A Comprehensive 3D Biomechanically-Driven Vocal Tract Model Including Inverse Dynamics for Speech Research
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Ear Pain in Patients with Oropharynx Carcinoma: Karlt.Beer Peter Vock How MRI Contributes to the Explanation Richard H
Eur Radiol (2004) 14:2206–2211 DOI 10.1007/s00330-004-2340-2 HEAD AND NECK Harriet C. Thoeny Ear pain in patients with oropharynx carcinoma: KarlT.Beer Peter Vock how MRI contributes to the explanation Richard H. Greiner of a prognostic and predictive symptom Received: 22 October 2003 Abstract Reflex otalgia is a predic- glossus muscle, stylopharyngeus Revised: 11 March 2004 tive and prognostic parameter for lo- muscle, hyoglossus muscle and pre- Accepted: 5 April 2004 cal control in patients with orophar- epiglottic space. No difference was Published online: 1 May 2004 ynx carcinoma. Can a morphologic found for the muscles of mastication, © Springer-Verlag 2004 correlate of this important symptom levator and tensor veli palatini mus- be detected by MRI? Thirty-six pa- cles, styloglossus muscle, genioglos- tients were prospectively evaluated sus muscle, intrinsic muscles of the by MRI before radical radiotherapy. tongue, digastric muscles, mucosal Sixteen patients had reflex otalgia; surface of the lateral and posterior 20 did not. The oropharynx and adja- pharyngeal wall, uvula, valleculae, cent regions were analyzed. Alter- parapharyngeal space and larynx. An ation was defined as effacement of alteration of structures innervated by H. C. Thoeny (✉) · P. Vock anatomical structures, signal alter- the glossopharyngeal nerve was vi- Department of Diagnostic Radiology, ation or enhancement after contrast sualized on MRI significantly more Inselspital, χ2 University of Bern, medium administration. The -test often when reflex otalgia was pres- Freiburgstrasse 10, 3010 Bern, Switzerland was used to compare categorical pa- ent. Involvement of structures inner- e-mail: [email protected], rameters. In patients with reflex vated by other cranial nerves did not [email protected] otalgia, alteration of the following show the same association with ear Tel.: +41-31-6322939 structures innervated by the glosso- pain. -

Volume 1: the Upper Extremity
Volume 1: The Upper Extremity 1.1 The Shoulder 01.00 - 38.20 (37.20) 1.1.1 Introduction to shoulder section 0.01.00 0.01.28 0.28 1.1.2 Bones, joints, and ligaments 1 Clavicle, scapula 0.01.29 0.05.40 4.11 1.1.3 Bones, joints, and ligaments 2 Movements of scapula 0.05.41 0.06.37 0.56 1.1.4 Bones, joints, and ligaments 3 Proximal humerus 0.06.38 0.08.19 1.41 Shoulder joint (glenohumeral joint) Movements of shoulder joint 1.1.5 Review of bones, joints, and ligaments 0.08.20 0.09.41 1.21 1.1.6 Introduction to muscles 0.09.42 0.10.03 0.21 1.1.7 Muscles 1 Long tendons of biceps, triceps 0.10.04 0.13.52 3.48 Rotator cuff muscles Subscapularis Supraspinatus Infraspinatus Teres minor Teres major Coracobrachialis 1.1.8 Muscles 2 Serratus anterior 0.13.53 0.17.49 3.56 Levator scapulae Rhomboid minor and major Trapezius Pectoralis minor Subclavius, omohyoid 1.1.9 Muscles 3 Pectoralis major 0.17.50 0.20.35 2.45 Latissimus dorsi Deltoid 1.1.10 Review of muscles 0.20.36 0.21.51 1.15 1.1.11 Vessels and nerves: key structures First rib 0.22.09 0.24.38 2.29 Cervical vertebrae Scalene muscles 1.1.12 Blood vessels 1 Veins of the shoulder region 0.24.39 0.27.47 3.08 1.1.13 Blood vessels 2 Arteries of the shoulder region 0.27.48 0.30.22 2.34 1.1.14 Nerves The brachial plexus and its branches 0.30.23 0.35.55 5.32 1.1.15 Review of vessels and nerves 0.35.56 0.38.20 2.24 1.2. -

