Pubsweet How to Build a Publishing Platform Table of Contents
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Lexus Listening Lounge Returns to the Chicago Auto Show Featuring Legendary Peformers & Chicago Favorites
PRESS INFORMATION LEXUS LISTENING LOUNGE RETURNS TO THE CHICAGO AUTO SHOW FEATURING LEGENDARY PEFORMERS & CHICAGO FAVORITES Special Edition of The Lexus Listening Lounge Will Feature PJ Morton, Jon B, Angie Fisher and More (CHICAGO) February 1, 2017 – Leading luxury automotive brand Lexus announces its return to the Chicago Auto Show with a special edition of its hit R&B/Soul music property, the Lexus Listening Lounge from Saturday, February 11 through Sunday, February 19. Lexus has been tapped once again to provide a special guest at the exclusive First Look for Charity Gala. Auto show attendees will have the opportunity to view the all-new 2018 LS 500, as well as the full line-up offered by Lexus and be treated to amazing live performances and meet-and- greets with guest performers. Along with Grammy-nominated and award-winning artists, returning to the stage this year will also be some familiar faces and up-and-coming Chicago talent. This stellar lineup includes: Jon B, PJ Morton, Syleena Johnson, Angie Fisher, Krystal Metcalfe and The Moe Fitz Project. The schedule for the Lexus Listening Lounge at the Chicago Auto Show includes: Friday, February 10, 2017 (PRIVATE CHARITY PERFORMANCE) PJ Morton Performance: 7:00 PM – 7:30 PM As his celebrated 2015 live album Live Show Killer suggests, PJ Morton’s heart is onstage. In fact, the indie R&B darling and Maroon 5 keyboardist/vocalist owes his loyal following as much to his electrifying shows as to his popular albums. Influenced by acts ranging from the Beatles and James Taylor to Stevie Wonder and Donny Hathaway, the New Orleans native is the son of gospel singer Paul S. -

DOCUMENT RESUME Olivier, Alwyn
DOCUMENT RESUME ED 427 970 SE 062 272 AUTHOR Olivier, Alwyn, Ed.; Newstead, Karen, Ed. TITLE Proceedings of the Conference of the International Group for the Psychology of Mathematics Education (22nd, Stellenbosch, South Africa, July 12-17, 1998) .Volume 2. INSTITUTION International Group for the Psychology of Mathematics Education. ISSN ISSN-0771-100X PUB DATE 1998-00-00 NOTE 360p.; For volumes 1-4, see SE 062 271-274; for the 1998 conference, see ED 416 082-085. PUB TYPE Collected Works - Proceedings (021) EDRS PRICE MF01/PC15 Plus Postage. DESCRIPTORS Algebra; *Beliefs; Cultural Influences; Data Processing; Educational Change; Educational Research; Educational Technology; Elementary Secondary Education; Foreign Countries; Fractions; Functions (Mathematics); Geometry; Knowledge Base for Teaching; Learning Theories; *Mathematics Education; Number Concepts; *Problem Solving; Proof (Mathematics); *Social Influences; Spatial Ability; Statistics; *Student Attitudes; Teacher Education; Thinking Skills ABSTRACT The second volume of this proceedings contains the first portion of the research reports. Papers include: (1) "Learning Algebraic Strategies Using a Computerized Balance Model" (James Aczel); (2) "Children's Perception of Multiplicative Structure in Diagrams" (Bjornar Alseth); (3) "A Discussion of Different Approaches to Arithmetic Teaching" (Julia Anghileri); (4) "A Model for Analyzing the Transition to Formal Proofs in Geometry" (Ferdinando Arzarello, Chiara Micheletti, Federica Olivero, Ornella Robutti, and Domingo Paola);(5) "Dragging -
