What Makes a Trophy Hunter? an Empirical Analysis of Reddit Discussions
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

UPC Platform Publisher Title Price Available 730865001347
UPC Platform Publisher Title Price Available 730865001347 PlayStation 3 Atlus 3D Dot Game Heroes PS3 $16.00 52 722674110402 PlayStation 3 Namco Bandai Ace Combat: Assault Horizon PS3 $21.00 2 Other 853490002678 PlayStation 3 Air Conflicts: Secret Wars PS3 $14.00 37 Publishers 014633098587 PlayStation 3 Electronic Arts Alice: Madness Returns PS3 $16.50 60 Aliens Colonial Marines 010086690682 PlayStation 3 Sega $47.50 100+ (Portuguese) PS3 Aliens Colonial Marines (Spanish) 010086690675 PlayStation 3 Sega $47.50 100+ PS3 Aliens Colonial Marines Collector's 010086690637 PlayStation 3 Sega $76.00 9 Edition PS3 010086690170 PlayStation 3 Sega Aliens Colonial Marines PS3 $50.00 92 010086690194 PlayStation 3 Sega Alpha Protocol PS3 $14.00 14 047875843479 PlayStation 3 Activision Amazing Spider-Man PS3 $39.00 100+ 010086690545 PlayStation 3 Sega Anarchy Reigns PS3 $24.00 100+ 722674110525 PlayStation 3 Namco Bandai Armored Core V PS3 $23.00 100+ 014633157147 PlayStation 3 Electronic Arts Army of Two: The 40th Day PS3 $16.00 61 008888345343 PlayStation 3 Ubisoft Assassin's Creed II PS3 $15.00 100+ Assassin's Creed III Limited Edition 008888397717 PlayStation 3 Ubisoft $116.00 4 PS3 008888347231 PlayStation 3 Ubisoft Assassin's Creed III PS3 $47.50 100+ 008888343394 PlayStation 3 Ubisoft Assassin's Creed PS3 $14.00 100+ 008888346258 PlayStation 3 Ubisoft Assassin's Creed: Brotherhood PS3 $16.00 100+ 008888356844 PlayStation 3 Ubisoft Assassin's Creed: Revelations PS3 $22.50 100+ 013388340446 PlayStation 3 Capcom Asura's Wrath PS3 $16.00 55 008888345435 -

