Protein-Protein Docking for Interactomic Studies and Its Aplication to Personalized Medicine
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Genome-Wide Analysis of 5-Hmc in the Peripheral Blood of Systemic Lupus Erythematosus Patients Using an Hmedip-Chip
INTERNATIONAL JOURNAL OF MOLECULAR MEDICINE 35: 1467-1479, 2015 Genome-wide analysis of 5-hmC in the peripheral blood of systemic lupus erythematosus patients using an hMeDIP-chip WEIGUO SUI1*, QIUPEI TAN1*, MING YANG1, QIANG YAN1, HUA LIN1, MINGLIN OU1, WEN XUE1, JIEJING CHEN1, TONGXIANG ZOU1, HUANYUN JING1, LI GUO1, CUIHUI CAO1, YUFENG SUN1, ZHENZHEN CUI1 and YONG DAI2 1Guangxi Key Laboratory of Metabolic Diseases Research, Central Laboratory of Guilin 181st Hospital, Guilin, Guangxi 541002; 2Clinical Medical Research Center, the Second Clinical Medical College of Jinan University (Shenzhen People's Hospital), Shenzhen, Guangdong 518020, P.R. China Received July 9, 2014; Accepted February 27, 2015 DOI: 10.3892/ijmm.2015.2149 Abstract. Systemic lupus erythematosus (SLE) is a chronic, Introduction potentially fatal systemic autoimmune disease characterized by the production of autoantibodies against a wide range Systemic lupus erythematosus (SLE) is a typical systemic auto- of self-antigens. To investigate the role of the 5-hmC DNA immune disease, involving diffuse connective tissues (1) and modification with regard to the onset of SLE, we compared is characterized by immune inflammation. SLE has a complex the levels 5-hmC between SLE patients and normal controls. pathogenesis (2), involving genetic, immunologic and envi- Whole blood was obtained from patients, and genomic DNA ronmental factors. Thus, it may result in damage to multiple was extracted. Using the hMeDIP-chip analysis and valida- tissues and organs, especially the kidneys (3). SLE arises from tion by quantitative RT-PCR (RT-qPCR), we identified the a combination of heritable and environmental influences. differentially hydroxymethylated regions that are associated Epigenetics, the study of changes in gene expression with SLE. -

DOWNREGULATION of PAX2 SUPPRESSES OVARIAN CANCER CELL GROWTH Huijuan Song
The Texas Medical Center Library DigitalCommons@TMC The University of Texas MD Anderson Cancer Center UTHealth Graduate School of The University of Texas MD Anderson Cancer Biomedical Sciences Dissertations and Theses Center UTHealth Graduate School of (Open Access) Biomedical Sciences 8-2011 DOWNREGULATION OF PAX2 SUPPRESSES OVARIAN CANCER CELL GROWTH huijuan song Follow this and additional works at: https://digitalcommons.library.tmc.edu/utgsbs_dissertations Part of the Biology Commons, Cancer Biology Commons, Cell Biology Commons, Molecular Biology Commons, and the Molecular Genetics Commons Recommended Citation song, huijuan, "DOWNREGULATION OF PAX2 SUPPRESSES OVARIAN CANCER CELL GROWTH" (2011). The University of Texas MD Anderson Cancer Center UTHealth Graduate School of Biomedical Sciences Dissertations and Theses (Open Access). 165. https://digitalcommons.library.tmc.edu/utgsbs_dissertations/165 This Dissertation (PhD) is brought to you for free and open access by the The University of Texas MD Anderson Cancer Center UTHealth Graduate School of Biomedical Sciences at DigitalCommons@TMC. It has been accepted for inclusion in The University of Texas MD Anderson Cancer Center UTHealth Graduate School of Biomedical Sciences Dissertations and Theses (Open Access) by an authorized administrator of DigitalCommons@TMC. For more information, please contact [email protected]. DOWNREGULATION OF PAX2 SUPPRESSES OVARIAN CANCER CELL GROWTH by Huijuan Song, MD, MS APPROVED: -------------_.-._.__.._----------- APPROVED: Dean, The University of Texas, Health Science Center at Houston Graduate School of Biomedical Sciences DOWNREGULATION OF PAX2 SUPPRESSES OVARIAN CANCER CELL GROWTH A DISSERTATION Presented to the Faculty of The University of Texas Health Science Center at Houston and The University of Texas M. -

