Discovering Implicit Knowledge with Unary Relations
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Monthly NTA and Performance Update
Absolute Equity Performance Fund Limited Monthly NTA and Performance Update As at 31 January 2018 Net Tangible Assets (NTA) NTA* Performance NTA before tax $1.122 1 month 1.27% NTA after tax $1.123 3 months 2.59% $ currency notation refers to Australian Dollars. 12 months 16.02% Since inception (annualised) 3.52% Portfolio Performance *Before tax. These calculations are unaudited and intended to illustrate the performance of the investment portfolio minus corporate expenses. They are calculated on a pre-dividend NTA basis. ‘Since inception (annualised)’ is annualised NTA performance since listing at $1.065 after listing related expenses The Company’s Portfolio returned +1.27% for January 2018 and the majority of pair positions were profitable. Performance was positive despite the significant headwind of a very strong $A/$US. The Company is Company Details net long $US-exposed companies and in the short term, currency swings ASX code AEG can influence performance. In the long run, company fundamentals overwhelm currency. Listing date 16 December 2015 Share price $1.080 In a quiet month for company news the most notable was a strong quarterly NTA* per share $1.122 profit update from Resmed which contributed to our long Resmed / short Ansell pair being amongst our strongest pairs. Long JB Hi-Fi / short Super Market capitalisation $109,365,375 Retail was also rewarded, driven by industry feedback that some retailers Shares on Issue 101,264,236 had experienced better Christmas sales than feared. The pair has been profitable over 12 months, particularly since Amazon announced it will *Before tax ex-dividend start a local business. -

Socially Conscious Australian Equity Holdings
Socially Conscious Australian Equity Holdings As at 30 June 2021 Country of Company domicile Weight COMMONWEALTH BANK OF AUSTRALIA AUSTRALIA 10.56% CSL LTD AUSTRALIA 8.46% AUST AND NZ BANKING GROUP AUSTRALIA 5.68% NATIONAL AUSTRALIA BANK LTD AUSTRALIA 5.32% WESTPAC BANKING CORP AUSTRALIA 5.08% TELSTRA CORP LTD AUSTRALIA 3.31% WOOLWORTHS GROUP LTD AUSTRALIA 2.93% FORTESCUE METALS GROUP LTD AUSTRALIA 2.80% TRANSURBAN GROUP AUSTRALIA 2.55% GOODMAN GROUP AUSTRALIA 2.34% WESFARMERS LTD AUSTRALIA 2.29% BRAMBLES LTD AUSTRALIA 1.85% COLES GROUP LTD AUSTRALIA 1.80% SUNCORP GROUP LTD AUSTRALIA 1.62% MACQUARIE GROUP LTD AUSTRALIA 1.54% JAMES HARDIE INDUSTRIES IRELAND 1.51% NEWCREST MINING LTD AUSTRALIA 1.45% SONIC HEALTHCARE LTD AUSTRALIA 1.44% MIRVAC GROUP AUSTRALIA 1.43% MAGELLAN FINANCIAL GROUP LTD AUSTRALIA 1.13% STOCKLAND AUSTRALIA 1.11% DEXUS AUSTRALIA 1.11% COMPUTERSHARE LTD AUSTRALIA 1.09% AMCOR PLC AUSTRALIA 1.02% ILUKA RESOURCES LTD AUSTRALIA 1.01% XERO LTD NEW ZEALAND 0.97% WISETECH GLOBAL LTD AUSTRALIA 0.92% SEEK LTD AUSTRALIA 0.88% SYDNEY AIRPORT AUSTRALIA 0.83% NINE ENTERTAINMENT CO HOLDINGS LIMITED AUSTRALIA 0.82% EAGERS AUTOMOTIVE LTD AUSTRALIA 0.82% RELIANCE WORLDWIDE CORP LTD UNITED STATES 0.80% SANDFIRE RESOURCES LTD AUSTRALIA 0.79% AFTERPAY LTD AUSTRALIA 0.79% CHARTER HALL GROUP AUSTRALIA 0.79% SCENTRE GROUP AUSTRALIA 0.79% ORORA LTD AUSTRALIA 0.75% ANSELL LTD AUSTRALIA 0.75% OZ MINERALS LTD AUSTRALIA 0.74% IGO LTD AUSTRALIA 0.71% GPT GROUP AUSTRALIA 0.69% Issued by Aware Super Pty Ltd (ABN 11 118 202 672, AFSL 293340) the trustee of Aware Super (ABN 53 226 460 365). -

