A Bilingual Numeral OCR System for Creating Uni-Lingual Digitized Numeral Document
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
2 . ^
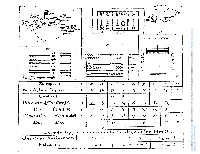
5 SI H.5n§ in 1W>o O0#W #M*V oQfQ P1^^ UUULIULlLJIJ «|\^ » § g_^< Si I J *^ N r-t >* s—. V — K4. i • J , — —1 g . 7 9 ' g •? • £ 7— I > ^ N ^ ^ |=|§ |§ I 1 ^ ^ «^^> to'^"^"?^ R Q a f— —— ^i H . S^oc^o-^^ II 9 11 V? 11 T ? 1 os3000D0- OH: P H "% ^ -J os • ^ CN ^ s * I I I'I «.;©—• !0C " ^ h+> < < < S> ^ %< .XXDHJV«JHiJXa/_L ^ , I I s F" > > * > * 2 . ^\ N^ ,1 ii 5^ ^ ^ ^ <& -* ^ illllllii ^ ^t >^ ^ ^ * XPHPArHCTX \> J o o • o * — * r^^ Downloaded from https://www.cambridge.org/core. Biblio Université Pierre et Marie Curie, on 15 May 2018 at 06:33:09, subject to the Cambridge Core terms of use, available at https://www.cambridge.org/core/terms. https://doi.org/10.1017/S0035869X00018438 Os. Ucrope&Ti i ; -I fe 2, p Malay<damI !r Tkmil Veylorv ci 4* Ex 1 t uropesj h IX) Ikmil I o o I * (to Ceylon Iff* 4 European, 00. 00 3 1" I no I. •s N oi f Ceylon Downloaded from https://www.cambridge.org/core. Biblio Université Pierre et Marie Curie, on 15 May 2018 at 06:33:09, subject to the Cambridge Core terms of use, available at https://www.cambridge.org/core/terms. https://doi.org/10.1017/S0035869X00018438 JOURNAL THE ROYAL ASIATIC SOCIETY. ART. I.—On the Genealogy of Modern Numerals. Part II. Simplification of the Ancient Indian Numeration. By Sir E. OLIVE BAYLEY, K.C.S.I., C.I.E. THE second part of this paper will be occupied by an attempt to show how the ancient Indian system of numeral signs, described in Part L, was simplified. -

Los Nombres De Los Números Ante El Préstamo
LOS NOMBRES DE LOS NÚMEROS ANTE EL PRÉSTAMO FRANCISCO MARCOS MARÍN Al hablar de los números, cabe también la posibilidad de ocuparse de ellos como préstamos. El préstamo de numerales es muy frecuente y no se limita a los escasos ejemplos que aducía un lingüista tan estimable como Jespersen (1922, xi, 11) a finales del primer cuarto de este siglo, aunque su incidencia es también muy variable dentro de los sistemas que lo adoptan. Las diferencias entre préstamos de los números bajos (< 100) y los altos (> 100) no obedezcan a razones lingüísticas, sino el hecho cultural de que muchos pueblos no han desarrollado designaciones para los números superiores, simplemente porque no los necesitaban; cuando, por razones de contacto con otros, generalmente comerciales, estas necesidades han surgido, han tomado esos nombres de los números en préstamos. No obstante, también los préstamos de números bajos, incluso de la primera decena, son moneda corriente en los contactos entre lenguas, con o sin desdoblamiento de designación. Podemos tratar los préstamos bien como cultismos, como préstamos léxi- cos (con sustitución total o aparición de una nueva forma), como préstamos sintácticos, también totales o parciales, e incluso hablaremos de préstamos de sistema. PRÉSTAMOS LÉXICOS El préstamo léxico es, aparentemente, el más frecuente, aunque luego veremos que no es el fundamental. Puede tratarse de un préstamo esporádico o de un préstamo extenso. Como ejemplo de la primera clase el más extendido es sin duda el nombre del conjunto vacío, cero, que procede de la palabra árabe que significa «vacío», sifr, a través del latín zephirum, con una evolución formal que lo sitúa en el grupo de los cultismos, si bien con ciertas peculiari- dades . -