Functional Anatomy of the Soft Palate Applied to Wind Playing
Review Functional Anatomy of the Soft Palate Applied to Wind Playing Alison Evans, MMus, Bronwen Ackermann, PhD, and Tim Driscoll, PhD Wind players must be able to sustain high intraoral pressures in dition occurs because of a structural deformity, such as with order to play their instruments. Prolonged exposure to these high cleft palate. It is also associated with some other speech dis- pressures may lead to the performance-related disorder velopharyn- orders. VPI occurs when the soft palate fails to completely geal insufficiency (VPI). This disorder occurs when the soft palate fails to completely close the air passage between the oral and nasal close the oronasal cavity while attempting to blow air through cavities in the upper respiratory cavity during blowing tasks, this clo- the mouth, resulting in air escaping from the nose.5 Without sure being necessary for optimum performance on a wind instru- a tight air seal, the air passes into the nasal cavity and can ment. VPI is potentially career threatening. Improving music teach- then escape out the nose. This has a disastrous effect on wind ers’ and students’ knowledge of the mechanism of velopharyngeal playing, as the power behind the wind musicians’ sound closure may assist in avoiding potentially catastrophic performance- related disorders arising from dysfunction of the soft palate. In the relies on enough controlled expired air through the mouth. functional anatomy of the soft palate as applied to wind playing, Understandably, this disorder may potentially end the musi- seven muscles of the soft palate involved in the velopharyngeal clo- cian’s career.6 sure mechanism are reviewed. -

Appendix B: Muscles of the Speech Production Mechanism
Appendix B: Muscles of the Speech Production Mechanism I. MUSCLES OF RESPIRATION A. MUSCLES OF INHALATION (muscles that enlarge the thoracic cavity) 1. Diaphragm Attachments: The diaphragm originates in a number of places: the lower tip of the sternum; the first 3 or 4 lumbar vertebrae and the lower borders and inner surfaces of the cartilages of ribs 7 - 12. All fibers insert into a central tendon (aponeurosis of the diaphragm). Function: Contraction of the diaphragm draws the central tendon down and forward, which enlarges the thoracic cavity vertically. It can also elevate to some extent the lower ribs. The diaphragm separates the thoracic and the abdominal cavities. 2. External Intercostals Attachments: The external intercostals run from the lip on the lower border of each rib inferiorly and medially to the upper border of the rib immediately below. Function: These muscles may have several functions. They serve to strengthen the thoracic wall so that it doesn't bulge between the ribs. They provide a checking action to counteract relaxation pressure. Because of the direction of attachment of their fibers, the external intercostals can raise the thoracic cage for inhalation. 3. Pectoralis Major Attachments: This muscle attaches on the anterior surface of the medial half of the clavicle, the sternum and costal cartilages 1-6 or 7. All fibers come together and insert at the greater tubercle of the humerus. Function: Pectoralis major is primarily an abductor of the arm. It can, however, serve as a supplemental (or compensatory) muscle of inhalation, raising the rib cage and sternum. (In other words, breathing by raising and lowering the arms!) It is mentioned here chiefly because it is encountered in the dissection. -

Anatomy and Physiology of the Velopharyngeal Mechanism
Anatomy and Physiology of the Velopharyngeal Mechanism Jamie L. Perry, Ph.D.1 ABSTRACT Understanding the normal anatomy and physiology of the velopharyngeal mechanism is the first step in providing appropriate diagnosis and treatment for children born with cleft lip and palate. The velopharyngeal mechanism consists of a muscular valve that extends from the posterior surface of the hard palate (roof of mouth) to the posterior pharyngeal wall and includes the velum (soft palate), lateral pharyngeal walls (sides of the throat), and the posterior pharyngeal wall (back wall of the throat). The function of the velopharyngeal mechanism is to create a tight seal between the velum and pharyngeal walls to separate the oral and nasal cavities for various purposes, including speech. Velopharyngeal closure is accomplished through the contraction of several velopharyngeal muscles including the levator veli palatini, musculus uvulae, superior pharyngeal con- strictor, palatopharyngeus, palatoglossus, and salpingopharyngeus. The tensor veli palatini is thought to be responsible for eustachian tube function. KEYWORDS: Anatomy, physiology, velopharyngeal muscles, cleft palate anatomy Downloaded by: SASLHA. Copyrighted material. Learning Outcomes: As a result of this activity, the reader will be able to (1) list the major muscles of the velopharyngeal mechanism and discuss their functions; (2) list the sensory and motor innervation patterns for the muscles of the velopharyngeal mechanism; and (3) discuss the variations in velopharyngeal anatomy found in an unrepaired cleft palate. Understanding the normal anatomy and and treatment for children born with cleft lip physiology of the velopharyngeal mechanism is and palate. Most of the diagnostic and therapy the first step in providing appropriate diagnosis approaches are based on a strong foundation of 1Department of Communication Sciences and Disorders, Guest Editor, Ann W. -