(ASX100) Women on Boards Analysis
Australia/NZ | Australia Thematic Investing (Citi) Equities 18 August 2011 │ 32 pages ESG: ASX100 Women on Board Analysis Increasing Focus on Board Diversity Women on Boards of ASX100 Companies — The ASX Corporate Governance Council’s new principles and recommendations on diversity commenced on 1 January Elaine Prior 2011. This is likely to lead to increasing focus on companies’ approaches to diversity +61-2-8225-4891 issues, including female representation on company boards. This report looks at data [email protected] on women directors on ASX100 company boards. The number of women directors has Felipe Faria increased, particularly in recent months (Figure 5 to Figure 8). Board diversity may [email protected] enhance effectiveness, by providing a wider range of perspectives and knowledge. Women on Boards Data — We collected and analysed data on female board directors of S&P/ASX100 companies from FY08 to 8 August 2011 (Figure 5 to Figure 9). At 8 August 2011 there were 134 women on ASX100 boards, a 46% increase from FY08. ASX100 companies with no female board directors were AQP, CQO, EGP, FMG, IPL, JHX, LEI, LYC, OSH, PDN, PRY, RHC, RMD, SGM and SWM. Companies with three female directors (the highest number identified) are AMP, BEN, CBA, MQG, QAN, QBE and WBC. Seven female directors each currently hold three ASX100 directorships. Business Case for Gender Diversity — Reibey Institute research found that those ASX500 companies with women directors on 30 June 2010 had a 3-year return on equity (ROE) 10.7% higher than those without any women directors. The 5-year ROE was 11.1% higher. -

Stoxx® Pacific Total Market Index
STOXX® PACIFIC TOTAL MARKET INDEX Components1 Company Supersector Country Weight (%) CSL Ltd. Health Care AU 7.79 Commonwealth Bank of Australia Banks AU 7.24 BHP GROUP LTD. Basic Resources AU 6.14 Westpac Banking Corp. Banks AU 3.91 National Australia Bank Ltd. Banks AU 3.28 Australia & New Zealand Bankin Banks AU 3.17 Wesfarmers Ltd. Retail AU 2.91 WOOLWORTHS GROUP Retail AU 2.75 Macquarie Group Ltd. Financial Services AU 2.57 Transurban Group Industrial Goods & Services AU 2.47 Telstra Corp. Ltd. Telecommunications AU 2.26 Rio Tinto Ltd. Basic Resources AU 2.13 Goodman Group Real Estate AU 1.51 Fortescue Metals Group Ltd. Basic Resources AU 1.39 Newcrest Mining Ltd. Basic Resources AU 1.37 Woodside Petroleum Ltd. Oil & Gas AU 1.23 Coles Group Retail AU 1.19 Aristocrat Leisure Ltd. Travel & Leisure AU 1.02 Brambles Ltd. Industrial Goods & Services AU 1.01 ASX Ltd. Financial Services AU 0.99 FISHER & PAYKEL HLTHCR. Health Care NZ 0.92 AMCOR Industrial Goods & Services AU 0.91 A2 MILK Food & Beverage NZ 0.84 Insurance Australia Group Ltd. Insurance AU 0.82 Sonic Healthcare Ltd. Health Care AU 0.82 SYDNEY AIRPORT Industrial Goods & Services AU 0.81 AFTERPAY Financial Services AU 0.78 SUNCORP GROUP LTD. Insurance AU 0.71 QBE Insurance Group Ltd. Insurance AU 0.70 SCENTRE GROUP Real Estate AU 0.69 AUSTRALIAN PIPELINE Oil & Gas AU 0.68 Cochlear Ltd. Health Care AU 0.67 AGL Energy Ltd. Utilities AU 0.66 DEXUS Real Estate AU 0.66 Origin Energy Ltd. -

ESG Reporting by the ASX200
