_145263 SPATA18 Homo sapiens spermatogenesis associated 18 homolog (rat) (SPATA18), mRNA [NM_145263] AA418814 zw01a02.s1 Soares_NhHMPu_S1 Homo sapiens cDNA clone IMAGE:767978 3', 3.69 0.03203913 AA418814 AA418814 mRNA sequence [AA418814] AL356953 leucine-rich repeat-containing G protein-coupled receptor 6 {Homo sapiens} (exp=0; 3.63 0.0277936 THC2705989 wgp=1; cg=0), partial (4%) [THC2752981] AA484677 ne64a07.s1 NCI_CGAP_Alv1 Homo sapiens cDNA clone IMAGE:909012, mRNA 3.63 0.027098073 AA484677 AA484677 sequence [AA484677] oe06h09.s1 NCI_CGAP_Ov2 Homo sapiens cDNA clone IMAGE:1385153, mRNA sequence 3.48 0.04468495 AA837799 AA837799 [AA837799] Homo sapiens hypothetical protein LOC340109, mRNA (cDNA clone IMAGE:5578073), partial 3.27 0.031178378 BC039509 LOC643401 cds. [BC039509] Homo sapiens Fas (TNF receptor superfamily, member 6) (FAS), transcript variant 1, mRNA 3.24 0.022156298 NM_000043 FAS [NM_000043] 3.20 0.021043295 A_32_P125056 BF803942 CM2-CI0135-021100-477-g08 CI0135 Homo sapiens cDNA, mRNA sequence 3.04 0.043389246 BF803942 BF803942 [BF803942] 3.03 0.002430239 NM_015920 RPS27L Homo sapiens ribosomal protein S27-like (RPS27L), mRNA [NM_015920] Homo sapiens tumor necrosis factor receptor superfamily, member 10c, decoy without an 2.98 0.021202829 NM_003841 TNFRSF10C intracellular domain (TNFRSF10C), mRNA [NM_003841] 2.97 0.03243901 AB002384 C6orf32 Homo sapiens mRNA for KIAA0386 gene, partial cds. -

Wild-Derived Allele of Tmem173 Potentiates an Alternate Signaling Response to Cytosolic DNA
Wild-derived allele of Tmem173 potentiates an alternate signaling response to cytosolic DNA. A dissertation submitted by Guy Surpris In partial fulfillment of the requirements for the degree of Doctor of Philosophy in Immunology TUFTS UNIVERSITY Sackler School of Graduate Biomedical Sciences May 2016 Adviser: Alexander Poltorak ABSTRACT The cellular recognition of cytosolic DNA is critical for maintaining homeostasis and to signal warnings to prevent the spread of pathogens such as HSV1 or Listeria. Inborn mutations in the human population determine the susceptibility or ability to clear infection. Mouse models of infectious disease are an invaluable resource for the study of these mechanisms of disease progression. However, classical laboratory mouse strains do not always recapitulate the diversity in immune responses found in the human population. Wild derived mice are an excellent source of genomic and phenotype diversity in the lab. Herein, we report and characterize phenotype variations in the wild-derived mouse strain MOLF/Ei and classical lab mouse strain in interferon stimulated gene induction to cytosolic DNA species. Using forward genetic analysis, we identified multiple loci that confer attenuated IFNβ production in MOLF/Ei macrophages to pathogen derived cytosolic di-nucleotides. Fine mapping of a major locus of linkage revealed a novel polymorphic allele of Tmem173 (STING). The MOLF allele of Tmem173 produces a protein with multiple amino acid changes, and an internal 6 amino acid deletion. Most of these amino acid changes are confined to the understudied N-terminus. These polymorphisms in MOLF STING altogether confer a lack of induction of the IFNβ promoter in an overexpression assay that seems to be attributed to the most N-terminal proximal mutations. -

Role and Regulation of the P53-Homolog P73 in the Transformation of Normal Human Fibroblasts
