Research Article Recognition of Multi-Lingual Handwritten Numerals Using Partial Derivatives
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
2 . ^
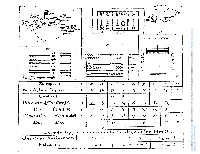
5 SI H.5n§ in 1W>o O0#W #M*V oQfQ P1^^ UUULIULlLJIJ «|\^ » § g_^< Si I J *^ N r-t >* s—. V — K4. i • J , — —1 g . 7 9 ' g •? • £ 7— I > ^ N ^ ^ |=|§ |§ I 1 ^ ^ «^^> to'^"^"?^ R Q a f— —— ^i H . S^oc^o-^^ II 9 11 V? 11 T ? 1 os3000D0- OH: P H "% ^ -J os • ^ CN ^ s * I I I'I «.;©—• !0C " ^ h+> < < < S> ^ %< .XXDHJV«JHiJXa/_L ^ , I I s F" > > * > * 2 . ^\ N^ ,1 ii 5^ ^ ^ ^ <& -* ^ illllllii ^ ^t >^ ^ ^ * XPHPArHCTX \> J o o • o * — * r^^ Downloaded from https://www.cambridge.org/core. Biblio Université Pierre et Marie Curie, on 15 May 2018 at 06:33:09, subject to the Cambridge Core terms of use, available at https://www.cambridge.org/core/terms. https://doi.org/10.1017/S0035869X00018438 Os. Ucrope&Ti i ; -I fe 2, p Malay<damI !r Tkmil Veylorv ci 4* Ex 1 t uropesj h IX) Ikmil I o o I * (to Ceylon Iff* 4 European, 00. 00 3 1" I no I. •s N oi f Ceylon Downloaded from https://www.cambridge.org/core. Biblio Université Pierre et Marie Curie, on 15 May 2018 at 06:33:09, subject to the Cambridge Core terms of use, available at https://www.cambridge.org/core/terms. https://doi.org/10.1017/S0035869X00018438 JOURNAL THE ROYAL ASIATIC SOCIETY. ART. I.—On the Genealogy of Modern Numerals. Part II. Simplification of the Ancient Indian Numeration. By Sir E. OLIVE BAYLEY, K.C.S.I., C.I.E. THE second part of this paper will be occupied by an attempt to show how the ancient Indian system of numeral signs, described in Part L, was simplified. -

The Origins, Evolution and Decline of the Khojki Script
The origins, evolution and decline of the Khojki script Juan Bruce The origins, evolution and decline of the Khojki script Juan Bruce Dissertation submitted in partial fulfilment of the requirements for the Master of Arts in Typeface Design, University of Reading, 2015. 5 Abstract The Khojki script is an Indian script whose origins are in Sindh (now southern Pakistan), a region that has witnessed the conflict between Islam and Hinduism for more than 1,200 years. After the gradual occupation of the region by Muslims from the 8th century onwards, the region underwent significant cultural changes. This dissertation reviews the history of the script and the different uses that it took on among the Khoja people since Muslim missionaries began their activities in Sindh communities in the 14th century. It questions the origins of the Khojas and exposes the impact that their transition from a Hindu merchant caste to a broader Muslim community had on the development of the script. During this process of transformation, a rich and complex creed, known as Satpanth, resulted from the blend of these cultures. The study also considers the roots of the Khojki writing system, especially the modernization that the script went through in order to suit more sophisticated means of expression. As a result, through recording the religious Satpanth literature, Khojki evolved and left behind its mercantile features, insufficient for this purpose. Through comparative analysis of printed Khojki texts, this dissertation examines the use of the script in Bombay at the beginning of the 20th century in the shape of Khoja Ismaili literature. -

