Hausch D. B. (Ed.), Ziemba W. T. (Ed.)
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

44Th Academy of International Business (UK & Ireland Chapter
44th Academy of International Business (UK & Ireland Chapter) and 6th Reading International Business Conference Contemporary Issues in International Business: Are we seeing the tail-end of globalization? 6-8 April 2017 Henley Business School, University of Reading 1 Program Overview Last update: Friday, March 17, 2017 Thursday, 6 April 12:00 AIB UK&I Executive Meeting (Executive Committee members only) - HBS, G04 15:00 14:00 Conference registration desk opens Guests are invited to collect their badges and delegate packs. Delegates who have registered to present a poster are invited to affix it to the poster boards provided ICMA Centre, New Atrium 16:45 Conference bus departs from the Penta Hotel, Reading Guests travelling independently, please see travel and transportation section in this booklet 17:00 Conference bus departs from the Reading Station, bus stop EJ Guests travelling independently, please see travel and transportation section in this booklet 15:00 Doctoral Colloquium - Doctoral Session Doctoral Session Doctoral Session Doctoral Session Doctoral Session Doctoral Session 17:00 A1: Emerging A2: Conflict and A3: Institutions A4: Networks and A5: Multinational A6: International Markets Multinational and Political Ties Enterprises HRM and SME HBS, G10 Enterprises Capital HBS, G03 HBS, G04 exporting Chair: Peter J. Buckley HBS, 108 HBS, 208 Chair: Sharon Chair: Keith HBS, 201 Panellist: Frank Chair: Nigel Driffield Chair: Jim Love Patricia Loane Brouthers Chair: Vijay Edward McDonald, Shaowei He Panellist: Roger Panellist: Quyen -
Chude Member¾ 嗖
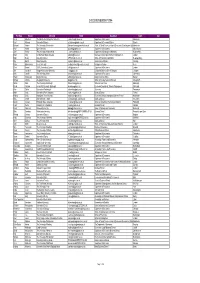
CHUDE MEMBERSHIP 2014 First Name Surname University E-Mail Department Town Sign Kevin Albertson The Manchester Metropolitan University [email protected] Department of Economics Manchester Paul Allanson University of Dundee [email protected] Department of Economic Studies Dundee Edmund Amann The University of Manchester [email protected] School of Social Sciences, Head of Economics (Teaching and Operations)Manchester Paul Anand Open University [email protected] Department of Economics Milton Keynes John Anchor The University of Huddersfield [email protected] Department of Strategy and Marketing Huddersfield Brian Ardy London South Bank University [email protected] Business, Computing & Information Management. London Mark Bailey University of Ulster [email protected] School of Economics and Politics Newtownabbey Ray Barrell Brunel University [email protected] Economics and Finance Uxbridge Robin Bladen-Hovell Keele University [email protected] Management School Keele Chris Bramall SOAS, University of London [email protected] Department of Economics London Jim Campbell Glasgow Caledonian University [email protected] Caledonian Business School Glasgow Glasgow Alan Carruth The University of Kent [email protected] Department of Economics Canterbury Shanti Chakravarty Bangor University [email protected] Bangor Business School Bangor Michael Christie Aberystywth University [email protected] School of Management and Business Aberystwyth Simon Clark The University of Edinburgh [email protected] -

Aalto University School of Business BI Norwegian Business School
5 Stars Awarded for Excellence – Europe - Astute International Influence In alphabetical order Aalto University School of Business BI Norwegian Business School – Handelshøyskolen BI Bocconi University SDA School of Management Copenhagen Business School Cranfield School of Management EBS Universität für Wirtschaft und Recht EMLyon Business School Erasmus University Rottderam School of Management ESADE Business School ESCP Europe Business School ESSEC Business School Graduate School of Management HEC Paris IE Business School IESE Business School IMD Business School INSEAD Fontainebleau (Paris) - Institut Européen d'Administration des Affaires Lomonosov Moscow State University Business School London Business School LSE London School of Economics and Political Science Maastricht University Schoolof Business and Management SGH Warsaw School of Economics St. Petersburg University Stockholm School of Economics Trinity College Dublin School of Business Universidade Nova de Lisboa School of Business and Economics Universität Mannheim Business School Universität St. Gallen School of Management Université Catholique de Louvain School of Management Université de Lausanne – HEC Université Paris Dauphine University College Dublin Michael Smurfit School of Business University of Economics Prague VSE University of Oxford Saïd Business School University of Warwick Business School Univesity of Cambridge Judge Business School WHU Otto Beisheim School of Management Wirtschaftsuniversität Wien – WU University of Economics and Business 4 Stars Awarded for -

