A Case Study in Carnatic Classical Music (CCM)
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Music Academy, Madras 115-E, Mowbray’S Road
Tyagaraja Bi-Centenary Volume THE JOURNAL OF THE MUSIC ACADEMY MADRAS A QUARTERLY DEVOTED TO THE ADVANCEMENT OF THE SCIENCE AND ART OF MUSIC Vol. XXXIX 1968 Parts MV srri erarfa i “ I dwell not in Vaikuntha, nor in the hearts of Yogins, nor in the Sun; (but) where my Bhaktas sing, there be I, Narada l ” EDITBD BY V. RAGHAVAN, M.A., p h .d . 1968 THE MUSIC ACADEMY, MADRAS 115-E, MOWBRAY’S ROAD. MADRAS-14 Annual Subscription—Inland Rs. 4. Foreign 8 sh. iI i & ADVERTISEMENT CHARGES ►j COVER PAGES: Full Page Half Page Back (outside) Rs. 25 Rs. 13 Front (inside) 20 11 Back (Do.) „ 30 „ 16 INSIDE PAGES: 1st page (after cover) „ 18 „ io Other pages (each) „ 15 „ 9 Preference will be given to advertisers of musical instruments and books and other artistic wares. Special positions and special rates on application. e iX NOTICE All correspondence should be addressed to Dr. V. Raghavan, Editor, Journal Of the Music Academy, Madras-14. « Articles on subjects of music and dance are accepted for mblication on the understanding that they are contributed solely o the Journal of the Music Academy. All manuscripts should be legibly written or preferably type written (double spaced—on one side of the paper only) and should >e signed by the writer (giving his address in full). The Editor of the Journal is not responsible for the views expressed by individual contributors. All books, advertisement moneys and cheques due to and intended for the Journal should be sent to Dr. V. Raghavan Editor. Pages. -

Syllabus for Post Graduate Programme in Music
1 Appendix to U.O.No.Acad/C1/13058/2020, dated 10.12.2020 KANNUR UNIVERSITY SYLLABUS FOR POST GRADUATE PROGRAMME IN MUSIC UNDER CHOICE BASED CREDIT SEMESTER SYSTEM FROM 2020 ADMISSION NAME OF THE DEPARTMENT: DEPARTMENT OF MUSIC NAME OF THE PROGRAMME: MA MUSIC DEPARTMENT OF MUSIC KANNUR UNIVERSITY SWAMI ANANDA THEERTHA CAMPUS EDAT PO, PAYYANUR PIN: 670327 2 SYLLABUS FOR POST GRADUATE PROGRAMME IN MUSIC UNDER CHOICE BASED CREDIT SEMESTER SYSTEM FROM 2020 ADMISSION NAME OF THE DEPARTMENT: DEPARTMENT OF MUSIC NAME OF THE PROGRAMME: M A (MUSIC) ABOUT THE DEPARTMENT. The Department of Music, Kannur University was established in 2002. Department offers MA Music programme and PhD. So far 17 batches of students have passed out from this Department. This Department is the only institution offering PG programme in Music in Malabar area of Kerala. The Department is functioning at Swami Ananda Theertha Campus, Kannur University, Edat, Payyanur. The Department has a well-equipped library with more than 1800 books and subscription to over 10 Journals on Music. We have gooddigital collection of recordings of well-known musicians. The Department also possesses variety of musical instruments such as Tambura, Veena, Violin, Mridangam, Key board, Harmonium etc. The Department is active in the research of various facets of music. So far 7 scholars have been awarded Ph D and two Ph D thesis are under evaluation. Department of Music conducts Seminars, Lecture programmes and Music concerts. Department of Music has conducted seminars and workshops in collaboration with Indira Gandhi National Centre for the Arts-New Delhi, All India Radio, Zonal Cultural Centre under the Ministry of Culture, Government of India, and Folklore Academy, Kannur. -