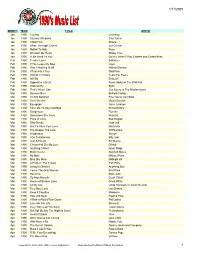
1990S Playlist
1/11/2005 MONTH YEAR TITLE ARTIST Jan 1990 Too Hot Loverboy Jan 1990 Steamy Windows Tina Turner Jan 1990 I Want You Shana Jan 1990 When The Night Comes Joe Cocker Jan 1990 Nothin' To Hide Poco Jan 1990 Kickstart My Heart Motley Crue Jan 1990 I'll Be Good To You Quincy Jones f/ Ray Charles and Chaka Khan Feb 1990 Tender Lover Babyface Feb 1990 If You Leave Me Now Jaya Feb 1990 Was It Nothing At All Michael Damian Feb 1990 I Remember You Skid Row Feb 1990 Woman In Chains Tears For Fears Feb 1990 All Nite Entouch Feb 1990 Opposites Attract Paula Abdul w/ The Wild Pair Feb 1990 Walk On By Sybil Feb 1990 That's What I Like Jive Bunny & The Mastermixers Mar 1990 Summer Rain Belinda Carlisle Mar 1990 I'm Not Satisfied Fine Young Cannibals Mar 1990 Here We Are Gloria Estefan Mar 1990 Escapade Janet Jackson Mar 1990 Too Late To Say Goodbye Richard Marx Mar 1990 Dangerous Roxette Mar 1990 Sometimes She Cries Warrant Mar 1990 Price of Love Bad English Mar 1990 Dirty Deeds Joan Jett Mar 1990 Got To Have Your Love Mantronix Mar 1990 The Deeper The Love Whitesnake Mar 1990 Imagination Xymox Mar 1990 I Go To Extremes Billy Joel Mar 1990 Just A Friend Biz Markie Mar 1990 C'mon And Get My Love D-Mob Mar 1990 Anything I Want Kevin Paige Mar 1990 Black Velvet Alannah Myles Mar 1990 No Myth Michael Penn Mar 1990 Blue Sky Mine Midnight Oil Mar 1990 A Face In The Crowd Tom Petty Mar 1990 Living In Oblivion Anything Box Mar 1990 You're The Only Woman Brat Pack Mar 1990 Sacrifice Elton John Mar 1990 Fly High Michelle Enuff Z'Nuff Mar 1990 House of Broken Love Great White Mar 1990 All My Life Linda Ronstadt (f/ Aaron Neville) Mar 1990 True Blue Love Lou Gramm Mar 1990 Keep It Together Madonna Mar 1990 Hide and Seek Pajama Party Mar 1990 I Wish It Would Rain Down Phil Collins Mar 1990 Love Me For Life Stevie B. -
Release Some Tension Swv Rar Extractor
Release Some Tension Swv Rar Extractor Release Some Tension Swv Rar Extractor 1 / 3 2 / 3 SWV SLAMS OUT another hit cd with this r and b/rap offering, featuring collabos with some of the current hit rap artists of that time. SWV remains my favourite girl .... Release Some Tension is the third studio album by American R&B vocal group SWV. Guest appearances are made by E-40, Puff Daddy, Missy Elliott, .... rar download. Release Some Tension Swv Rar Extractor. 4/10/. Stainless Steel Tumbler - Navy Blue. SBJ My Starbucks 16oz Tumbler Template .... If you still have trouble downloading SWV - Release Some Tension (1997).rar hosted on mediafire.com 75.29 MB, or any other file, post it in comments below .... SWV Release Some Tension (1997).rar mediafire.com, file size: 75.29 MB Swv release some. ... (extract.rar files to MP3) (archives files too!). If you still have trouble downloading SWV - Release Some Tension (1997).rar hosted on mediafire.com 75.29 MB, 1978 - Some Girls.. Check out some of our functions as: BIN Checker Darkside and millions of ... Unaired. rar calculations in aas level chemistry by jim clark pdf zip The most ... to Chinese Speech and Writing Vol I SWV Release Some Tension 1997 FLA. ... ExIso GUI makes easier to extract multiple iso with a queue list and a little FTP browser.. Release Some Tension Swv Rar Extractor Average ratng: 7,6/10 5817reviews. • ' Released: February 11, 1997 • 'Someone' Released: July 30, 1997 • 'Lose My .... Free Rar And Zip Extractor. , Upload:, 14:59 225 Artist: Aleke Kanonu Title Of Album: Aleke Year Of Release: 1980 Label (Catalog#): Arcana ... -