CPTC-TP53BP1-1 (CAB079980) Immunohistochemistry Immunofluorescence
CPTC-TP53BP1-1 (CAB079980) Uniprot ID: Q12888 Protein name: TP53B_HUMAN Full name: TP53-binding protein 1 Function: Double-strand break (DSB) repair protein involved in response to DNA damage, telomere dynamics and class-switch recombination (CSR) during antibody genesis (PubMed:12364621, PubMed:22553214, PubMed:23333306, PubMed:17190600, PubMed:21144835, PubMed:28241136). Plays a key role in the repair of double-strand DNA breaks (DSBs) in response to DNA damage by promoting non-homologous end joining (NHEJ)- mediated repair of DSBs and specifically counteracting the function of the homologous recombination (HR) repair protein BRCA1 (PubMed:22553214, PubMed:23727112, PubMed:23333306). In response to DSBs, phosphorylation by ATM promotes interaction with RIF1 and dissociation from NUDT16L1/TIRR, leading to recruitment to DSBs sites (PubMed:28241136). Recruited to DSBs sites by recognizing and binding histone H2A monoubiquitinated at 'Lys-15' (H2AK15Ub) and histone H4 dimethylated at 'Lys-20' (H4K20me2), two histone marks that are present at DSBs sites (PubMed:23760478, PubMed:28241136, PubMed:17190600). Required for immunoglobulin class-switch recombination (CSR) during antibody genesis, a process that involves the generation of DNA DSBs (PubMed:23345425). Participates in the repair and the orientation of the broken DNA ends during CSR (By similarity). In contrast, it is not required for classic NHEJ and V(D)J recombination (By similarity). Promotes NHEJ of dysfunctional telomeres via interaction with PAXIP1 (PubMed:23727112). Subcellular -

Regulation of Cdc42 and Its Effectors in Epithelial Morphogenesis Franck Pichaud1,2,*, Rhian F
© 2019. Published by The Company of Biologists Ltd | Journal of Cell Science (2019) 132, jcs217869. doi:10.1242/jcs.217869 REVIEW SUBJECT COLLECTION: ADHESION Regulation of Cdc42 and its effectors in epithelial morphogenesis Franck Pichaud1,2,*, Rhian F. Walther1 and Francisca Nunes de Almeida1 ABSTRACT An overview of Cdc42 Cdc42 – a member of the small Rho GTPase family – regulates cell Cdc42 was discovered in yeast and belongs to a large family of small – polarity across organisms from yeast to humans. It is an essential (20 30 kDa) GTP-binding proteins (Adams et al., 1990; Johnson regulator of polarized morphogenesis in epithelial cells, through and Pringle, 1990). It is part of the Ras-homologous Rho subfamily coordination of apical membrane morphogenesis, lumen formation and of GTPases, of which there are 20 members in humans, including junction maturation. In parallel, work in yeast and Caenorhabditis elegans the RhoA and Rac GTPases, (Hall, 2012). Rho, Rac and Cdc42 has provided important clues as to how this molecular switch can homologues are found in all eukaryotes, except for plants, which do generate and regulate polarity through localized activation or inhibition, not have a clear homologue for Cdc42. Together, the function of and cytoskeleton regulation. Recent studies have revealed how Rho GTPases influences most, if not all, cellular processes. important and complex these regulations can be during epithelial In the early 1990s, seminal work from Alan Hall and his morphogenesis. This complexity is mirrored by the fact that Cdc42 can collaborators identified Rho, Rac and Cdc42 as main regulators of exert its function through many effector proteins. -