Comparative Myology and Evolution of Marsupials and Other Vertebrates, with Notes on Complexity, Bauplan, and “Scala Naturae”
RVC OPEN ACCESS REPOSITORY – COPYRIGHT NOTICE This is the peer reviewed version of: Diogo, R., Bello-Hellegouarch, G., Kohlsdorf, T., Esteve-Altava, B. and Molnar, J. L. (2016), Comparative Myology and Evolution of Marsupials and Other Vertebrates, With Notes on Complexity, Bauplan, and “Scala Naturae”. Anat. Rec., 299: 1224–1255. doi:10.1002/ar.23390 which has been published in final form at http://dx.doi.org/10.1002/ar.23390. This article may be used for non-commercial purposes in accordance with Wiley Terms and Conditions for Self-Archiving. The full details of the published version of the article are as follows: TITLE: Comparative Myology and Evolution of Marsupials and Other Vertebrates, With Notes on Complexity, Bauplan, and "Scala Naturae" AUTHORS: Diogo, R., Bello-Hellegouarch, G., Kohlsdorf, T., Esteve-Altava, B. and Molnar, J. L. JOURNAL TITLE: Anatomical Record: Advances in Integrative Anatomy and Evolutionary Biology PUBLISHER: Wiley PUBLICATION DATE: September 2016 DOI: 10.1002/ar.23390 Comparative myology and evolution of marsupials and other vertebrates, with notes on complexity, Bauplan, and ‘scala naturae’ Rui Diogo1, Gaelle Bello-Hellegouarch2, Tiana Kohlsdorf2, Borja Esteve-Altava1,3, Julia L. Molnar1 1 Department of Anatomy, Howard University College of Medicine, Numa Adams Building, 520 W St. NW, Washington, DC 20059, US. 2 Department of Biology, FFCLRP. University of São Paulo. Avenida Bandeirantes, 3900. Bairro Monte 7 Alegre. Ribeirão Preto, SP. Brazil. 3 Structure & Motion Laboratory, Department of Comparative Biomedical Sciences, Royal Veterinary College, Hawkshead Lane, Hatfield, Hertfordshire AL9 7TA, United Kingdom. Corresponding author: Rui Diogo. Department of Anatomy, Howard University College of Medicine, Numa Adams Building, 520 W St. -

Modified Expansion Sphincter Pharyngoplasty for Treatment of Children with Obstructive Sleep Apnea
Research Original Investigation Modified Expansion Sphincter Pharyngoplasty for Treatment of Children With Obstructive Sleep Apnea Seckin O. Ulualp, MD IMPORTANCE Lateral pharyngeal wall collapse has been implicated in the pathogenesis of obstructive sleep apnea (OSA). Modified expansion sphincter pharyngoplasty (ESP) is a simple procedure and can be considered in the surgical management of children with severe OSA. OBJECTIVE To describe a modified ESP addressing lateral pharyngeal muscle wall collapse in the treatment of children with OSA. DESIGN, SETTING, AND PARTICIPANTS Retrospective review of the medical records of children with OSA and lateral pharyngeal muscle wall collapse who underwent modified ESP and children who had tonsillectomy and adenoidectomy (TA) for OSA between 2008 and 2013 at a tertiary care children’s hospital. INTERVENTIONS Modified ESP. MAIN OUTCOMES AND MEASURES The primary outcome measure was the rate of cure, which was defined as an apnea-hypopnea index (AHI) lower than 1. Other outcomes were differences in preoperative and postoperative AHI, minimum saturation of peripheral oxygen, and percentage of total sleep study time with oxygen saturation less than 90%. RESULTS Twenty-five children who had modified ESP and 25 AHI-matched children who had TA for severe OSA were identified. The postoperative AHI was lower than the preoperative AHI in both groups. Preoperative AHI was similar between modified ESP and TA groups. The Author Affiliations: Department of Otolaryngology–Head and Neck mean (SD) postoperative AHI of the modified ESP group (2.4 [3.9]) was lower than that of the Surgery, University of Texas TA group (6.2 [6.0]) (P < .001). Cure rates for the modified ESP group (AHI <1, 64%; AHI <2, Southwestern Medical Center, Dallas; 72%; and AHI <5, 80%) were greater than those for the TA group (AHI <1, 8%; AHI <2, 44%; Division of Pediatric Otolaryngology, and AHI <5, 60%). -

