Table of Contents
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Changing Needs: Can the Common European Framework Be the Standard for English Proficiency Testing?
Changing Needs: Can the Common European Framework Be the Standard for English Proficiency Testing? Yoshihiro Omura 1 . Introduction There are numerous English proficiency exams available today in Japan as well as in the world. In fact, test takers have the luxury of choosing which one they prefer. However, are all such tests able to measure an individual's proficiency level accurately, consistently, and at approximately the same competence level? Do all the exams test the skills needed for specific purposes, such as academic and/or professional work, as they claim? This paper will classify, review and compare most of the globally recognized English proficiency exams, as well as a few others offered mostly in Japan, in terms of tested skills, availability, format, cost and acceptability. This paper focuses on globally available English exams that test general English proficiency for adults and, thus, does not thoroughly review English exams that are available only in a single country or English exams for children. English proficiency exams that are available only in a specific country include General English Proficiency Test (GEPT) in Taiwan, and Test of English Proficiency Developed by Seoul National University (TEPS), Test of Oral Proficiency in English (TOP), and Test of Written Proficiency in English (TWP) in South Korea. English for specific purposes are listed in Table 5 and briefly reviewed. Exams for younger learners include London Tests of English for Children, Cambridge Young Learners English Tests, and Jido EIKEN (or English Proficiency Tests for children offered in Japan). 2 . The Common European Framework of Reference for Languages Is it, then, possible to compare the test results on one test to another based upon comparisons? As Taylor (2004) states, the "ability to relate different tests to one another in useful and meaningful ways is becoming more and more important for test users (p. -

A List of Certificates Confirming the Knowledge of a Modern Foreign Language at the Level of at Least B2, Recognized by the Doctoral School in the Recruitment Process
Appendix no 4 to the Admission Rules to the Doctoral School of the Stanisław Moniuszko Academy of Music in Gdańsk in the academic year 2020/2021 A list of certificates confirming the knowledge of a modern foreign language at the level of at least B2, recognized by the Doctoral School in the recruitment process. Persons who do not have any of the certificates listed below before matriculation will have to pass an exam in a modern foreign language at B2 level, organized by the Foreign Languages Unit of the Stanisław Moniuszko Academy of Music in Gdańsk. This exam will be held in September 20..... Certificates confirming at least B2 level of global language proficiency according to the "Common European Framework of Reference for Languages: learning, teaching, assessment (CEFR)": 1. Certificate confirming the knowledge of a foreign language, issued by the National School of Public Administration as a result of a linguistic verification procedure. 2. Certificates confirming at least B2 level of global language proficiency according to the "Common European Framework of Reference for Languages: learning, teaching, assessment (CEFR)": 1) certificates issued by institutions associated in the Association of Language Testers in Europe (ALTE) - ALTE Level 3 (B2), ALTE Level 4 (C1), ALTE Level 5 (C2), in particular the certificates: a) First Certificate in English (FCE), Certificate in Advanced English (CAE), Certificate of Proficiency in English (CPE), Business English Certificate (BEC) Vantage — at least Pass, Business English Certificate (BEC) -

