Java Optimizations Using Bytecode Templates
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Actors at Work Issue Date: 2016-12-15 Actors at Work Behrooz Nobakht
Cover Page The handle http://hdl.handle.net/1887/45620 holds various files of this Leiden University dissertation Author: Nobakht, Behrooz Title: Actors at work Issue Date: 2016-12-15 actors at work behrooz nobakht 2016 Leiden University Faculty of Science Leiden Institute of Advanced Computer Science Actors at Work Actors at Work Behrooz Nobakht ACTORS AT WORK PROEFSCHRIFT ter verkrijging van de graad van doctor aan de Universiteit Leiden op gezag van de Rector Magnificus prof. dr. C. J. J. M. Stolker, volgens besluit van het College voor Promoties te verdedigen op donderdag 15 december 2016 klokke 11.15 uur door Behrooz Nobakht geboren te Tehran, Iran, in 1981 Promotion Committee Promotor: Prof. Dr. F.S. de Boer Co-promotor: Dr. C. P. T. de Gouw Other members: Prof. Dr. F. Arbab Dr. M.M. Bonsangue Prof. Dr. E. B. Johnsen University of Oslo, Norway Prof. Dr. M. Sirjani Reykjavik University, Iceland The work reported in this thesis has been carried out at the Center for Mathematics and Computer Science (CWI) in Amsterdam and Leiden Institute of Advanced Computer Science at Leiden University. This research was supported by the European FP7-231620 project ENVISAGE on Engineering Virtualized Resources. Copyright © 2016 by Behrooz Nobakht. All rights reserved. October, 2016 Behrooz Nobakht Actors at Work Actors at Work, October, 2016 ISBN: 978-94-028-0436-2 Promotor: Prof. Dr. Frank S. de Boer Cover Design: Ehsan Khakbaz <[email protected]> Built on 2016-11-02 17:00:24 +0100 from 397717ec11adfadec33e150b0264b0df83bdf37d at https://github.com/nobeh/thesis using: This is pdfTeX, Version 3.14159265-2.6-1.40.16 (TeX Live 2015/Debian) kpathsea version 6.2.1 Leiden University Leiden Institute of Advanced Computer Science Faculty of Science Niels Bohrweg 1 2333 CA and Leiden Contents I Introduction1 1 Introduction 3 1.1 Objectives and Architecture . -
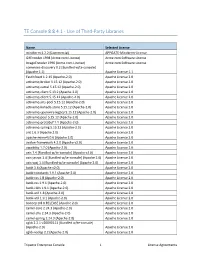
TE Console 8.8.4.1 - Use of Third-Party Libraries
TE Console 8.8.4.1 - Use of Third-Party Libraries Name Selected License mindterm 4.2.2 (Commercial) APPGATE-Mindterm-License GifEncoder 1998 (Acme.com License) Acme.com Software License ImageEncoder 1996 (Acme.com License) Acme.com Software License commons-discovery 0.2 [Bundled w/te-console] (Apache 1.1) Apache License 1.1 FastInfoset 1.2.15 (Apache-2.0) Apache License 2.0 activemQ-broker 5.15.12 (Apache-2.0) Apache License 2.0 activemQ-camel 5.15.12 (Apache-2.0) Apache License 2.0 activemQ-client 5.13.2 (Apache-2.0) Apache License 2.0 activemQ-client 5.15.12 (Apache-2.0) Apache License 2.0 activemQ-jms-pool 5.15.12 (Apache-2.0) Apache License 2.0 activemQ-kahadb-store 5.15.12 (Apache-2.0) Apache License 2.0 activemQ-openwire-legacy 5.15.12 (Apache-2.0) Apache License 2.0 activemQ-pool 5.15.12 (Apache-2.0) Apache License 2.0 activemQ-protobuf 1.1 (Apache-2.0) Apache License 2.0 activemQ-spring 5.15.12 (Apache-2.0) Apache License 2.0 ant 1.6.3 (Apache 2.0) Apache License 2.0 apache-mime4j 0.6 (Apache 2.0) Apache License 2.0 avalon-framework 4.2.0 (Apache v2.0) Apache License 2.0 awaitility 1.7.0 (Apache-2.0) Apache License 2.0 axis 1.4 [Bundled w/te-console] (Apache v2.0) Apache License 2.0 axis-jaxrpc 1.4 [Bundled w/te-console] (Apache 2.0) Apache License 2.0 axis-saaj 1.4 [Bundled w/te-console] (Apache 2.0) Apache License 2.0 batik 1.6 (Apache v2.0) Apache License 2.0 batik-constants 1.9.1 (Apache-2.0) Apache License 2.0 batik-css 1.8 (Apache-2.0) Apache License 2.0 batik-css 1.9.1 (Apache-2.0) Apache License 2.0 batik-i18n 1.9.1 (Apache-2.0) -