Official Fact Sheet in PDF Format
Telltale Games and LucasArts Present ™ Platforms His name is Guybrush Threepwood, and he’s a Mighty Pirate™! This summer, join PC Download him in an all-new monthly series that brings the intrigue, adventure, and rich, WiiWare™ piratey goodness of Monkey Island™ to today’s gamers. Genre Background Episodic Adventure Tales of Monkey Island was created through a partnership between Telltale Games, Comedy the leader in interactive episodic entertainment, and LucasArts, the company that spearheaded the “golden age” of adventure games in the 1990s. Developer Telltale Games The Tales of Monkey Island creative team—also responsible for Telltale’s acclaimed Sam & Max, Strong Bad, and Wallace & Gromit series—includes writers, designers, Publisher and artists who worked on all four of the previous Monkey Island games. Telltale Games The Story ESRB Rating Pending An epic adventure in five parts, Tales of Monkey Island grows more engrossing with each new installment. While battling the evil pirate LeChuck, Guybrush mistakenly Release timeframe unleashes an insidious pox that transforms the buccaneers of the Caribbean into Five monthly episodes unruly monsters. On the Voodoo Lady’s advice, he sets sail in search of La Esponja starting Summer 2009 Grande, a legendary sea sponge that will stem the epidemic. Official website Little does he know, Threepwood’s quest is part of a more sinister plot. Good and www.telltalegames.com/ evil are not always what they seem, and everything you think you know will be monkeyisland challenged as Tales of Monkey Island -
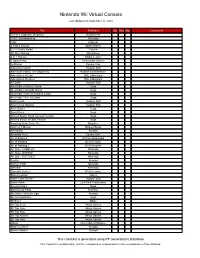
Nintendo Wii Virtual Console
Nintendo Wii Virtual Console Last Updated on September 25, 2021 Title Publisher Qty Box Man Comments 101-in-1 Explosive Megamix Nordcurrent 1080° Snowboarding Nintendo 1942 Capcom 2 Fast 4 Gnomz QubicGames 3-2-1, Rattle Battle! Tecmo 3D Pixel Racing Microforum 5 in 1 Solitaire Digital Leisure 5 Spots Party Cosmonaut Games ActRaiser Square Enix Adventure Island Hudson Soft Adventure Island: The Beginning Hudson Entertainment Adventures of Lolo HAL Laboratory Adventures of Lolo 2 HAL Laboratory Air Zonk Hudson Soft Alex Kidd in Miracle World Sega Alex Kidd in Shinobi World Sega Alex Kidd: In the Enchanted Castle Sega Alex Kidd: The Lost Stars Sega Alien Crush Hudson Soft Alien Crush Returns Hudson Soft Alien Soldier Sega Alien Storm Sega Altered Beast: Sega Genesis Version Sega Altered Beast: Arcade Version Sega Amazing Brain Train, The NinjaBee And Yet It Moves Broken Rules Ant Nation Konami Arkanoid Plus! Square Enix Art of Balance Shin'en Multimedia Art of Fighting D4 Enterprise Art of Fighting 2 D4 Enterprise Art Style: CUBELLO Nintendo Art Style: ORBIENT Nintendo Art Style: ROTOHEX Nintendo Axelay Konami Balloon Fight Nintendo Baseball Nintendo Baseball Stars 2 D4 Enterprise Bases Loaded Jaleco Battle Lode Runner Hudson Soft Battle Poker Left Field Productions Beyond Oasis Sega Big Kahuna Party Reflexive Bio Miracle Bokutte Upa Konami Bio-Hazard Battle Sega Bit Boy!! Bplus Bit.Trip Beat Aksys Games Bit.Trip Core Aksys Games Bit.Trip Fate Aksys Games Bit.Trip Runner Aksys Games Bit.Trip Void Aksys Games bittos+ Unconditional Studios Blades of Steel Konami Blaster Master Sunsoft This checklist is generated using RF Generation's Database This checklist is updated daily, and it's completeness is dependent on the completeness of the database. -

Overview Core Game Mechanics and Features in Adventure Games
Adventure Games Overview While most good games include elements found in various game genres, there are some core game mechanics typically found in most Adventure games. These include character progression through dialog, game story structure, puzzle solving, and exploration. Looking back at classic Adventure games such as Monkey Island, Beyond good and Evil, Grim Fandiago, and others used these elements to create some popular and playable games. Modern Adventure games such as the Tomb Raider series or games from Telltale Games (the Walking Dead and the Wolf Among Us) include such core elements in their game designs. Core Game Mechanics and Features in Adventure Games The core mechanics in most adventure games include the following elements: Story driven – most adventure games include some kind of game story that is used to structure the game and allow the player to participate in the game. Typically, the game ends with the story. The win/lose conditions are based on puzzle and exploration actions. Single Player and Character Driven – most adventure games are single player and allow the player to assume control of a game character. This character is typically set at the start of the game and, unlike RPG games, is not mutable as the result of gameplay. Most (but not all) Adventure games are in the third person perspective. Exploration – Many adventure games allow the player to explore (to some degree). The purpose of such exploration is typically to flesh out the world, extend the story, or solve puzzles. Some adventure games that have a strong story structure may not allow for much exploration. -

Failed Failures: the Critique of the Game of Thrones Video Game
Pobrane z czasopisma New Horizons in English Studies http://newhorizons.umcs.pl Data: 28/07/2021 12:52:03 New Horizons in English Studies 3/2018 CULTURE & MEDIA • Agata Waszkiewicz Maria Curie-SkłodowSka univerSity (uMCS) in LubLin [email protected] Failed Failures: The Critique of the Game of Thrones Video Game Abstract. In this research paper the Game of Thrones video game is juxtaposed with the original book and TV series in order to investigate the differences in failures experienced by the characters, primarily in the context of its fairness. J. Juul's book from 2013 serves as a main source of theoretical framework. It is argued that by misinforming the player about their influence on the plot, the game causes the player to develop learned helplessness, which, in turn, causes a lack of interest and lowered enjoyment. Key words: Game of Thrones,UMCS failure, learnt helplessness, attribution theory, coping mechanisms. Introduction In the famous sentence Cersei Lannister – a wife and, later, a mother of Westerosi kings – says that “When you play the game of thrones, you win or you die” (Episode 7, Season 1), which has been frequently quoted as a sign of ruthlessness in the Game of Thrones’ world. The characters plot, deceive, make and break alliances, and are not afraid to kill their opponents to gain the advantage. The fantasy world created by George R. R. Martin is predominantly a story of “abuse and consequences of power” (Schröter 2015, 72) as it interweaves diplomacy and politics with magical elements. This world is famously harsh and ruthless, and it is not uncommon for the important characters to lose their lives, to the immense surprise of readers. -