Role and regulation of the p53-homolog p73 in the transformation of normal human fibroblasts Dissertation zur Erlangung des naturwissenschaftlichen Doktorgrades der Bayerischen Julius-Maximilians-Universität Würzburg vorgelegt von Lars Hofmann aus Aschaffenburg Würzburg 2007 Eingereicht am Mitglieder der Promotionskommission: Vorsitzender: Prof. Dr. Dr. Martin J. Müller Gutachter: Prof. Dr. Michael P. Schön Gutachter : Prof. Dr. Georg Krohne Tag des Promotionskolloquiums: Doktorurkunde ausgehändigt am Erklärung Hiermit erkläre ich, dass ich die vorliegende Arbeit selbständig angefertigt und keine anderen als die angegebenen Hilfsmittel und Quellen verwendet habe. Diese Arbeit wurde weder in gleicher noch in ähnlicher Form in einem anderen Prüfungsverfahren vorgelegt. Ich habe früher, außer den mit dem Zulassungsgesuch urkundlichen Graden, keine weiteren akademischen Grade erworben und zu erwerben gesucht. Würzburg, Lars Hofmann Content SUMMARY ................................................................................................................ IV ZUSAMMENFASSUNG ............................................................................................. V 1. INTRODUCTION ................................................................................................. 1 1.1. Molecular basics of cancer .......................................................................................... 1 1.2. Early research on tumorigenesis ................................................................................. 3 1.3. Developing -
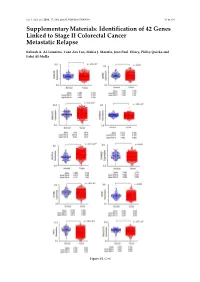
Identification of 42 Genes Linked to Stage II Colorectal Cancer Metastatic Relapse
Int. J. Mol. Sci. 2016, 17, 598; doi:10.3390/ijms17040598 S1 of S16 Supplementary Materials: Identification of 42 Genes Linked to Stage II Colorectal Cancer Metastatic Relapse Rabeah A. Al-Temaimi, Tuan Zea Tan, Makia J. Marafie, Jean Paul Thiery, Philip Quirke and Fahd Al-Mulla Figure S1. Cont. Int. J. Mol. Sci. 2016, 17, 598; doi:10.3390/ijms17040598 S2 of S16 Figure S1. Mean expression levels of fourteen genes of significant association with CRC DFS and OS that are differentially expressed in normal colon compared to CRC tissues. Each dot represents a sample. Table S1. Copy number aberrations associated with poor disease-free survival and metastasis in early stage II CRC as predicted by STAC and SPPS combined methodologies with resident gene symbols. CN stands for copy number, whereas CNV is copy number variation. Region Cytoband % of CNV Count of Region Event Gene Symbols Length Location Overlap Genes chr1:113,025,076–113,199,133 174,057 p13.2 CN Loss 0.0 2 AKR7A2P1, SLC16A1 chr1:141,465,960–141,822,265 356,305 q12–q21.1 CN Gain 95.9 1 SRGAP2B MIR5087, LOC10013000 0, FLJ39739, LOC10028679 3, PPIAL4G, PPIAL4A, NBPF14, chr1:144,911,564–146,242,907 1,331,343 q21.1 CN Gain 99.6 16 NBPF15, NBPF16, PPIAL4E, NBPF16, PPIAL4D, PPIAL4F, LOC645166, LOC388692, FCGR1C chr1:177,209,428–177,226,812 17,384 q25.3 CN Gain 0.0 0 chr1:197,652,888–197,676,831 23,943 q32.1 CN Gain 0.0 1 KIF21B chr1:201,015,278–201,033,308 18,030 q32.1 CN Gain 0.0 1 PLEKHA6 chr1:201,289,154–201,298,247 9093 q32.1 CN Gain 0.0 0 chr1:216,820,186–217,043,421 223,235 q41 CN -

Human Induced Pluripotent Stem Cell–Derived Podocytes Mature Into Vascularized Glomeruli Upon Experimental Transplantation
BASIC RESEARCH www.jasn.org Human Induced Pluripotent Stem Cell–Derived Podocytes Mature into Vascularized Glomeruli upon Experimental Transplantation † Sazia Sharmin,* Atsuhiro Taguchi,* Yusuke Kaku,* Yasuhiro Yoshimura,* Tomoko Ohmori,* ‡ † ‡ Tetsushi Sakuma, Masashi Mukoyama, Takashi Yamamoto, Hidetake Kurihara,§ and | Ryuichi Nishinakamura* *Department of Kidney Development, Institute of Molecular Embryology and Genetics, and †Department of Nephrology, Faculty of Life Sciences, Kumamoto University, Kumamoto, Japan; ‡Department of Mathematical and Life Sciences, Graduate School of Science, Hiroshima University, Hiroshima, Japan; §Division of Anatomy, Juntendo University School of Medicine, Tokyo, Japan; and |Japan Science and Technology Agency, CREST, Kumamoto, Japan ABSTRACT Glomerular podocytes express proteins, such as nephrin, that constitute the slit diaphragm, thereby contributing to the filtration process in the kidney. Glomerular development has been analyzed mainly in mice, whereas analysis of human kidney development has been minimal because of limited access to embryonic kidneys. We previously reported the induction of three-dimensional primordial glomeruli from human induced pluripotent stem (iPS) cells. Here, using transcription activator–like effector nuclease-mediated homologous recombination, we generated human iPS cell lines that express green fluorescent protein (GFP) in the NPHS1 locus, which encodes nephrin, and we show that GFP expression facilitated accurate visualization of nephrin-positive podocyte formation in -