Full-Graph-Limited-Mvn-Deps.Pdf
org.jboss.cl.jboss-cl-2.0.9.GA org.jboss.cl.jboss-cl-parent-2.2.1.GA org.jboss.cl.jboss-classloader-N/A org.jboss.cl.jboss-classloading-vfs-N/A org.jboss.cl.jboss-classloading-N/A org.primefaces.extensions.master-pom-1.0.0 org.sonatype.mercury.mercury-mp3-1.0-alpha-1 org.primefaces.themes.overcast-${primefaces.theme.version} org.primefaces.themes.dark-hive-${primefaces.theme.version}org.primefaces.themes.humanity-${primefaces.theme.version}org.primefaces.themes.le-frog-${primefaces.theme.version} org.primefaces.themes.south-street-${primefaces.theme.version}org.primefaces.themes.sunny-${primefaces.theme.version}org.primefaces.themes.hot-sneaks-${primefaces.theme.version}org.primefaces.themes.cupertino-${primefaces.theme.version} org.primefaces.themes.trontastic-${primefaces.theme.version}org.primefaces.themes.excite-bike-${primefaces.theme.version} org.apache.maven.mercury.mercury-external-N/A org.primefaces.themes.redmond-${primefaces.theme.version}org.primefaces.themes.afterwork-${primefaces.theme.version}org.primefaces.themes.glass-x-${primefaces.theme.version}org.primefaces.themes.home-${primefaces.theme.version} org.primefaces.themes.black-tie-${primefaces.theme.version}org.primefaces.themes.eggplant-${primefaces.theme.version} org.apache.maven.mercury.mercury-repo-remote-m2-N/Aorg.apache.maven.mercury.mercury-md-sat-N/A org.primefaces.themes.ui-lightness-${primefaces.theme.version}org.primefaces.themes.midnight-${primefaces.theme.version}org.primefaces.themes.mint-choc-${primefaces.theme.version}org.primefaces.themes.afternoon-${primefaces.theme.version}org.primefaces.themes.dot-luv-${primefaces.theme.version}org.primefaces.themes.smoothness-${primefaces.theme.version}org.primefaces.themes.swanky-purse-${primefaces.theme.version} -

Semantic Fuzzing with Zest
Semantic Fuzzing with Zest Rohan Padhye Caroline Lemieux Koushik Sen University of California, Berkeley University of California, Berkeley University of California, Berkeley USA USA USA [email protected] [email protected] [email protected] Mike Papadakis Yves Le Traon University of Luxembourg University of Luxembourg Luxembourg Luxembourg [email protected] [email protected] ABSTRACT Syntactic Semantic Valid Input Output Programs expecting structured inputs often consist of both a syntac- Stage Stage tic analysis stage, which parses raw input, and a semantic analysis Syntactically Semantically stage, which conducts checks on the parsed input and executes Invalid Invalid the core logic of the program. Generator-based testing tools in the Syntactic Semantic lineage of QuickCheck are a promising way to generate random Error Error syntactically valid test inputs for these programs. We present Zest, a technique which automatically guides QuickCheck-like random- input generators to better explore the semantic analysis stage of test Figure 1: Inputs to a program taking structured inputs can programs. Zest converts random-input generators into determinis- be either syntactically or semantically invalid or just valid. tic parametric generators. We present the key insight that mutations in the untyped parameter domain map to structural mutations in the input domain. Zest leverages program feedback in the form 1 INTRODUCTION of code coverage and input validity to perform feedback-directed parameter search. We evaluate Zest against AFL and QuickCheck Programs expecting complex structured inputs often process their on five Java programs: Maven, Ant, BCEL, Closure, and Rhino. Zest inputs and convert them into suitable data structures before in- covers 1:03×–2:81× as many branches within the benchmarks’ se- voking the actual functionality of the program. -