Annual Report 2020 Coming Through the Crisis to Better and Happier Times Coming Through the Crisis to Better and Happier Times
Annual Report 2020 Coming through the crisis to better and happier times Coming through the crisis to better and happier times 4 Message from the Chairman of the Board and the President Dear EFMD Member, 2020 will, without a doubt, be a year we look back on and study in history for many years to come. The world has faced a pandemic with no boundaries or borders that has affected every country, society, people and organisation at every level and that continues to challenge the governance, structures and well-being of humanity. Yet, there have been remarkable advancements in science, collaboration and the human spirit as we start to slowly see hope with vaccines being developed. We have also witnessed incredible resilience, kindness and open debate on how to come out of this terrible crisis, with societies reflecting about the future and how to engage and think differently about the world. Within the EFMD network as well, so much has happened and so much has been learnt over this past year. We managed to hold our face-to-face gathering with the Deans and Directors in Milan last February which was hosted wonderfully by SDA Bocconi School of Management, with over 400 participants from 50 countries. Little did we know that Alain Dominique Perrin, soon after such a wonderful event where we enjoyed seeing friends, engaging with Chairman of the Board great speakers and making new connections, the world would change dramatically. We are incredibly proud to say that EFMD acted quickly. The response of our staff was remarkable, and nearly overnight, we adapted to the new conditions. -

Business & Management 2013
H I G H E R E D U C A T I O N Business & Management 2013 Resources for teaching and learning 2752 academics responded to our survey, helping us shape this catalogue to focus on Higher Education titles, with a little more emphasis on the new. Our full book list is available online, where it’s now easier to find what you want with our improved search and filter. If you’d like to be alerted to new books as they publish, sign up to our e-mail list: www.palgrave.com/mailinglist Management & Leadership Strategy Quantitative Methods & Operational Research For a complete list of titles, Human Resource Management & Employee Relations please visit www.palgrave.com * H I G H E R E D U C A T I O N Organization Studies . Business & Marketing International Business Management Operations Management 2013 IT for Business Entrepreneurship & Small Business Innovation Management K E Y T O S Y M B O L S Business Ethics & Corporate Social Responsibility New New title IC Inspection copy available Research Methods, Study Skills and Reference Ebook Title available as an ebook Web Web resource available Banking, Finance & Accounting *Prices are correct at the time of print Our catalogues and the packaging they are delivered in are recyclable - when you have finished with this catalogue please recycle it. Printed by an ISO 14001 (Environmental Standard) accredited printer on FSC standard paper and printed using vegetable-based ink. 1 MANAGEMENT & LEADERSHIP Project Management Management A Problem-Based Approach A Concise Introduction Bennet P. Lientz, Richard Pettinger, Business and Management Consultant, Lecturer in Professor, UCLA Management, University College London, UK Anderson School of ‘Pettinger has captured the essentials of organizations and Management, USA management studies in this concise and highly informative ‘This extremely useful introductory text. -

BUSINESS SCHOOLS and the PUBLIC GOOD a Chartered ABS Taskforce Report
BUSINESS SCHOOLS AND THE PUBLIC GOOD A Chartered ABS Taskforce Report June 2021 Business Schools and the Public Good Page 1 CONTENTS page Foreword ......................................................................................................................................................... 2 Executive Summary .................................................................................................................................3 The Taskforce ................................................................................................................................................ 4 Chapter 1: ........................................................................................................................................................ 5 a. Introduction ........................................................................................................................................... 5 b. Objectives and Methodology ................................................................................................... 11 Chapter 2: The View from Business Schools ....................................................................13 a. Survey Results ..................................................................................................................................... 14 Chapter 3: Promising Practices .................................................................................................. 22 a. Teaching ................................................................................................................................................ -
EIBA 2019 Leeds 45Th European International Business Academy Conference
EIBA 2019 Leeds 45th European International Business Academy Conference What Now? International Business in a Confused World Order Leeds, 13-15 December 2019 EIBA 2019 Leeds EIBA 2020 Madrid 46th EIBA Annual Conference 10-12 DecemberEIBA 2020 Madrid 2020 th Complutense46 EIBA Annual Conference University of Madrid, Spain 10-12 December 2020 “Firms,Complutense University of Madrid Innovation, and Location, Spain Reshaping International Business for “Firms, Innovation, and Location SustainableReshaping Development”International Business for Sustainable Development” The challenges defined in the Sustainable Development Goals (SDGs) have moved the traditional development agenda The challenges forward. defined The UN’sin the 2030 Sustainable AgendaDevelopment implies a radicalGoals (SDGs) shift from have prior moved approaches;the traditional economic, political, and social actors development have agenda all beenforward. called The to UNaction,’s 2030 given Agenda that implies potential a radical solutionsshift are from to beprior executedapproaches globally.; Business firms in particular – economic, politicalalong with, and social actors governments,have NGOs,all been universities called to action and, othergiven that socialpotential solutions are actors – should taketo be a more active role in contributing to executed globally. sustainableBusiness firm development.s in particular – along with governments, NGOs, universities and other social actors – should take a more active role in contributing to sustainable development. The presiding theme for EIBA 2020 is The presiding theme for‘firms, innovation EIBA 2020 is, and ‘firms,location innovation,at the crossroad and locations of IB and atsustainable the crossroads of IB and sustainable developmentdevelopment’.’. The rationale The is to discuss rationale local actions that is to discuss localcan be applied to actions that global can solutions andbe applied to flows of global solutions and flows of information to information to and from the IB community. -