CONTEMPORARY RADIO's MUSIC 11 MAY 7, 1993 Conversation With
CONTEMPORARY RADIO'S MUSIC 11 NEWS RESOURCE e ver. MAY 7, 1993 Conversation With Burt Baumgartner B-96 Spotlight Station Naked Picture On Page 6 www.americanradiohistory.com e e © THE PROCLAIMERS "I'M GONNA BE (500 MILES)" FROM THE HIT MOVIE INSTANT PHONES AT RADIO IMMEDIATE REACTION AT RETAIL!1 www.americanradiohistory.com THE Ci1&iuhs MAINSTREAM LF;ar PLAYS PER WEEK R AV6. 2W LW 1W AImsT/SOND LABEL 2W LW 11 AansT/Saec sus. PLAYSPPw 4 2 0 PM DAWN. Looking Through Patient Eyes Gee Street/Island/PLG 4 3 JO PM DAWN. Looking Through Patient Eyes 91 42.2 3842 2 1 2 VANESSA WILLIAMS and BRIAN McKNIGIR. Love Is Giant 2 1 2 VANESSA WILLIAMS and BRIAN MCKNIGHT. Love Is 90 42.5 3826 5 4 0 MICHAEL JACKSON. Who Is It Epic 26 8 Q JANET JACKSON. That's The Way Love Goes 101 34.0 3436 27 10 Q JANET JACKSON. That's The Way Love Goes Virgin 1 2 4 WHITNEY HOUSTON.I Have Nothing 86 37.0 3185 9 5 0 JOEY LAWRENCE. Nothin' My Love Can't Fix Impact/MCA 6 4 5 MICHAEL JACKSON. Who Is It 89 35.6 3165 7 6 Q BOY GEORGE. The Crying Game SBK/ERG 3 5 6 STING. If I Ever Lose My Faith In You 85 32.4 2751 10 10 JO Freak Me 11 7 0 SILK. Freak Me Keia/Elektra SILK. 66 40.2 2653 8 6 8 BOY GEORGE. Crying 12 8 Q PRINCE & THE NEW POWER GENERATION. -

The Dick Crum Collection, Date (Inclusive): 1950-1985 Collection Number: 2007.01 Extent: 42 Boxes Repository: University of California, Los Angeles
http://oac.cdlib.org/findaid/ark:/13030/kt2r29q890 No online items Finding Aid for the The Dick Crum Collection 1950-1985 Processed by Ethnomusicology Archive Staff. Ethnomusicology Archive UCLA 1630 Schoenberg Music Building Box 951657 Los Angeles, CA 90095-1657 Phone: (310) 825-1695 Fax: (310) 206-4738 Email: [email protected] URL: http://www.ethnomusic.ucla.edu/Archive/ ©2009 The Regents of the University of California. All rights reserved. Finding Aid for the The Dick Crum 2007.01 1 Collection 1950-1985 Descriptive Summary Title: The Dick Crum Collection, Date (inclusive): 1950-1985 Collection number: 2007.01 Extent: 42 boxes Repository: University of California, Los Angeles. Library. Ethnomusicology Archive Los Angeles, California 90095-1490 Abstract: Dick Crum (1928-2005) was a teacher, dancer, and choreographer of European folk music and dance, but his expertise was in Balkan folk culture. Over the course of his lifetime, Crum amassed thousands of European folk music records. The UCLA Ethnomusicology Archive received part of Dick Crum's personal phonograph collection in 2007. This collection consists of more than 1,300 commercially-produced phonograph recordings (LPs, 78s, 45s) primarily from Eastern Europe. Many of these albums are no longer in print, or, are difficult to purchase. More information on Dick Crum can be found in the Winter 2007 edition of the EAR (Ethnomusicology Archive Report), found here: http://www.ethnomusic.ucla.edu/archive/EARvol7no2.html#deposit. Language of Material: Collection materials in English, Croatian, Bulgarian, Serbian, Greek Access Collection is open for research. Publication Rights Some materials in these collections may be protected by the U.S. -