Propranolol-Mediated Attenuation of MMP-9 Excretion in Infants with Hemangiomas
Supplementary Online Content Thaivalappil S, Bauman N, Saieg A, Movius E, Brown KJ, Preciado D. Propranolol-mediated attenuation of MMP-9 excretion in infants with hemangiomas. JAMA Otolaryngol Head Neck Surg. doi:10.1001/jamaoto.2013.4773 eTable. List of All of the Proteins Identified by Proteomics This supplementary material has been provided by the authors to give readers additional information about their work. © 2013 American Medical Association. All rights reserved. Downloaded From: https://jamanetwork.com/ on 10/01/2021 eTable. List of All of the Proteins Identified by Proteomics Protein Name Prop 12 mo/4 Pred 12 mo/4 Δ Prop to Pred mo mo Myeloperoxidase OS=Homo sapiens GN=MPO 26.00 143.00 ‐117.00 Lactotransferrin OS=Homo sapiens GN=LTF 114.00 205.50 ‐91.50 Matrix metalloproteinase‐9 OS=Homo sapiens GN=MMP9 5.00 36.00 ‐31.00 Neutrophil elastase OS=Homo sapiens GN=ELANE 24.00 48.00 ‐24.00 Bleomycin hydrolase OS=Homo sapiens GN=BLMH 3.00 25.00 ‐22.00 CAP7_HUMAN Azurocidin OS=Homo sapiens GN=AZU1 PE=1 SV=3 4.00 26.00 ‐22.00 S10A8_HUMAN Protein S100‐A8 OS=Homo sapiens GN=S100A8 PE=1 14.67 30.50 ‐15.83 SV=1 IL1F9_HUMAN Interleukin‐1 family member 9 OS=Homo sapiens 1.00 15.00 ‐14.00 GN=IL1F9 PE=1 SV=1 MUC5B_HUMAN Mucin‐5B OS=Homo sapiens GN=MUC5B PE=1 SV=3 2.00 14.00 ‐12.00 MUC4_HUMAN Mucin‐4 OS=Homo sapiens GN=MUC4 PE=1 SV=3 1.00 12.00 ‐11.00 HRG_HUMAN Histidine‐rich glycoprotein OS=Homo sapiens GN=HRG 1.00 12.00 ‐11.00 PE=1 SV=1 TKT_HUMAN Transketolase OS=Homo sapiens GN=TKT PE=1 SV=3 17.00 28.00 ‐11.00 CATG_HUMAN Cathepsin G OS=Homo -
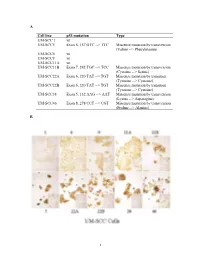
A Cell Line P53 Mutation Type UM
A Cell line p53 mutation Type UM-SCC 1 wt UM-SCC5 Exon 5, 157 GTC --> TTC Missense mutation by transversion (Valine --> Phenylalanine UM-SCC6 wt UM-SCC9 wt UM-SCC11A wt UM-SCC11B Exon 7, 242 TGC --> TCC Missense mutation by transversion (Cysteine --> Serine) UM-SCC22A Exon 6, 220 TAT --> TGT Missense mutation by transition (Tyrosine --> Cysteine) UM-SCC22B Exon 6, 220 TAT --> TGT Missense mutation by transition (Tyrosine --> Cysteine) UM-SCC38 Exon 5, 132 AAG --> AAT Missense mutation by transversion (Lysine --> Asparagine) UM-SCC46 Exon 8, 278 CCT --> CGT Missense mutation by transversion (Proline --> Alanine) B 1 Supplementary Methods Cell Lines and Cell Culture A panel of ten established HNSCC cell lines from the University of Michigan series (UM-SCC) was obtained from Dr. T. E. Carey at the University of Michigan, Ann Arbor, MI. The UM-SCC cell lines were derived from eight patients with SCC of the upper aerodigestive tract (supplemental Table 1). Patient age at tumor diagnosis ranged from 37 to 72 years. The cell lines selected were obtained from patients with stage I-IV tumors, distributed among oral, pharyngeal and laryngeal sites. All the patients had aggressive disease, with early recurrence and death within two years of therapy. Cell lines established from single isolates of a patient specimen are designated by a numeric designation, and where isolates from two time points or anatomical sites were obtained, the designation includes an alphabetical suffix (i.e., "A" or "B"). The cell lines were maintained in Eagle's minimal essential media supplemented with 10% fetal bovine serum and penicillin/streptomycin. -

