Characterizing the Cancer in Lung Adenocarcinoma
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Watsonjn2018.Pdf (1.780Mb)
UNIVERSITY OF CENTRAL OKLAHOMA Edmond, Oklahoma Department of Biology Investigating Differential Gene Expression in vivo of Cardiac Birth Defects in an Avian Model of Maternal Phenylketonuria A THESIS SUBMITTED TO THE GRADUATE FACULTY In partial fulfillment of the requirements For the degree of MASTER OF SCIENCE IN BIOLOGY By Jamie N. Watson Edmond, OK June 5, 2018 J. Watson/Dr. Nikki Seagraves ii J. Watson/Dr. Nikki Seagraves Acknowledgements It is difficult to articulate the amount of gratitude I have for the support and encouragement I have received throughout my master’s thesis. Many people have added value and support to my life during this time. I am thankful for the education, experience, and friendships I have gained at the University of Central Oklahoma. First, I would like to thank Dr. Nikki Seagraves for her mentorship and friendship. I lucked out when I met her. I have enjoyed working on this project and I am very thankful for her support. I would like thank Thomas Crane for his support and patience throughout my master’s degree. I would like to thank Dr. Shannon Conley for her continued mentorship and support. I would like to thank Liz Bullen and Dr. Eric Howard for their training and help on this project. I would like to thank Kristy Meyer for her friendship and help throughout graduate school. I would like to thank my committee members Dr. Robert Brennan and Dr. Lilian Chooback for their advisement on this project. Also, I would like to thank the biology faculty and staff. I would like to thank the Seagraves lab members: Jailene Canales, Kayley Pate, Mckayla Muse, Grace Thetford, Kody Harvey, Jordan Guffey, and Kayle Patatanian for their hard work and support. -

Age-Driven Developmental Drift in the Pathogenesis of Idiopathic Pulmonary Fibrosis
BACK TO BASICS INTERSTITIAL LUNG DISEASES | Age-driven developmental drift in the pathogenesis of idiopathic pulmonary fibrosis Moisés Selman1, Carlos López-Otín2 and Annie Pardo3 Affiliations: 1Instituto Nacional de Enfermedades Respiratorias Ismael Cosío Villegas, Mexico city, Mexico. 2Departamento de Bioquímica y Biología Molecular, Facultad de Medicina, Instituto Universitario de Oncología, Universidad de Oviedo, Oviedo, Spain. 3Facultad de Ciencias, Universidad Nacional Autónoma de México, Mexico city, Mexico. Correspondence: Moisés Selman, Instituto Nacional de Enfermedades Respiratorias, Tlalpan 4502, CP 14080, México DF, México. E-mail: [email protected] ABSTRACT Idiopathic pulmonary fibrosis (IPF) is a progressive and usually lethal disease of unknown aetiology. A growing body of evidence supports that IPF represents an epithelial-driven process characterised by aberrant epithelial cell behaviour, fibroblast/myofibroblast activation and excessive accumulation of extracellular matrix with the subsequent destruction of the lung architecture. The mechanisms involved in the abnormal hyper-activation of the epithelium are unclear, but we propose that recapitulation of pathways and processes critical to embryological development associated with a tissue specific age-related stochastic epigenetic drift may be implicated. These pathways may also contribute to the distinctive behaviour of IPF fibroblasts. Genomic and epigenomic studies have revealed that wingless/ Int, sonic hedgehog and other developmental signalling pathways are reactivated and deregulated in IPF. Moreover, some of these pathways cross-talk with transforming growth factor-β activating a profibrotic feedback loop. The expression pattern of microRNAs is also dysregulated in IPF and exhibits a similar expression profile to embryonic lungs. In addition, senescence, a process usually associated with ageing, which occurs early in alveolar epithelial cells of IPF lungs, likely represents a conserved programmed developmental mechanism. -