Business History News
BUSINESS HISTORY NEWS Association of Business Historians The Newsletter of the Association of Business Historians Spring 2006 No. 31 ISSN 9062-9440 COUNCIL MEMBERS President: John F. Wilson ([email protected]) Past President: Sue Bowden ([email protected]) Secretary/ Treasurer: Neil Rollings (n.rollings@[email protected]) Newsletter Editor: Teresa da Silva Lopes ([email protected]) Council Member: Peter Scott (p.m. [email protected]) Secretary/Treasurer Elect: Maggie Walsh ([email protected]) Newsletter Editor Elect: Richard Coopey ([email protected]) Ex officio: Coleman Prize Winner 2005: Alan Carroll ([email protected]) Webmaster: Teresa da Silva Lopes ([email protected]) Contents Editorial Visit the ABH Website Feature Articles – The Current State of the ABH (i) John Wilson, ‘The ABH: Position and Status in 2006’ (ii) Neil Rollings, ‘ABH is a Treasure’, ‘Keep up the Good Work!!’, ‘The Council does a Great Job! ABH Conference 2006, 16 – 17 June - Programme: ‘Globalization and Business History’ - Registration Form (including accommodation booking) Special Events – Alfred D. Chandler Jr. Celebration Other 2006 Conferences 2007 Conferences - ABH Call for Papers - Other Conferences Seminars and Workshops Call for Papers – Special Issues of Journals Doctoral Research Opportunities 2007 Archives News Discounts for ABH Members ABH Membership Form: Join / Renew Editorial As usual this Spring issue of the ABH newsletter is mainly dedicated to advertising the Annual Conference which, this year, will take place on 16-17 June at Queen Mary, University of London. The subject of the conference is ‘Globalization and Business History’, and the topics covered, as well as the institutions and countries of origin of the speakers – from all continents of the world, clearly fit this global theme. -

ABS PILLARS Whole
THE HIGH VALUE OF BUSINESS SCHOOLS TO THE ECONOMY AND SOCIETY 21ST CENTURY CURRICULUM WORKING SMARTER, LEANER AND GREENER INTERNATIONALISATION OF BUSINESS SCHOOLS THE HIGH VALUE OF BUSINESS SCHOOLS TO UNIVERSITIES PILLARS OF THE SUSTAINABLE ECONOMY PILLARS OF THE SUSTAINABLE 2010/11 OUR ROLE The Association of Business Schools (ABS) is the representative body and authoritative voice for all the leading business schools of UK universities, higher education institutions and independent management colleges. With over 100 members, ABS promotes the study of business and management to help improve the quality and effectiveness of managers in the UK and internationally. Formed in 1992, ABS works with similar organisations in Europe and around the world to influence the international management education community. OUR MISSION To promote the interests of our members and the business and management education, training, research and development they provide, nationally and internationally, so as to improve the quality and effectiveness of management, entrepreneurship and leadership for the benefit of society at large. The Association of Business Schools 137 Euston Road, London NW1 2AA Tel +44 (0)20 7388 0007 Fax +44 (0)20 7388 0009 Email [email protected] Web www.the-abs.org.uk PILLARS FOREWORD PROFESSOR HUW MORRIS 2-3 OF THE SUSTAINABLE THE YEAR IN FOCUS 4-8 ECONOMY A snapshot of some recent highlights, key developments 2010/11 and achievements of members CASE STUDIES > The High Value of Business Schools to Universities 10-11 > Internationalisation -