Navarathri Mandapam CHAPTER 4 Musical Aspect of Maharaja’S Compositions
Navarathri Mandapam CHAPTER 4 Musical Aspect of Maharaja’s Compositions 4.1. Introduction “Music begins where the possibilities of language end.” - Jean Sibelius Music is just not confined only to notes and its rendition, it is a unit of melody, its combinations and beautiful body movements. Therefore it is called Samageetam (g“rV_²) and Sharangdeva has given an apt definition to the term - JrV§ dmÚ§ VWm Z¥Ë`§, Ì`§ g“rV_wÀ`Vo& Maharaja’s compositions are models of all the three faculties of music. They are sung, played on various instruments and some compositions are exclusively composed for dance performances. To understand the nuance and technical aspects of music, it is very necessary to look back at the history of both the streams of Indian Music which are prevalent. As discussed in the earlier chapters, North Indian Music, popularly known as the Hindusthani Music had a lot of transitions since the Vedic era to the Mughal or the pre- indehendence era. After the decline of the Mughal Empire, the patronage of music continued in smaller princely kingdoms like Gwalior, Jaipur, Patiala giving rise to diversity of styles that is today known as Gharanas. Meanwhile the Bhakti and Sufi traditions -------------------------------- ( 100 ) ---------------------------------- continued to develop and interact with the different schools of music. Gharana system had a peculiar tradition of one-to-one teaching which was imparted through the Guru-Shishya tradition. To a large extent, it was limited to the palace and dance halls. It was shunned by the intellectuals, avoided by the educated middle class, and in general looked down upon as a frivolous practise. -

Rakti in Raga and Laya
VEDAVALLI SPEAKS Sangita Kalanidhi R. Vedavalli is not only one of the most accomplished of our vocalists, she is also among the foremost thinkers of Carnatic music today with a mind as insightful and uncluttered as her music. Sruti is delighted to share her thoughts on a variety of topics with its readers. Rakti in raga and laya Rakti in raga and laya’ is a swara-oriented as against gamaka- complex theme which covers a oriented raga-s. There is a section variety of aspects. Attempts have of exponents which fears that ‘been made to interpret rakti in the tradition of gamaka-oriented different ways. The origin of the singing is giving way to swara- word ‘rakti’ is hard to trace, but the oriented renditions. term is used commonly to denote a manner of singing that is of a Yo asau Dhwaniviseshastu highly appreciated quality. It swaravamavibhooshitaha carries with it a sense of intense ranjako janachittaanaam involvement or engagement. Rakti Sankarabharanam or Bhairavi? rasa raga udaahritaha is derived from the root word Tyagaraja did not compose these ‘ranj’ – ranjayati iti ragaha, ranjayati kriti-s as a cluster under the There is a reference to ‘dhwani- iti raktihi. That which is pleasing, category of ghana raga-s. Older visesha’ in this sloka from Brihaddcsi. which engages the mind joyfully texts record these five songs merely Scholars have suggested that may be called rakti. The term rakti dhwanivisesha may be taken th as Tyagaraja’ s compositions and is not found in pre-17 century not as the Pancharatna kriti-s. Not to connote sruti and that its texts like Niruktam, Vyjayanti and only are these raga-s unsuitable for integration with music ensures a Amarakosam. -

Discographie
698 DISCOGRAPHIE Dans cette discographie, nous avons essayer de recenser, de manière aussi complète que possible, tous les enregistrements commerciaux réalisés jusqu'à ce jour par les musiciens que nous avons étudiés au cours de notre travail, ainsi que ceux de quelques autres artistes qui leur sont très directement affiliés (Karaikudi S. Subramaniam, Jayanthi R. Kiran (anciennement Jayanthi R. Krishnan), K.S. Narayanaswamy, Catherine Zalay & Anandi Roy, Muthulakshmi Ranganathan, Kalyani Lakshminarayana et Pappu Chandrasekhar). L'ordre adopté ici correspond à celui employé dans la première partie de cet ouvrage, procédant par écoles, b別-s et générations. Les disques de compilation, réalisés avec des enregistrements extraits d'albums de nombreux artistes différents, ne sont pas pris en compte. Cette liste a été constituée à partir des discographies rédigées par Alain Danielou, Elise B. Barnett et Michael S. Kinnear1, du catalogue de la collection privée de V.A.K. Ranga Rao à Madras, des catalogues des firmes H.M.V., Sangeetha, Vani, A.V.M. audio, et de nos propres recherches personnelles2. Les orthographes des titres des oeuvres figurant sur ces documents sonores, souvent approximatives sur les pochettes qui leur sont jointes, sont rectifiées dans la mesure du possible en suivant celles indiquées par l'Index of Songs in South Indian Music3, ou parfois en se référant à la partition originale. Certains renseignements que nous n'avons pu retrouver (date de parution, råga, tå¬a, compositeur) sont néanmoins absents dans quelques cas limités, et nous prions le lecteur de nous en excuser. 1 Cf. DANIELOU (Alain) : Catalogue de la musique Indienne classique et traditionnelle enregistrée, Paris, UNESCO, 1952, 236 p. -

