Probability Theory
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

3.2.3 Binomial Distribution
3.2.3 Binomial Distribution The binomial distribution is based on the idea of a Bernoulli trial. A Bernoulli trail is an experiment with two, and only two, possible outcomes. A random variable X has a Bernoulli(p) distribution if 8 > <1 with probability p X = > :0 with probability 1 − p, where 0 ≤ p ≤ 1. The value X = 1 is often termed a “success” and X = 0 is termed a “failure”. The mean and variance of a Bernoulli(p) random variable are easily seen to be EX = (1)(p) + (0)(1 − p) = p and VarX = (1 − p)2p + (0 − p)2(1 − p) = p(1 − p). In a sequence of n identical, independent Bernoulli trials, each with success probability p, define the random variables X1,...,Xn by 8 > <1 with probability p X = i > :0 with probability 1 − p. The random variable Xn Y = Xi i=1 has the binomial distribution and it the number of sucesses among n independent trials. The probability mass function of Y is µ ¶ ¡ ¢ n ¡ ¢ P Y = y = py 1 − p n−y. y For this distribution, t n EX = np, Var(X) = np(1 − p),MX (t) = [pe + (1 − p)] . 1 Theorem 3.2.2 (Binomial theorem) For any real numbers x and y and integer n ≥ 0, µ ¶ Xn n (x + y)n = xiyn−i. i i=0 If we take x = p and y = 1 − p, we get µ ¶ Xn n 1 = (p + (1 − p))n = pi(1 − p)n−i. i i=0 Example 3.2.2 (Dice probabilities) Suppose we are interested in finding the probability of obtaining at least one 6 in four rolls of a fair die. -

5 Stochastic Processes
5 Stochastic Processes Contents 5.1. The Bernoulli Process ...................p.3 5.2. The Poisson Process .................. p.15 1 2 Stochastic Processes Chap. 5 A stochastic process is a mathematical model of a probabilistic experiment that evolves in time and generates a sequence of numerical values. For example, a stochastic process can be used to model: (a) the sequence of daily prices of a stock; (b) the sequence of scores in a football game; (c) the sequence of failure times of a machine; (d) the sequence of hourly traffic loads at a node of a communication network; (e) the sequence of radar measurements of the position of an airplane. Each numerical value in the sequence is modeled by a random variable, so a stochastic process is simply a (finite or infinite) sequence of random variables and does not represent a major conceptual departure from our basic framework. We are still dealing with a single basic experiment that involves outcomes gov- erned by a probability law, and random variables that inherit their probabilistic † properties from that law. However, stochastic processes involve some change in emphasis over our earlier models. In particular: (a) We tend to focus on the dependencies in the sequence of values generated by the process. For example, how do future prices of a stock depend on past values? (b) We are often interested in long-term averages,involving the entire se- quence of generated values. For example, what is the fraction of time that a machine is idle? (c) We sometimes wish to characterize the likelihood or frequency of certain boundary events. -

1 Normal Distribution
1 Normal Distribution. 1.1 Introduction A Bernoulli trial is simple random experiment that ends in success or failure. A Bernoulli trial can be used to make a new random experiment by repeating the Bernoulli trial and recording the number of successes. Now repeating a Bernoulli trial a large number of times has an irritating side e¤ect. Suppose we take a tossed die and look for a 3 to come up, but we do this 6000 times. 1 This is a Bernoulli trial with a probability of success of 6 repeated 6000 times. What is the probability that we will see exactly 1000 success? This is de…nitely the most likely possible outcome, 1000 successes out of 6000 tries. But it is still very unlikely that an particular experiment like this will turn out so exactly. In fact, if 6000 tosses did produce exactly 1000 successes, that would be rather suspicious. The probability of exactly 1000 successes in 6000 tries almost does not need to be calculated. whatever the probability of this, it will be very close to zero. It is probably too small a probability to be of any practical use. It turns out that it is not all that bad, 0:014. Still this is small enough that it means that have even a chance of seeing it actually happen, we would need to repeat the full experiment as many as 100 times. All told, 600,000 tosses of a die. When we repeat a Bernoulli trial a large number of times, it is unlikely that we will be interested in a speci…c number of successes, and much more likely that we will be interested in the event that the number of successes lies within a range of possibilities. -