SUPPLEMENTARY MATERIAL Bone Morphogenetic Protein 4 Promotes
www.intjdevbiol.com doi: 10.1387/ijdb.160040mk SUPPLEMENTARY MATERIAL corresponding to: Bone morphogenetic protein 4 promotes craniofacial neural crest induction from human pluripotent stem cells SUMIYO MIMURA, MIKA SUGA, KAORI OKADA, MASAKI KINEHARA, HIROKI NIKAWA and MIHO K. FURUE* *Address correspondence to: Miho Kusuda Furue. Laboratory of Stem Cell Cultures, National Institutes of Biomedical Innovation, Health and Nutrition, 7-6-8, Saito-Asagi, Ibaraki, Osaka 567-0085, Japan. Tel: 81-72-641-9819. Fax: 81-72-641-9812. E-mail: [email protected] Full text for this paper is available at: http://dx.doi.org/10.1387/ijdb.160040mk TABLE S1 PRIMER LIST FOR QRT-PCR Gene forward reverse AP2α AATTTCTCAACCGACAACATT ATCTGTTTTGTAGCCAGGAGC CDX2 CTGGAGCTGGAGAAGGAGTTTC ATTTTAACCTGCCTCTCAGAGAGC DLX1 AGTTTGCAGTTGCAGGCTTT CCCTGCTTCATCAGCTTCTT FOXD3 CAGCGGTTCGGCGGGAGG TGAGTGAGAGGTTGTGGCGGATG GAPDH CAAAGTTGTCATGGATGACC CCATGGAGAAGGCTGGGG MSX1 GGATCAGACTTCGGAGAGTGAACT GCCTTCCCTTTAACCCTCACA NANOG TGAACCTCAGCTACAAACAG TGGTGGTAGGAAGAGTAAAG OCT4 GACAGGGGGAGGGGAGGAGCTAGG CTTCCCTCCAACCAGTTGCCCCAAA PAX3 TTGCAATGGCCTCTCAC AGGGGAGAGCGCGTAATC PAX6 GTCCATCTTTGCTTGGGAAA TAGCCAGGTTGCGAAGAACT p75 TCATCCCTGTCTATTGCTCCA TGTTCTGCTTGCAGCTGTTC SOX9 AATGGAGCAGCGAAATCAAC CAGAGAGATTTAGCACACTGATC SOX10 GACCAGTACCCGCACCTG CGCTTGTCACTTTCGTTCAG Suppl. Fig. S1. Comparison of the gene expression profiles of the ES cells and the cells induced by NC and NC-B condition. Scatter plots compares the normalized expression of every gene on the array (refer to Table S3). The central line -
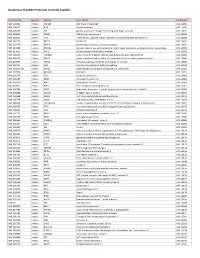
Quantigene Flowrna Probe Sets Currently Available
QuantiGene FlowRNA Probe Sets Currently Available Accession No. Species Symbol Gene Name Catalog No. NM_003452 Human ZNF189 zinc finger protein 189 VA1-10009 NM_000057 Human BLM Bloom syndrome VA1-10010 NM_005269 Human GLI glioma-associated oncogene homolog (zinc finger protein) VA1-10011 NM_002614 Human PDZK1 PDZ domain containing 1 VA1-10015 NM_003225 Human TFF1 Trefoil factor 1 (breast cancer, estrogen-inducible sequence expressed in) VA1-10016 NM_002276 Human KRT19 keratin 19 VA1-10022 NM_002659 Human PLAUR plasminogen activator, urokinase receptor VA1-10025 NM_017669 Human ERCC6L excision repair cross-complementing rodent repair deficiency, complementation group 6-like VA1-10029 NM_017699 Human SIDT1 SID1 transmembrane family, member 1 VA1-10032 NM_000077 Human CDKN2A cyclin-dependent kinase inhibitor 2A (melanoma, p16, inhibits CDK4) VA1-10040 NM_003150 Human STAT3 signal transducer and activator of transcripton 3 (acute-phase response factor) VA1-10046 NM_004707 Human ATG12 ATG12 autophagy related 12 homolog (S. cerevisiae) VA1-10047 NM_000737 Human CGB chorionic gonadotropin, beta polypeptide VA1-10048 NM_001017420 Human ESCO2 establishment of cohesion 1 homolog 2 (S. cerevisiae) VA1-10050 NM_197978 Human HEMGN hemogen VA1-10051 NM_001738 Human CA1 Carbonic anhydrase I VA1-10052 NM_000184 Human HBG2 Hemoglobin, gamma G VA1-10053 NM_005330 Human HBE1 Hemoglobin, epsilon 1 VA1-10054 NR_003367 Human PVT1 Pvt1 oncogene homolog (mouse) VA1-10061 NM_000454 Human SOD1 Superoxide dismutase 1, soluble (amyotrophic lateral sclerosis 1 (adult)) -