Translations of Krithis of Ashok Madhava Contents
Translations of Krithis of ashok Madhava I am a multi linguist and enjoyed translating compositions of another Multi linguist. I have translated 59 of his compositions from Sanskrit, Tamil, Telugu and kannada. I enjoyed it Contents Translations of Krithis of ashok Madhava ................................................. 1 1. Abhaghi Naanalla(Kannada) ........................................................ 3 2. Adhi Nayakim(Sanskrit) ................................................................ 5 3. Amba YUvathi(Sanskrit) ............................................................. 6 4. Anbu vellame (Tamil) ................................................................... 8 5. Aravinda Nayanam (Sanskrit) ....................................................... 9 6. Arul Tharuvai shri(tamil) ........................................................... 10 7. Baaramma Hogona(Kannada) ................................................... 12 8. Bandhaa Krishna(Kannada) ....................................................... 13 9. Bhagavathi neene hari manohari (kannada).............................. 15 10. Bhajami Manasa(sanskrit) ......................................................... 16 11. Bhajamyaham satatam(sanskrit) .............................................. 18 12. Bhajana seyyu(telugu)................................................................ 20 13. BHajare re sriman(Sanskrit) ...................................................... 21 14. BHajeham sri(Sanskrit) .............................................................. -

Carnatic Music Primer
A KARNATIC MUSIC PRIMER P. Sriram PUBLISHED BY The Carnatic Music Association of North America, Inc. ABOUT THE AUTHOR Dr. Parthasarathy Sriram, is an aerospace engineer, with a bachelor’s degree from IIT, Madras (1982) and a Ph.D. from Georgia Institute of Technology where is currently a research engineer in the Dept. of Aerospace Engineering. The preface written by Dr. Sriram speaks of why he wrote this monograph. At present Dr. Sriram is looking after the affairs of the provisionally recognized South Eastern chapter of the Carnatic Music Association of North America in Atlanta, Georgia. CMANA is very privileged to publish this scientific approach to Carnatic Music written by a young student of music. © copyright by CMANA, 375 Ridgewood Ave, Paramus, New Jersey 1990 Price: $3.00 Table of Contents Preface...........................................................................................................................i Introduction .................................................................................................................1 Swaras and Swarasthanas..........................................................................................5 Ragas.............................................................................................................................10 The Melakarta Scheme ...............................................................................................12 Janya Ragas .................................................................................................................23 -

Mukherji-Handout-0056.Pdf
Rāga as Scale 42nd Annual Conference of the Society for Music Theory November 7, 2019 Columbus OH USA Sam Mukherji University of Michigan, Ann Arbor ([email protected]) 2 Example 1. Two theorists of North Indian classical music Vishnu Narayan Bhatkhande (1860–1936) Omkarnath Thakur (1897–1967) 3 phrases (1 and 3 performed by Amjad Ali Khan, 2 and 4 performed by Buddhadev Das Gupta) Ali2 and by Khan, (1 and Amjad 4 performed 3 performed phrases rāga Example 2. Four Example 2. Four 4 Example 3. Bhatkhande’s list of ten tḥāṭs, from his Hindustānī Sangīta Paddhatī (1909-32) Tḥāṭ Scale structure (centered on C) Western equivalent Pūrvī C Db Eb F# G Ab Bb C Mārvā C Db Eb F# G Ab Bb C Kalyān Lydian C Db Eb F# G Ab Bb C Bilāval Major, or Ionian C Db Eb F# G Ab Bb C Khamāj Mixolydian C Db Eb F# G Ab Bb C Kāfi Dorian C Db Eb F# G Ab Bb C Āsāvari Natural minor, or Aeolian C Db Eb F# G Ab Bb C Bhairavī Phrygian C Db Eb F# G Ab Bb C Bhairav C Db Eb F# G Ab Bb C Tōdī C Db Eb F# G Ab Bb C Example 4. Thakur’s list of six pedagogical rāgas, from his Sangītānjalī (1938-62) Name Rāga scale (centered on C) Forbidden scale degrees Bhoop C D E F G A B C 4 and 7 Hamsadhvanī C D E F G A B C 4 and 6 Durgā C D E F G A B C 3 and 7 Sārang C D E F G A B C 3 and 6 Tilang C D E F G A B C 2 and 6 Bhinna-shadạj C D E F G A B C 2 and 5 5 Example 5. -