You're Listening to Imaginary Worlds, a Show About How We Create Them
1 You’re listening to Imaginary Worlds, a show about how we create them and why we suspend our disbelief. I’m Eric Molinsky. Have I mentioned that I’m a Batman fan? Maybe a half dozen times? For years, I’ve been playing the Arkham video games where you get to be Batman in this very cinematic universe. But as a player, your options are limited beyond whether you skip the side missions or just stick to the main plotline. But in 2016, I started hearing about this new Batman game by a company called Telltale. The design of the game wasn’t very CGI. It looked more like a graphic novel come to life. And the game was broken up like a TV show, with episodes that you download periodically as part of a limited series. Now what really stood out about the Telltale game is that you have a lot of choices. Some of the choices are big, like whether you decide to save to Selina Kyle or Harvey Dent – which could delay his transformation into Two-Face. BATMAN: Mr. Dent. HARVEY: Thanks. But the choices that really fascinated me where smaller ones, especially when you’re playing Bruce Wayne, and all you have to work with are your dialogue options – where you can try and diffuse the tension or make a stand. And I could never predict how the characters would react. BRUCE: You were the fiercest DA the city ever had – someone who fought for people’s dreams! So much for a safer Gotham. TWO-FACE: You’re right, this isn’t me! Go! Get away! Telltale also got critical acclaim for their The Walking Dead games – where your need to survive is in conflict with your moral principles. -

Telltale Batman Pc Download Batman – the Telltale Series Free Download (Incl
telltale batman pc download Batman – The Telltale Series Free Download (Incl. DLC) How to Download & Install Batman – The Telltale Series. Click the Download button below and you should be redirected to UploadHaven. Wait 5 seconds and click on the blue ‘download now’ button. Now let the download begin and wait for it to finish. Once Batman – The Telltale Series is done downloading, right click the .zip file and click on “Extract to Batman.The.Telltale.Series.Incl.DLC.zip” (To do this you must have 7-Zip, which you can get here). Double click inside the Batman – The Telltale Series folder and run the exe application. Have fun and play! Make sure to run the game as administrator and if you get any missing dll errors, look for a Redist or _CommonRedist folder and install all the programs in the folder. Batman – The Telltale Series Free Download. Click the download button below to start Batman – The Telltale Series Free Download with direct link. It is the full version of the game. Don’t forget to run the game as administrator. NOTICE : This game is already pre-installed for you, meaning you don’t have to install it. If you get any missing dll errors, make sure to look for a _Redist or _CommonRedist folder and install directx, vcredist and all other programs in that folder. You need these programs for the game to run. Look for a ‘HOW TO RUN GAME. txt’ file for more help. Also, be sure to right click the exe and always select “Run as administrator” if you’re having problems saving the game. -