Funktionaalisten Kielten Ydinpiirteiden Toteutus Oliokielten Virtuaalikonealustoilla
Funktionaalisten kielten ydinpiirteiden toteutus oliokielten virtuaalikonealustoilla Laura Leppänen Pro gradu -tutkielma HELSINGIN YLIOPISTO Tietojenkäsittelytieteen laitos Helsinki, 30. lokakuuta 2016 HELSINGIN YLIOPISTO — HELSINGFORS UNIVERSITET — UNIVERSITY OF HELSINKI Tiedekunta — Fakultet — Faculty Laitos — Institution — Department Matemaattis-luonnontieteellinen Tietojenkäsittelytieteen laitos Tekijä — Författare — Author Laura Leppänen Työn nimi — Arbetets titel — Title Funktionaalisten kielten ydinpiirteiden toteutus oliokielten virtuaalikonealustoilla Oppiaine — Läroämne — Subject Tietojenkäsittelytiede Työn laji — Arbetets art — Level Aika — Datum — Month and year Sivumäärä — Sidoantal — Number of pages Pro gradu -tutkielma 30. lokakuuta 2016 106 sivua + 25 sivua liitteissä Tiivistelmä — Referat — Abstract Tutkielma käsittelee funktionaalisille kielille tyypillisten piirteiden, ensimmäisen luo- kan funktioarvojen ja häntäkutsujen toteutusta oliokielille suunnatuilla JVM- ja .NET- virtuaalikonealustoilla. Oliokielille suunnattujen virtuaalikonealustojen tarjoamien tavukoodi- rajapintojen rajoitteet verrattuna matalamman tason assembly-kieliin ovat pitkään aiheut- taneet valtavirran oliokielistä poikkeavien kielten toteuttajille päänvaivaa. Tarkasteltavista alustoista .NET-alustan tavoitteena on alusta asti ollut monenlaisten kielten tukeminen. JVM- alustalla erilaisten kielten toteuttajien tarpeisiin on havahduttu vasta viimeisten vuosien aikana. Tutkielma tarkastelee, millaisia mahdollisuuksia alustat nykyisellään tarjoavat ensim- -

JVM Bytecode
Michael Rasmussen ZeroTurnaround Terminology Basic ASM classes Generating bytecode Transforming bytecode Bytecode in the Wild Binary names ◦ In Java source code file Uses dots to separate, e.g. java.lang.String In accordance with the JLS http://docs.oracle.com/javase/specs/jls/se7/html/jls-13.html#jls-13.1 ◦ In class file format Uses slash to separate, e.g. java/lang/String Also commonly referred to as Internal name or Internal form In accordance with the JVMS http://docs.oracle.com/javase/specs/jvms/se7/html/jvms-4.html#jvms-4.2 String representing a class’ name Fully qualified class name ◦ uses / as package separator Example: ◦ java.lang.String “java/lang/String” ◦ java.util.ArrayList “java/util/ArrayList” Internal definition of a type Primitive types ◦ Single character “J” (long), “I” (int), “S” (short), “B” (byte), “C” (char) “F" (float), “D” (double) “Z” (boolean), “V” (void) Object types ◦ Binary name enclosed by L; “Ljava/lang/String;” “Ljava/util/ArrayList;” Array types ◦ [ followed by type descriptor “[B” byte[] “[Ljava/lang/String;” String[] “[[D” double[][] Multiple [ indicates multiple dimensions Defines parameter and return types Consists of: ◦ Enclosed in parenthesis: 0 or more Type Descriptors Describing the parameters ◦ 1 Type Descriptor Describing the return type Example ◦ “(Ljava/lang/String;)I” Takes a java.lang.String as arguments Returns an int ◦ “()V” Takes zero arguments Returns nothing (void) ◦ “(DD)D” Takes two arguments of type double Returns a double Constructor ◦ Special -

At the Core of the Jvm by Anton Arhipov, Jrebel Product Lead
MASTERING JAVA BYTECODE AT THE CORE OF THE JVM BY ANTON ARHIPOV, JREBEL PRODUCT LEAD take a byte out of this code... All rights reserved. 2012 (c) ZeroTurnaround OÜ 1 INRODUCTION WHAT YOU SHOULD KNOW Whether you are a Java developer or architect, CxO or simply the user of a modern smart phone, Java bytecode is in your face, quietly supporting the foundation of the Java Virtual Machine (JVM). All rights reserved. 2012 (c) ZeroTurnaround OÜ 2 Directors, executives and non-technical folks can take a breather here: In addition to getting the skinny on Java bytecode, we interviewed bytecode All they need to know is that while their development teams are building specialists Cédric Champeau and Jochen Theodorou working on the and preparing to deploy the next amazing version of their software, Java Groovy [1] ecosystem at SpringSource, and tech lead Andrey Breslav bytecode is silently pumping through the JVM platform. working on Kotlin [2] , a newcomer to the JVM language party, from JetBrains. Put simply, Java bytecode is the intermediate representation of Java code (i.e. class files) and it is executed inside the JVM - so why should you care We will cover the following topics: about it? Well, because you cannot run your entire development ecosystem without Java bytecode telling it all what to do, especially how to treat and • How to obtain the bytecode listings define the code that Java developers are writing. • How to read the bytecode • How the language constructs are mirrored by the compiler: From a technical POV, Java bytecode is the code set used by the Java local variables, method calls, conditional logic Virtual Machine that is JIT-compiled into native code at runtime. -