The Journal Ie Music Academy
THE JOURNAL OF IE MUSIC ACADEMY MADRAS A QUARTERLY OTED TO THE ADVANCEMENT OF THE SCIENCE AND ART OF MUSIC XIII 1962 Parts I-£V _ j 5tt i TOTftr 1 ®r?r <nr firerftr ii dwell not in Vaikuntha, nor in the hearts of Yogins, - the Sun; where my Bhaktas sing, there be I, ! ” EDITED BY V. RAGHAVAN, M.A., PH.D. 1 9 6 2 PUBLISHED BY HE MUSIC ACADEMY, MADRAS 115-E, M OW BRAY’S RO AD, M ADRAS-14. "iption—Inland Rs, 4. Foreign 8 sh. Post paid. i ADVERTISEMENT CHARGES I S COVER PAGES: if Back (outside) $ if Front (inside) i Back (D o.) if 0 if INSIDE PAGES: if 1st page (after cover) if if Ot^er pages (each) 1 £M E N i if k reference will be given to advertisers of if instruments and books and other artistic wares. if I Special position and special rate on application. Xif Xtx XK XK X&< i - XK... >&< >*< >*<. tG O^ & O +O +f >*< >•< >*« X NOTICE All correspondence should be addressed to Dr. V. R Editor, Journal of the Music Academy, Madras-14. Articles on subjects of music and dance are accep publication on the understanding that they are contribute) to the Journal of tlie Music Academy. All manuscripts should be legibly written or preferab written (double spaced—on one side of the paper only) and be signed by the writer (giving his address in full). The Editor of the Journal is not responsible for t1 expressed by individual contributors. All books, advertisement, moneys and cheque ♦ended for the Journal should be sent to D CONTENTS 'le X X X V th Madras Music Conference, 1961 : Official Report Alapa and Rasa-Bhava id wan C. -

A Method for Quantifying Raga Similarity
INTERNATIONAL JOURNAL OF SCIENTIFIC & TECHNOLOGY RESEARCH VOLUME 10, ISSUE 06, JUNE 2021 ISSN 2277-8616 Ragadist: A Method For Quantifying Raga Similarity Vinuraj Devaraj Abstract: Raga Similarity had been a topic of fascination among Karnatik music followers. Though the topic remains active and interesting, a lack of appropriate similarity quantification method leads to subjective interpretations which in turn can be ambiguous intermittently. In this paper, we propose a raga similarity method, RagaDist, that quantifies similarities between raga pairs, based on their semantic structure and classifies the similarity into a 4- scale measure. Similarities derived using RagaDist is compared with popular string similarity methods using clustering approaches – Hierarchical clustering and Partition Around Medoids (PAM) and Multi-Dimensional Scaling (MDS) methods to analyze emerging patterns and characteristics among Melakarta raga similarities. Empirical measurements were conducted using one-way ANOVA and post hoc analysis. We also determined that using RagaDist, a threshold of 0.79 may be used as a cut off to distinguish ragas based on similarity. Index Terms: Multi-Dimensional Scaling, Correlation Analysis, Clustering, Partition Around Medoids (PAM), Levenshtein distance, ANOVA, Karnatik Ragas. ———————————————————— 1 INTRODUCTION KARNATIK Music is an ancient, sophisticated yet refined art form of delivering mesmerizing music through a structured In its core, Karnatik ragas are based on sapta swaras or seven method. This form of art is predominantly practiced in South musical notes viz. ―Sa‖, ―Ri‖, ―Ga‖, ―Ma‖, ―Pa‖, ―Dha‖ and ―Ni‖. India and this form of music is still the foundation for various The figure 1 below represents solfeggio of Karnatik raga as musical compositions that are emerging in several forms of represented on a single octave of a piano. -