16Th Annual DICE Awards
Academy of Interactive Arts & Sciences 16th Annual D.I.C.E. Awards Finalists GAME TITLE PUBLISHER DEVELOPER Game of the Year Borderlands 2 2k Games Gearbox Software Far Cry 3 Ubisoft Ubisoft Journey Sony Computer Entertainment America, LLC thatgamecompany The Walking Dead Telltale Games Telltale Games XCOM: Enemy Unknown 2k Games Firaxis Games Outstanding Achievement in Game Direction Journey Sony Computer Entertainment America, LLC thatgamecompany Dishonored Bethesda Softworks Arkane Studios Far Cry 3 Ubisoft Ubisoft The Unfinished Swan Sony Computer Entertainment America, LLC Giant Sparrow The Walking Dead Telltale Games Telltale Games Outstanding Innovation in Gaming Journey Sony Computer Entertainment America, LLC thatgamecompany Nintendo Land Nintendo of America Inc. Nintendo Sound Shapes Sony Computer Entertainment America, LLC Queasy Games The Unfinished Swan Sony Computer Entertainment America, LLC Giant Sparrow The Walking Dead Telltale Games Telltale Games Downloadable Game of the Year Fez Microsoft Studios Polytron Corporation Journey Sony Computer Entertainment America, LLC thatgamecompany Mark of the Ninja Microsoft Studios Klei Entertainment The Unfinished Swan Sony Computer Entertainment America, LLC Giant Sparrow The Walking Dead Telltale Games Telltale Games Handheld Game of the Year Gravity Rush Sony Computer Entertainment America, LLC Japan Studio Paper Mario Sticker Star Nintendo of America Inc. Intelligent Systems Resident Evil Revelations Capcom USA Capcom Co., Ltd. Sound Shapes Sony Computer Entertainment America, LLC Queasy Games Uncharted: Golden Abyss Sony Computer Entertainment America, LLC Sony Bend Studio Mobile Game of the Year Fairway Solitaire Big Fish Big Fish Hero Academy Robot Entertainment Robot Entertainment Horn Zynga Inc. Phosphor Games Studio Rayman Jungle Run Ubisoft Pastagames, Ubisoft Montpellier Web Based Game of the Year Bingo Bash BitRhymes Inc. -

Microsoft Xbox Live Arcade
Microsoft Xbox Live Arcade Last Updated on September 27, 2021 Title Publisher Qty Box Man Comments 0 Day Attack on Earth Square Enix 0-D: Beat Drop Arc System Works 1942: Joint Strike Capcom 3 on 3 NHL Arcade EA Freestyle 3D Ultra Minigolf Adventures Sierra Online 3D Ultra Minigolf Adventures 2 Konami Abyss Odyssey Atlus Aces of the Galaxy Artech Studios Adventures of Shuggy, The Valcon Games Aegis Wing Microsoft After Burner Climax Sega Age of Booty Capcom AirMech Arena Ubisoft Alan Wake's American Nightmare Microsoft Alein Spidey Kalypso Media Alien Breed 2: Assault Team17 Alien Breed 3: Descent Team 17 Alien Breed Evolution: Episode 1 Team 17 Alien Hominid HD The Behemoth Alien Spidy Kalypso Media All Zombies Must Die! Square Enix Altered Beast Sega American Mensa Academy Square Enix Amy VectorCell Ancients of Ooga Microsoft Anomaly: Warzone Earth Microsoft Apples to Apples THQ Aqua Xbox LIVE Arcade Are You Smarter Than A 5th Grader? THQ Arkadian Warriors Sierra Online ARKANOID Live! Xbox LIVE Arcade Ascend: Hand of Kul Microsoft Studios Assassin's Creed: Liberation HD Ubisoft Assault Heroes Sierra Online Assault Heroes 2 Sierra Online Asteroids & Asteroids Deluxe Atari AstroPop Oberon Media Awesomenauts DTP Entertainment Axel & Pixel 2K Games Babel Rising Ubisoft Backbreaker Vengence 505 Games Band of Bugs NinjaBee Bang Bang Racing Digital Reality Software Bangai-O HD: Missile Fury D3 Publisher Banjo-Kazooie Microsoft Banjo-Tooie Microsoft Bankshot Billiards 2 PixelStorm Bastion Warner Bros. Interactive Batman: Arkham Origins Blackgate - Deluxe Edition Warner Bros. Interactive En... Battle: Los Angeles Konami BattleBlock Theater Microsoft Battlefield 1943 Electronic Arts Battlestar Galactica Sierra Online Battlezone Atari This checklist is generated using RF Generation's Database This checklist is updated daily, and it's completeness is dependent on the completeness of the database. -