Language Requirements
Language Policy NB: This Language Policy applies to applicants of the 20J and 20D MBA Classes. For all other MBA Classes, please use this document as a reference only and be sure to contact the MBA Admissions Office for confirmation. Last revised in October 2018. Please note that this Language Policy document is subject to change regularly and without prior notice. 1 Contents Page 3 INSEAD Language Proficiency Measurement Scale Page 4 Summary of INSEAD Language Requirements Page 5 English Proficiency Certification Page 6 Entry Language Requirement Page 7 Exit Language Requirement Page 8 FL&C contact details Page 9 FL&C Language courses available Page 12 FL&C Language tests available Page 13 Language Tuition Prior to starting the MBA Programme Page 15 List of Official Language Tests recognised by INSEAD Page 22 Frequently Asked Questions 2 INSEAD Language Proficiency Measurement Scale INSEAD uses a four-level scale which measures language competency. This is in line with the Common European Framework of Reference for language levels (CEFR). Below is a table which indicates the proficiency needed to fulfil INSEAD language requirement. To be admitted to the MBA Programme, a candidate must be fluent level in English and have at least a practical level of knowledge of a second language. These two languages are referred to as your “Entry languages”. A candidate must also have at least a basic level of understanding of a third language. This will be referred to as “Exit language”. LEVEL DESCRIPTION INSEAD REQUIREMENTS Ability to communicate spontaneously, very fluently and precisely in more complex situations. -
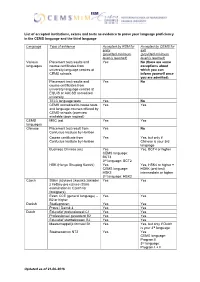
List of Accepted Institutions, Exams and Tests As Evidence to Prove Your Language Proficiency in the CEMS Language and the Third Language
List of accepted institutions, exams and tests as evidence to prove your language proficiency in the CEMS language and the third language Language Type of evidence Accepted by RSM for Accepted by CEMS for entry exit (provided minimum (provided minimum level is reached) level is reached) Various Placement test results and Yes No (there are some languages course certificates from exceptions about university language centres at which you can CEMS schools inform yourself once you are admitted) Placement test results and Yes No course certificates from university language centres at EQUIS or AACSB accredited university TELC language tests Yes No CEMS accredited in-house tests Yes Yes and language courses offered by CEMS-schools (overview available upon request) CEMS MBC test Yes Yes languages Chinese Placement test result from Yes No Confucius Institute by Hanban Course certificate from Yes Yes, but only if Confucius Institute by Hanban Chinese is your 3rd language Business Chinese test Yes Yes, BCT4 or higher CEMS language: BCT3 3rd language: BCT2 HSK (Hanyu Shuiping Kaoshi) Yes Yes, HSK4 or higher + CEMS language: HSKK (oral test) HSK3 intermediate or higher 3rd language: HSK2 Czech Státní jazyková zkouška základní Yes Yes z češtiny pro cizince (State examination in Czech for foreigners) Exam CCE (general language) – Yes Yes B2 or higher Danish Studieprøven Yes Yes Prøve i Dansk 3 Yes Yes Dutch Educatief professioneel C1 Yes Yes Professioneel gevorderd B2 Yes Yes Educatief startbekwaam B2 Yes Yes Maatschappelijk formeel B1 Yes Yes, but only -

Fremdsprachenzertifikate in Der Schule
FREMDSPRACHENZERTIFIKATE IN DER SCHULE Handreichung März 2014 Referat 522 Fremdsprachen, Bilingualer Unterricht und Internationale Abschlüsse Redaktion: Henny Rönneper 2 Vorwort Fremdsprachenzertifikate in den Schulen in Nordrhein-Westfalen Sprachen öffnen Türen, diese Botschaft des Europäischen Jahres der Sprachen gilt ganz besonders für junge Menschen. Das Zusammenwachsen Europas und die In- ternationalisierung von Wirtschaft und Gesellschaft verlangen die Fähigkeit, sich in mehreren Sprachen auszukennen. Fremdsprachenkenntnisse und interkulturelle Er- fahrungen werden in der Ausbildung und im Studium zunehmend vorausgesetzt. Sie bieten die Gewähr dafür, dass Jugendliche die Chancen nutzen können, die ihnen das vereinte Europa für Mobilität, Begegnungen, Zusammenarbeit und Entwicklung bietet. Um die fremdsprachliche Bildung in den allgemein- und berufsbildenden Schulen in Nordrhein-Westfalen weiter zu stärken, finden in Nordrhein-Westfalen internationale Zertifikatsprüfungen in vielen Sprachen statt, an denen jährlich mehrere tausend Schülerinnen und Schüler teilnehmen. Sie erwerben internationale Fremdsprachen- zertifikate als Ergänzung zu schulischen Abschlusszeugnissen und zum Europäi- schen Portfolio der Sprachen und erreichen damit eine wichtige Zusatzqualifikation für Berufsausbildungen und Studium im In- und Ausland. Die vorliegende Informationsschrift soll Lernende und Lehrende zu fremdsprachli- chen Zertifikatsprüfungen ermutigen und ihnen angesichts der wachsenden Zahl an- gebotener Zertifikate eine Orientierungshilfe geben. -