140503 IPF Signatures Supplement Withfigs Thorax
Supplementary material for Heterogeneous gene expression signatures correspond to distinct lung pathologies and biomarkers of disease severity in idiopathic pulmonary fibrosis Daryle J. DePianto1*, Sanjay Chandriani1⌘*, Alexander R. Abbas1, Guiquan Jia1, Elsa N. N’Diaye1, Patrick Caplazi1, Steven E. Kauder1, Sabyasachi Biswas1, Satyajit K. Karnik1#, Connie Ha1, Zora Modrusan1, Michael A. Matthay2, Jasleen Kukreja3, Harold R. Collard2, Jackson G. Egen1, Paul J. Wolters2§, and Joseph R. Arron1§ 1Genentech Research and Early Development, South San Francisco, CA 2Department of Medicine, University of California, San Francisco, CA 3Department of Surgery, University of California, San Francisco, CA ⌘Current address: Novartis Institutes for Biomedical Research, Emeryville, CA. #Current address: Gilead Sciences, Foster City, CA. *DJD and SC contributed equally to this manuscript §PJW and JRA co-directed this project Address correspondence to Paul J. Wolters, MD University of California, San Francisco Department of Medicine Box 0111 San Francisco, CA 94143-0111 [email protected] or Joseph R. Arron, MD, PhD Genentech, Inc. MS 231C 1 DNA Way South San Francisco, CA 94080 [email protected] 1 METHODS Human lung tissue samples Tissues were obtained at UCSF from clinical samples from IPF patients at the time of biopsy or lung transplantation. All patients were seen at UCSF and the diagnosis of IPF was established through multidisciplinary review of clinical, radiological, and pathological data according to criteria established by the consensus classification of the American Thoracic Society (ATS) and European Respiratory Society (ERS), Japanese Respiratory Society (JRS), and the Latin American Thoracic Association (ALAT) (ref. 5 in main text). Non-diseased normal lung tissues were procured from lungs not used by the Northern California Transplant Donor Network. -

14Q13 Deletions FTNW
14q13 deletions rarechromo.org 14q13 deletions A chromosome 14 deletion means that part of one of the body’s chromosomes (chromosome 14) has been lost or deleted. If the deleted material contains important genes, learning disability, developmental delay and health problems may occur. How serious these problems are depends on how much of the chromosome has been deleted, which genes have been lost and where precisely the deletion is. The features associated with 14q13 deletions vary from person to person, but are likely to include a degree of developmental delay, an unusually small or large head, a raised risk of medical problems and unusual facial features. Genes and chromosomes Our bodies are made up of billions of cells. Most of these cells contain a complete set of thousands of genes that act as instructions, controlling our growth, development and how our bodies work. Inside human cells there is a nucleus where the genes are carried on microscopically small, thread-like structures called chromosomes which are made up p arm p arm of DNA. p arm p arm Chromosomes come in pairs of different sizes and are numbered from largest to smallest, roughly according to their size, from number 1 to number 22. In addition to these so-called autosomal chromosomes there are the sex chromosomes, X and Y. So a human cell has 46 chromosomes: 23 inherited from the mother and 23 inherited from the father, making two sets of 23 chromosomes. A girl has two X chromosomes (XX) while a boy will have one X and one Y chromosome (XY). -