Handwriting Recognition in Indian Regional Scripts: a Survey of Offline Techniques
1 Handwriting Recognition in Indian Regional Scripts: A Survey of Offline Techniques UMAPADA PAL, Indian Statistical Institute RAMACHANDRAN JAYADEVAN, Pune Institute of Computer Technology NABIN SHARMA, Indian Statistical Institute Offline handwriting recognition in Indian regional scripts is an interesting area of research as almost 460 million people in India use regional scripts. The nine major Indian regional scripts are Bangla (for Bengali and Assamese languages), Gujarati, Kannada, Malayalam, Oriya, Gurumukhi (for Punjabi lan- guage), Tamil, Telugu, and Nastaliq (for Urdu language). A state-of-the-art survey about the techniques available in the area of offline handwriting recognition (OHR) in Indian regional scripts will be of a great aid to the researchers in the subcontinent and hence a sincere attempt is made in this article to discuss the advancements reported in this regard during the last few decades. The survey is organized into different sections. A brief introduction is given initially about automatic recognition of handwriting and official re- gional scripts in India. The nine regional scripts are then categorized into four subgroups based on their similarity and evolution information. The first group contains Bangla, Oriya, Gujarati and Gurumukhi scripts. The second group contains Kannada and Telugu scripts and the third group contains Tamil and Malayalam scripts. The fourth group contains only Nastaliq script (Perso-Arabic script for Urdu), which is not an Indo-Aryan script. Various feature extraction and classification techniques associated with the offline handwriting recognition of the regional scripts are discussed in this survey. As it is important to identify the script before the recognition step, a section is dedicated to handwritten script identification techniques. -

Adrian Chircu–Buftea, Précis De Morphologie Romane, Casa Cărții De Știință, Cluj-Napoca, 2011, 184 P
book review doi:10.17684/i1A11en DIACRONIA ISSN: 2393-1140 Impavidi progrediamur! www.diacronia.ro Adrian Chircu–Buftea, Précis de morphologie romane, Casa Cărții de Știință, Cluj-Napoca, 2011, 184 p. Anda Bratu∗ Faculty of Letters, “Babeș–Bolyai” University, Str. Horea 31, 400202 Cluj-Napoca, Romania Written in the French language, this volume brings el (elo, lo) / pl. los (elos) vs. esp. mod. masc. (sing.) an important contribution to the study of Romance el (lo) / pl. los”) (p. 39). The declared aim of the languages, which lately have not aroused so much ten chapters is to illustrate the main changes that had the interest of Romanian linguists. In the foreword, taken place in the approached discourse categories in the author confesses that: “le manque d’ouvrages de all the seven Romance languages and, additionally, morphologie romane, surtout en Roumanie, nous a the specificity of each of them. déterminé à concevoir un livre synthétique facile à The approach of this book is based on a great consulter et source de nombreux enseignements lin- variety of examples taken from all the analysed Ro- guistiques” (p. 5). mance languages, examples about which the author This work has an illustrative character and offers claims that are generally constructed. Some of them to those interested information about the evolution are presented within a context “port. Não mani- of the morphological system, from the Latin lan- festou nenhuma surpresa. [Il ne manifeste aucune guage, towards Romance languages. It consists of surprise.]” (p. 78), the others are presented independ- ten synthetic chapters which describe the so-called ently “it. -

Los Nombres De Los Números Ante El Préstamo
LOS NOMBRES DE LOS NÚMEROS ANTE EL PRÉSTAMO FRANCISCO MARCOS MARÍN Al hablar de los números, cabe también la posibilidad de ocuparse de ellos como préstamos. El préstamo de numerales es muy frecuente y no se limita a los escasos ejemplos que aducía un lingüista tan estimable como Jespersen (1922, xi, 11) a finales del primer cuarto de este siglo, aunque su incidencia es también muy variable dentro de los sistemas que lo adoptan. Las diferencias entre préstamos de los números bajos (< 100) y los altos (> 100) no obedezcan a razones lingüísticas, sino el hecho cultural de que muchos pueblos no han desarrollado designaciones para los números superiores, simplemente porque no los necesitaban; cuando, por razones de contacto con otros, generalmente comerciales, estas necesidades han surgido, han tomado esos nombres de los números en préstamos. No obstante, también los préstamos de números bajos, incluso de la primera decena, son moneda corriente en los contactos entre lenguas, con o sin desdoblamiento de designación. Podemos tratar los préstamos bien como cultismos, como préstamos léxi- cos (con sustitución total o aparición de una nueva forma), como préstamos sintácticos, también totales o parciales, e incluso hablaremos de préstamos de sistema. PRÉSTAMOS LÉXICOS El préstamo léxico es, aparentemente, el más frecuente, aunque luego veremos que no es el fundamental. Puede tratarse de un préstamo esporádico o de un préstamo extenso. Como ejemplo de la primera clase el más extendido es sin duda el nombre del conjunto vacío, cero, que procede de la palabra árabe que significa «vacío», sifr, a través del latín zephirum, con una evolución formal que lo sitúa en el grupo de los cultismos, si bien con ciertas peculiari- dades . -

