Semantic Fuzzing with Zest
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Processing an Intermediate Representation Written in Lisp
Processing an Intermediate Representation Written in Lisp Ricardo Pena,˜ Santiago Saavedra, Jaime Sanchez-Hern´ andez´ Complutense University of Madrid, Spain∗ [email protected],[email protected],[email protected] In the context of designing the verification platform CAVI-ART, we arrived to the need of deciding a textual format for our intermediate representation of programs. After considering several options, we finally decided to use S-expressions for that textual representation, and Common Lisp for processing it in order to obtain the verification conditions. In this paper, we discuss the benefits of this decision. S-expressions are homoiconic, i.e. they can be both considered as data and as code. We exploit this duality, and extensively use the facilities of the Common Lisp environment to make different processing with these textual representations. In particular, using a common compilation scheme we show that program execution, and verification condition generation, can be seen as two instantiations of the same generic process. 1 Introduction Building a verification platform such as CAVI-ART [7] is a challenging endeavour from many points of view. Some of the tasks require intensive research which can make advance the state of the art, as it is for instance the case of automatic invariant synthesis. Some others are not so challenging, but require a lot of pondering and discussion before arriving at a decision, in order to ensure that all the requirements have been taken into account. A bad or a too quick decision may have a profound influence in the rest of the activities, by doing them either more difficult, or longer, or more inefficient. -

Actors at Work Issue Date: 2016-12-15 Actors at Work Behrooz Nobakht
Cover Page The handle http://hdl.handle.net/1887/45620 holds various files of this Leiden University dissertation Author: Nobakht, Behrooz Title: Actors at work Issue Date: 2016-12-15 actors at work behrooz nobakht 2016 Leiden University Faculty of Science Leiden Institute of Advanced Computer Science Actors at Work Actors at Work Behrooz Nobakht ACTORS AT WORK PROEFSCHRIFT ter verkrijging van de graad van doctor aan de Universiteit Leiden op gezag van de Rector Magnificus prof. dr. C. J. J. M. Stolker, volgens besluit van het College voor Promoties te verdedigen op donderdag 15 december 2016 klokke 11.15 uur door Behrooz Nobakht geboren te Tehran, Iran, in 1981 Promotion Committee Promotor: Prof. Dr. F.S. de Boer Co-promotor: Dr. C. P. T. de Gouw Other members: Prof. Dr. F. Arbab Dr. M.M. Bonsangue Prof. Dr. E. B. Johnsen University of Oslo, Norway Prof. Dr. M. Sirjani Reykjavik University, Iceland The work reported in this thesis has been carried out at the Center for Mathematics and Computer Science (CWI) in Amsterdam and Leiden Institute of Advanced Computer Science at Leiden University. This research was supported by the European FP7-231620 project ENVISAGE on Engineering Virtualized Resources. Copyright © 2016 by Behrooz Nobakht. All rights reserved. October, 2016 Behrooz Nobakht Actors at Work Actors at Work, October, 2016 ISBN: 978-94-028-0436-2 Promotor: Prof. Dr. Frank S. de Boer Cover Design: Ehsan Khakbaz <[email protected]> Built on 2016-11-02 17:00:24 +0100 from 397717ec11adfadec33e150b0264b0df83bdf37d at https://github.com/nobeh/thesis using: This is pdfTeX, Version 3.14159265-2.6-1.40.16 (TeX Live 2015/Debian) kpathsea version 6.2.1 Leiden University Leiden Institute of Advanced Computer Science Faculty of Science Niels Bohrweg 1 2333 CA and Leiden Contents I Introduction1 1 Introduction 3 1.1 Objectives and Architecture . -