Appendix 2. Significantly Differentially Regulated Genes in Term Compared with Second Trimester Amniotic Fluid Supernatant
Appendix 2. Significantly Differentially Regulated Genes in Term Compared With Second Trimester Amniotic Fluid Supernatant Fold Change in term vs second trimester Amniotic Affymetrix Duplicate Fluid Probe ID probes Symbol Entrez Gene Name 1019.9 217059_at D MUC7 mucin 7, secreted 424.5 211735_x_at D SFTPC surfactant protein C 416.2 206835_at STATH statherin 363.4 214387_x_at D SFTPC surfactant protein C 295.5 205982_x_at D SFTPC surfactant protein C 288.7 1553454_at RPTN repetin solute carrier family 34 (sodium 251.3 204124_at SLC34A2 phosphate), member 2 238.9 206786_at HTN3 histatin 3 161.5 220191_at GKN1 gastrokine 1 152.7 223678_s_at D SFTPA2 surfactant protein A2 130.9 207430_s_at D MSMB microseminoprotein, beta- 99.0 214199_at SFTPD surfactant protein D major histocompatibility complex, class II, 96.5 210982_s_at D HLA-DRA DR alpha 96.5 221133_s_at D CLDN18 claudin 18 94.4 238222_at GKN2 gastrokine 2 93.7 1557961_s_at D LOC100127983 uncharacterized LOC100127983 93.1 229584_at LRRK2 leucine-rich repeat kinase 2 HOXD cluster antisense RNA 1 (non- 88.6 242042_s_at D HOXD-AS1 protein coding) 86.0 205569_at LAMP3 lysosomal-associated membrane protein 3 85.4 232698_at BPIFB2 BPI fold containing family B, member 2 84.4 205979_at SCGB2A1 secretoglobin, family 2A, member 1 84.3 230469_at RTKN2 rhotekin 2 82.2 204130_at HSD11B2 hydroxysteroid (11-beta) dehydrogenase 2 81.9 222242_s_at KLK5 kallikrein-related peptidase 5 77.0 237281_at AKAP14 A kinase (PRKA) anchor protein 14 76.7 1553602_at MUCL1 mucin-like 1 76.3 216359_at D MUC7 mucin 7, -

Whole-Exome Sequencing of Metastatic Cancer and Biomarkers of Treatment Response
Supplementary Online Content Beltran H, Eng K, Mosquera JM, et al. Whole-exome sequencing of metastatic cancer and biomarkers of treatment response. JAMA Oncol. Published online May 28, 2015. doi:10.1001/jamaoncol.2015.1313 eMethods eFigure 1. A schematic of the IPM Computational Pipeline eFigure 2. Tumor purity analysis eFigure 3. Tumor purity estimates from Pathology team versus computationally (CLONET) estimated tumor purities values for frozen tumor specimens (Spearman correlation 0.2765327, p- value = 0.03561) eFigure 4. Sequencing metrics Fresh/frozen vs. FFPE tissue eFigure 5. Somatic copy number alteration profiles by tumor type at cytogenetic map location resolution; for each cytogenetic map location the mean genes aberration frequency is reported eFigure 6. The 20 most frequently aberrant genes with respect to copy number gains/losses detected per tumor type eFigure 7. Top 50 genes with focal and large scale copy number gains (A) and losses (B) across the cohort eFigure 8. Summary of total number of copy number alterations across PM tumors eFigure 9. An example of tumor evolution looking at serial biopsies from PM222, a patient with metastatic bladder carcinoma eFigure 10. PM12 somatic mutations by coverage and allele frequency (A) and (B) mutation correlation between primary (y- axis) and brain metastasis (x-axis) eFigure 11. Point mutations across 5 metastatic sites of a 55 year old patient with metastatic prostate cancer at time of rapid autopsy eFigure 12. CT scans from patient PM137, a patient with recurrent platinum refractory metastatic urothelial carcinoma eFigure 13. Tracking tumor genomics between primary and metastatic samples from patient PM12 eFigure 14. -

Role and Regulation of the P53-Homolog P73 in the Transformation of Normal Human Fibroblasts