Genioglossus Muscle Is the Largest Extrinsic Tongue Muscle and Upper Airway Dilator
PLEASE TYPE THE UNIVERSITY OF NEW SOUTH WALES Thesis/Dissertation Sheet Surname or Family name: Kwan First name: Benjamin Other name/s: Chi Hin Abbreviation for degree as given in the University calendar: PhD School: Prince of Wales Hospital Clinical School Faculty: Medicine Title: Breathing movements of the human tongue and genioglossus measured with ultrasound imaging Abstract 350 words maximum: (PLEASE TYPE) Genioglossus muscle is the largest extrinsic tongue muscle and upper airway dilator. To maintain pharyngeal patency within and between breaths, delicate moment-to-moment coordination of pharyngeal muscles activity and drive is required. Dynamic pharyngeal muscle movement in response to the neural input during sleep/wake states is not clearly understood. This thesis reports a novel ultrasound method to visualise and measure dynamic genioglossus motion in healthy and OSA subjects. In Chapter 2, the method revealed ~1 mm predominantly anterior peak displacement within a 50 mm2 area in the infero-posterior genioglossus in healthy awake subjects during quiet breathing. Motion within this area was non-uniform. The method has good reliability, intraclass correlation coefficient (ICC) of 0.85 across separate imaging sessions. Chapter 3 reported good agreement between ultrasound and tagged MRI in measuring regional tongue motion in healthy and OSA subjects, with an ICC of 0.79. Compared to MRI, ultrasound revealed greater anterior displacement in the posterior tongue (mean difference of 0.24 ± 0.64 mm, 95% limits of agreement: 1.03 to -1.49). Chapter 4 examined influence of respiratory mechanics and drive on genioglossus movement. Inspiration against a resistive load increased posterior genioglossus motion, but it had less anterior and more inferior displacement at the highest inspiratory resistance. -

A Gephalometric Study of the Maxillofacial Structure In
A Gephalometric Study of the Maxillofacial Structure in Obstructive Sleep Apnoea David Sherring B.D.S. (Syd) Oral and Maxillofacial Surgery Faculty of Health Sciences The UnÍversity of Adelaide South Australia 2001 Table of Contents A CEPHALOMETRIC STTJDY OF THE MAXILLOFACIAL STRUCTIJRE IN OBSTRUCTIVE SLEEP APNOEA .....................I SIJMMARY VIII ACKNOIVLEDGEMENTS............... XII xrII CHAPTER 1 I SLEEP I 1.1 INTRODUCTION .2 I.2 NORMAL SLEEP .3 l.3 Clnssl¡lcATIoN oF SleEp Drsonnens .6 1.4 Polvsorr¡NOGRApHy ..... ll 1.5 OBSTRUCITve SLeep ApNos¡. Syr.¡onoue 17 22 COMPLICATIONS OF OBSTRUCTIVE SLEEP APNOEA.... ............22 2.l lNrRooucrron 23 2.2 C,qn¡TovASCULAR CHnNcrs rN OesrnucrrvE Sr-¡¡p ApNoEA 23 2.3 Resprnerony CH¡,NcEs rN OssrnucrrvE SLEEp ApNoee 26 2.4 HYPERSOMNOLENCE., 27 2.5 ENDOCRTNE DISORDERS 30 2.6 Ngunoloclc CovpllcArroNs .. 3l 34 IMAGING OF THE UPPER AIRWAY... 34 3.1 ANnrouY oF THE UppenAlnwey .. 35 3.1 .I Nose.... 35 3. I . 2 Nasopharynx........... 36 3 1.3 Oropharynx ..........., 37 3. I .4 Hypopharynx .......... 38 3.2 Drn-Ecr VrsueLlserloN . 40 3.3 N¡s¡Nooscopy............. 44 3.4 MnNovarRy .............. 45 3.5 SovrNopl-uoRoscopy. 47 3.6 CT ANDMRI 41 3.7 LnrEncL CepHRLorr¿Erny..... 49 57 ERRORS IN LATERAL CEPHALOMETRY.. ...................57 4.1 lNrRonucrloN 58 4.2 Ennons oF PRoJECTroN... 59 4.3 Ennons o¡ L¡.Novnnx loENrrprcRrloN ................ 60 4.4 ERRoRS oF DrcrrrzrNc 62 4.5 ERRORS oF MEASURTMENT 62 4.5.1 The Co-fficient of Reliability 64 4. 5.2 Confidence Limits.... 64 4.6 INrnq-oesERVER AND INTER-oBSERVER VRnrRsrr-lry 65 66 LATERAL CEPHALOMETRIC EXAMINATION OF THE UPPER AIRWAY-HARI) 5.I INTRODUCTION 67 5.2 Cn¡¡¡nrBas¡ 67 5.3 M¡,xu-r-¡. -
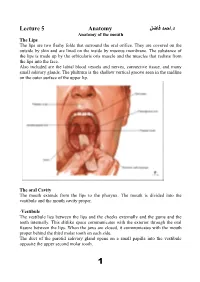
Lecture 5 Anatomy احمد فاضل د
د.احمد فاضل Lecture 5 Anatomy Anatomy of the mouth The Lips The lips are two fleshy folds that surround the oral orifice. They are covered on the outside by skin and are lined on the inside by mucous membrane. The substance of the lips is made up by the orbicularis oris muscle and the muscles that radiate from the lips into the face. Also included are the labial blood vessels and nerves, connective tissue, and many small salivary glands. The philtrum is the shallow vertical groove seen in the midline on the outer surface of the upper lip. The oral Cavity The mouth extends from the lips to the pharynx. The mouth is divided into the vestibule and the mouth cavity proper. -Vestibule The vestibule lies between the lips and the cheeks externally and the gums and the teeth internally. This slitlike space communicates with the exterior through the oral fissure between the lips. When the jaws are closed, it communicates with the mouth proper behind the third molar tooth on each side. The duct of the parotid salivary gland opens on a small papilla into the vestibule opposite the upper second molar tooth. 1 -Mouth Proper The mouth proper has a roof and a floor. Roof of Mouth The roof of the mouth is formed by the hard palate in front and the soft palate behind. Floor of Mouth The submandibular duct of the submandibular gland opens onto the floor of the mouth on the summit of a small papilla on either side of the frenulum of the tongue. -