Request to Encode Tamil Fractions §1. Tamil Numerals and Fractions to Be
Request to encode Tamil fractions Shriramana Sharma, jamadagni-at-gmail-dot-com, India 2010-Sep-09 This document replaces L2/09-376, which requested the encoding of the three major fractions used in Tamil and Grantha in the Tamil block. L2/09-398 from INFITT and L2/09- 416 from ICTA Sri Lanka had recommended that the major and minor Tamil fractions be together encoded in the SMP. In accordance with that, this document requests such an encoding in the SMP of fifteen fractions for Tamil, which includes both the major fractions one quarter, one half and three quarters, as well as minor fractions below one quarter. §1. Tamil numerals and fractions to be re-used for Grantha The Tamil digits 0-9 and Tamil numbers 10, 100 and 1000 are already encoded in the Tamil block in the BMP in the range 0BE6-0BF2. Despite their presence in the Tamil block and script=tamil property, they are used in Grantha texts also, as demonstrated in L2/09-372 p 5. Therefore, these same digits and numbers with the script=tamil property will be used along with Grantha characters (with script=grantha) being proposed separately, as recommended by L2/10-053 p 12 (though not in so many words). As there are already (at least) two precedents in: 1. the Devanagari digits 0966-096F with script=devanagari being used with Kaithi (see also N3438), and 2. the Bengali digits 09E6-09EF with script=bengali being used with Syloti Nagri there should not be a problem in the “Tamil” digits, which are in fact the Tamil-Grantha digits, being used with Grantha text as well. -

Latine Disco, Student's Manual
HANS H. ØRBERG PER SE ILLVSTRATA LINGVAPARS I LATINE DISCO LATINASTUDENT’S MANUAL Hans H. Ørberg LINGVA LATINA PER SE ILLVSTRATA Latine Disco Student’s Manual an imprint of Hackett Publishing Company, Inc. Indianapolis/Cambridge Focus Part of the LINGVA LATINA PER SE ILLVSTRATA series For further information on the complete series and new titles, visit www.hackettpublishing.com. Lingua Latina per se illustrata Pars I Latine Disco Student’s Manual © 2001 Hans Ørberg Domus Latina, Skovvangen 7 DK-8500 Grenaa, Danimarca Distributed by Hackett Publishing Co. by agreement with Domus Latina. an imprint of Hackett Publishing Company, Inc. P.O. Box 44937 Indianapolis, Indiana 46244-0937 Focuswww.hackettpublishing.com ISBN 13: 978-1-58510-050-7 All rights are reserved. Printed in the United States of America 21 20 19 18 4 5 6 7 8 Adobe PDF ebook ISBN: 978-1-58510-533-5 CONTENTS Introduction . ............ .............. p. 3 Instructions Chapter 1 ........................................ 9 Chapter 2 .................. ........ .... .. ........ 1 1 Chapter 3 .... .. .. ............ ................... 12 Chapter 4 .. ........ .......... .... ................ 14 Chapter 5 ..... ........ ............... ............ 1 5 Chapter 6 ...... .... .......... .... ............ ... 16 Chapter 7 .. .... .... ............. ............ ..... 1 7 Chapter 8 .......................... ... ........... 1 8 Chapter 9 ...... ........ ...... ... .. ........... .... 1 9 Chapter 10 ...................................... 20 Chapter 11 ... ........ .................. ........ -