Whose Mind Is the Signal? Focalization in Video Game Narratives
Whose mind is the signal? Focalization in video game narratives Fraser Allison Interaction Design Lab Computing and Information Systems The University of Melbourne [email protected] ABSTRACT In this paper, I explore instances in which video games convey an experience of subjectivity, utilizing an appropriation of Gérard Genette’s (1980) concept of focalization. Through an analysis of The Sims 3 (The Sims Studio 2009), Top Spin 4 (2K Czech 2011), Mirror’s Edge (EA Digital Illusions CE 2008) and Grand Theft Auto V (Rockstar North 2014), I demonstrate that internal focalization can be made apparent in a video game through its audiovisual presentation, its selection and restriction of private knowledge, and its ludic affordances. I provide a framework for analyzing games that seek to present a diversity of perspectives, and to allow players to access modes of thinking that accord with a perspective other than their own. This framework can assist researchers, critics, and designers to identify ways in which video games express elements of internal focalization that communicate the mental patterns of a perspective character. Keywords Video game, focalization, Mirror’s Edge, Grand Theft Auto, The Sims, Top Spin, QWOP INTRODUCTION In video games it is typical for the player to be given control of one or more character- avatars that anchor the perspective into the game world. Drawing on cinematic and literary traditions, these characters are commonly provided with detailed personalities, traits, abilities and motivations. In many cases the player’s viewpoint is literally inside the character’s head. And yet rarely does the player know what their character is thinking. -

A Study of Affect, Achievements and Hats in Team Fortress 2, Game Studies, Vol
Deakin Research Online This is the published version: Moore, Christopher 2011, Hats of affect: a study of affect, achievements and hats in Team Fortress 2, Game Studies, vol. 11, no. 1, pp. 1-14. Available from Deakin Research Online: http://hdl.handle.net/10536/DRO/DU:30041568 Reproduced with the kind permission of the copyright owner. Copyright: 2011, The Author. the international journal of volume 11 issue 1 computer game research February 2011 ISSN:1604-7982 home about archive RSS Search Hats of Affect: A Study of Affect, Christopher Moore Achievements and Hats in Team Christopher Moore is a Postdoctoral Research Fortress 2 Fellow at Deakin by Christopher Moore University, Melbourne, and has previously Abstract lectured in Digital An iconic staple of the First-Person Shooter genre, Team Fortress 2 , Communications and is popular for its chaotic action, distinguished by its painterly Games Studies. He aesthetics, and made unique by the introduction of hats as rewards researches the for its players. This study investigates the intersection of virtual appropriative and millinery items, player achievements, user generated content and the creative practices of implications for online gamer personas as they are connected to the gamer subcultures that digital distribution platform, Steam. The article examines the address the issues of iterations of affect involved in the design and play of a game no creativity, identity, longer imagined by its publisher, the Valve Corporation, as a distinct intellectual property, commodity but rather a commercial community service. and technological obsolescence. His Keywords: affect, achievements, persona, FPS, Team Fortress 2 , current focus is an hats ethnography of Australian gamers and content regulation in the Introduction Australian games industry. -

Telltale's Games
Telltale, Inc. Telltale is the first and only company to release interactive episodic content on a monthly 101 Glacier Point, Suite E schedule. Founded in 2004 by industry veterans with a new perspective on gaming, San Rafael, CA 94901 the San Rafael, Calif.-based publisher has over 70 employees and is recognized as Phone: (415) 258-1638 the industry leader in episodic gaming and digitally distributed interactive entertainment. Fax: (415) 258-1795 [email protected] Telltale’s Games www.telltalegames.com Telltale has released more than 25 games across seven franchises, including: Key Milestones • Wallace & Gromit’s™ Grand Adventures: Created in collaboration with Aardman, the studio responsible for the award-winning Wallace & Gromit films, this four-episode • Sold over 1,000,000 series is now releasing on PC and Xbox LIVE® Arcade. episodes across all channels and platforms • Sam & Max™: Telltale’s landmark episodic series, based on the independent comics by • Built proprietary Steve Purcell, paved the way for episodic gaming with two award-winning seasons on interactive storytelling PC and Wii™. Both seasons are coming soon to Xbox LIVE Arcade. technology • Strong Bad’s Cool Game for Attractive People: The first episodic series for • Funded by top-tier WiiWare™ and the first monthly series to appear on any console is based on the investors, including popular HomestarRunner.com web cartoons. Granite Ventures and IDG Ventures SF • Tales of Monkey Island™: Telltale’s newest series, based on the classic LucasArts • Launched direct sales pirate franchise, will launch for PC on July 7 (www.telltalegames.com/monkeyisland). and distribution channel The five-episode series is also coming to WiiWare.