24 Celtic (Indo-European)
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Parameters and Micro-Parameters in Arabic Sentence Structure
PARAMETERS AND MICRO-PARAMETERS IN ARABIC SENTENCE STRUCTURE By Kemel Jouini A thesis submitted to the Victoria University of Wellington in fulfilment of the requirements for the degree of Doctor of Philosophy in Linguistics Victoria University of Wellington 2014 ACKNOWLEGDMENTS I would like to thank Professor Elabbas Benmamoun, in particular, for accepting to be my adviser for the nine-month period I spent at the Department of Linguistics at the University of Illinois at Urbana-Champaign in the academic year 2004-2005 as a non- degree Fulbright grantee. During my stay at UIUC, Elabbas’s lectures convinced me of the view that a proper understanding of the feature structure of functional categories could enlighten linguistic theory on how the structure of sentences could vary cross-linguistically. Special thanks go to Dr. Elizabeth Pearce for willing to be my supervisor, for her patience to read through the so many drafts of chapters I was sending her, and for her advice on the numerous revisions I thereby had to make. I also thank Professor Richard S. Kayne for the invaluable opportunity he offered me during his visit at VUW to discuss with him some aspects of micro- parametric syntax relevant to my analysis of verbal inflection. Last, but not least, I thank my secondary supervisor Dr. Sasha Calhoun for her willingness to share ideas and offer suggestions, as well as Professor Laurie Bauer for his helpful comments on part of my thesis. I also want to thank Professor Tim Stowell, Professor Halldór Sigurðsson, Professor Henry Davis, Professor Jan Koster and Dr. Fred Hoyt for sending me documents I could not find elsewhere. -

RELATIONAL NOUNS, PRONOUNS, and Resumptionw Relational Nouns, Such As Neighbour, Mother, and Rumour, Present a Challenge to Synt
Linguistics and Philosophy (2005) 28:375–446 Ó Springer 2005 DOI 10.1007/s10988-005-2656-7 ASH ASUDEH RELATIONAL NOUNS, PRONOUNS, AND RESUMPTIONw ABSTRACT. This paper presents a variable-free analysis of relational nouns in Glue Semantics, within a Lexical Functional Grammar (LFG) architecture. Rela- tional nouns and resumptive pronouns are bound using the usual binding mecha- nisms of LFG. Special attention is paid to the bound readings of relational nouns, how these interact with genitives and obliques, and their behaviour with respect to scope, crossover and reconstruction. I consider a puzzle that arises regarding rela- tional nouns and resumptive pronouns, given that relational nouns can have bound readings and resumptive pronouns are just a specific instance of bound pronouns. The puzzle is: why is it impossible for bound implicit arguments of relational nouns to be resumptive? The puzzle is highlighted by a well-known variety of variable-free semantics, where pronouns and relational noun phrases are identical both in category and (base) type. I show that the puzzle also arises for an established variable-based theory. I present an analysis of resumptive pronouns that crucially treats resumptives in terms of the resource logic linear logic that underlies Glue Semantics: a resumptive pronoun is a perfectly ordinary pronoun that constitutes a surplus resource; this surplus resource requires the presence of a resumptive-licensing resource consumer, a manager resource. Manager resources properly distinguish between resumptive pronouns and bound relational nouns based on differences between them at the level of semantic structure. The resumptive puzzle is thus solved. The paper closes by considering the solution in light of the hypothesis of direct compositionality. -

THE INDO-EUROPEAN FAMILY — the LINGUISTIC EVIDENCE by Brian D
THE INDO-EUROPEAN FAMILY — THE LINGUISTIC EVIDENCE by Brian D. Joseph, The Ohio State University 0. Introduction A stunning result of linguistic research in the 19th century was the recognition that some languages show correspondences of form that cannot be due to chance convergences, to borrowing among the languages involved, or to universal characteristics of human language, and that such correspondences therefore can only be the result of the languages in question having sprung from a common source language in the past. Such languages are said to be “related” (more specifically, “genetically related”, though “genetic” here does not have any connection to the term referring to a biological genetic relationship) and to belong to a “language family”. It can therefore be convenient to model such linguistic genetic relationships via a “family tree”, showing the genealogy of the languages claimed to be related. For example, in the model below, all the languages B through I in the tree are related as members of the same family; if they were not related, they would not all descend from the same original language A. In such a schema, A is the “proto-language”, the starting point for the family, and B, C, and D are “offspring” (often referred to as “daughter languages”); B, C, and D are thus “siblings” (often referred to as “sister languages”), and each represents a separate “branch” of the family tree. B and C, in turn, are starting points for other offspring languages, E, F, and G, and H and I, respectively. Thus B stands in the same relationship to E, F, and G as A does to B, C, and D. -