Gujarati Handwritten Numeral Optical Character Through Neural Network and Skeletonization
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Diponegoro University Institutional Repository GUJARATI HANDWRITTEN NUMERAL OPTICAL CHARACTER THROUGH NEURAL NETWORK AND SKELETONIZATION Kamal MORO*, Mohammed FAKIR, Badr Dine EL KESSAB, Belaid BOUIKHALENE, Cherki DAOUI (dont delete this line. It is used to insert authors detail) Abstract — This paper deals with an optical character recognition (OCR) system for handwritten Gujarati numbers. One may find so much of work for Indian languages like Hindi, Kannada, Tamil, Bangala, Malayalam, Gurumukhi etc, but Gujarati is a language for which hardly any work is Fig. 2 Confusing Gujarati digits traceable especially for handwritten characters. The features of Gujarati digits are abstracted by four different profiles of This paper addresses the problem of handwritten digits. Skeletonization and binarization are also done for Gujarati numeral recognition. Gujarati numeral preprocessing of handwritten numerals before their recognition requires binarization and skeletonozation as classification. This work has achieved approximately 80,5% of preprocess. Further, profiles are used for feature extraction success rate for Gujarati handwritten digit identification. and artificial neural network (ANN) is suggested for the classification. Index Terms —Optical character recognition, neural network, feature extraction, Gujarati handwritten digits, II. DATABASE skeletonization, classification. For handwritten English numerals, we have the CEDAR (Centre of Excellence for Document Analysis I. INTRODUCTION and Recognition at the University of New York at ujarati belonging to Devnagari family of Buffalo, USA) numeral database. It contains Glanguages, which originated and flourished in approximately 5000 samples of numerals. It contains Gujarat a western state of India, is spoken by over 50 approximately 5000 samples of numerals. -

Roman Population Size: the Logic of the Debate
Princeton/Stanford Working Papers in Classics Roman population size: the logic of the debate Version 2.0 July 2007 Walter Scheidel Stanford University Abstract: This paper provides a critical assessment of the current state of the debate about the number of Roman citizens and the size of the population of Roman Italy. Rather than trying to make a case for a particular reading of the evidence, it aims to highlight the strengths and weaknesses of rival approaches and examine the validity of existing arguments and critiques. After a brief survey of the evidence and the principal positions of modern scholarship, it focuses on a number of salient issues such as urbanization, military service, labor markets, political stability, living standards, and carrying capacity, and considers the significance of field surveys and comparative demographic evidence. © Walter Scheidel. [email protected] 1 1. Roman population size: why it matters Our ignorance of ancient population numbers is one of the biggest obstacles to our understanding of Roman history. After generations of prolific scholarship, we still do not know how many people inhabited Roman Italy and the Mediterranean at any given point in time. When I say ‘we do not know’ I do not simply mean that we lack numbers that are both precise and safely known to be accurate: that would surely be an unreasonably high standard to apply to any pre-modern society. What I mean is that even the appropriate order of magnitude remains a matter of intense dispute. This uncertainty profoundly affects modern reconstructions of Roman history in two ways. First of all, our estimates of overall Italian population number are to a large extent a direct function of our views on the size of the Roman citizenry, and inevitably shape any broader guesses concerning the demography of the Roman empire as a whole. -