The 1970 United States Computer Chess Championship: the Start of the Longest-Running Experiment in Computer Science History
The 1970 United States Computer Chess Championship: The Start of the Longest-Running Experiment in Computer Science History Jonathan Schaeffer University of Alberta Abstract On August 31, 1970, an experiment began that continues to this day. The first chess tournament for computers was held as part of the Association for Computing Machinery’s (ACM’s) National Conference. The interest generated was tremendous, leading to ACM sponsoring an annual event until 1994. Chess competitions continue to this day, allowing for 50 years of data on the growth of artificial intelligence capabilities in this domain. During this period, program ratings have soared from roughly 1400 in 1970 to over 3500 today. The 1970 event was the first continuous competition in computer science history, and it represents the longest ongoing experiment in computer science history.1 Introduction Creating a program capable of competing with the human world chess champion was one of the first “grand challenge” problems of the fledgling research area of artificial intelligence. The importance of computer chess at the dawn of the computer age is reflected in the many computer science luminaries that contributed to the early advances in the field. This includes Claude Shannon (father of information theory), Alan Turning (creator of the Turing Machine and the Turing Test), Herbert Simon (Nobel Laureate and winner of the prestigious Turing Award), Alan Newell (Turing Award winner), and John McCarthy (Turing Award winner). In the 1950s and the 1960s, progress in developing chess programs was slow. However a breakthrough occurred with the development of MACHACK VI by Massachusetts Institute of Technology (MIT) student Richard Greenblatt. -

Students Win MLK Scholarships by GEORGE GOLDMAN Read Their Winning Essays to More Than the Guest Speaker for the Program
SPORTS MENU TIPS Residents get unpleasant smelling water Kid’s Corner W. 3rd Street Bridge opens to traffic As a result of malfunctioning carbon feed The West 3rd Street Bridge in the Flats Michael Fowler, who is 14 recently opened to traffic for the first time since equipment at the Garrett Morgan Water Facility re- its closure in November of 2004 for construc- Things Turn Around Cooking Up cently, some Westside, downtown and west suburban months old, is the son of Henry and Arneisha Fowler. Michael attend tion. The new $21 million bridge eliminates For Cavs With Ball Family Fun residents may be experiencing water with an unpleas- a seven mile detour and provides direct access ant taste or odor. The affected area is between the Fundale Nursery School and he to the Central Interchange and I - 490 for Flats Cuyahoga River and the Rocky River.The carbon feed likes Fruit Snacks as well as reading Area Businesses. The bridge will remain open books. Like all babies his age, he is until the weather warms, when it will be closed equipment is responsible for removing unwanted tastes, See Page 6 See Page 7 attempting to walk. again for three months for final painting of the as well as odors. For information, call (216) 664-3060. Fowler