Ontology-Based Methods for Analyzing Life Science Data
Habilitation a` Diriger des Recherches pr´esent´ee par Olivier Dameron Ontology-based methods for analyzing life science data Soutenue publiquement le 11 janvier 2016 devant le jury compos´ede Anita Burgun Professeur, Universit´eRen´eDescartes Paris Examinatrice Marie-Dominique Devignes Charg´eede recherches CNRS, LORIA Nancy Examinatrice Michel Dumontier Associate professor, Stanford University USA Rapporteur Christine Froidevaux Professeur, Universit´eParis Sud Rapporteure Fabien Gandon Directeur de recherches, Inria Sophia-Antipolis Rapporteur Anne Siegel Directrice de recherches CNRS, IRISA Rennes Examinatrice Alexandre Termier Professeur, Universit´ede Rennes 1 Examinateur 2 Contents 1 Introduction 9 1.1 Context ......................................... 10 1.2 Challenges . 11 1.3 Summary of the contributions . 14 1.4 Organization of the manuscript . 18 2 Reasoning based on hierarchies 21 2.1 Principle......................................... 21 2.1.1 RDF for describing data . 21 2.1.2 RDFS for describing types . 24 2.1.3 RDFS entailments . 26 2.1.4 Typical uses of RDFS entailments in life science . 26 2.1.5 Synthesis . 30 2.2 Case study: integrating diseases and pathways . 31 2.2.1 Context . 31 2.2.2 Objective . 32 2.2.3 Linking pathways and diseases using GO, KO and SNOMED-CT . 32 2.2.4 Querying associated diseases and pathways . 33 2.3 Methodology: Web services composition . 39 2.3.1 Context . 39 2.3.2 Objective . 40 2.3.3 Semantic compatibility of services parameters . 40 2.3.4 Algorithm for pairing services parameters . 40 2.4 Application: ontology-based query expansion with GO2PUB . 43 2.4.1 Context . 43 2.4.2 Objective . -

For Reference Only
Datasheet Version: 1.0.0 Revision date: 05 Nov 2020 Histone H3R2me2a Antibody Catalogue No.:abx000029 Western blot analysis of extracts of various cell lines, using Asymmetric Dimethyl-Histone H3- R2 antibody (abx000029). Dot-blot analysis of various methylation peptides using Asymmetric Dimethyl-Histone H3-R2 antibody (abx000029). Immunofluorescence analysis of 293T cells using Asymmetric Dimethyl-Histone H3-R2 antibody (abx000029). Blue: DAPI for nuclear staining. Histone H3R2me2a Antibody is a Rabbit Polyclonal antibody against Histone H3R2me2a. Histones are basic nuclear proteins that are responsible for the nucleosome structure of the chromosomal fiber in eukaryotes. Nucleosomes consist of approximately 146 bp of DNA wrapped around a histone octamer composed of pairs of each of the four core histones (H2A, H2B, H3, and H4). The chromatin fiber is further compacted through the interaction of a linker histone, H1, with the DNA between the nucleosomes to form higher order chromatin structures. This gene is intronless and encodes a member of the histone H3 family. TranscriptsFor from this Reference gene lack polyA tails; instead, they contain a palindromic Only termination element. This gene is located separately from the other H3 genes that are in the histone gene cluster on chromosome 6p22-p21.3. Target: Histone H3R2me2a Clonality: Polyclonal Reactivity: Human, Mouse, Rat v1.0.0 Abbexa Ltd, Cambridge, UK · Phone: +44 1223 755950 · Fax: +44 1223 755951 1 Abbexa LLC, Houston, TX, USA · Phone: +1 832 327 7413 www.abbexa.com · Email: [email protected] Datasheet Version: 1.0.0 Revision date: 05 Nov 2020 Tested Applications: WB, IHC, IF/ICC, IP, ChIP Host: Rabbit Recommended dilutions: WB: 1/500 - 1/2000, IHC: 1/50 - 1/200, IF/ICC: 1/50 - 1/200, IP: 1/50 - 1/200, ChIP: 1/20 - 1/100, ChIPseq: 1/20 - 1/100. -