Role and regulation of the p53-homolog p73 in the transformation of normal human fibroblasts Dissertation zur Erlangung des naturwissenschaftlichen Doktorgrades der Bayerischen Julius-Maximilians-Universität Würzburg vorgelegt von Lars Hofmann aus Aschaffenburg Würzburg 2007 Eingereicht am Mitglieder der Promotionskommission: Vorsitzender: Prof. Dr. Dr. Martin J. Müller Gutachter: Prof. Dr. Michael P. Schön Gutachter : Prof. Dr. Georg Krohne Tag des Promotionskolloquiums: Doktorurkunde ausgehändigt am Erklärung Hiermit erkläre ich, dass ich die vorliegende Arbeit selbständig angefertigt und keine anderen als die angegebenen Hilfsmittel und Quellen verwendet habe. Diese Arbeit wurde weder in gleicher noch in ähnlicher Form in einem anderen Prüfungsverfahren vorgelegt. Ich habe früher, außer den mit dem Zulassungsgesuch urkundlichen Graden, keine weiteren akademischen Grade erworben und zu erwerben gesucht. Würzburg, Lars Hofmann Content SUMMARY ................................................................................................................ IV ZUSAMMENFASSUNG ............................................................................................. V 1. INTRODUCTION ................................................................................................. 1 1.1. Molecular basics of cancer .......................................................................................... 1 1.2. Early research on tumorigenesis ................................................................................. 3 1.3. Developing -

Identification of Transcriptional Mechanisms Downstream of Nf1 Gene Defeciency in Malignant Peripheral Nerve Sheath Tumors Daochun Sun Wayne State University
Wayne State University DigitalCommons@WayneState Wayne State University Dissertations 1-1-2012 Identification of transcriptional mechanisms downstream of nf1 gene defeciency in malignant peripheral nerve sheath tumors Daochun Sun Wayne State University, Follow this and additional works at: http://digitalcommons.wayne.edu/oa_dissertations Recommended Citation Sun, Daochun, "Identification of transcriptional mechanisms downstream of nf1 gene defeciency in malignant peripheral nerve sheath tumors" (2012). Wayne State University Dissertations. Paper 558. This Open Access Dissertation is brought to you for free and open access by DigitalCommons@WayneState. It has been accepted for inclusion in Wayne State University Dissertations by an authorized administrator of DigitalCommons@WayneState. IDENTIFICATION OF TRANSCRIPTIONAL MECHANISMS DOWNSTREAM OF NF1 GENE DEFECIENCY IN MALIGNANT PERIPHERAL NERVE SHEATH TUMORS by DAOCHUN SUN DISSERTATION Submitted to the Graduate School of Wayne State University, Detroit, Michigan in partial fulfillment of the requirements for the degree of DOCTOR OF PHILOSOPHY 2012 MAJOR: MOLECULAR BIOLOGY AND GENETICS Approved by: _______________________________________ Advisor Date _______________________________________ _______________________________________ _______________________________________ © COPYRIGHT BY DAOCHUN SUN 2012 All Rights Reserved DEDICATION This work is dedicated to my parents and my wife Ze Zheng for their continuous support and understanding during the years of my education. I could not achieve my goal without them. ii ACKNOWLEDGMENTS I would like to express tremendous appreciation to my mentor, Dr. Michael Tainsky. His guidance and encouragement throughout this project made this dissertation come true. I would also like to thank my committee members, Dr. Raymond Mattingly and Dr. John Reiners Jr. for their sustained attention to this project during the monthly NF1 group meetings and committee meetings, Dr. -