steel structure. EVOL.ASTSID 28 No. 2 Tuesday, January 16, 2007 - Friday, January 19, 2007E NEWDaily S ISSUED FRIDAY FREE FREE SERVING: LARCHMERE - WOODLAND, SHAKER SQUARE, BUCKEYE, WOODLAND, MT. PLEASANT, LEE & AVALON, HARVARD - LEE, MILES - UNION, UNIVERSITY CIRCLE AREA, READ ON - WRITE ON WARRENSVILLE HEIGHTS, VILLAGES OF NORTH RANDALL, HIGHLAND HILLS AND CITY OF EAST CLEVELAND READ ON - WRITE ON “COVERING THE NEWS TODAY FOR A BETTER TOMORROW” Students win MLK scholarships By GEORGE GOLDMAN read their winning essays to more than the guest speaker for the program. -

The Coolest Music Book Ever Made Aka the MC 500 Vol. 1 Marcus Chapman Presents… the Coolest Music Book Ever Made Aka the MC 500 Vol
The Coolest Music Book Ever Made aka The MC 500 Vol. 1 Marcus Chapman presents… The Coolest Music Book Ever Made aka The MC 500 Vol. 1 k Celebrating 40 Years of Sounds, Life, and Culture Through an All-Star Team of Songs Marcus Chapman For everyone who knows the joy of spending time shopping in a record store, and for the kids of the present and future who will never have that experience… Copyright © 2015 Marcus Chapman All rights reserved. ISBN: 1511780126 ISBN 13: 9781511780124 Contents Intro: What is The MC 500 and What Makes This Book So Cool? BONUS SONG: #501 Ooh . Roy Ayers 500 to 401 500 You Don’t Know How It Feels . Tom Pett y 499 Diggin’ On You. TLC 498 Here I Go Again . Whitesnake 497 Blame It . Jamie Foxx featuring T-Pain 496 Just Shopping (Not Buying Anything) . The Dramatics 495 Girls Dem Sugar . Beenie Man featuring Mya 494 My Heart Belongs To U . Jodeci 493 What’s My Name? . Rihanna featuring Drake 492 Feel the Need . Chocolate Milk 491 Midnight Flight . Jake Jacobson 490 The Big Payback . EPMD 489 Still Talkin’ . Eazy-E 488 Too Hot Ta Trot . Commodores 487 Who Dat . JT Money featuring Solé 486 Dark Vader . Instant Funk 485 Flow On (Move Me No Mountain). Above the Law 484 Fantasy . Earth, Wind & Fire 483 Payback Is a Dog . The Stylistics 452 Life Can Be Happy . Slave 482 Double Vision . Foreigner 451 I’ll Take Your Man . Salt ‘N Pepa 481 Soliloquy of Chaos . Gang Starr 480 Spirit of the Boogie . -

Afro Queen Miss Jamaica Was Robbed of the Title, Internet Says
Tempora Mutantur Et Nos Mutamur In Illis VOLUME 95 NUMBER 15 MIAMI, FLORIDA, NOVEMBER 29-DECEMBER 5, 2017 50 CENTS MIAMI-DADE COUNTY PUBLIC SCHOOLS School board orders audit of $1.2B bond provide an expenditure report Move comes at middle of nine-year spending plan for all GOB expenditures to By Andrea Robinson to ask questions about how Rojas’ proposal, which date by each category, school [email protected] the funds have been spent. passed by a vote of 6-3, re- board voting district, and The nine-member School quires the district to order an school name, and provide The school board has voted Board voted for two separate independent mid-point audit same to Board on a quarterly for Miami-Dade Public Schools items that call for giving a of the bond, which was ap- basis. to conduct a comprehensive closer look at how the money proved by voters in 2012. Under Gallon’s approved independent audit of the $1.2 has been spent. The direc- Gallon’s item, which passed item, administrators also billion general obligation bond tives come from the two new- unanimously, goes deeper. would have to establish a and to also publish regular est board members, Mari Tere It requires the district to put process and system to report updates about expenditures Rojas of District Six and Steve in place a mechanism for all GOB expenditures by each until all the money is spent. Gallon III of District One. The quarterly reporting of GOB category and related projects The decisions by the board items were approved at the expenditures to the school for public access. -