The University of Hull Mutation and the Syntactic Structure Of
THE UNIVERSITY OF HULL MUTATION AND THE SYNTACTIC STRUCTURE OF i MODERN COLLOQUIAL WELSH being a Thesis submitted for the Degree of Doctor of Philosophy in the University of Hull by MARGARET OLWEN TALLERMAN B.A. (HONS.) June 1987 -b bLf3 1987 SUMMAR/ Summary of Thesis submitted for PhD degree by Margaret Olwen Tallerman on Mutation and the Syntactic Structure of Modern Colloquial Welsh In this dissertation I discuss the phenomenon of initial consonantal mutation in modern Welsh, and explore the syntactic structure of this language: I will concentrate on the syntax of Colloquial rather than Literary Welsh. It transpires that mutation phenomena can frequently be cited as evidence for or against certain syntactic analyses. In chapter 1 I present a critical survey of previous treatments of mutation, and show that mutation in Welsh conforms to a modified version of the Trigger Constraint proposed by Lieber and by Zwicky. It is argued that adjacency of the mutation trigger is the criterial property in Welsh. Chapter 2 presents a comprehensive description of the productive environments for mutation in modern Welsh. In chapter 3 I give a snort account of Government and Binding theory, the framework used for several recent analyses of Celtic languages. I also discuss proposals that have been made concerning the underlying word order of Welsh, a surface VSO language. Although I reject SVO underlying order, I conclude that there is nonetheless a VP constituent in Welsh. Chapters 4 and 5 concern the role of NPs as triggers for Soft Mutation: both overt and 1 empty category NPs are considered. -