Termination of RNA Polymerase II Transcription by the 5’-3’ Exonuclease Xrn2
TERMINATION OF RNA POLYMERASE II TRANSCRIPTION BY THE 5’-3’ EXONUCLEASE XRN2 by MICHAEL ANDRES CORTAZAR OSORIO B.S., Universidad del Valle – Colombia, 2011 A thesis submitted to the Faculty of the Graduate School of the University of Colorado in partial fulfillment of the requirements for the degree of Doctor of Philosophy Molecular Biology Program 2018 This thesis for the Doctor of Philosophy degree by Michael Andrés Cortázar Osorio has been approved for the Molecular Biology Program by Mair Churchill, Chair Richard Davis Jay Hesselberth Thomas Blumenthal James Goodrich David Bentley, Advisor Date: Aug 17, 2018 ii Cortázar Osorio, Michael Andrés (Ph.D., Molecular Biology) Termination of RNA polymerase II transcription by the 5’-3’ exonuclease Xrn2 Thesis directed by Professor David L. Bentley ABSTRACT Termination of transcription occurs when RNA polymerase (pol) II dissociates from the DNA template and releases a newly-made mRNA molecule. Interestingly, an active debate fueled by conflicting reports over the last three decades is still open on which of the two main models of termination of RNA polymerase II transcription does in fact operate at 3’ ends of genes. The torpedo model indicates that the 5’-3’ exonuclease Xrn2 targets the nascent transcript for degradation after cleavage at the polyA site and chases pol II for termination. In contrast, the allosteric model asserts that transcription through the polyA signal induces a conformational change of the elongation complex and converts it into a termination-competent complex. In this thesis, I propose a unified allosteric-torpedo mechanism. Consistent with a polyA site-dependent conformational change of the elongation complex, I found that pol II transitions at the polyA site into a mode of slow transcription elongation that is accompanied by loss of Spt5 phosphorylation in the elongation complex. -
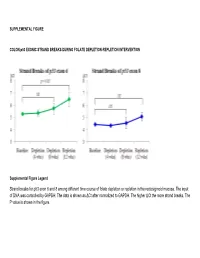
Strand Breaks for P53 Exon 6 and 8 Among Different Time Course of Folate Depletion Or Repletion in the Rectosigmoid Mucosa
SUPPLEMENTAL FIGURE COLON p53 EXONIC STRAND BREAKS DURING FOLATE DEPLETION-REPLETION INTERVENTION Supplemental Figure Legend Strand breaks for p53 exon 6 and 8 among different time course of folate depletion or repletion in the rectosigmoid mucosa. The input of DNA was controlled by GAPDH. The data is shown as ΔCt after normalized to GAPDH. The higher ΔCt the more strand breaks. The P value is shown in the figure. SUPPLEMENT S1 Genes that were significantly UPREGULATED after folate intervention (by unadjusted paired t-test), list is sorted by P value Gene Symbol Nucleotide P VALUE Description OLFM4 NM_006418 0.0000 Homo sapiens differentially expressed in hematopoietic lineages (GW112) mRNA. FMR1NB NM_152578 0.0000 Homo sapiens hypothetical protein FLJ25736 (FLJ25736) mRNA. IFI6 NM_002038 0.0001 Homo sapiens interferon alpha-inducible protein (clone IFI-6-16) (G1P3) transcript variant 1 mRNA. Homo sapiens UDP-N-acetyl-alpha-D-galactosamine:polypeptide N-acetylgalactosaminyltransferase 15 GALNTL5 NM_145292 0.0001 (GALNT15) mRNA. STIM2 NM_020860 0.0001 Homo sapiens stromal interaction molecule 2 (STIM2) mRNA. ZNF645 NM_152577 0.0002 Homo sapiens hypothetical protein FLJ25735 (FLJ25735) mRNA. ATP12A NM_001676 0.0002 Homo sapiens ATPase H+/K+ transporting nongastric alpha polypeptide (ATP12A) mRNA. U1SNRNPBP NM_007020 0.0003 Homo sapiens U1-snRNP binding protein homolog (U1SNRNPBP) transcript variant 1 mRNA. RNF125 NM_017831 0.0004 Homo sapiens ring finger protein 125 (RNF125) mRNA. FMNL1 NM_005892 0.0004 Homo sapiens formin-like (FMNL) mRNA. ISG15 NM_005101 0.0005 Homo sapiens interferon alpha-inducible protein (clone IFI-15K) (G1P2) mRNA. SLC6A14 NM_007231 0.0005 Homo sapiens solute carrier family 6 (neurotransmitter transporter) member 14 (SLC6A14) mRNA. -