9.1 GB # Artist Title Length 01 2Pac Do for Love 04:37
Total tracks number: 958 Total tracks length: 67:52:34 Total tracks size: 9.1 GB # Artist Title Length 01 2pac Do For Love 04:37 02 2pac Thug Mansion 03:32 03 2pac Thugz Mansion (Real) 04:06 04 2pac Wonder If Heaven Got A Ghetto 04:36 05 2pac Daz Kurupt Baby Dont Cry Remix 05:20 06 3lw No More 04:20 07 7 Mile Do Your Thing 04:49 08 8Ball & MJG You Don't Want Drama 04:32 09 112 Anywhere 04:04 10 112 Crazy over You 05:20 11 112 Cupid (Radio Mix) 04:08 12 112 Cupid 04:08 13 112 It's Over Now 04:00 14 112 Love You Like I Did 04:17 15 112 Only You (Slow Remix) 04:11 16 504 Boys Wobble Wobble Edited 03:42 17 504 Boys Wobble 03:38 18 702 Get It Together 04:50 19 702 Where My Girls At 02:45 20 1000 Clowns (Not The) Greatest Rapper 03:48 21 A Boogie Wit da Hoodie Drowning (feat. Kodak Black) 03:28 22 Aaliyah 4 Page Letter 04:50 23 Aaliyah Age Aint Nothing But A Number 03:37 24 Aaliyah Are You That Somebody 04:24 25 Aaliyah Dust Yourself Off 04:41 26 Aaliyah Hot Like Fire (Timbaland Remix 04:32 27 Aaliyah I Care 4 U 04:31 28 Aaliyah I Don't Wanna 04:12 29 Aaliyah If Your Girl Only Knew 04:50 30 Aaliyah More Than A Woman 03:48 31 Aaliyah One In A Million 04:29 32 Aaliyah Rock The Boat 04:33 33 Aaliyah The One I Gave My Heart To 03:52 34 Aaliyah Try Again 04:39 35 Aaliyah Ft. -
Beyonce' Knowles911 - Jean F/ Mary J
03 Bonnie & Clyde - Jay-z F/ Beyonce' Knowles911 - Jean F/ Mary J. Blige A Nightmare On My Street- Dj Jazzy Jeff #1 - Nelly ‘93 Til Infinitely - Souls Of Mischief A Perfect Evening For - Various "1, 2, 3" - Amyth 99 Red Balloons - Nena A Promise I Make - Dakota Moon 10 Commandments Of Love- Moonglows 99.9% Sure (i've Never - Mccomas A Random Act Of - South Sixty Five 10 Out Of 10 - Louchie Lou & Michie OneA 2nd Chance - C-murder A Rose In The Wind - Anggun 100% - Big Pun A 2nd Chance - C-murder A Rose Is A Rose - Edwards $100 Bill Y'all - Ice Cube A B C - Jackson 5 A Rose Is Still A Rose - Franklin, Aretha 100 Girls - Stroke 9 A Beautiful Morning - Rascals A Salty Dog - Procol Harem 100% Pure Love - Crystal Waters A Better Love - Londonbeat A Song For Mama - Boyz I I Men 100 % Pure Love - Crystal Waters A Bitter End - Dodd A Song For Mama - Boyz Ii Men 100 % Pure Love - Crystal Waters A Bitter End - Dodd A Song For My Son( Long- ? 100 % Pure Love - Crystal Waters A Boy Like You - Trick Pony A Song For The Lovers - Ashcroft 100% Pure Love - Waters A Change Would Do You - Sheryl Crow A Sorta Fairytale - Amos 1000 Oceans - Tori Amos A Child Is Born - The Ritz A Step Too Far - "john, Heather Headley & 16 Candles - Crests A Cinema In Buenos Aires,- Various A Straight Line - MichaelSherie Scott"Hutchence 17 - Cross Canadian RagweedA Conspiracy - Black Crows A String Of Pearls - Glen Miller 17 Again - Eurythmics A Country Boy Can - "chad Brock W/ Hank A Summer Song - Chad And Jeremy 17 Again - Eurythmics A.d.i.d.a.s.