Bernoulli Random Forests: Closing the Gap Between Theoretical Consistency and Empirical Soundness
Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence (IJCAI-16) Bernoulli Random Forests: Closing the Gap between Theoretical Consistency and Empirical Soundness , , , ? Yisen Wang† ‡, Qingtao Tang† ‡, Shu-Tao Xia† ‡, Jia Wu , Xingquan Zhu ⇧ † Dept. of Computer Science and Technology, Tsinghua University, China ‡ Graduate School at Shenzhen, Tsinghua University, China ? Quantum Computation & Intelligent Systems Centre, University of Technology Sydney, Australia ⇧ Dept. of Computer & Electrical Engineering and Computer Science, Florida Atlantic University, USA wangys14, tqt15 @mails.tsinghua.edu.cn; [email protected]; [email protected]; [email protected] { } Traditional Bernoulli Trial Controlled Abstract Tree Node Splitting Tree Node Splitting Random forests are one type of the most effective ensemble learning methods. In spite of their sound Random Attribute Bagging Bernoulli Trial Controlled empirical performance, the study on their theoreti- Attribute Bagging cal properties has been left far behind. Recently, several random forests variants with nice theoreti- Random Structure/Estimation cal basis have been proposed, but they all suffer Random Bootstrap Sampling Points Splitting from poor empirical performance. In this paper, we (a) Breiman RF (b) BRF propose a Bernoulli random forests model (BRF), which intends to close the gap between the theoreti- Figure 1: Comparisons between Breiman RF (left panel) vs. cal consistency and the empirical soundness of ran- the proposed BRF (right panel). The tree node splitting of dom forests classification. Compared to Breiman’s Breiman RF is deterministic, so the final trees are highly data- original random forests, BRF makes two simplifi- dependent. Instead, BRF employs two Bernoulli distributions cations in tree construction by using two indepen- to control the tree construction. -

The Birthday Problem (2.7)
Combinatorics (2.6) The Birthday Problem (2.7) Prof. Tesler Math 186 Winter 2020 Prof. Tesler Combinatorics & Birthday Problem Math 186 / Winter 2020 1 / 29 Multiplication rule Combinatorics is a branch of Mathematics that deals with systematic methods of counting things. Example How many outcomes (x, y, z) are possible, where x = roll of a 6-sided die; y = value of a coin flip; z = card drawn from a 52 card deck? (6 choices of x) × (2 choices of y) × (52 choices of z) = 624 Multiplication rule The number of sequences (x1, x2,..., xk) where there are n1 choices of x1, n2 choices of x2,..., nk choices of xk is n1 · n2 ··· nk. This assumes the number of choices of xi is a constant ni that doesn’t depend on the other choices. Prof. Tesler Combinatorics & Birthday Problem Math 186 / Winter 2020 2 / 29 Addition rule Months and days How many pairs (m, d) are there where m = month 1,..., 12; d = day of the month? Assume it’s not a leap year. 12 choices of m, but the number of choices of d depends on m (and if it’s a leap year), so the total is not “12 × ” Split dates into Am = f (m, d): d is a valid day in month m g: A = A1 [···[ A12 = whole year jAj = jA1j + ··· + jA12j = 31 + 28 + ··· + 31 = 365 Addition rule If A ,..., A are mutually exclusive, then 1 n n n [ Ai = jAij i=1 i=1 X Prof. Tesler Combinatorics & Birthday Problem Math 186 / Winter 2020 3 / 29 Permutations of distinct objects Here are all the permutations of A, B, C: ABC ACB BAC BCA CAB CBA There are 3 items: A, B, C. -

A Note on the Exponentiation Approximation of the Birthday Paradox
A note on the exponentiation approximation of the birthday paradox Kaiji Motegi∗ and Sejun Wooy Kobe University Kobe University July 3, 2021 Abstract In this note, we shed new light on the exponentiation approximation of the probability that all K individuals have distinct birthdays across N calendar days. The exponen- tiation approximation imposes a pairwise independence assumption, which does not hold in general. We sidestep it by deriving the conditional probability for each pair of individuals to have distinct birthdays given that previous pairs do. An interesting im- plication is that the conditional probability decreases in a step-function form |not in a strictly monotonical form| as the more pairs are restricted to have distinct birthdays. The source of the step-function structure is identified and illustrated. The equivalence between the proposed pairwise approach and the existing permutation approach is also established. MSC 2010 Classification Codes: 97K50, 60-01, 65C50. Keywords: birthday problem, pairwise approach, permutation approach, probability. ∗Corresponding author. Graduate School of Economics, Kobe University. 2-1 Rokkodai-cho, Nada, Kobe, Hyogo 657-8501 Japan. E-mail: [email protected] yDepartment of Economics, Kobe University. 2-1 Rokkodai-cho, Nada, Kobe, Hyogo 657-8501 Japan. E-mail: [email protected] 1 1 Introduction Suppose that each of K individuals has his/her birthday on one of N calendar days consid- ered. Let K¯ = f1;:::;Kg be the set of individuals, and let N¯ = f1;:::;Ng be the set of ¯ calendar days, where 2 ≤ K ≤ N. Let Ak;n be an event that individual k 2 K has his/her birthday on day n 2 N¯ . -