Rubicon: Bounded Verification of Web Applications
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by DSpace@MIT Rubicon: Bounded Verification of Web Applications Joseph P. Near, Daniel Jackson Computer Science and Artificial Intelligence Lab Massachusetts Institute of Technology Cambridge, MA, USA {jnear,dnj}@csail.mit.edu ABSTRACT ification language is an extension of the Ruby-based RSpec We present Rubicon, an application of lightweight formal domain-specific language for testing [7]; Rubicon adds the methods to web programming. Rubicon provides an embed- quantifiers of first-order logic, allowing programmers to re- ded domain-specific language for writing formal specifica- place RSpec tests over a set of mock objects with general tions of web applications and performs automatic bounded specifications over all objects. This compatibility with the checking that those specifications hold. Rubicon's language existing RSpec language makes it easy for programmers al- is based on the RSpec testing framework, and is designed to ready familiar with testing to write specifications, and to be both powerful and familiar to programmers experienced convert existing RSpec tests into specifications. in testing. Rubicon's analysis leverages the standard Ruby interpreter to perform symbolic execution, generating veri- Rubicon's automated analysis comprises two parts: first, fication conditions that Rubicon discharges using the Alloy Rubicon generates verification conditions based on specifica- Analyzer. We have tested Rubicon's scalability on five real- tions; second, Rubicon invokes a constraint solver to check world applications, and found a previously unknown secu- those conditions. The Rubicon library modifies the envi- rity bug in Fat Free CRM, a popular customer relationship ronment so that executing a specification performs symbolic management system. -

HOL-Testgen Version 1.8 USER GUIDE
HOL-TestGen Version 1.8 USER GUIDE Achim Brucker, Lukas Brügger, Abderrahmane Feliachi, Chantal Keller, Matthias Krieger, Delphine Longuet, Yakoub Nemouchi, Frédéric Tuong, Burkhart Wolff To cite this version: Achim Brucker, Lukas Brügger, Abderrahmane Feliachi, Chantal Keller, Matthias Krieger, et al.. HOL-TestGen Version 1.8 USER GUIDE. [Technical Report] Univeristé Paris-Saclay; LRI - CNRS, University Paris-Sud. 2016. hal-01765526 HAL Id: hal-01765526 https://hal.inria.fr/hal-01765526 Submitted on 12 Apr 2018 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. R L R I A P P O R HOL-TestGen Version 1.8 USER GUIDE T BRUCKER A D / BRUGGER L / FELIACHI A / KELLER C / KRIEGER M P / LONGUET D / NEMOUCHI Y / TUONG F / WOLFF B D Unité Mixte de Recherche 8623 E CNRS-Université Paris Sud-LRI 04/2016 R Rapport de Recherche N° 1586 E C H E R C CNRS – Université de Paris Sud H Centre d’Orsay LABORATOIRE DE RECHERCHE EN INFORMATIQUE E Bâtiment 650 91405 ORSAY Cedex (France) HOL-TestGen 1.8.0 User Guide http://www.brucker.ch/projects/hol-testgen/ Achim D. Brucker Lukas Brügger Abderrahmane Feliachi Chantal Keller Matthias P. -

Exploring Languages with Interpreters and Functional Programming Chapter 11
Exploring Languages with Interpreters and Functional Programming Chapter 11 H. Conrad Cunningham 24 January 2019 Contents 11 Software Testing Concepts 2 11.1 Chapter Introduction . .2 11.2 Software Requirements Specification . .2 11.3 What is Software Testing? . .3 11.4 Goals of Testing . .3 11.5 Dimensions of Testing . .3 11.5.1 Testing levels . .4 11.5.2 Testing methods . .6 11.5.2.1 Black-box testing . .6 11.5.2.2 White-box testing . .8 11.5.2.3 Gray-box testing . .9 11.5.2.4 Ad hoc testing . .9 11.5.3 Testing types . .9 11.5.4 Combining levels, methods, and types . 10 11.6 Aside: Test-Driven Development . 10 11.7 Principles for Test Automation . 12 11.8 What Next? . 15 11.9 Exercises . 15 11.10Acknowledgements . 15 11.11References . 16 11.12Terms and Concepts . 17 Copyright (C) 2018, H. Conrad Cunningham Professor of Computer and Information Science University of Mississippi 211 Weir Hall P.O. Box 1848 University, MS 38677 1 (662) 915-5358 Browser Advisory: The HTML version of this textbook requires a browser that supports the display of MathML. A good choice as of October 2018 is a recent version of Firefox from Mozilla. 2 11 Software Testing Concepts 11.1 Chapter Introduction The goal of this chapter is to survey the important concepts, terminology, and techniques of software testing in general. The next chapter illustrates these techniques by manually constructing test scripts for Haskell functions and modules. 11.2 Software Requirements Specification The purpose of a software development project is to meet particular needs and expectations of the project’s stakeholders. -