Reference Grammar & Lexicon (Incomplete)
Bwangxùd Reference Grammar and Lexicon Andrew Ray Revised: July 6, 2018 Contents 1 Foreword ...................................................... 3 2 Overview ...................................................... 4 2.1 Dialects....................................................... 4 3 Phonology ...................................................... 5 3.1 Inventory...................................................... 5 3.2 Tones and sandhi ................................................. 5 3.3 Morphosyntax................................................... 6 3.4 Phonological processes.............................................. 6 3.5 Vowel allophony.................................................. 7 3.6 Consonant allophony............................................... 7 3.7 Dialectal variations in phonology ........................................ 8 3.7.1 Western coastal dialect............................................. 8 3.7.2 Northern interior dialect............................................ 8 3.7.3 Southern coastal dialect............................................. 8 3.7.4 Southern interior dialect............................................ 8 4 Simple morphology and syntax ......................................... 9 4.1 Word classes.................................................... 9 4.2 Word order..................................................... 9 4.3 Deniteness and surprise............................................. 9 4.4 Noun roles..................................................... 10 4.5 Proximity..................................................... -

Numerical Notation: a Comparative History
This page intentionally left blank Numerical Notation Th is book is a cross-cultural reference volume of all attested numerical notation systems (graphic, nonphonetic systems for representing numbers), encompassing more than 100 such systems used over the past 5,500 years. Using a typology that defi es progressive, unilinear evolutionary models of change, Stephen Chrisomalis identifi es fi ve basic types of numerical notation systems, using a cultural phylo- genetic framework to show relationships between systems and to create a general theory of change in numerical systems. Numerical notation systems are prima- rily representational systems, not computational technologies. Cognitive factors that help explain how numerical systems change relate to general principles, such as conciseness and avoidance of ambiguity, which also apply to writing systems. Th e transformation and replacement of numerical notation systems relate to spe- cifi c social, economic, and technological changes, such as the development of the printing press and the expansion of the global world-system. Stephen Chrisomalis is an assistant professor of anthropology at Wayne State Uni- versity in Detroit, Michigan. He completed his Ph.D. at McGill University in Montreal, Quebec, where he studied under the late Bruce Trigger. Chrisomalis’s work has appeared in journals including Antiquity, Cambridge Archaeological Jour- nal, and Cross-Cultural Research. He is the editor of the Stop: Toutes Directions project and the author of the academic weblog Glossographia. Numerical Notation A Comparative History Stephen Chrisomalis Wayne State University CAMBRIDGE UNIVERSITY PRESS Cambridge, New York, Melbourne, Madrid, Cape Town, Singapore, São Paulo, Delhi, Dubai, Tokyo Cambridge University Press The Edinburgh Building, Cambridge CB2 8RU, UK Published in the United States of America by Cambridge University Press, New York www.cambridge.org Information on this title: www.cambridge.org/9780521878180 © Stephen Chrisomalis 2010 This publication is in copyright. -

Miramo Mmcomposer Reference Guide
Miramo® mmComposer mmComposer Reference Guide VERSION 1.5 Copyright © 2014–2018 Datazone Ltd. All rights reserved. Miramo®, mmChart™, mmComposer™ and fmComposer™ are trademarks of Datazone Ltd. All other trademarks are the property of their respective owners. Readers of this documentation should note that its contents are intended for guidance only, and do not constitute formal offers or undertakings. ‘License Agreement’ This software, called Miramo, is licensed for use by the user subject to the terms of a License Agreement between the user and Datazone Ltd. Use of this software outside the terms of this license agreement is strictly prohibited. Unless agreed otherwise, this License Agreement grants a non-exclusive, non-transferable license to use the software programs and related document- ation in this package (collectively referred to as Miramo) on licensed computers only. Any attempted sublicense, assignment, rental, sale or other transfer of the software or the rights or obligations of the License Agreement without prior written con- sent of Datazone shall be void. In the case of a Miramo Development License, it shall be used to develop applications only and no attempt shall be made to remove the associated watermark included in output documents by any method. The documentation accompanying this software must not be copied or re-distributed to any third-party in either printed, photocopied, scanned or electronic form. The software and documentation are copyrighted. Unless otherwise agreed in writ- ing, copies of the software may be made only for backup and archival purposes. Unauthorized copying, reverse engineering, decompiling, disassembling, and creating derivative works based on the software are prohibited.