Types of Documents Confirming the Knowledge of a Foreign Language by Foreigners
TYPES OF DOCUMENTS CONFIRMING THE KNOWLEDGE OF A FOREIGN LANGUAGE BY FOREIGNERS 1. Diplomas of completion of: 1) studies in the field of foreign languages or applied linguistics; 2) a foreign language teacher training college 3) the National School of Public Administration (KSAP). 2. A document issued abroad confirming a degree or a scientific title – certifies the knowledge of the language of instruction 3. A document confirming the completion of higher or postgraduate studies conducted abroad or in Poland - certifies the knowledge of the language only if the language of instruction was exclusively a foreign language. 4. A document issued abroad that is considered equivalent to the secondary school-leaving examination certificate - certifies the knowledge of the language of instruction 5. International Baccalaureate Diploma. 6. European Baccalaureate Diploma. 7. A certificate of passing a language exam organized by the following Ministries: 1) the Ministry of Foreign Affairs; 2) the ministry serving the minister competent for economic affairs, the Ministry of Cooperation with Foreign Countries, the Ministry of Foreign Trade and the Ministry of Foreign Trade and Marine Economy; 3) the Ministry of National Defense - level 3333, level 4444 according to the STANAG 6001. 8. A certificate confirming the knowledge of a foreign language, issued by the KSAP as a result of linguistic verification proceedings. 9. A certificate issued by the KSAP confirming qualifications to work on high-rank state administration positions. 10. A document confirming -

Exploring Language Frameworks
Exploring Language Frameworks Proceedings of the ALTE Kraków Conference, July 2011 For a complete list of titles please visit: http://www.cambridge.org/elt/silt Also in this series: Experimenting with Uncertainty: Essays in Assessing Academic English: Testing honour of Alan Davies English profi ciency 1950–1989 – the IELTS Edited by C. Elder, A. Brown, E. Grove, K. Hill, solution N. Iwashita, T. Lumley, T. McNamara, Alan Davies K. O’Loughlin Impact Theory and Practice: Studies of the An Empirical Investigation of the IELTS test and Progetto Lingue 2000 Componentiality of L2 Reading in English for Roger Hawkey Academic Purposes IELTS Washback in Context: Preparation for Edited by Cyril J. Weir, Yang Huizhong, Jin Yan academic writing in higher education The Equivalence of Direct and Semi- direct Anthony Green Speaking Tests Examining Writing: Research and practice in Kieran O’Loughlin assessing second language writing A Qualitative Approach to the Validation of Stuart D. Shaw and Cyril J. Weir Oral Language Tests Multilingualism and Assessment: Achieving Anne Lazaraton transparency, assuring quality, sustaining Continuity and Innovation: Revising the diversity – Proceedings of the ALTE Berlin Cambridge Profi ciency in English Examination Conference, May 2005 1913–2002 Edited by Lynda Taylor and Cyril J. Weir Edited by Cyril J. Weir and Michael Milanovic Examining FCE and CAE: Key issues and A Modular Approach to Testing English recurring themes in developing the First Language Skills: The development of the Certifi cate in English and Certifi cate in Certifi cates in English Language Skills (CELS) Advanced English exams examination Roger Hawkey Roger Hawkey Language Testing Matters: Investigating Issues in Testing Business English: The revision the wider social and educational impact of the Cambridge Business English Certifi cates of assessment – Proceedings of the ALTE Barry O’Sullivan Cambridge Conference, April 2008 European Language Testing in a Global Edited by Lynda Taylor and Cyril J. -

Procesos Administrativos De La Traducción Certificada
COLEGIO DE TRADUCTORES DEL PERÚ Creado por Ley n.° 26684 PROCESOS ADMINISTRATIVOS DE LA TRADUCCIÓN CERTIFICADA Modificado en la Asamblea General Extraordinaria del 4 de noviembre de 2015 Modificado en la Asamblea General Extraordinaria del 14 de diciembre de 2017 Modificado en la Asamblea General Extraordinaria del 8 de julio de 2020 TABLA DE CONTENIDOS PROCESO DE CERTIFICACIÓN DE LOS TRADUCTORES COLEGIADOS ........................................... 3 Curso de certificación ........................................................................................................... 3 Proceso de actualización ...................................................................................................... 3 Certificación en lenguas de titulación ................................................................................... 3 Certificación en lenguas adicionales ..................................................................................... 4 Proceso de adquisición de carátulas ......................................................................................... 5 Proceso de registro en la Plataforma CTP-TCCD ....................................................................... 5 ANEXO 01: ............................................................................................................................... 6 FICHA DE REGISTRO COMO TRADUCTOR COLEGIADO CERTIFICADO ......................................... 6 ANEXO 02: .............................................................................................................................. -