Australian Council of Superannuation Investors ESG Reporting by the ASX200 August 2019 ABOUT ACSI Established in 2001, the Australian Council of Superannuation Investors (ACSI) provides a strong, collective voice on environmental, social and governance (ESG) issues on behalf of our members. Our members include 38 Australian and international We undertake a year-round program of research, asset owners and institutional investors. Collectively, they engagement, advocacy and voting advice. These activities manage over $2.2 trillion in assets and own on average 10 provide a solid basis for our members to exercise their per cent of every ASX200 company. ownership rights. Our members believe that ESG risks and opportunities have We also offer additional consulting services a material impact on investment outcomes. As fiduciary including: ESG and related policy development; analysis investors, they have a responsibility to act to enhance the of service providers, fund managers and ESG data; and long-term value of the savings entrusted to them. disclosure advice. Through ACSI, our members collaborate to achieve genuine, measurable and permanent improvements in the ESG practices and performance of the companies they invest in. 6 INTERNATIONAL MEMBERS 32 AUSTRALIAN MEMBERS MANAGING $2.2 TRILLION IN ASSETS 2 ESG REPORTING BY THE ASX200: AUGUST 2019 FOREWORD We are currently operating in a low-trust environment Yet, safety data is material to our members. In 2018, 22 – for organisations generally but especially businesses. people from 13 ASX200 companies died in their workplaces. Transparency and accountability are crucial to rebuilding A majority of these involved contractors, suggesting that this trust deficit. workplace health and safety standards are not uniformly applied. -

Business Leadership: the Catalyst for Accelerating Change
BUSINESS LEADERSHIP: THE CATALYST FOR ACCELERATING CHANGE Follow us on twitter @30pctAustralia OUR OBJECTIVE is to achieve 30% of ASX 200 seats held by women by end 2018. Gender balance on boards does achieve better outcomes. GREATER DIVERSITY ON BOARDS IS VITAL TO THE GOOD GOVERNANCE OF AUSTRALIAN BUSINESSES. FROM THE PERSPECTIVE OF PERFORMANCE AS WELL AS EQUITY THE CASE IS CLEAR. AUSTRALIA HAS MORE THAN ENOUGH CAPABLE WOMEN TO EXCEED THE 30% TARGET. IF YOUR BOARD IS NOT INVESTING IN THE CAPABILITY THAT DIVERSITY BRINGS, IT’S NOW A MARKED DEPARTURE FROM THE WHAT THE INVESTOR AND BROADER COMMUNITY EXPECT. Angus Armour FAICD, Managing Director & Chief Executive Officer, Australian Institute of Company Directors BY BRINGING TOGETHER INFLUENTIAL COMPANY CHAIRS, DIRECTORS, INVESTORS, HEAD HUNTERS AND CEOs, WE WANT TO DRIVE A BUSINESS-LED APPROACH TO INCREASING GENDER BALANCE THAT CHANGES THE WAY “COMPANIES APPROACH DIVERSITY ISSUES. Patricia Cross, Australian Chair 30% Club WHO WE ARE LEADERS LEADING BY EXAMPLE We are a group of chairs, directors and business leaders taking action to increase gender diversity on Australian boards. The Australian chapter launched in May 2015 with a goal of achieving 30% women on ASX 200 boards by the end of 2018. AUSTRALIAN 30% CLUB MEMBERS Andrew Forrest Fortescue Metals Douglas McTaggart Spark Group Ltd Infrastructure Trust Samuel Weiss Altium Ltd Kenneth MacKenzie BHP Billiton Ltd John Mulcahy Mirvac Ltd Stephen Johns Brambles Ltd Mark Johnson G8 Education Ltd John Shine CSL Ltd Paul Brasher Incitec Pivot -

FTSE Publications