Beginner's Luck
Beginner’s Luck A Language for Property-Based Generators Leonidas Lampropoulos1 Diane Gallois-Wong2,3 Cat˘ alin˘ Hrit¸cu2 John Hughes4 Benjamin C. Pierce1 Li-yao Xia2,3 1University of Pennsylvania, USA 2INRIA Paris, France 3ENS Paris, France 4Chalmers University, Sweden Abstract An appealing feature of QuickCheck is that it offers a library Property-based random testing a` la QuickCheck requires build- of property combinators resembling standard logical operators. For ing efficient generators for well-distributed random data satisfying example, a property of the form p ==> q, built using the impli- complex logical predicates, but writing these generators can be dif- cation combinator ==>, will be tested automatically by generating ficult and error prone. We propose a domain-specific language in valuations (assignments of random values, of appropriate type, to which generators are conveniently expressed by decorating pred- the free variables of p and q), discarding those valuations that fail icates with lightweight annotations to control both the distribu- to satisfy p, and checking whether any of the ones that remain are tion of generated values and the amount of constraint solving that counterexamples to q. happens before each variable is instantiated. This language, called QuickCheck users soon learn that this default generate-and-test Luck, makes generators easier to write, read, and maintain. approach sometimes does not give satisfactory results. In particular, We give Luck a formal semantics and prove several fundamen- if the precondition p is satisfied by relatively few values of the ap- tal properties, including the soundness and completeness of random propriate type, then most of the random inputs that QuickCheck generation with respect to a standard predicate semantics. -

Java Optimizations Using Bytecode Templates
FACULDADE DE ENGENHARIA DA UNIVERSIDADE DO PORTO Java Optimizations Using Bytecode Templates Rubén Ramos Horta Mestrado Integrado em Engenharia Informática e Computação Supervisor: Professor Doutor João Manuel Paiva Cardoso July 28, 2016 c Rubén Ramos Horta, 2016 Java Optimizations Using Bytecode Templates Rubén Ramos Horta Mestrado Integrado em Engenharia Informática e Computação July 28, 2016 Resumo Aplicações móveis e embebidas funcionam em ambientes com poucos recursos e que estão sujeitos a constantes mudanças no seu contexto operacional. Estas características dificultam o desenvolvi- mento deste tipo de aplicações pois a volatilidade e as limitações de recursos levam muitas vezes a uma diminuição do rendimento e a um potencial aumento do custo computacional. Além disso, as aplicações que têm como alvo ambientes móveis e embebidos (por exemplo, Android) necessitam de adaptações e otimizações para fiabilidade, manutenção, disponibilidade, segurança, execução em tempo real, tamanho de código, eficiência de execução e também consumo de energia. Esta dissertação foca-se na otimização, em tempo de execução, de programas Java, com base na aplicação de otimizações de código baseadas na geração de bytecodes em tempo de execução, usando templates. Estes templates, fornecem geração de bytecodes usando informação apenas disponível em tempo de execução. Este artigo propõe uma estratégia para o desenvolvimento desses templates e estuda o seu impacto em diferentes plataformas. i ii Resumen Las aplicaciones móviles y embedded trabajan en entornos limitados de recursos y están sujetas a constantes cambios de escenario. Este tipo de características desafían el desarrollo de este tipo de aplicaciones en términos de volatibilidad y limitación de recursos que acostumbran a afec- tar al rendimiento y también producen un incremento significativo en el coste computacional. -

Quickcheck Tutorial
QuickCheck Tutorial Thomas Arts John Hughes Quviq AB Queues Erlang contains a queue data structure (see stdlib documentation) We want to test that these queues behave as expected What is “expected” behaviour? We have a mental model of queues that the software should conform to. Erlang Exchange 2008 © Quviq AB 2 Queue Mental model of a fifo queue …… first last …… Remove from head Insert at tail / rear Erlang Exchange 2008 © Quviq AB 3 Queue Traditional test cases could look like: We want to check for arbitrary elements that Q0 = queue:new(), if we add an element, Q1 = queue:cons(1,Q0), it's there. 1 = queue:last(Q1). Q0 = queue:new(), We want to check for Q1 = queue:cons(8,Q0), arbitrary queues that last added element is Q2 = queue:cons(0,Q1), "last" 0 = queue:last(Q2), Property is like an abstraction of a test case Erlang Exchange 2008 © Quviq AB 4 QuickCheck property We want to know that for any element, when we add it, it's there prop_itsthere() -> ?FORALL(I,int(), I == queue:last( queue:cons(I, queue:new()))). Erlang Exchange 2008 © Quviq AB 5 QuickCheck property We want to know that for any element, when we add it, it's there prop_itsthere() -> ?FORALL(I,int(), I == queue:last( queue:cons(I, queue:new()))). This is a property Test cases are generasted from such properties Erlang Exchange 2008 © Quviq AB 6 QuickCheck property We want to know that for any element, when we add it, it's there int() is a generator for random integers prop_itsthere() -> ?FORALL(I,int(), I == queue:last( queue:cons(I, I represents one queue:new()))). -