Akzeptierte Zertifikate Für Den Nachweis Der Sprachkenntnisse (Zulassung Masterstudium Translation)
Akzeptierte Zertifikate für den Nachweis der Sprachkenntnisse (Zulassung Masterstudium Translation) SPRACHE AKZEPTIERTE/S LINK ANMERKUNGEN INFORMATION ZERTIFIKAT/E Deutsch ÖSD – Österreichisches Sprachdiplom Deutsch http://www.osd.at/default.aspx?SIid Ab 2015: ÖSD-Zertifikat =17&LAid=1&ARid=109 WD/C2 Vor 2015: ÖSD-Zertifikat „C2 Wirtschaftssprache Deutsch“ https://www.goethe.de/de/spr/kup/ Goethe-Zertifikat C2: prf/prf/gzc2.html GDS Dieses Zertifikat wird unter dieser Bezeichnung seit 2012 vergeben. Vor 2012 werden folgende Zertifikate des Goethe- Instituts anerkannt: ZOP – Zentrale Oberstufenprüfung GDS – Großes Deutsches https://www.telc.net/ Sprachdiplom • telc – The European Language Certificates telc – Deutsch C2 • DSH – Deutsche Sprachprüfung für den Hochschulzugang DSH III B/K/S CEFR2 http://www.lingvisti.ba (Bosnisch) http://croaticum.ffzg.unizg.hr/?page _id=1110 (Kroatisch) http://www.srpskijezik.edu.rs/index .php?id=1160&jzk=sr (Serbisch: Национални сертификат о познавању српског језика за странце) Chinesisch HSK 6 http://www.hsk-pruefung.de/ TOCFL Level 5 http://de.wikipedia http://www.hskpruefung. .org/wiki/Test_of_ de/HSK_6.html Chinese_as_a_Fore ign_Language Englisch GERS C2 (CERF C2) http://www.europaeischerreferenzrahmen. TOEFL (online Test) de Score: Mindestens 115; IELTS - Score 9 entspricht C2 Cambridge Proficiency: Ab Grade C Cambridge Advanced Certificate: Grade A (TOEIC geht nur bis C1) Französisch DALF 2 http://institutfrancais. at/vienne/de/pruefungen/d elf-dalf/praesentation.html http://www.ciep.fr/de/delf-delfversion- -

LTRC 2016 Exe Abb.Indd 1 03/06/16 15:42 More Than Four Decades of Research Supports the Validity of the TOEFL® Family of Assessments
38th Annual Language Testing Research Colloquium June 20-24, 2016 Palermo, Sicily (Italy) LANGUAGE CONSTRUCTS, CONTEXTS, AND LTRC CONTENT IN CLASSROOM AND 2016 LARGE-SCALE ASSESSMENTS libro_convegno_LTRC 2016_exe_abb.indd 1 03/06/16 15:42 More than four decades of research supports the validity of the TOEFL® Family of Assessments Read the latest journal articles and reports on the TOEFL® Family of Assessments. Analyzing and Comparing Reading Stimulus Materials Across the TOEFL® Family of Assessments (2015). Chen, J., & Sheehan, K. M. TOEFL iBT Research Report No. 26. Princeton, NJ: ETS. Comparing Writing Performance in TOEFL iBT ® and Academic Assignments: An Exploration of Textual Features. (2016). Riazi, A. M. Assessing Writing, 28, 15–27. Designing the TOEFL® Primary™ Tests. (2016). Cho, Y., Ginsburgh, M., Morgan, R., Moulder, B., Xi, X., & Hauck, M. C. Research Memorandum No. RM-16-02. Princeton, NJ: ETS. Different Topics, Different Discourse: Relationships Among Writing Topic, Measures of Syntactic Complexity, and Judgments of Writing Quality. (2015). Yang, W., Lu, X., & Weigle, S. Journal of Second Language Writing, 28, 53–67. Effects of Strength of Accent on an L2 Interactive Lecture Listening Comprehension Test. (In press). Ockey, G. J., Papageorgiou, S., & French, R. International Journal of Listening. Enhancing the Interpretability of the Overall Results of an International Test of English-language Proficiency. (2015). Papageorgiou, S., Morgan, R., & Becker, V. International Journal of Testing, 15, 310–336. Evaluating the TOEFL Junior® Standard Test as a Measure of Progress for Young English Language Learners. (2015). Gu, L., Lockwood, J., & Powers, D. E. (2015). ETS Research Report RR-15-22. Princeton, NJ: ETS. -