Supplementary Table 1
Supplementary Table 1. 492 genes are unique to 0 h post-heat timepoint. The name, p-value, fold change, location and family of each gene are indicated. Genes were filtered for an absolute value log2 ration 1.5 and a significance value of p ≤ 0.05. Symbol p-value Log Gene Name Location Family Ratio ABCA13 1.87E-02 3.292 ATP-binding cassette, sub-family unknown transporter A (ABC1), member 13 ABCB1 1.93E-02 −1.819 ATP-binding cassette, sub-family Plasma transporter B (MDR/TAP), member 1 Membrane ABCC3 2.83E-02 2.016 ATP-binding cassette, sub-family Plasma transporter C (CFTR/MRP), member 3 Membrane ABHD6 7.79E-03 −2.717 abhydrolase domain containing 6 Cytoplasm enzyme ACAT1 4.10E-02 3.009 acetyl-CoA acetyltransferase 1 Cytoplasm enzyme ACBD4 2.66E-03 1.722 acyl-CoA binding domain unknown other containing 4 ACSL5 1.86E-02 −2.876 acyl-CoA synthetase long-chain Cytoplasm enzyme family member 5 ADAM23 3.33E-02 −3.008 ADAM metallopeptidase domain Plasma peptidase 23 Membrane ADAM29 5.58E-03 3.463 ADAM metallopeptidase domain Plasma peptidase 29 Membrane ADAMTS17 2.67E-04 3.051 ADAM metallopeptidase with Extracellular other thrombospondin type 1 motif, 17 Space ADCYAP1R1 1.20E-02 1.848 adenylate cyclase activating Plasma G-protein polypeptide 1 (pituitary) receptor Membrane coupled type I receptor ADH6 (includes 4.02E-02 −1.845 alcohol dehydrogenase 6 (class Cytoplasm enzyme EG:130) V) AHSA2 1.54E-04 −1.6 AHA1, activator of heat shock unknown other 90kDa protein ATPase homolog 2 (yeast) AK5 3.32E-02 1.658 adenylate kinase 5 Cytoplasm kinase AK7 -

Pan-Cancer Transcriptome Analysis Reveals a Gene Expression
Modern Pathology (2016) 29, 546–556 546 © 2016 USCAP, Inc All rights reserved 0893-3952/16 $32.00 Pan-cancer transcriptome analysis reveals a gene expression signature for the identification of tumor tissue origin Qinghua Xu1,6, Jinying Chen1,6, Shujuan Ni2,3,4,6, Cong Tan2,3,4,6, Midie Xu2,3,4, Lei Dong2,3,4, Lin Yuan5, Qifeng Wang2,3,4 and Xiang Du2,3,4 1Canhelp Genomics, Hangzhou, Zhejiang, China; 2Department of Oncology, Shanghai Medical College, Fudan University, Shanghai, China; 3Department of Pathology, Fudan University Shanghai Cancer Center, Shanghai, China; 4Institute of Pathology, Fudan University, Shanghai, China and 5Pathology Center, Shanghai General Hospital, School of Medicine, Shanghai Jiaotong University, Shanghai, China Carcinoma of unknown primary, wherein metastatic disease is present without an identifiable primary site, accounts for ~ 3–5% of all cancer diagnoses. Despite the development of multiple diagnostic workups, the success rate of primary site identification remains low. Determining the origin of tumor tissue is, thus, an important clinical application of molecular diagnostics. Previous studies have paved the way for gene expression-based tumor type classification. In this study, we have established a comprehensive database integrating microarray- and sequencing-based gene expression profiles of 16 674 tumor samples covering 22 common human tumor types. From this pan-cancer transcriptome database, we identified a 154-gene expression signature that discriminated the origin of tumor tissue with an overall leave-one-out cross-validation accuracy of 96.5%. The 154-gene expression signature was first validated on an independent test set consisting of 9626 primary tumors, of which 97.1% of cases were correctly classified.