Branching Processes for Quickcheck Generators (Extended Version)
Branching Processes for QuickCheck Generators (extended version) Agustín Mista Alejandro Russo John Hughes Universidad Nacional de Rosario Chalmers University of Technology Chalmers University of Technology Rosario, Argentina Gothenburg, Sweden Gothenburg, Sweden [email protected] [email protected] [email protected] Abstract random test data generators or QuickCheck generators for short. In QuickCheck (or, more generally, random testing), it is chal- The generation of test cases is guided by the types involved in lenging to control random data generators’ distributions— the testing properties. It defines default generators for many specially when it comes to user-defined algebraic data types built-in types like booleans, integers, and lists. However, when (ADT). In this paper, we adapt results from an area of mathe- it comes to user-defined ADTs, developers are usually required matics known as branching processes, and show how they help to specify the generation process. The difficulty is, however, to analytically predict (at compile-time) the expected number that it might become intricate to define generators so that they of generated constructors, even in the presence of mutually result in a suitable distribution or enforce data invariants. recursive or composite ADTs. Using our probabilistic formu- The state-of-the-art tools to derive generators for user- las, we design heuristics capable of automatically adjusting defined ADTs can be classified based on the automation level probabilities in order to synthesize generators which distribu- as well as the sort of invariants enforced at the data genera- tions are aligned with users’ demands. We provide a Haskell tion phase. QuickCheck and SmallCheck [27] (a tool for writing implementation of our mechanism in a tool called generators that synthesize small test cases) use type-driven and perform case studies with real-world applications. -
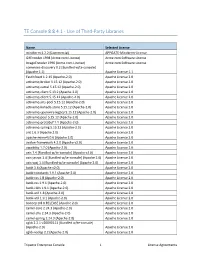
TE Console 8.8.4.1 - Use of Third-Party Libraries
TE Console 8.8.4.1 - Use of Third-Party Libraries Name Selected License mindterm 4.2.2 (Commercial) APPGATE-Mindterm-License GifEncoder 1998 (Acme.com License) Acme.com Software License ImageEncoder 1996 (Acme.com License) Acme.com Software License commons-discovery 0.2 [Bundled w/te-console] (Apache 1.1) Apache License 1.1 FastInfoset 1.2.15 (Apache-2.0) Apache License 2.0 activemQ-broker 5.15.12 (Apache-2.0) Apache License 2.0 activemQ-camel 5.15.12 (Apache-2.0) Apache License 2.0 activemQ-client 5.13.2 (Apache-2.0) Apache License 2.0 activemQ-client 5.15.12 (Apache-2.0) Apache License 2.0 activemQ-jms-pool 5.15.12 (Apache-2.0) Apache License 2.0 activemQ-kahadb-store 5.15.12 (Apache-2.0) Apache License 2.0 activemQ-openwire-legacy 5.15.12 (Apache-2.0) Apache License 2.0 activemQ-pool 5.15.12 (Apache-2.0) Apache License 2.0 activemQ-protobuf 1.1 (Apache-2.0) Apache License 2.0 activemQ-spring 5.15.12 (Apache-2.0) Apache License 2.0 ant 1.6.3 (Apache 2.0) Apache License 2.0 apache-mime4j 0.6 (Apache 2.0) Apache License 2.0 avalon-framework 4.2.0 (Apache v2.0) Apache License 2.0 awaitility 1.7.0 (Apache-2.0) Apache License 2.0 axis 1.4 [Bundled w/te-console] (Apache v2.0) Apache License 2.0 axis-jaxrpc 1.4 [Bundled w/te-console] (Apache 2.0) Apache License 2.0 axis-saaj 1.4 [Bundled w/te-console] (Apache 2.0) Apache License 2.0 batik 1.6 (Apache v2.0) Apache License 2.0 batik-constants 1.9.1 (Apache-2.0) Apache License 2.0 batik-css 1.8 (Apache-2.0) Apache License 2.0 batik-css 1.9.1 (Apache-2.0) Apache License 2.0 batik-i18n 1.9.1 (Apache-2.0) -