Request to Encode Tamil Fractions §1. Tamil Numerals and Fractions to Be
Request to encode Tamil fractions Shriramana Sharma, jamadagni-at-gmail-dot-com, India 2010-Sep-09 This document replaces L2/09-376, which requested the encoding of the three major fractions used in Tamil and Grantha in the Tamil block. L2/09-398 from INFITT and L2/09- 416 from ICTA Sri Lanka had recommended that the major and minor Tamil fractions be together encoded in the SMP. In accordance with that, this document requests such an encoding in the SMP of fifteen fractions for Tamil, which includes both the major fractions one quarter, one half and three quarters, as well as minor fractions below one quarter. §1. Tamil numerals and fractions to be re-used for Grantha The Tamil digits 0-9 and Tamil numbers 10, 100 and 1000 are already encoded in the Tamil block in the BMP in the range 0BE6-0BF2. Despite their presence in the Tamil block and script=tamil property, they are used in Grantha texts also, as demonstrated in L2/09-372 p 5. Therefore, these same digits and numbers with the script=tamil property will be used along with Grantha characters (with script=grantha) being proposed separately, as recommended by L2/10-053 p 12 (though not in so many words). As there are already (at least) two precedents in: 1. the Devanagari digits 0966-096F with script=devanagari being used with Kaithi (see also N3438), and 2. the Bengali digits 09E6-09EF with script=bengali being used with Syloti Nagri there should not be a problem in the “Tamil” digits, which are in fact the Tamil-Grantha digits, being used with Grantha text as well. -

Numerical Notation: a Comparative History
This page intentionally left blank Numerical Notation Th is book is a cross-cultural reference volume of all attested numerical notation systems (graphic, nonphonetic systems for representing numbers), encompassing more than 100 such systems used over the past 5,500 years. Using a typology that defi es progressive, unilinear evolutionary models of change, Stephen Chrisomalis identifi es fi ve basic types of numerical notation systems, using a cultural phylo- genetic framework to show relationships between systems and to create a general theory of change in numerical systems. Numerical notation systems are prima- rily representational systems, not computational technologies. Cognitive factors that help explain how numerical systems change relate to general principles, such as conciseness and avoidance of ambiguity, which also apply to writing systems. Th e transformation and replacement of numerical notation systems relate to spe- cifi c social, economic, and technological changes, such as the development of the printing press and the expansion of the global world-system. Stephen Chrisomalis is an assistant professor of anthropology at Wayne State Uni- versity in Detroit, Michigan. He completed his Ph.D. at McGill University in Montreal, Quebec, where he studied under the late Bruce Trigger. Chrisomalis’s work has appeared in journals including Antiquity, Cambridge Archaeological Jour- nal, and Cross-Cultural Research. He is the editor of the Stop: Toutes Directions project and the author of the academic weblog Glossographia. Numerical Notation A Comparative History Stephen Chrisomalis Wayne State University CAMBRIDGE UNIVERSITY PRESS Cambridge, New York, Melbourne, Madrid, Cape Town, Singapore, São Paulo, Delhi, Dubai, Tokyo Cambridge University Press The Edinburgh Building, Cambridge CB2 8RU, UK Published in the United States of America by Cambridge University Press, New York www.cambridge.org Information on this title: www.cambridge.org/9780521878180 © Stephen Chrisomalis 2010 This publication is in copyright. -

N Umerations in Tke Sink Ala Language Numerations in the Sinhala Language
Numerations in the Sinhala Language N umerations in tke Sink ala Language Numerations in the Sinhala Language N umerations in tke Sinkala Language by Harsha Wijayawardhana edited by Aruni Goonetilleke 3 Num erations in the Sinhala Language Numerations in the Sinhala Language © Harsha Wijayawardhana 9th Lane, Nawala Road, Rajagiriya, Sri Lanka. [email protected] www.ucsc.cbm.ac.lk/sdu 2009 October ISBN- 978-955-1199-05-0 Design Sanjaya Epa Senevirathna Information and Communication Technology Agency of Sri Lanka All rights reserved. No part of this document may be reporoduced or transmitted in any form or by any means without prior written permission from ICTA. Published Strategic Communications and Media Unit - ICTA 160/24, Kirimandala Mawatha, Colombo 05, Sri Lanka. TP: +94 11 2369099 FAX:+ 94 11 2369091 email: [email protected] web: www.icta.lk Numerations in the Sinhala Language To my parents and to my daughter Panchali. um a.tlions m llie Sinhala Language Preface The research into Sinhala numerals that ICTA initiated has yielded the fact the Sinhala language had several sets of Sinhala numerals, of which two sets had been widely used: one set (Sinhala Illakkam) was in use up to the early part of the nineteenth century, and the other set (Lith Illakkam) was in use well into the 20th century. The latter set clearly includes a zero and a zero place holder. ICTA’s Local Language Working Group, after reviewing the research and after extensive discussions with experts and stakeholders agreed that these two sets should be encoded in (he Sri Lanka Standard Sinhala Character Code for Information Interchange (SLS 1134 : 2004), in the Unicode standard and in ISO/IEC 10646 (the Universal Character set). -