Historical Background of the Contact Between Celtic Languages and English
Historical background of the contact between Celtic languages and English Dominković, Mario Master's thesis / Diplomski rad 2016 Degree Grantor / Ustanova koja je dodijelila akademski / stručni stupanj: Josip Juraj Strossmayer University of Osijek, Faculty of Humanities and Social Sciences / Sveučilište Josipa Jurja Strossmayera u Osijeku, Filozofski fakultet Permanent link / Trajna poveznica: https://urn.nsk.hr/urn:nbn:hr:142:149845 Rights / Prava: In copyright Download date / Datum preuzimanja: 2021-09-27 Repository / Repozitorij: FFOS-repository - Repository of the Faculty of Humanities and Social Sciences Osijek Sveučilište J. J. Strossmayera u Osijeku Filozofski fakultet Osijek Diplomski studij engleskog jezika i književnosti – nastavnički smjer i mađarskog jezika i književnosti – nastavnički smjer Mario Dominković Povijesna pozadina kontakta između keltskih jezika i engleskog Diplomski rad Mentor: izv. prof. dr. sc. Tanja Gradečak – Erdeljić Osijek, 2016. Sveučilište J. J. Strossmayera u Osijeku Filozofski fakultet Odsjek za engleski jezik i književnost Diplomski studij engleskog jezika i književnosti – nastavnički smjer i mađarskog jezika i književnosti – nastavnički smjer Mario Dominković Povijesna pozadina kontakta između keltskih jezika i engleskog Diplomski rad Znanstveno područje: humanističke znanosti Znanstveno polje: filologija Znanstvena grana: anglistika Mentor: izv. prof. dr. sc. Tanja Gradečak – Erdeljić Osijek, 2016. J.J. Strossmayer University in Osijek Faculty of Humanities and Social Sciences Teaching English as -
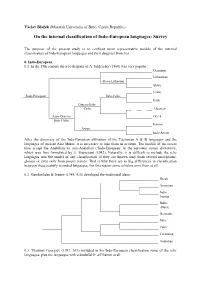
Internal Classification of Indo-European Languages: Survey
Václav Blažek (Masaryk University of Brno, Czech Republic) On the internal classification of Indo-European languages: Survey The purpose of the present study is to confront most representative models of the internal classification of Indo-European languages and their daughter branches. 0. Indo-European 0.1. In the 19th century the tree-diagram of A. Schleicher (1860) was very popular: Germanic Lithuanian Slavo-Lithuaian Slavic Celtic Indo-European Italo-Celtic Italic Graeco-Italo- -Celtic Albanian Aryo-Graeco- Greek Italo-Celtic Iranian Aryan Indo-Aryan After the discovery of the Indo-European affiliation of the Tocharian A & B languages and the languages of ancient Asia Minor, it is necessary to take them in account. The models of the recent time accept the Anatolian vs. non-Anatolian (‘Indo-European’ in the narrower sense) dichotomy, which was first formulated by E. Sturtevant (1942). Naturally, it is difficult to include the relic languages into the model of any classification, if they are known only from several inscriptions, glosses or even only from proper names. That is why there are so big differences in classification between these scantily recorded languages. For this reason some scholars omit them at all. 0.2. Gamkrelidze & Ivanov (1984, 415) developed the traditional ideas: Greek Armenian Indo- Iranian Balto- -Slavic Germanic Italic Celtic Tocharian Anatolian 0.3. Vladimir Georgiev (1981, 363) included in his Indo-European classification some of the relic languages, plus the languages with a doubtful IE affiliation at all: Tocharian Northern Balto-Slavic Germanic Celtic Ligurian Italic & Venetic Western Illyrian Messapic Siculian Greek & Macedonian Indo-European Central Phrygian Armenian Daco-Mysian & Albanian Eastern Indo-Iranian Thracian Southern = Aegean Pelasgian Palaic Southeast = Hittite; Lydian; Etruscan-Rhaetic; Elymian = Anatolian Luwian; Lycian; Carian; Eteocretan 0.4. -

CHAPTER SEVENTEEN History of the German Language 1 Indo
CHAPTER SEVENTEEN History of the German Language 1 Indo-European and Germanic Background Indo-European Background It has already been mentioned in this course that German and English are related languages. Two languages can be related to each other in much the same way that two people can be related to each other. If two people share a common ancestor, say their mother or their great-grandfather, then they are genetically related. Similarly, German and English are genetically related because they share a common ancestor, a language which was spoken in what is now northern Germany sometime before the Angles and the Saxons migrated to England. We do not have written records of this language, unfortunately, but we have a good idea of what it must have looked and sounded like. We have arrived at our conclusions as to what it looked and sounded like by comparing the sounds of words and morphemes in earlier written stages of English and German (and Dutch) and in modern-day English and German dialects. As a result of the comparisons we are able to reconstruct what the original language, called a proto-language, must have been like. This particular proto-language is usually referred to as Proto-West Germanic. The method of reconstruction based on comparison is called the comparative method. If faced with two languages the comparative method can tell us one of three things: 1) the two languages are related in that both are descended from a common ancestor, e.g. German and English, 2) the two are related in that one is the ancestor of the other, e.g. -