Foundational Property-Based Testing
Foundational Property-Based Testing Zoe Paraskevopoulou1,2 Cat˘ alin˘ Hrit¸cu1 Maxime Den´ es` 1 Leonidas Lampropoulos3 Benjamin C. Pierce3 1Inria Paris-Rocquencourt 2ENS Cachan 3University of Pennsylvania Abstract Integrating property-based testing with a proof assistant creates an interesting opportunity: reusable or tricky testing code can be formally verified using the proof assistant itself. In this work we introduce a novel methodology for formally verified property-based testing and implement it as a foundational verification framework for QuickChick, a port of QuickCheck to Coq. Our frame- work enables one to verify that the executable testing code is testing the right Coq property. To make verification tractable, we provide a systematic way for reasoning about the set of outcomes a random data generator can produce with non-zero probability, while abstracting away from the actual probabilities. Our framework is firmly grounded in a fully verified implementation of QuickChick itself, using the same underlying verification methodology. We also apply this methodology to a complex case study on testing an information-flow control abstract machine, demonstrating that our verification methodology is modular and scalable and that it requires minimal changes to existing code. 1 Introduction Property-based testing (PBT) allows programmers to capture informal conjectures about their code as executable specifications and to thoroughly test these conjectures on a large number of inputs, usually randomly generated. When a counterexample is found it is shrunk to a minimal one, which is displayed to the programmer. The original Haskell QuickCheck [19], the first popular PBT tool, has inspired ports to every mainstream programming language and led to a growing body of continuing research [6,18,26,35,39] and industrial interest [2,33]. -

Full-Graph-Limited-Mvn-Deps.Pdf
org.jboss.cl.jboss-cl-2.0.9.GA org.jboss.cl.jboss-cl-parent-2.2.1.GA org.jboss.cl.jboss-classloader-N/A org.jboss.cl.jboss-classloading-vfs-N/A org.jboss.cl.jboss-classloading-N/A org.primefaces.extensions.master-pom-1.0.0 org.sonatype.mercury.mercury-mp3-1.0-alpha-1 org.primefaces.themes.overcast-${primefaces.theme.version} org.primefaces.themes.dark-hive-${primefaces.theme.version}org.primefaces.themes.humanity-${primefaces.theme.version}org.primefaces.themes.le-frog-${primefaces.theme.version} org.primefaces.themes.south-street-${primefaces.theme.version}org.primefaces.themes.sunny-${primefaces.theme.version}org.primefaces.themes.hot-sneaks-${primefaces.theme.version}org.primefaces.themes.cupertino-${primefaces.theme.version} org.primefaces.themes.trontastic-${primefaces.theme.version}org.primefaces.themes.excite-bike-${primefaces.theme.version} org.apache.maven.mercury.mercury-external-N/A org.primefaces.themes.redmond-${primefaces.theme.version}org.primefaces.themes.afterwork-${primefaces.theme.version}org.primefaces.themes.glass-x-${primefaces.theme.version}org.primefaces.themes.home-${primefaces.theme.version} org.primefaces.themes.black-tie-${primefaces.theme.version}org.primefaces.themes.eggplant-${primefaces.theme.version} org.apache.maven.mercury.mercury-repo-remote-m2-N/Aorg.apache.maven.mercury.mercury-md-sat-N/A org.primefaces.themes.ui-lightness-${primefaces.theme.version}org.primefaces.themes.midnight-${primefaces.theme.version}org.primefaces.themes.mint-choc-${primefaces.theme.version}org.primefaces.themes.afternoon-${primefaces.theme.version}org.primefaces.themes.dot-luv-${primefaces.theme.version}org.primefaces.themes.smoothness-${primefaces.theme.version}org.primefaces.themes.swanky-purse-${primefaces.theme.version}