Elements of South-Indian Palaeography, from the Fourth To
This is a reproduction of a library book that was digitized by Google as part of an ongoing effort to preserve the information in books and make it universally accessible. https://books.google.com ELEMENTS SOUTH-INDIAN PALfi3&BAPBY FROM THE FOURTH TO THE SEVENTEENTH CENTURY A. D. BEIN1 AN INTRODUCTION TO ?TIK STUDY OF SOUTH-INDIAN INSCRIPTIONS AND MSS. BY A. C. BURNELL HON'. PH. O. OF TUE UNIVERSITY M. K. A, ri'VORE PIS I. A SOClfcTE MANGALORE \ BASEL MISSION BOOK & TRACT DEPOSITORY ft !<3 1874 19 Vi? TRUBNER & Co. 57 & 69 LUDOATE HILL' . ' \jj *£=ggs3|fg r DISTRIBUTION of S INDIAN alphabets up to 1550 a d. ELEMENTS OF SOUTH-INDIAN PALEOGRAPHY FROM THE FOURTH TO THE SEVENTEENTH CENTURY A. D. BEING AN INTRODUCTION TO THE STUDY OF SOUTH-INDIAN INSCRIPTIONS AND MSS. BY A. p. j^URNELL HON. PH. D. OF THE UNIVERSITY OF STRASSBUB.G; M. R. A. S.; MEMBKE DE LA S0CIETE ASIATIQUE, ETC. ETC. MANGALORE PRINTED BY STOLZ & HIRNER, BASEL MISSION PRESS 1874 LONDON TRtlBNER & Co. 57 & 59 LUDGATE HILL 3« w i d m « t als ^'ctdjcn kr §anltekcit fiir Mc i|jm bdic<jcnc JJoctorMvk ttcsc fetlings^kit auf rincm fejjcr mtfrckntcn Jfclk bet 1®4 INTRODUCTION. I trust that this elementary Sketch of South-Indian Palaeography may supply a want long felt by those who are desirous of investigating the real history of the peninsula of India. Trom the beginning of this century (when Buchanan executed the only archaeological survey that has ever been done in even a part of the South of India) up to the present time, a number of well meaning persons have gone about with much simplicity and faith collecting a mass of rubbish which they term traditions and accept as history. -

On the Genealogy of Modern Numerals
13). ON THE GENEALOGY OF MODERN NUMERALS. PART II. SIR E. CLIVE BAYLEY, K.C.S.I., CLE. 1 ["The Genealogy of Modem Numerals ' is separately printed only for private circulation by the writer. It is published only in the Journal of the Royal Asiatic Society.'] 4- 1 V 8- g 8 1 ON THE GENEALOGY OF MODERN NUMERALS. PART II. SIMPLIFICATION OF THE ANCIENT INDIAN NUMERATION. By Sir E. Clive Bayley, K.C.S.I., CLE. The second part of this paper will be occupied by an attempt to show how the ancient Indian system of numeral signs, described in Part I., was simplified. In other words, it will be attempted to show how this old system became the parent of that now used in India, which employs only nine units and a zero,—indeed of that system as used not in India alone, but now almost universally both in eastern and western countries. Since this simplification of the signs was the outcome of a reform in the system of numeration itself, it becomes necessary to deal to a large extent with the latter also. In entering upon this question however, it is necessary to premise that, as it has already been the subject of long and learned discussions by writers of the highest ability, it cannot be pretended in the present paper to examine it with any degree of completeness. Indeed, the literature of the question is in itself so extensive that it would be impossible, except after years of study and in the compass of a very considerable volume, to attempt an analysis of it, —much less to discuss completely the conflicting views held by many competent authorities. -