Rapid Development of Extensible Profilers for the Java Virtual
Rapid Development of Extensible Profilers for the Java Virtual Machine with Aspect-Oriented Programming Danilo Ansaloni Walter Binder Alex Villazón Faculty of Informatics Faculty of Informatics Faculty of Informatics University of Lugano University of Lugano University of Lugano Switzerland Switzerland Switzerland [email protected] [email protected] [email protected] Philippe Moret Faculty of Informatics University of Lugano Switzerland [email protected] ABSTRACT 1. INTRODUCTION Many profilers for Java applications are implemented with Bytecode instrumentation techniques are widely used low-level bytecode instrumentation techniques, which is te- for profiling [9, 8, 11, 6, 14, 7]. Java supports byte- dious, error-prone, and complicates maintenance and ex- code instrumentation using native code agents through tension of the tools. In order to reduce development time the Java Virtual Machine Tool Interface (JVMTI) [18], and cost, we promote building Java profilers using high-level as well as portable bytecode instrumentation through the aspect-oriented programming (AOP). We show that the use java.lang.instrument API. Several bytecode engineering of aspects yields concise profilers that are easy to develop, libraries have been developed, such as BCEL [19] and extend, and maintain, because low-level instrumentation de- ASM [15]. However, because of the low-level nature of byte- tails are hidden from the tool developer. Our profiler re- code and of bytecode engineering libraries, it is difficult and lies on inter-advice communication, an extension to common error-prone to implement new profilers, which often requires AOP languages that enables efficient data passing between high effort for development and testing. Moreover, profilers advice woven into the same method. -

Open Source Used in Apicem Config Arch Shockwave
Open Source Used In apicem_config_arch Shockwave Cisco Systems, Inc. www.cisco.com Cisco has more than 200 offices worldwide. Addresses, phone numbers, and fax numbers are listed on the Cisco website at www.cisco.com/go/offices. Text Part Number: 78EE117C99-1166400647 Open Source Used In apicem_config_arch Shockwave 1 This document contains licenses and notices for open source software used in this product. With respect to the free/open source software listed in this document, if you have any questions or wish to receive a copy of any source code to which you may be entitled under the applicable free/open source license(s) (such as the GNU Lesser/General Public License), please contact us at [email protected]. In your requests please include the following reference number 78EE117C99-1166400647 Contents 1.1 spring-web 4.3.19.RELEASE 1.1.1 Available under license 1.2 log4j-over-slf4j 1.7.21 1.2.1 Available under license 1.3 bson4jackson 2.7.0 1.3.1 Available under license 1.4 asm 4.0 1.4.1 Available under license 1.5 icu4j 63.1 1.5.1 Available under license 1.6 jax-ws-api 2.3.0 1.6.1 Available under license 1.7 jetty-http 9.3.27.v20190418 1.7.1 Available under license 1.8 shiro-cache 1.6.0 1.8.1 Available under license 1.9 spring-jms 4.3.19.RELEASE 1.9.1 Available under license 1.10 jtoml 1.0.0 1.11 jackson-jaxrs-xml-provider 2.9.10 1.11.1 Available under license 1.12 easymock 3.1 1.12.1 Available under license 1.13 shiro-config-ogdl 1.6.0 1.13.1 Available under license 1.14 snake-yaml 1.15 Open Source Used In apicem_config_arch -