Learning and Assessment: Making the Connections
Learning and Assessment: Making the Connections 3–5 May 2017 CONFERENCE PROCEEDINGS In collaboration with and supported by Association of Language Testers in Europe, 1 Hills Road, Cambridge CB1 2EU, United Kingdom www.alte.org © ALTE, September 2017 This publication is in copyright. No reproduction of any part may take place without appropriate acknowledgement or the written permission of ALTE. If you would like to quote any part of this work, please use the following details: ALTE (2017). Learning and Assessment: Making the Connections – Proceedings of the ALTE 6th International Conference, 3-5 May 2017. The opinions expressed in this work are those of the authors and do not necessarily reflect the views of ALTE. ALTE has no responsibility for the persistence or accuracy of URLs for external or third-party internet websites referred to in this publication, and does not guarantee that any content on such websites is, or will remain, accurate or appropriate. Learning and Assessment: Making the Connections ALTE 6th International Conference, 3-5 May 2017 CONFERENCE PROCEEDINGS Editor/Production Lead Esther Gutiérrez Eugenio, ALTE Secretariat Manager Production Team John Savage, Publications Assistant, Cambridge English Language Assessment Mariangela Marulli, ALTE Secretariat Coordinator Alison French, Consultant Acknowledgements We would like to extend our most sincere thanks to all the contributors who have diligently replied to all our queries (even during the summer months) and thus allowed this publication to come to life on such a tight schedule. Conference Proceedings Learning and Assessment: Making the Connections … in a globalised economy ............................................................................................... 1 La Verifica come Occasione di Apprendimento e Aggiornamento Attraverso l’Esperienza della Certificazione Glottodidattica DILS-PG di II Livello ................................................................................................................................. -

ALTE Framework 2018
ALTE Framework 2018 A1 A2 B1 B2 C1 C2 Language Organisation Pre-A1 ALTE Breakthrough ALTE Level 1 ALTE Level 2 ALTE Level 3 ALTE Level 4 ALTE Level 5 Euskararen Gaitasun Agiria (EGA) Re-audit Nov 2021 Basque Government Eusko Jaurlaritza Basque Euskara Euskararen Gaitasun Agiria (EGA) • Re-audit Oct 2018 Government of Navarre Gobierno de Navarra Standardised Test in Bulgarian as a Foreign Sofia University St. Language B2 Kliment Ohridski – Re-audit March 2019 Department for Language Teaching - Bulgarian DLTIS Български език Софийски университет "Св. Климент Охридски" – Департамент за езиково обучение – ДЕО Version date: 27/02/2018 ALTE Framework 2018 A1 A2 B1 B2 C1 C2 Language Organisation Pre-A1 ALTE Breakthrough ALTE Level 1 ALTE Level 2 ALTE Level 3 ALTE Level 4 ALTE Level 5 Nivell superior de català Catalan Generalitat of Catalonia Audit pending Català Generalitat de Catalunya Charles University in The Czech Language The Czech Language The Czech Language The Czech Language The Czech Language Prague, Institute for Certificate Exam (CCE) Certificate Exam (CCE) Certificate Exam (CCE) Certificate Exam (CCE) Certificate Exam (CCE) Language and A1 A2 B1 B2 C1 Czech Preparatory Studies Re-audit Jan 2021 Re-audit Jan 2021 Re-audit Jan 2021 Re-audit Jan 2021 Re-audit Jan 2021 (ILPS) Čeština Univerzita Karlova v Praze, Ústav jazykové a odborné přípravy, (ÚJOP UK) Prøve i Dansk 1 (PD1) Prøve i Dansk 2 (PD2) Prøve i Dansk 3 (PD3) The Ministry for Re-audit Oct 2022 Re-audit Oct 2022 Re-audit Oct 2022 Danish Foreigners and Integration