A Non-Uniform Birthday Problem with Applications to Discrete Logarithms
A NON-UNIFORM BIRTHDAY PROBLEM WITH APPLICATIONS TO DISCRETE LOGARITHMS STEVEN D. GALBRAITH AND MARK HOLMES Abstract. We consider a generalisation of the birthday problem that arises in the analysis of algorithms for certain variants of the discrete logarithm problem in groups. More precisely, we consider sampling coloured balls and placing them in urns, such that the distribution of assigning balls to urns depends on the colour of the ball. We determine the expected number of trials until two balls of different colours are placed in the same urn. As an aside we present an amusing “paradox” about birthdays. Keywords: birthday paradox, discrete logarithm problem (DLP), probabilistic analysis of randomised algorithms 1. Introduction In the classical birthday problem one samples uniformly with replacement from a set of size N until the same value is sampled twice. It is known that the expected time at which this match first occurs grows as πN/2. The word “birthday” arises from a common application of this result: the expected value of the minimum number of people in a room before two of them have the same birthday is approximately 23.94 (assuming birthdays are uniformly distributed over the year). The birthday problem can be generalised in a number of ways. For example, the assumption that births are uniformly distributed over the days in the year is often false. Hence, researchers have studied the expected time until a match occurs for general distributions. One can also generalise the problem to multi-collisions (e.g., 3 people having the same birthday) or coincidences among individuals of different “types” (e.g., in a room with equal numbers of boys and girls, when can one expect a boy and girl to share the same birthday). -
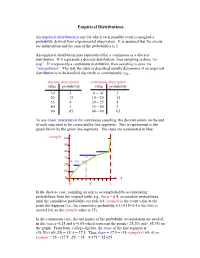
Discrete Distributions: Empirical, Bernoulli, Binomial, Poisson
Empirical Distributions An empirical distribution is one for which each possible event is assigned a probability derived from experimental observation. It is assumed that the events are independent and the sum of the probabilities is 1. An empirical distribution may represent either a continuous or a discrete distribution. If it represents a discrete distribution, then sampling is done “on step”. If it represents a continuous distribution, then sampling is done via “interpolation”. The way the table is described usually determines if an empirical distribution is to be handled discretely or continuously; e.g., discrete description continuous description value probability value probability 10 .1 0 – 10- .1 20 .15 10 – 20- .15 35 .4 20 – 35- .4 40 .3 35 – 40- .3 60 .05 40 – 60- .05 To use linear interpolation for continuous sampling, the discrete points on the end of each step need to be connected by line segments. This is represented in the graph below by the green line segments. The steps are represented in blue: rsample 60 50 40 30 20 10 0 x 0 .5 1 In the discrete case, sampling on step is accomplished by accumulating probabilities from the original table; e.g., for x = 0.4, accumulate probabilities until the cumulative probability exceeds 0.4; rsample is the event value at the point this happens (i.e., the cumulative probability 0.1+0.15+0.4 is the first to exceed 0.4, so the rsample value is 35). In the continuous case, the end points of the probability accumulation are needed, in this case x=0.25 and x=0.65 which represent the points (.25,20) and (.65,35) on the graph. -

Randomization-Based Inference for Bernoulli Trial Experiments And
Article Statistical Methods in Medical Research 2019, Vol. 28(5) 1378–1398 ! The Author(s) 2018 Randomization-based inference for Article reuse guidelines: sagepub.com/journals-permissions Bernoulli trial experiments and DOI: 10.1177/0962280218756689 implications for observational studies journals.sagepub.com/home/smm Zach Branson and Marie-Abe`le Bind Abstract We present a randomization-based inferential framework for experiments characterized by a strongly ignorable assignment mechanism where units have independent probabilities of receiving treatment. Previous works on randomization tests often assume these probabilities are equal within blocks of units. We consider the general case where they differ across units and show how to perform randomization tests and obtain point estimates and confidence intervals. Furthermore, we develop rejection-sampling and importance-sampling approaches for conducting randomization-based inference conditional on any statistic of interest, such as the number of treated units or forms of covariate balance. We establish that our randomization tests are valid tests, and through simulation we demonstrate how the rejection-sampling and importance-sampling approaches can yield powerful randomization tests and thus precise inference. Our work also has implications for observational studies, which commonly assume a strongly ignorable assignment mechanism. Most methodologies for observational studies make additional modeling or asymptotic assumptions, while our framework only assumes the strongly ignorable assignment -