Sruti Online LETTERS Subscribe to Magzter GOLD
To enjoy unlimited reading of Sruti online LETTERS Subscribe to Magzter GOLD For queries, contact [email protected] or log in and chat with a representative on www.magzter.com SRUTI BOX Chat lines are open 24x7. Hariharasubramania Iyer well as other times of the year. It would himself acknowledged, they are be useful to rasikas and students living standing on the shoulders of giants The article on guru Vechoor outside Chennai. and are able to see far. They are well Hariharasubramania Iyer of Trivandrum educated, technologically savvy, keen is a well documented and interesting S.K. Anil Murthy by email learners and have a far better voice portrayal of the esteemed musician. culture than the giants of the past. They Thanks to the author C. Ramakrishnan P.V. Krishnamoorthy are dedicated and have chosen classical for sparing no effort to collate minute music as a career which is none-too- details of the personality and present it Most of us had only heard of this promising, what with dwindling and in a delectable manner. Although I have great man, more as a brother of the ageing audiences. Their only sources not heard of any concert of Vechoor in late irrepressible Subbudu. Coming to of a neat income seem to be foreign Bengaluru, I had a couple of students know of his pioneering contributions tours and ‘fusion’ programmes. Local from Kerala who had been his students. to various forms of music and dance, remunerations are paltry, with almost nil Their pathantaram was solid and the working for All India Radio and gate collections. -
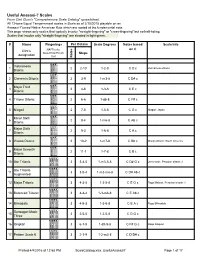
Comprehensive Scale Catalog" Spreadsheet
Useful Anasasi-7 Scales From Clint Goss's "Comprehensive Scale Catalog" spreadsheet. All 12-tone Equal Temperament scales in Scala as of 2/10/2015 playable on an Anasazi-7 tuned Native American flute which are rooted at the fundamental note. This page shows only scales that typically involve "straight-fingering" or "cross-fingering" but no half-holing. Scales that involve only "straight-fingering" are shaded in light green. # Name Fingerings Per Octave Scale Degrees Notes based Scala Info on C Clint's NAFTracks SevenHoleThumb Steps designation font Notes Vietnamese 1 2 2-10 1-2-8 C D c Vietnamese ditonic Ditonic 018 2 Cheremis Ditonic 028 2 3-9 1-m3-8 C D# c Major Third 3 2 4-8 1-3-8 C E c Ditonic 038 4 Tritone Ditonic 0G8 2 6-6 1-d5-8 C F# c 5 Niagari 048 2 7-5 1-5-8 C G c Niagari: Japan Minor Sixth 6 2 8-4 1-m6-8 C Ab c Ditonic 0K8 Major Sixth 7 2 9-3 1-6-8 C A c Ditonic 058 8 Warao Ditonic 068 2 10-2 1-m7-8 C Bb c Warao ditonic: South America Major Seventh 9 2 11-1 1-7-8 C B c Ditonic 078 10 Ute Tritonic 0248 3 3-4-5 1-m3-5-8 C D# G c Ute tritonic, Peruvian tritonic 2 Ute Tritonic 11 3 3-5-4 1-m3-m6-8 C D# Ab c Augmented 02K8 12 Major Tritonic 0348 3 4-3-5 1-3-5-8 C E G c Raga Malasri, Peruvian tritonic 1 13 Balanced Tritonic 03K8 3 4-4-4 1-3-m6-8 C E Ab c 14 Bilwadala 0358 3 4-5-3 1-3-6-8 C E A c Raga Bilwadala Sansagari Mode 15 3 2-5-5 1-2-5-8 C D G c Three 0148 16 Ongkari 0G48 3 6-1-5 1-d5-5-8 C F# G c Raga Ongkari 17 Pattern Scale 6 0128 3 2-1-9 1-2-m3-8 C D D# c Printed 4/4/2016 at 12:58 PM ScaleCatalog.xlsx, UsefulAnasazi7 Page