2 FTSE Russell Publications FTSE Developed Asia Pacific ex 19 August 2021 Japan ex Controversies ex CW Index Indicative Index Weight Data as at Closing on 30 June 2021 Index weight Index weight Index weight Constituent Country Constituent Country Constituent Country (%) (%) (%) a2 Milk 0.1 NEW CJ Cheiljedang 0.1 KOREA GPT Group 0.22 AUSTRALIA ZEALAND CJ CheilJedang Pfd. 0.01 KOREA Green Cross 0.05 KOREA AAC Technologies Holdings 0.16 HONG KONG CJ Corp 0.04 KOREA GS Engineering & Construction 0.07 KOREA ADBRI 0.04 AUSTRALIA CJ ENM 0.05 KOREA GS Holdings 0.06 KOREA Afterpay Touch Group 0.61 AUSTRALIA CJ Logistics 0.04 KOREA GS Retail 0.04 KOREA AGL Energy 0.12 AUSTRALIA CK Asset Holdings 0.5 HONG KONG Guotai Junan International Holdings 0.01 HONG KONG AIA Group Ltd. 4.6 HONG KONG CK Hutchison Holdings 0.64 HONG KONG Haitong International Securities Group 0.02 HONG KONG Air New Zealand 0.02 NEW CK Infrastructure Holdings 0.11 HONG KONG Hana Financial Group 0.36 KOREA ZEALAND Cleanaway Waste Management 0.08 AUSTRALIA Hang Lung Group 0.07 HONG KONG ALS 0.14 AUSTRALIA CLP Holdings 0.5 HONG KONG Hang Lung Properties 0.15 HONG KONG Alteogen 0.06 KOREA Cochlear 0.37 AUSTRALIA Hang Seng Bank 0.44 HONG KONG Altium 0.09 AUSTRALIA Coles Group 0.5 AUSTRALIA Hanjin KAL 0.04 KOREA Alumina 0.1 AUSTRALIA ComfortDelGro 0.08 SINGAPORE Hankook Technology Group 0.1 KOREA Amcor CDI 0.54 AUSTRALIA Commonwealth Bank of Australia 4.07 AUSTRALIA Hanmi Pharmaceutical 0.06 KOREA AmoreG 0.05 KOREA Computershare 0.21 AUSTRALIA Hanmi Science 0.03 KOREA Amorepacific Corp 0.21 KOREA Contact Energy 0.14 NEW Hanon Systems 0.07 KOREA Amorepacific Pfd. -
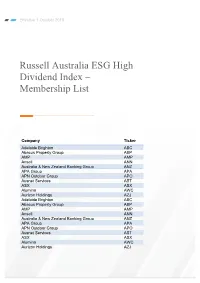
Russell Australia ESG High Dividend Index – Membership List
Effective 1 October 2018 Russell Australia ESG High Dividend Index – Membership List Company Ticker Adelaide Brighton ABC Abacus Property Group ABP AMP AMP Ansell ANN Australia & New Zealand Banking Group ANZ APA Group APA APN Outdoor Group APO Ausnet Services AST ASX ASX Alumina AWC Aurizon Holdings AZJ Adelaide Brighton ABC Abacus Property Group ABP AMP AMP Ansell ANN Australia & New Zealand Banking Group ANZ APA Group APA APN Outdoor Group APO Ausnet Services AST ASX ASX Alumina AWC Aurizon Holdings AZJ Company Ticker Bendigo and Adelaide Bank BEN Bega Cheese BGA Boral BLD Bank of Queensland Ltd. BOQ Beach Energy BPT Bluescope Steel BSL Brambles BXB Commonwealth Bank of Australia CBA Coca-Cola Amatil CCL Challenger CGF Charter Hall Group CHC CIMIC Group CIM Cromwell Property Group CMW Cochlear COH Computershare CPU Charter Hall Retail REIT CQR CSL CSL CSR CSR Caltex Australia CTX Cleanaway Waste Management CWY DuluxGroup DLX Downer Group DOW Dexus Property Group DXS Evolution Mining EVN Fortescue Metals Group FMG Genworth Mortgage Insurance Australia GMA Goodman Group GMG Graincorp GNC Growthpoint Properties Australia GOZ GPT Group GPT Healthscope HSO Insurance Australia Group IAG IOOF Holdings IFL Infigen Energy IFN Independence Group NL IGO Iluka Resources ILU Investa Office Fund IOF Incitec Pivot Ltd IPL Lend Lease Group LLC Magellan Financial Group MFG Mirvac Group MGR Medibank Private MPL Macquarie Group MQG National Australia Bank NAB Company Ticker Scentre Group SCG Shopping Centres Australasia Property Group SCP Sandfire Resources NL SFR Stockland SGP Sonic Healthcare SHL Santos STO Super Retail Group SUL Suncorp Group SUN Sydney Airport SYD Transurban Group TCL Tassal Group TGR Telstra Corp TLS Vicinity Centers VCX Westpac Banking Corp WBC Wesfarmers WES WorleyParsons Ltd. -

Barramundi Monthly Update