Contemporary Issues in International Business: Are We Seeing the Tail-End of Globalisation?
44TH AIB (UKI) AND 6TH READING CONFERENCE 2017 Contemporary Issues in International Business: Are we seeing the tail-end of globalisation? 6-8 April, 2017 Henley Business School, University of Reading AIB–UKI Conference Welcome Dear friends and colleagues, We are delighted to welcome you to the 44th 2017 AIB–UKI Conference, this year merged with the 6th Reading IB conference! The Reading Conferences are a relatively new phenomenon: we hosted the first one in 2007, to mark John Dunning’s 80th birthday, as well as to re-launch the Centre for Inteernational Business Studies at Reading. This subsequently became a biennial event, and the Centre was renamed in John Dunning’s honour at our second conference (and remains a biennial event). That Peter Buckley and Mark Casson are receiving this year’s AIB–UKI Lifetime Achievement Award, named after John Dunning at a conference hosted by a Research Centre in his memory, has certain poetry to it. Both began their careers at the Department of Economics here at Reading (which was to form part of Henley Business School) and worked closely with John. As such, this confluence of the two conferences is extremely pleasing, at a number of levels. It is also worth noting that the AIB– UKI was last hosted in Reading in 1982, with a somewhat younger Mark Casson as the local organiser. Thus the ‘feel good’ factor of these coincidences (or is it fate?) is incredibly higgh. The joint event brings together the informal intellectual fraternity that is known as ‘the Reading School’ with the more formal (and non-dennominational) and significantly fine-tuned organisational machinery that is the Academy of International Business. -

How Do the Top 40 Business Schools in the UK Understand, Teach and Implement KM in Their Teaching?
How do the top 40 business schools in the UK understand, teach and implement KM in their teaching? Article (Accepted Version) Ahmed, Allam (2017) How do the top 40 business schools in the UK understand, teach and implement KM in their teaching? World Journal of Science, Technology and Sustainable Development, 14 (2/3). pp. 111-134. ISSN 2042-5945 This version is available from Sussex Research Online: http://sro.sussex.ac.uk/id/eprint/68255/ This document is made available in accordance with publisher policies and may differ from the published version or from the version of record. If you wish to cite this item you are advised to consult the publisher’s version. Please see the URL above for details on accessing the published version. Copyright and reuse: Sussex Research Online is a digital repository of the research output of the University. Copyright and all moral rights to the version of the paper presented here belong to the individual author(s) and/or other copyright owners. To the extent reasonable and practicable, the material made available in SRO has been checked for eligibility before being made available. Copies of full text items generally can be reproduced, displayed or performed and given to third parties in any format or medium for personal research or study, educational, or not-for-profit purposes without prior permission or charge, provided that the authors, title and full bibliographic details are credited, a hyperlink and/or URL is given for the original metadata page and the content is not changed in any way. http://sro.sussex.ac.uk 1 How do the top 40 business schools in the UK understand, teach and implement KM in their teaching? Abstract: Purpose The emergence of ‘knowledge economies’ brings along new lenses to organizational management and behaviour. -

Essential Texts for MBA Students 2015-2016
Essential Texts for MBA Students 2015-2016 sagepub.co.uk Essential Texts for MBA Students Welcome... Welcome to the 2015-2016 MBA catalogue. As we reach our 50th anniversary this year, we’re looking forward to celebrating with all of you whom we have known and worked with over the years and who have been pivotal in our growth as an independent, international, academic social science publisher of textbooks. As we look back on our success so far, and forward to a dynamic and innovative publishing future, we would like to take this opportunity to thank you for choosing SAGE and for being part of our journey. This catalogue showcases SAGE’s most suitable texts and resources for use on an MBA programme of study. Whether you are looking for texts on key business topics such as leadership, strategy, marketing and organization studies, or texts to support your study skills and research, we are confi dent you will fi nd something on these pages to meet your and your students’ needs. Our titles are now available in eBook format for individual purchase. Key titles come with access to companion websites which may contain slides, teaching notes, access to SAGE journal articles, MCQ’s and podcasts. Please visit www.sagepub.co.uk for our complete backlist of titles or contact your local sales representative for further guidance and to discuss custom publishing solutions. The SAGE Business & Management Team New and Bestselling Titles P4 P13 P5 Essential Texts for MBA Students Contact us Contents 1 Oliver’s Yard, 55 City Road, Corporate Communication & PR .................