FIPAT-TA2-Part-2.Pdf
TERMINOLOGIA ANATOMICA Second Edition (2.06) International Anatomical Terminology FIPAT The Federative International Programme for Anatomical Terminology A programme of the International Federation of Associations of Anatomists (IFAA) TA2, PART II Contents: Systemata musculoskeletalia Musculoskeletal systems Caput II: Ossa Chapter 2: Bones Caput III: Juncturae Chapter 3: Joints Caput IV: Systema musculare Chapter 4: Muscular system Bibliographic Reference Citation: FIPAT. Terminologia Anatomica. 2nd ed. FIPAT.library.dal.ca. Federative International Programme for Anatomical Terminology, 2019 Published pending approval by the General Assembly at the next Congress of IFAA (2019) Creative Commons License: The publication of Terminologia Anatomica is under a Creative Commons Attribution-NoDerivatives 4.0 International (CC BY-ND 4.0) license The individual terms in this terminology are within the public domain. Statements about terms being part of this international standard terminology should use the above bibliographic reference to cite this terminology. The unaltered PDF files of this terminology may be freely copied and distributed by users. IFAA member societies are authorized to publish translations of this terminology. Authors of other works that might be considered derivative should write to the Chair of FIPAT for permission to publish a derivative work. Caput II: OSSA Chapter 2: BONES Latin term Latin synonym UK English US English English synonym Other 351 Systemata Musculoskeletal Musculoskeletal musculoskeletalia systems systems -

The Velopharyngeal Mechanism: an Electromyographic Study
City University of New York (CUNY) CUNY Academic Works All Dissertations, Theses, and Capstone Projects Dissertations, Theses, and Capstone Projects 1973 The Velopharyngeal Mechanism: An Electromyographic Study Fredericka Bell-Berti The Graduate Center, City University of New York How does access to this work benefit ou?y Let us know! More information about this work at: https://academicworks.cuny.edu/gc_etds/2197 Discover additional works at: https://academicworks.cuny.edu This work is made publicly available by the City University of New York (CUNY). Contact: [email protected] INFORMATION TO USERS This material was produced from a microfilm copy of the original document. While the most advanced technological means to photograph and reproduce this document have been used, the quality is heavily dependent upon the quality of the original submitted. The following explanation of techniques is provided to help you understand markings or patterns which may appear on this reproduction. 1.T he sign or "target" for pages apparently lacking from the document photographed is "Missing Page(s)". If it was possible to obtain the missing page(s) or section, they are spliced into the film along with adjacent pages. This may have necessitated cutting thru an image and duplicating adjacent pages to insure you complete continuity. 2. When an image on the film is obliterated with a large round black mark, it is an indication that the photographer suspected that the copy may have moved during exposure and thus cause a blurred image. You will find a good image of the page in the adjacent frame. 3. When a map, drawing or chart, etc., was part of the material being photographed the photographer followed a definite method in "sectioning" the material.