MONTHLY UPDATE August 2021 Share Price BRM NAV Warrant Price PREMIUM1 $1.03 $0.86 $0.33 29.5% as at 31 July 2021 A WORD FROM THE MANAGER In July Barramundi returned gross performance of -0.6% and an NEXTDC (+7.5%) announced it had secured land for a new data adjusted NAV return of -1.0%. This compares to the ASX200 Index centre in Sydney. The data centre will be NEXTDC’s fourth site which returned +0.5% (70% hedged into NZ$). in Sydney and twelfth in Australia. The facility will be the largest in Australia and reflects the robust long-term demand for cloud Bolstered by strong commodity prices, the Materials sector (+7.1% services and data centre capacity. in the month) led the market higher along with Industrials (+4.3%) and Consumer Staples (+1.4%). Information Technology (-6.9%), Sonic Healthcare returned +4.2% in July. The spread of the Delta weighed down by the buy-now-pay-later bellwether Afterpay variant led to accelerated COVID testing in Australia where Sonic’s (-18.2% in the month) lagged the market. laboratories are one of the leading providers of COVID testing. In the US, two of Sonic’s key competitors announced their quarterly Heightened takeover activity, which we wrote about last month, results in the month. They both saw a strong recovery in their core continues to be a feature in Australia. In early August, Afterpay pathology testing businesses supplemented by continued, albeit received a A$39bn takeover offer (supported by its board and declining, COVID testing volumes. -

Download Annual Report 2015
Chairman’s Message The 2015 financial year saw BlueScope’s best profit performance since the impact of the global financial crisis on the steel sector in 2009. Dear Shareholder The 2015 financial year saw BlueScope’s best profit performance Strategy review since the impact of the global financial crisis on the steel sector BlueScope has a diverse portfolio of businesses. We are a global in 2009. leader in premium branded coated and painted steel products The Company’s return to earnings growth is pleasing. While and have regional strengths in engineered steel buildings. there is still a lot of work to do to achieve acceptable return on We have a strong competitive advantage in global markets – invested capital, I commend BlueScope employees across the highlighted by our outstanding brands, technology, channels globe for this year’s result. to market and manufacturing footprint. Underlying earnings grew across the Company in all but one We are the third largest manufacturer of painted and coated steel of our five operating segments. products globally, the number one in building and construction markets and the recognised quality leader in nine countries. Underlying performance In our North Star BlueScope Steel joint venture, we operate BlueScope’s net profit after tax (NPAT) of $136.3 million arguably the best performing steel plant in the US. was $218.7 million higher than FY2014. Underlying NPAT was $134.1 million, an increase of nine per cent over FY2014. The global steel industry has seen extensive changes in recent times. For example, from an annual average of 52 million tonnes Full year underlying EBIT was $301.8 million, 14 per cent higher in 2010–2013 China’s finished steel exports have doubled to over than the comparable period in FY2014 (prior to restatement of 100 million tonnes per annum, an increase equivalent to 20 times discontinued operations). -