Universal Dependencies for Manx Gaelic
Universal Dependencies for Manx Gaelic Kevin P. Scannell Department of Computer Science Saint Louis University St. Louis, Missouri, USA [email protected] Abstract Manx Gaelic is one of the three Q-Celtic languages, along with Irish and Scottish Gaelic. We present a new dependency treebank for Manx consisting of 291 sentences and about 6000 tokens, annotated according to the Universal Dependency (UD) guidelines. To the best of our knowledge, this is the first annotated corpus of any kind for Manx. Our annotations generally follow the conventions established by the existing UD treebanks for Irish and Scottish Gaelic, although we highlight some areas where the grammar of Manx diverges, requiring new analyses. We use 10- fold cross validation to evaluate the accuracy of dependency parsers trained on the corpus, and compare these results with delexicalized models transferred from Irish and Scottish Gaelic. 1 Introduction Manx Gaelic, spoken primarily on the Isle of Man, is one of the three Q-Celtic (or Goidelic) languages, along with Irish and Scottish Gaelic. Although the language fell out of widespread use during the 19th and 20th centuries, it has seen a vibrant revitalization movement in recent years. The number of speakers is now growing, thanks in part to a Manx-language primary school on the island. The language also has a strong online presence relative to the size of the community. Several Manx dictionaries were published in the 19th and 20th centuries, and a number of these have been digitized in recent years and published online.1 The full text of the Bible, originally published in the 18th century, is also available and provides an easily-accessible source of parallel text.2 In terms of spoken language, the Irish Folklore Commission recorded fluent speakers on the Isle of Man in 1948, and those recordings are now available digitally as well.3 Outside of these corpus resources, very little advanced language technology exists for Manx. -

K 03-UP-004 Insular Io02(A)
By Bernard Wailes TOP: Seventh century A.D., peoples of Ireland and Britain, with places and areas that are mentioned in the text. BOTTOM: The Ogham stone now in St. Declan’s Cathedral at Ardmore, County Waterford, Ireland. Ogham, or Ogam, was a form of cipher writing based on the Latin alphabet and preserving the earliest-known form of the Irish language. Most Ogham inscriptions are commemorative (e.g., de•fin•ing X son of Y) and occur on stone pillars (as here) or on boulders. They date probably from the fourth to seventh centuries A.D. who arrived in the fifth century, occupied the southeast. The British (p-Celtic speakers; see “Celtic Languages”) formed a (kel´tik) series of kingdoms down the western side of Britain and over- seas in Brittany. The q-Celtic speaking Irish were established not only in Ireland but also in northwest Britain, a fifth- THE CASE OF THE INSULAR CELTS century settlement that eventually expanded to become the kingdom of Scotland. (The term Scot was used interchange- ably with Irish for centuries, but was eventually used to describe only the Irish in northern Britain.) North and east of the Scots, the Picts occupied the rest of northern Britain. We know from written evidence that the Picts interacted extensively with their neighbors, but we know little of their n decades past, archaeologists several are spoken to this day. language, for they left no texts. After their incorporation into in search of clues to the ori- Moreover, since the seventh cen- the kingdom of Scotland in the ninth century, they appear to i gin of ethnic groups like the tury A.D. -

Celts Ancient and Modern: Recent Controversies in Celtic Studies
Celts Ancient and Modern: Recent Controversies in Celtic Studies John R. Collis As often happens in conferences on Celtic Studies, I was the only contributor at Helsinki who was talking about archaeology and the Ancient Celts. This has been a controversial subject since the 1980s when archaeologists started to apply to the question of the Celts the changes of paradigm, which had impacted on archaeology since the 1960s and 1970s. This caused fundamental changes in the way in which we treat archaeological evidence, both the theoretical basis of what we are doing and the methodologies we use, and even affecting the sorts of sites we dig and what of the finds we consider important. Initially it was a conflict among archaeologists, but it has also spilt over into other aspects of Celtic Studies in what has been termed ‘Celtoscepticism’. In 2015–2016 the British Museum and the National Museum of Scotland put on exhibitions (Farley and Hunter 2015) based largely on these new approaches, raising again the conflicts from the 1990s between traditional Celticists, and those who are advocates of the new approaches (‘New Celticists’), but it also revived, especially in the popular press, misinformation about what the conflicts are all about. Celtoscepticism comes from a Welsh term celtisceptig invented by the poet and novelist Robin Llywelin, and translated into English and applied to Celtic Studies by Patrick Sims-Williams (1998); it is used for people who do not consider that the ancient people of Britain should be called Celts as they had never been so-called in the Ancient World. -