Bism: Bytecode-Level Instrumentation for Software Monitoring
BISM: BYTECODE-LEVEL INSTRUMENTATION FOR SOFTWARE MONITORING APREPRINT Chukri Soueidi Ali Kassem Ylies` Falcone Univ. Grenoble Alpes, Inria, Univ. Grenoble Alpes, Inria, Univ. Grenoble Alpes, Inria, CNRS, Grenoble INP, LIG CNRS, Grenoble INP, LIG CNRS, Grenoble INP, LIG 38000 Grenoble 38000 Grenoble 38000 Grenoble France France France [email protected] [email protected] [email protected] July 16, 2020 ABSTRACT BISM (Bytecode-Level Instrumentation for Software Monitoring) is a lightweight bytecode instru- mentation tool that features an expressive high-level control-flow-aware instrumentation language. The language follows the aspect-oriented programming paradigm by adopting the joinpoint model, advice inlining, and separate instrumentation mechanisms. BISM provides joinpoints ranging from bytecode instruction to method execution, access to comprehensive static and dynamic context in- formation, and instrumentation methods. BISM runs in two instrumentation modes: build-time and load-time. We demonstrate BISM effectiveness using two experiments: a security scenario and a general runtime verification case. The results show that BISM instrumentation incurs low runtime and memory overheads. Keywords Bytecode Instrumentation · Control Flow · Aspect-Oriented Programming · Static and Dynamic Contexts. 1 Introduction Instrumentation is essential to the software monitoring workflow [1]. Instrumentation allows extracting information from a running software to abstract the execution into a trace fed to a monitor. Depending on the information needed by the monitor, the granularity level of the extracted information may range from coarse (e.g., a function call) to fine (e.g., an assignment to a local variable, a jump in the control flow). arXiv:2007.03936v2 [cs.PL] 15 Jul 2020 For software instrumentation, aspect-oriented programming (AOP) [2] is a popular and convenient paradigm where instrumentation is a cross-cutting concern. -

Slides Revision: 20190923-Ea7c311
Will it blend? Java agents and OSGi Slides revision: 20190923-ea7c311 1 Welcome 2 About me 3 Outline Quick demo Java agents primer Usage scenarios OSGi integration Integration testing Testing demo 4 Quick demo 5 Java agents primer 6 Java instrumentation APIs Provides services that allow Java programming language agents to instrument programs running on the JVM. java.lang.instrument Javadoc, Java SE 8 7 Static agents # loaded at application startup $ java -javaagent:agent.jar -jar app.jar Premain-Class: org.example.my.Agent import java.lang.instrument.*; public class Agent { public static void premain(String args,⏎ Instrumentation inst) { inst.addTransformer(new ClassFileTransformer() { /* implementation elided */ }); } } 8 Dynamic agents // dynamically attached to a running JVM VirtualMachine vm = VirtualMachine.attach(vmPid); vm.loadAgent(agentFilePath); vm.detach(); Agent-Class: org.example.my.Agent import java.lang.instrument.*; public class Agent { public static void agentmain(String args,⏎ Instrumentation inst) { inst.addTransformer(new ClassFileTransformer() { /* implementation elided */ }); } } 9 Class transformation public interface ClassFileTransformer { byte[] transform(ClassLoader loader, String className, Class<?> classBeingRedefined, ProtectionDomain protectionDomain, byte[] classfileBuffer) throws IllegalClassFormatException; } 10 Java bytecode public static void main(java.lang.String[]); Code: 0: getstatic #16⏎ // Field java/lang/System.out:Ljava/io/PrintStream; 3: ldc #22⏎ // String Hello, world 5: invokevirtual #24⏎ // -

Type-Safe Java Bytecode Modification Library Based on Javassist
TALLINN UNIVERSITY OF TECHNOLOGY Faculty of Information Technology Institute of Computer Science Chair of Theoretical Informatics Type-safe Java bytecode modification library based on Javassist Bachelor thesis Student: Sven Laanela Student code: IAPB020471 Advisor: Pavel Grigorenko Tallinn 2015 I declare that this thesis is the result of my own research except as cited in the references. The thesis has not been accepted for any degree and is not concurrently submitted in candidature of any other degree. Signature Name Sven Laanela Date May 26, 2015 Abstract Dynamic (runtime) Java bytecode modification enables various fra- meworks to greatly enhance Java programs. They can provide logging, caching, dependency injection, object-relational mapping, etc. with- out cluttering the application source code, or even when the source code is not available. Existing Java bytecode modification libraries do not provide compile-time type safety or IDE-assisted code completion capabilities with regard to the class under modification. This thesis researches a problem of type-safe Java bytecode modification, build- ing on top of Javassist { a Java bytecode modification library { and taking into consideration the most common Java bytecode modifica- tion use-cases. Scenarios implemented in Javassist are described and an alternative approach that implements those scenarios in a type-safe manner is proposed. An implementation library is presented as proof of concept for the proposed approach to Java bytecode modification. An analysis of the applicability of the approach is provided, outlining both the benefits and trade-offs when compared to Javassist. Annotatsioon D¨unaamiline(s.t. rakenduse t¨o¨otamiseaegne) Java baitkoodi muut- mine v~oimaldaboluliselt t¨aiendadaJava rakendusi ilma l¨ahtekoodi ris- ustamata.