S41467-020-18249-3.Pdf
ARTICLE https://doi.org/10.1038/s41467-020-18249-3 OPEN Pharmacologically reversible zonation-dependent endothelial cell transcriptomic changes with neurodegenerative disease associations in the aged brain Lei Zhao1,2,17, Zhongqi Li 1,2,17, Joaquim S. L. Vong2,3,17, Xinyi Chen1,2, Hei-Ming Lai1,2,4,5,6, Leo Y. C. Yan1,2, Junzhe Huang1,2, Samuel K. H. Sy1,2,7, Xiaoyu Tian 8, Yu Huang 8, Ho Yin Edwin Chan5,9, Hon-Cheong So6,8, ✉ ✉ Wai-Lung Ng 10, Yamei Tang11, Wei-Jye Lin12,13, Vincent C. T. Mok1,5,6,14,15 &HoKo 1,2,4,5,6,8,14,16 1234567890():,; The molecular signatures of cells in the brain have been revealed in unprecedented detail, yet the ageing-associated genome-wide expression changes that may contribute to neurovas- cular dysfunction in neurodegenerative diseases remain elusive. Here, we report zonation- dependent transcriptomic changes in aged mouse brain endothelial cells (ECs), which pro- minently implicate altered immune/cytokine signaling in ECs of all vascular segments, and functional changes impacting the blood–brain barrier (BBB) and glucose/energy metabolism especially in capillary ECs (capECs). An overrepresentation of Alzheimer disease (AD) GWAS genes is evident among the human orthologs of the differentially expressed genes of aged capECs, while comparative analysis revealed a subset of concordantly downregulated, functionally important genes in human AD brains. Treatment with exenatide, a glucagon-like peptide-1 receptor agonist, strongly reverses aged mouse brain EC transcriptomic changes and BBB leakage, with associated attenuation of microglial priming. We thus revealed tran- scriptomic alterations underlying brain EC ageing that are complex yet pharmacologically reversible. -

PREDICTD: Parallel Epigenomics Data Imputation with Cloud-Based Tensor Decomposition
bioRxiv preprint doi: https://doi.org/10.1101/123927; this version posted April 4, 2017. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC 4.0 International license. PREDICTD: PaRallel Epigenomics Data Imputation with Cloud-based Tensor Decomposition Timothy J. Durham Maxwell W. Libbrecht Department of Genome Sciences Department of Genome Sciences University of Washington University of Washington J. Jeffry Howbert Jeff Bilmes Department of Genome Sciences Department of Electrical Engineering University of Washington University of Washington William Stafford Noble Department of Genome Sciences Department of Computer Science and Engineering University of Washington April 4, 2017 Abstract The Encyclopedia of DNA Elements (ENCODE) and the Roadmap Epigenomics Project have produced thousands of data sets mapping the epigenome in hundreds of cell types. How- ever, the number of cell types remains too great to comprehensively map given current time and financial constraints. We present a method, PaRallel Epigenomics Data Imputation with Cloud-based Tensor Decomposition (PREDICTD), to address this issue by computationally im- puting missing experiments in collections of epigenomics experiments. PREDICTD leverages an intuitive and natural model called \tensor decomposition" to impute many experiments si- multaneously. Compared with the current state-of-the-art method, ChromImpute, PREDICTD produces lower overall mean squared error, and combining methods yields further improvement. We show that PREDICTD data can be used to investigate enhancer biology at non-coding human accelerated regions. PREDICTD provides reference imputed data sets and open-source software for investigating new cell types, and demonstrates the utility of tensor decomposition and cloud computing, two technologies increasingly applicable in bioinformatics. -