Some Basic Probabilistic Processes
CHAPTER FOUR some basic probabilistic processes This chapter presents a few simple probabilistic processes and develops family relationships among the PMF's and PDF's associated with these processes. Although we shall encounter many of the most common PMF's and PDF's here, it is not our purpose to develop a general catalogue. A listing of the most frequently occurring PRfF's and PDF's and some of their properties appears as an appendix at the end of this book. 4-1 The 8er~ouil1Process A single Bernoulli trial generates an experimental value of discrete random variable x, described by the PMF to expand pkT(z) in a power series and then note the coefficient of zko in this expansion, recalling that any z transform may be written in the form pkT(~)= pk(0) + zpk(1) + z2pk(2) + ' ' This leads to the result known as the binomial PMF, 1-P xo-0 OlPll xo= 1 otherwise where the notation is the common Random variable x, as described above, is known as a Bernoulli random variable, and we note that its PMF has the z transform discussed in Sec. 1-9. Another way to derive the binomial PMF would be to work in a sequential sample space for an experiment which consists of n independ- The sample space for each Bernoulli trial is of the form ent Bernoulli trials, We have used the notation t success (;'') (;'') = Ifailure1 on the nth trial Either by use of the transform or by direct calculation we find We refer to the outcome of a Bernoulli trial as a success when the ex- Each sample point which represents an outcome of exactly ko suc- perimental value of x is unity and as a failure when the experimental cesses in the n trials would have a probability assignment equal to value of x is zero. -

The Matching, Birthday and the Strong Birthday Problem
Journal of Statistical Planning and Inference 130 (2005) 377–389 www.elsevier.com/locate/jspi The matching, birthday and the strong birthday problem: a contemporary review Anirban DasGupta Department of Statistics, Purdue University, 1399 Mathematical Science Building, West Lafayette, IN 47907, USA Received 7 October 2003; received in revised form 1 November 2003; accepted 10 November 2003 Dedicated to Herman Chernoff with appreciation and affection on his 80th birthday Available online 29 July 2004 Abstract This article provides a contemporary exposition at a moderately quantitative level of the distribution theory associated with the matching and the birthday problems. A large number of examples, many not well known, are provided to help a reader have a feeling for these questions at an intuitive level. © 2004 Elsevier B.V. All rights reserved. Keywords: Birthday problem; Coincidences; Matching problem; Poisson; Random permutation; Strong birthday problem 1. Introduction My first exposure to Professor Chernoff’s work was in an asymptotic theory class at the ISI. Later I had the opportunity to read and teach a spectrum of his work on design of experiments, goodness of fit, multivariate analysis and variance inequalities. My own modest work on look-alikes in Section 2.8 here was largely influenced by the now famous Chernoff faces. It is a distinct pleasure to write this article for the special issue in his honor. This article provides an exposition of some of the major questions related to the matching and the birthday problems. The article is partially historical, and partially forward looking. For example, we address a new problem that we call the strong birthday problem. -

Approximations to the Birthday Problem with Unequal Occurrence Probabilities and Their Application to the Surname Problem in Japan*
Ann. Inst. Statist. Math. Vol. 44, No. 3, 479-499 (1992) APPROXIMATIONS TO THE BIRTHDAY PROBLEM WITH UNEQUAL OCCURRENCE PROBABILITIES AND THEIR APPLICATION TO THE SURNAME PROBLEM IN JAPAN* SHIGERU MASE Faculty of Integrated Arts and Sciences, Hiroshima University, Naka-ku, Hiroshima 730, Japan (Received July 4, 1990; revised September 2, 1991) Abstract. Let X1,X2,...,X~ be iid random variables with a discrete dis- tribution {Pi}~=l. We will discuss the coincidence probability Rn, i.e., the probability that there are members of {Xi} having the same value. If m = 365 and p~ ~ 1/365, this is the famous birthday problem. Also we will give two kinds of approximation to this probability. Finally we will give two applica- tions. The first is the estimation of the coincidence probability of surnames in Japan. For this purpose, we will fit a generalized zeta distribution to a fre- quency data of surnames in Japan. The second is the true birthday problem, that is, we will evaluate the birthday probability in Japan using the actual (non-uniform) distribution of birthdays in Japan. Key words and phrases: Birthday problem, coincidence probability, non-uni- formness, Bell polynomial, approximation, surname. I. Introduction It is frequently observed that, even within a small group, there are people with the same surname. It may not be considered so curious to find persons with the same surname in a group compared to those with the same birthday. But if we consider the variety of surnames and the relatively small portions of each surname in some countries, this fact becomes less trivial than is first seen.