Numbering Systems Developed by the Ancient Mesopotamians
Emergent Culture 2011 August http://emergent-culture.com/2011/08/ Home About Contact RSS-Email Alerts Current Events Emergent Featured Global Crisis Know Your Culture Legend of 2012 Synchronicity August, 2011 Legend of 2012 Wednesday, August 31, 2011 11:43 - 4 Comments Cosmic Time Meets Earth Time: The Numbers of Supreme Wholeness and Reconciliation Revealed In the process of writing about the precessional cycle I fell down a rabbit hole of sorts and in the process of finding my way around I made what I think are 4 significant discoveries about cycles of time and the numbers that underlie and unify cosmic and earthly time . Discovery number 1: A painting by Salvador Dali. It turns that clocks are not as bad as we think them to be. The units of time that segment the day into hours, minutes and seconds are in fact reconciled by the units of time that compose the Meso American Calendrical system or MAC for short. It was a surprise to me because one of the world’s foremost authorities in calendrical science the late Dr.Jose Arguelles had vilified the numbers of Western timekeeping as a most grievious error . So much so that he attributed much of the worlds problems to the use of the 12 month calendar and the 24 hour, 60 minute, 60 second day, also known by its handy acronym 12-60 time. I never bought into his argument that the use of those time factors was at fault for our largely miserable human-planetary condition. But I was content to dismiss mechanized time as nothing more than a convenient tool to facilitate the activities of complex societies. -

Science in the Forest, Science in the Past Hbooksau
SCIENCE IN THE FOREST, SCIENCE IN THE PAST HBooksau Director Anne-Christine Taylor Editorial Collective Hylton White Catherine V. Howard Managing Editor Nanette Norris Editorial Staff Michelle Beckett Jane Sabherwal Hau Books are published by the Society for Ethnographic Theory (SET) SET Board of Directors Kriti Kapila (Chair) John Borneman Carlos Londoño Sulkin Anne-Christine Taylor www.haubooks.org SCIENCE IN THE FOREST, SCIENCE IN THE PAST Edited by Geoffrey E. R. Lloyd and Aparecida Vilaça Hau Books Chicago © 2020 Hau Books Originally published as a special issue of HAU: Journal of Ethnographic Theory 9 (1): 36–182. © 2019 Society for Ethnographic Theory Science in the Forest, Science in the Past, edited by Geoffrey E. R. Lloyd and Aparecida Vilaça, is licensed under CC BY-NC-ND 4.0 https://creativecommons.org/licenses/by-nc-nd/4.0/legalcode Cover photo: Carlos Fausto. Used with permission. Cover design: Daniele Meucci and Ania Zayco Layout design: Deepak Sharma, Prepress Plus Typesetting: Prepress Plus (www.prepressplus.in) ISBN: 978-1-912808-41-0 [paperback] ISBN: 978-1-912808-79-3 [ebook] ISBN: 978-1-912808-42-7 [PDF] LCCN: 2020950467 Hau Books Chicago Distribution Center 11030 S. Langley Chicago, Il 60628 www.haubooks.org Publications of Hau Books are printed, marketed, and distributed by The University of Chicago Press. www.press.uchicago.edu Printed in the United States of America on acid-free paper. Contents List of Figures vii Preface viii Geoffrey E. R. Lloyd and Aparecida Vilaça Acknowledgments xii Chapter 1. The Clash of Ontologies and the Problems of Translation and Mutual Intelligibility 1 Geoffrey E. -

A Study on Collation of Languages from Developing Asia
A Study on Collation of Languages from Developing Asia Sarmad Hussain Nadir Durrani Center for Research in Urdu Language Processing National University of Computer and Emerging Sciences www.nu.edu.pk www.idrc.ca Published by Center for Research in Urdu Language Processing National University of Computer and Emerging Sciences Lahore, Pakistan Copyrights © International Development Research Center, Canada Printed by Walayatsons, Pakistan ISBN: 978-969-8961-03-9 This work was carried out with the aid of a grant from the International Development Research Centre (IDRC), Ottawa, Canada, administered through the Centre for Research in Urdu Language Processing (CRULP), National University of Computer and Emerging Sciences (NUCES), Pakistan. ii Preface Defining collation, or what is normally termed as alphabetical order or less frequently as lexicographic order, is one of the first few requirements for enabling computing in any language, second only to encoding, keyboard and fonts. It is because of this critical dependence of computing on collation that its definition is included within the locale of a language. Collation of all written languages are defined in their dictionaries, developed over centuries, and are thus very representative of cultural tradition. However, though it is well understood in these cultures, it is not always thoroughly documented or well understood in the context of existing character encodings, especially the Unicode. Collation is a complex phenomenon, dependent on three factors: script, language and encoding. These factors interact in a complicated fashion to uniquely define the collation sequence for each language. This volume aims to address the complex algorithms needed for sorting out the words in sequence for a subset of the languages. -