CEÜCIC LEAGUE COMMEEYS CELTIAGH Danmhairceach Agus an Rùnaire No A' Bhan- Ritnaire Aige, a Dhol Limcheall Air an Roinn I R ^ » Eòrpa Air Sgath Nan Cànain Bheaga
No. 105 Spring 1999 £2.00 • Gaelic in the Scottish Parliament • Diwan Pressing on • The Challenge of the Assembly for Wales • League Secretary General in South Armagh • Matearn? Drew Manmn Hedna? • Building Inter-Celtic Links - An Opportunity through Sport for Mannin ALBA: C O M U N N B r e i z h CEILTEACH • BREIZH: KEVRE KELTIEK • CYMRU: UNDEB CELTAIDD • EIRE: CONRADH CEILTEACH • KERNOW: KESUNYANS KELTEK • MANNIN: CEÜCIC LEAGUE COMMEEYS CELTIAGH Danmhairceach agus an rùnaire no a' bhan- ritnaire aige, a dhol limcheall air an Roinn i r ^ » Eòrpa air sgath nan cànain bheaga... Chunnaic sibh iomadh uair agus bha sibh scachd sgith dhen Phàrlamaid agus cr 1 3 a sliopadh sibh a-mach gu aighcaraeh air lorg obair sna cuirtean-lagha. Chan eil neach i____ ____ ii nas freagarraiche na sibh p-fhèin feadh Dainmheag uile gu leir! “Ach an aontaich luchd na Pàrlamaid?” “Aontaichidh iad, gun teagamh... nach Hans Skaggemk, do chord iad an òraid agaibh mu cor na cànain againn ann an Schleswig-Holstein! Abair gun robh Hans lan de Ball Vàidaojaid dh’aoibhneas. Dhèanadh a dhicheall air sgath nan cànain beaga san Roinn Eòrpa direach mar a rinn e airson na Daineis ann atha airchoireiginn, fhuair Rinn Skagerrak a dhicheall a an Schieswig-I lolstein! Skaggerak ]¡l¡r ori dio-uglm ami an mhinicheadh nach robh e ach na neo-ncach “Ach tha an obair seo ro chunnartach," LSchlesvvig-Molstein. De thuirt e sa Phàrlamaid. Ach cha do thuig a cho- arsa bodach na Pàrlamaid gu trom- innte ach:- ogha idir. chridheach. “Posda?” arsa esan. -

Contracted Preposition-Determiner Forms in German: Semantics And
Contracted Preposition-Determiner Forms in German: Semantics and Pragmatics A Thesis Presented to the Departament de Traducci´oi Filologia, Universitat Pompeu Fabra, Barcelona In Partial Fulfillment of the Requirements for the Degree Doctor of Philosophy by Estela Sophie Puig Waldm¨uller Advisor: Dr. Louise McNally Seifert March, 2008 Table of Contents 1 Introduction 1 2 Contexts where NCFs are used or preferred 4 2.1 Introduction . 5 2.2 Basic assumptions on the use of definite NPs in German . 5 2.2.1 Anaphoric use . 9 2.2.2 Endophoric use . 10 2.2.3 Generic use . 11 2.2.4 Use with inferable referents . 12 2.2.5 Use with “inherently” unique expressions . 14 2.3 NCFs as anaphoric definites . 15 2.4 NCFs as endophoric definites . 20 2.4.1 Restrictive relative clauses . 20 2.4.2 Restrictive modifiers . 22 ii TABLE OF CONTENTS iii 2.5 NCFs with inferable referents (“Bridging”) . 23 2.6 Summary . 25 3 Contexts where CFs are used or preferred 26 3.1 Introduction . 27 3.2 Overview . 27 3.3 CFs with semantically unique expressions . 31 3.3.1 “Head-Noun-Driven” uniqueness . 31 3.3.1.1 Proper nouns . 31 3.3.1.2 Time and Date expressions . 34 3.3.1.3 Abstract expressions . 35 3.3.1.4 Situationally unique individuals . 37 3.3.2 “Modifier-Driven” uniqueness: Superlatives and or- dinals . 41 3.4 CFs with non-specific readings . 42 3.4.1 Relational use . 43 3.4.2 Situational use (“Configurational use”) . 44 3.4.3 Idiomatic use .