Australia & New Zealand Report 2018
DISCLOSURE INSIGHT ACTION Australia & New Zealand Report 2018 On behalf of over 650 investors with US$87 trillion in assets. CDP Report 2018 | Published February 2019 Contents 3 CEO foreword 14 Appendix I List of disclosing companies in Australia & 4 Disclosure in 2018 New Zealand 5 Climate Change: Australia & New 18 Appendix II Zealand insights Responding companies in Australia & New Zealand – supply chain program 9 Water Security: Driving water stewardship 19 Appendix III Non-responding companies in Australia & 10 Forests: Building sustainable New Zealand supply chains 12 CDP Australia & New Zealand Awards 2018 13 Investor Signatories & Members in Australia & New Zealand Important Notice The contents of this report may be used by anyone providing acknowledgement is given to CDP. This does not represent a license to repackage or resell any of the data reported to CDP or the contributing authors and presented in this report. If you intend to repackage or resell any of the contents of this report, you need to obtain express permission from CDP before doing so. CDP has prepared the data and analysis in this report based on responses to the CDP 2018 information request. No representation or warranty (express or implied) is given by CDP as to the accuracy or completeness of the information and opinions contained in this report. You should not act upon the information contained in this publication without obtaining specific professional advice. To the extent permitted by law, CDP does not accept or assume any liability, responsibility or duty of care for any consequences of you or anyone else acting, or refraining to act, in reliance on the information contained in this report or for any decision based on it. -

Investments Updated on 2 September 2021
Verve Investments Updated on 2 September 2021 Investments you can feel good about! AUSTRALIAN MAGELLAN FINANCIAL GROUP NEW ENERGY SOLAR RESOLVE SOCIAL BENEFIT BOND CHARTER HALL GROUP SYNERGIS FUND NEXTDC CSL VICINITY CENTRES BRAMBLES JB HI-FI GOODMAN GROUP ANSELL SONIC HEALTHCARE CLEANAWAY WASTE MANAGEMENT FISHER & PAYKEL HEALTHCARE ALTIUM RESMED APPEN ASX LTD CHORUS COCHLEAR IDP EDUCATION TELSTRA WISETECH GLOBAL RAMSAY HEALTH CARE BENDIGO AND ADELAIDE BANK XERO FLETCHER BUILDING SUNCORP NINE ENTERTAINMENT CO A2 MILK COMPANY BANK OF QUEENSLAND INSURANCE AUSTRALIA GROUP BREVILLE GROUP DEXUS BAPCOR STOCKLAND MEGAPORT MIRVAC MESOBLAST LTD SPARK NEW ZEALAND HEALIUS GPT GROUP NIB HOLDINGS SEEK TECHNOLOGYONE MEDIBANK PRIVATE INVOCARE Verve Super Fund (ABN: 960 194 277, R1072914) is issued by Diversa Trustees Limited PAGE 1 (ABN 49 006 421 638, RSEL0000635, AFSL 235153) NANOSONICS IRESS COSTA GROUP BRAVURA SOLUTIONS SIMS METAL MANAGEMENT PEOPLE INFRASTRUCTURE LTD BEGA CHEESE SUNCORP INGENIA COMMUNITIES GROUP PLENTI NATIONAL CLEAN ENERGY MARKET BINGO INDUSTRIES CHALLENGER GUD HOLDINGS BANK OF QUEENSLAND ABACUS PROPERTY GROUP NEXTDC BLACKMORES HERITAGE BANK LTD GROWTHPOINT PROPERTIES AUSTRALIA INSURANCE AUSTRALIA GROUP LTD OMNI BRIDGEWAY BENDIGO AND ADELAIDE BANK PRO MEDICUS MYSTATE BANK LTD G8 EDUCATION SEEK LTD SEALINK TRAVEL GROUP LIBERTY FINANCIAL PTY LTD GWA GROUP MACQUARIE UNIVERSITY SELECT HARVESTS NEW SOUTH WALES TREASURY CORP SIGMA HEALTHCARE QUEENSLAND TREASURY CORP OROCOBRE TREASURY CORP VICTORIA PILBARA MINERALS BANK AUSTRALIA PACT