Sorting Tamil Words
SSRG International Journal of Computer Science and Engineering (SSRG-IJCSE) – volume 3 issue 2 February 2016 Sorting Tamil Words: Issues and Solutions K.Ponmozhi Assistant Professor, Department of Information Technology, Hajee Karuth Rowther Howdia College Uthamapalayam, Theni, TamilNadu Abstract — There are approximately 65 million have proposed data entry schemes to be used with Tamils in India, and 80 million worldwide. It has been specific fonts which seem to cater to some sort of recognized as Classical Language. Collation is one of character coding for the characters. The multiplicity of the most important features of a script. It determines the fonts seen has posed real problems in arriving at the order in which a given culture indexes its some uniformity in text display. characters. Unicode has become a world standard This was the main theme of discussions and many computer applications have provided during the Tamilnet99 conference [2] held in Chennai Unicode support so that multilingual text can be during February 1999. At this conference, it was handled. It encodes glyphs which have no sound and proposed that the placement of glyphs within a Tamil are not characters in Tamil. The Unicode standard font would follow a recommended scheme. Both proposed for Tamil has not taken into consideration bilingual and monolingual schemes were standardized. some of the important linguistic issues. This leads to The conference also arrived at a standard for data problems in Language processing in Tamil, especially entry in Tamil. Three different keyboard layouts were the sorting which is the basic operation for database arrived at for use by different sections of the users. -

Eastern Arabic Numerals - Wikipedia
Eastern Arabic numerals - Wikipedia https://en.wikipedia.org/wiki/Eastern_Arabic_numerals Eastern Arabic numerals e Eastern Arabic numerals (also called Arabic–Hindu numerals , Arabic Eastern numerals and Indo-Persian numerals ) are the symbols used to represent the Hindu–Arabic numeral system, in conjunction with the Arabic alphabet in the countries of the Mashriq (the east of the Arab world), the Arabian Peninsula, and its ariant in other countries that use the Perso-Arabic script in the Iranian plateau and Asia. Eastern Arabic numerals on a clock Contents in the Cairo Metro. Origin Other names Numerals Usage Contemporary use Notes References Origin e numeral system originates from an ancient Indian numeral system, which was re-introduced in the book On the Calculation with Hindu Numerals wri&en by Clocks in the Ottoman Empire tended to use Eastern Arabic the medie al-era Iranian mathematician and engineer Khwara(mi,[1] whose name numerals. was Latini(ed as Algoritmi .[note 1] Other names Indian numbers") in Arabic. ey are sometimes also called "Indic numerals" in") ﺃﺭﻗﺎﻡ ﻫﻨﺪﻳﺔ ese numbers are known as English. [2] Howe er, that is sometimes discouraged as it can lead to confusion with Indian numerals, used in ,rahmic scripts of India.[3] Numerals Each numeral in the Persian ariant has a di-erent .nicode point e en if it looks identical to the Eastern Arabic numeral counterpart. Howe er the ariants used with .rdu, Sindhi, and other South Asian languages are not encoded separately from the Persian ariants. See .01221 through .01223 and .01241 through .01243. 1 of 3 6/13/2018, 9:46 PM Eastern Arabic numerals - Wikipedia https://en.wikipedia.org/wiki/Eastern_Arabic_numerals Hindu-Arabic numerals 0 1 2 3 4 5 6 7 8 9 ٩ ٨ ٧ ٦ ٥ ٤ ٣ ٢ ١ ٠ Eastern Arabic Perso-Arabic variant ۰ ۱ ۲ ۳ ۴ ۵ ۶ ۷ ۸ ۹ Urdu variant Usage 5ri&en numerals are arranged with their lowest- alue digit to the right, with higher alue positions added to the le6.