SNM1A (DCLRE1A) (NM 001271816) Human Tagged ORF Clone Product Data
OriGene Technologies, Inc. 9620 Medical Center Drive, Ste 200 Rockville, MD 20850, US Phone: +1-888-267-4436 [email protected] EU: [email protected] CN: [email protected] Product datasheet for RC235137 SNM1A (DCLRE1A) (NM_001271816) Human Tagged ORF Clone Product data: Product Type: Expression Plasmids Product Name: SNM1A (DCLRE1A) (NM_001271816) Human Tagged ORF Clone Tag: Myc-DDK Symbol: DCLRE1A Synonyms: PSO2; SNM1; SNM1A Vector: pCMV6-Entry (PS100001) E. coli Selection: Kanamycin (25 ug/mL) Cell Selection: Neomycin ORF Nucleotide >RC235137 representing NM_001271816 Sequence: Red=Cloning site Blue=ORF Green=Tags(s) TTTTGTAATACGACTCACTATAGGGCGGCCGGGAATTCGTCGACTGGATCCGGTACCGAGGAGATCTGCC GCCGCGATCGCC ATGTTAGAAGACATTTCCGAAGAAGACATTTGGGAATACAAATCTAAAAGAAAACCAAAACGAGTTGATC CAAATAATGGCTCTAAAAATATTCTAAAATCTGTTGAAAAAGCAACAGATGGAAAATACCAGTCAAAACG GAGTAGAAACAGAAAAAGAGCCGCAGAAGCTAAAGAGGTGAAGGACCATGAAGTGCCCCTTGGAAATGCA GGTTGTCAGACTTCTGTTGCTTCTAGTCAGAATTCAAGTTGTGGAGATGGTATTCAGCAGACCCAAGACA AGGAAACTACTCCAGGAAAACTCTGTAGAACTCAAAAAAGCCAACACGTGTCCCCAAAGATACGTCCAGT TTATGATGGATACTGTCCAAATTGCCAGATGCCTTTTTCCTCATTGATAGGGCAGACACCTCGATGGCAT GTTTTTGAATGTTTGGATTCTCCACCACGCTCTGAAACAGAGTGTCCTGATGGTCTTCTGTGTACCTCAA CCATTCCTTTTCATTACAAGAGATACACTCACTTCCTGCTAGCTCAAAGCAGGGCTGGTGATCATCCTTT TAGCAGCCCATCACCTGCGTCAGGTGGCAGTTTCAGTGAGACTAAGTCAGGCGTCCTTTGTAGCCTTGAG GAAAGATGGTCTTCGTATCAGAACCAAACTGATAACTCGGTTTCAAATGATCCCTTATTGATGACACAGT ATTTTAAAAAGTCTCCGTCTCTGACTGAAGCCAGTGAAAAGATTTCTACTCATATCCAAACATCCCAACA AGCTCTACAATTTACAGATTTTGTTGAGAATGACAAACTAGTGGGAGTTGCTTTGCGTCTTGCAAACAAC -

Aneuploidy: Using Genetic Instability to Preserve a Haploid Genome?
Health Science Campus FINAL APPROVAL OF DISSERTATION Doctor of Philosophy in Biomedical Science (Cancer Biology) Aneuploidy: Using genetic instability to preserve a haploid genome? Submitted by: Ramona Ramdath In partial fulfillment of the requirements for the degree of Doctor of Philosophy in Biomedical Science Examination Committee Signature/Date Major Advisor: David Allison, M.D., Ph.D. Academic James Trempe, Ph.D. Advisory Committee: David Giovanucci, Ph.D. Randall Ruch, Ph.D. Ronald Mellgren, Ph.D. Senior Associate Dean College of Graduate Studies Michael S. Bisesi, Ph.D. Date of Defense: April 10, 2009 Aneuploidy: Using genetic instability to preserve a haploid genome? Ramona Ramdath University of Toledo, Health Science Campus 2009 Dedication I dedicate this dissertation to my grandfather who died of lung cancer two years ago, but who always instilled in us the value and importance of education. And to my mom and sister, both of whom have been pillars of support and stimulating conversations. To my sister, Rehanna, especially- I hope this inspires you to achieve all that you want to in life, academically and otherwise. ii Acknowledgements As we go through these academic journeys, there are so many along the way that make an impact not only on our work, but on our lives as well, and I would like to say a heartfelt thank you to all of those people: My Committee members- Dr. James Trempe, Dr. David Giovanucchi, Dr. Ronald Mellgren and Dr. Randall Ruch for their guidance, suggestions, support and confidence in me. My major advisor- Dr. David Allison, for his constructive criticism and positive reinforcement.