Fibrosis Accumulation in Idiopathic Pulmonary Apoptosis
Increased Cell Surface Fas Expression Is Necessary and Sufficient To Sensitize Lung Fibroblasts to Fas Ligation-Induced Apoptosis: Implications for Fibroblast This information is current as Accumulation in Idiopathic Pulmonary of October 1, 2021. Fibrosis Murry W. Wynes, Benjamin L. Edelman, Amanda G. Kostyk, Michael G. Edwards, Christopher Coldren, Steve D. Groshong, Gregory P. Cosgrove, Elizabeth F. Redente, Alison Bamberg, Kevin K. Brown, Nichole Reisdorph, Downloaded from Rebecca C. Keith, Stephen K. Frankel and David W. H. Riches J Immunol 2011; 187:527-537; Prepublished online 1 June 2011; doi: 10.4049/jimmunol.1100447 http://www.jimmunol.org/ http://www.jimmunol.org/content/187/1/527 Supplementary http://www.jimmunol.org/content/suppl/2011/06/01/jimmunol.110044 Material 7.DC1 References This article cites 62 articles, 18 of which you can access for free at: by guest on October 1, 2021 http://www.jimmunol.org/content/187/1/527.full#ref-list-1 Why The JI? Submit online. • Rapid Reviews! 30 days* from submission to initial decision • No Triage! Every submission reviewed by practicing scientists • Fast Publication! 4 weeks from acceptance to publication *average Subscription Information about subscribing to The Journal of Immunology is online at: http://jimmunol.org/subscription Permissions Submit copyright permission requests at: http://www.aai.org/About/Publications/JI/copyright.html Email Alerts Receive free email-alerts when new articles cite this article. Sign up at: http://jimmunol.org/alerts The Journal of Immunology is published twice each month by The American Association of Immunologists, Inc., 1451 Rockville Pike, Suite 650, Rockville, MD 20852 Copyright © 2011 by The American Association of Immunologists, Inc. -

The Structural Basis of Indisulam-Mediated Recruitment of RBM39 to The
bioRxiv preprint doi: https://doi.org/10.1101/737510; this version posted August 16, 2019. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. 1 Title: The structural basis of Indisulam-mediated recruitment of RBM39 to the 2 DCAF15-DDB1-DDA1 E3 ligase complex 3 Authors: 4 Dirksen E. Bussiere*1, Lili Xie1, Honnappa Srinivas2, Wei Shu1, Ashley Burke3, 5 Celine Be2, Junping Zhao3, Adarsh Godbole3, Dan King3, Rajeshri G. Karki3, Viktor 6 Hornak3, Fangmin Xu3, Jennifer Cobb3, Nathalie Carte2, Andreas O. Frank1, 7 Alexandra Frommlet1, Patrick Graff2, Mark Knapp1, Aleem Fazal3, Barun Okram4, 8 Songchun Jiang4, Pierre-Yves Michellys4, Rohan Beckwith3, Hans Voshol2, Christian 9 Wiesmann2, Jonathan Solomon*3,5, Joshiawa Paulk*3,5 10 Affiliations/Institutions: 11 1Novartis Institutes for Biomedical Research, Emeryville, CA, USA 12 2Novartis Institutes for Biomedical Research, Basel, Switzerland 13 3Novartis Institutes for Biomedical Research, Cambridge, MA, USA 14 4 Genomics Institute of the Novartis Research Foundation, San Diego, CA, USA 15 16 5Equal contribution statement: 17 Joshiawa Paulk and Jonathan Solomon jointly supervised this work 18 19 *Corresponding authors: 20 1Dirksen E. Bussiere ([email protected]) 21 3Joshiawa Paulk ([email protected]) 22 3Jonathan Solomon ([email protected]) 23 24 25 26 27 28 29 30 31 1 bioRxiv preprint doi: https://doi.org/10.1101/737510; this version posted August 16, 2019. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission.