Assigning Creative Commons Licenses to Research Metadata: Issues and Cases
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Réseaux Sociaux Et Visibilité Du Chercheur
ACADEMIA, RESEARCHGATE... A. Bouchard (URFIST de Paris) LAAS RÉSEAUX SOCIAUX ACADÉMIQUES Toulouse, 09/06/2015 ET VISIBILITÉ DU CHERCHEUR PLAN Repères Présentation de quelques outils Réseaux sociaux et visibilité du chercheur Publication scientifique et réseaux sociaux Enjeux académiques présents et à venir PLAN Repères Présentation de quelques outils Réseaux sociaux et visibilité du chercheur Publication scientifique et réseaux sociaux Enjeux académiques présents et à venir RÉSEAUX SOCIAUX ? ÉTAT DES LIEUX - MONDE ACADÉMIQUE, FRANCE étude Arces, 2013 étude Wanacôme, 2012 ÉTAT DES LIEUX - MONDE ACADÉMIQUE, FRANCE Profil Twitter Profil Facebook ÉTAT DES LIEUX - MONDE ACADÉMIQUE, FRANCE études URFIST de Nice, 2011 et Couperin, 2014 ÉTAT DES LIEUX - MONDE ACADÉMIQUE, MONDE étude Nature, 2014 ÉTAT DES LIEUX A. Gruzd et al., 2012 PLAN Repères Présentation de quelques outils Réseaux sociaux et visibilité du chercheur Publication scientifique et réseaux sociaux Enjeux académiques présents et à venir RÉSEAUX SOCIAUX PROFESSIONNELS RÉSEAUX SOCIAUX PROFESSIONNELS - USAGES ex. : LinkedIn 1 2 3 étude Nature, 2014 RÉSEAUX SOCIAUX ACADÉMIQUES RÉSEAUX SOCIAUX ACADÉMIQUES Profil Academia Profil ResearchGate Chistophe Benech RÉSEAUX SOCIAUX ACADÉMIQUES - USAGES ex. : ResearchGate 1 3 2 étude Nature, 2014 TWITTER - USAGES 1 D. Lupton, 2014 2 3 étude Nature, 2014 PLAN Repères Présentation de quelques outils Réseaux sociaux et visibilité du chercheur Publication scientifique et réseaux sociaux Enjeux académiques présents et à venir ÊTRE VISIBLE - POURQUOI requête Google ? ? ? ÊTRE VISIBLE - POURQUOI requête Google Scholar ÊTRE VISIBLE - POURQUOI Page d’annuaire Page de Post-doc ÊTRE VISIBLE - COMMENT Profil ResearchGate EXEMPLE DE CAS FAIRE SON AUTOPROMOTION Ex. : ResearchGate EXEMPLE DE CAS S’INSCRIRE DANS UNE COMMUNAUTÉ Ex. : ResearchGate Ex. -

Editorialising” Open Access Scientific Journals
Critical study of the new ways of “editorialising” open access scientific journals Synthesised report of the study piloted by BSN 4 and BSN 7 Produced by Pierre-Carl Langlais (June 2016) Steering committee: Serge Bauin, Emmanuelle Corne, Jacques Lafait, Pierre Mounier Introduction As this report goes to press, France has just adopted an open access law. Article 30 of the “Law for a Digital Republic” provides that the authors of scientific texts whose work is at least 50% publicly funded may “make [it] freely available in an open format, through digital means” after a period of restricted access (known as an “embargo” period) lasting no longer than six months in the technical and medical sciences, and twelve months in the humanities and social sciences. In September 2016, this measure was definitively approved by the National Assembly and the Senate. It aims to remove one of the main restrictions limiting the dissemination of scientific publications on digital networks: the need to obtain the publisher‟s authorisation. The exclusivity clauses typically included in publishing contracts potentially prevent authors from re-disseminating their scientific contributions (for example, in an institutional repository) or else apply varying restrictions.1 These complex arrangements do not facilitate the implementation of a coherent open access policy, neither for authors (who must adopt a radically distinct republication strategy, depending on the publisher) nor for readers. The embedding of open access in the law creates a minimum harmonised framework capable of simplifying the conditions attached to accessing publicly funded research. The French law builds on a European, indeed global, movement. -

Visibilidad E Impacto Altmétrico De Los Investigadores De La Universidad De Antioquia: Metodología Aplicable a Universidades
SEÇÃO TEMÁTICA: ALTMÉTRICAS E CIÊNCIA ABERTA NA AMÉRICA LATINA LATINA NA AMÉRICA E CIÊNCIA ABERTA ALTMÉTRICAS TEMÁTICA: SEÇÃO 1 Visibilidad e impacto altmétrico de los investigadores ALTMETRICS de la Universidad de Antioquia: metodología DE LOS INVESTIGADORES DE LA UDEA DE LOS aplicable a universidades Visibility and altmetric impact of the University of Antioquia researchers: Methodology applicable to universities Alejandro URIBE-TIRADO1 0000-0002-0381-1269 Jaider OCHOA-GUTIÉRREZ1 0000-0002-5492-3922 Kelis RUIZ-NUÑEZ1 0000-0002-5168-1737 Marcela FAJARDO-BERMÚDEZ1 0000-0001-5885-4429 Resumen SESSION THEMATIC Este trabajo es resultado de uno de los componentes de una investigación macro que busca crear un Modelo para identifi car el grado de vinculación de una universidad con su entorno, en este caso, aplicado a la Universidad de Antioquia (Medellín-Colombia). Este componente se refi ere a la visibilidad e impacto de los investigadores desde la perspectiva y datos que ofrecen las altmetrics. Para ello, se analizan los datos altmétricos de 1.032 investigadores de seis áreas del conocimiento, considerando diferentes plataformas académicas, profesionales y sociales, además de una plataforma integradora de indicadores altmétricos. Aunque se realiza esta medición para investigadores de la Universidad de Antioquia, la metodología general para la captura e interpretación AMERICA AND OPEN SCIENCE IN LATIN ALTMETRICS de datos puede aplicarse a otras universidades que comparten características de investigación y de comunicación científi ca : y que, a partir de las altmetrics, desean identifi car la visibilidad e impacto de sus investigadores y la vinculación misma de la institución con su entorno, para complementar, de esta manera, las mediciones bibliométricas tradicionales u otras mediciones del entorno de la universidad, como lo considera, por ejemplo, el Manual de Valencia. -

ERC Document on Open Research Data and Data Management Plans
Open Research Data and Data Management Plans Information for ERC grantees by the ERC Scientific Council Version 4.0 11 August 2021 This document is regularly updated in order to take into account new developments in this rapidly evolving field. Comments, corrections and suggestions should be sent to the Secretariat of the ERC Scientific Council Working Group on Open Science via the address [email protected]. The table below summarizes the main changes that this document has undergone. HISTORY OF CHANGES Version Publication Main changes Page (in the date relevant version) 1.0 23.02.2018 Initial version 2.0 24.04.2018 Part ‘Open research data and data deposition in the 15-17 Physical Sciences and Engineering domain’ added Minor editorial changes; faulty link corrected 6, 10 Contact address added 2 3.0 23.04.2019 Name of WG updated 2 Added text to the section on ‘Data deposition’ 5 Reference to FAIRsharing moved to the general part 7 from the Life Sciences part and extended Added example of the Austrian Science Fund in the 8 section on ‘Policies of other funding organisations’; updated links related to the German Research Foundation and the Arts and Humanities Research Council; added reference to the Science Europe guide Small changes to the text on ‘Image data’ 9 Added reference to the Ocean Biogeographic 10 Information (OBIS) Reformulation of the text related to Biostudies 11 New text in the section on ‘Metadata’ in the Life 11 Sciences part Added reference to openICPSR 13 Added references to ioChem-BD and ChemSpider -

Open Science Toolbox
Open Science Toolbox A Collection of Resources to Facilitate Open Science Practices Lutz Heil [email protected] LMU Open Science Center April 14, 2018 [last edit: July 10, 2019] Contents Preface 2 1 Getting Started 3 2 Resources for Researchers 4 2.1 Plan your Study ................................. 4 2.2 Conduct your Study ............................... 6 2.3 Analyse your Data ................................ 7 2.4 Publish your Data, Material, and Paper .................... 10 3 Resources for Teaching 13 4 Key Papers 16 5 Community 18 1 Preface The motivation to engage in a more transparent research and the actual implementation of Open Science practices into the research workflow can be two very distinct things. Work on the motivational side has been successfully done in various contexts (see section Key Papers). Here the focus rather lays on closing the intention-action gap. Providing an overview of handy Open Science tools and resources might facilitate the implementation of these practices and thereby foster Open Science on a practical level rather than on a theoretical. So far, there is a vast body of helpful tools that can be used in order to foster Open Science practices. Without doubt, all of these tools add value to a more transparent research. But for reasons of clarity and to save time which would be consumed by trawling through the web, this toolbox aims at providing only a selection of links to these resources and tools. Our goal is to give a short overview on possibilities of how to enhance your Open Science practices without consuming too much of your time. -

A Digital Mapping of Climate Diplomacy Tommaso Venturini, Nicolas Baya-Laffite, Jean-Philippe Cointet, Ian Gray, Vinciane Zabban, Kari De Pryck
Three maps and three misunderstandings: A digital mapping of climate diplomacy Tommaso Venturini, Nicolas Baya-Laffite, Jean-Philippe Cointet, Ian Gray, Vinciane Zabban, Kari de Pryck To cite this version: Tommaso Venturini, Nicolas Baya-Laffite, Jean-Philippe Cointet, Ian Gray, Vinciane Zabban, et al.. Three maps and three misunderstandings: A digital mapping of climate diplomacy. Big Data & Society, SAGE, 2014, 1 (2), pp.1-19. 10.1177/2053951714543804. hal-01672306 HAL Id: hal-01672306 https://hal.archives-ouvertes.fr/hal-01672306 Submitted on 23 Dec 2017 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Big Data & Society http://bds.sagepub.com/ Three maps and three misunderstandings: A digital mapping of climate diplomacy Tommaso Venturini, Nicolas Baya Laffite, Jean-Philippe Cointet, Ian Gray, Vinciane Zabban and Kari De Pryck Big Data & Society 2014 1: DOI: 10.1177/2053951714543804 The online version of this article can be found at: http://bds.sagepub.com/content/1/2/2053951714543804 Published by: http://www.sagepublications.com On behalf of: Additional -

Assessing the Impact and Quality of Research Data Using Altmetrics and Other Indicators
Konkiel, S. (2020). Assessing the Impact and Quality of Research Data Using Altmetrics and Other Indicators. Scholarly Assessment Reports, 2(1): 13. DOI: https://doi.org/10.29024/sar.13 COMMISSIONED REPORT Assessing the Impact and Quality of Research Data Using Altmetrics and Other Indicators Stacy Konkiel Altmetric, US [email protected] Research data in all its diversity—instrument readouts, observations, images, texts, video and audio files, and so on—is the basis for most advancement in the sciences. Yet the assessment of most research pro- grammes happens at the publication level, and data has yet to be treated like a first-class research object. How can and should the research community use indicators to understand the quality and many poten- tial impacts of research data? In this article, we discuss the research into research data metrics, these metrics’ strengths and limitations with regard to formal evaluation practices, and the possible meanings of such indicators. We acknowledge the dearth of guidance for using altmetrics and other indicators when assessing the impact and quality of research data, and suggest heuristics for policymakers and evaluators interested in doing so, in the absence of formal governmental or disciplinary policies. Policy highlights • Research data is an important building block of scientific production, but efforts to develop a framework for assessing data’s impacts have had limited success to date. • Indicators like citations, altmetrics, usage statistics, and reuse metrics highlight the influence of research data upon other researchers and the public, to varying degrees. • In the absence of a shared definition of “quality”, varying metrics may be used to measure a dataset’s accuracy, currency, completeness, and consistency. -

Response to NSF 20-015 Request for Information on Data-Focused
Response to NSF 20-015, Dear Colleague Letter: Request for Information on Data-Focused Cyberinfrastructure Needed to Support Future Data-Intensive Science and Engineering Research Reference ID: 11202805209_Poelen Reference ID: 11202805209_Poelen Submission Date and Time: 12/6/2019 6:22:08 PM This contribution was submitted to the National Science Foundation in response to a Request for Information, https://www.nsf.gov/pubs/2020/nsf20015/nsf20015.jsp. Consideration of this contribution in NSF's planning process and any NSF-provided public accessibility of this document does not constitute approval of the content by NSF or the US Government. The opinions and views expressed herein are those of the author(s) and do not necessarily reflect those of the NSF or the US Government. The content of this submission is protected by the Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License (https://creativecommons.org/licenses/by-nc-nd/4.0/legalcode). Consent Statement: “I hereby agree to give the National Science Foundation (NSF) the right to use this information for the purposes stated above and to display it on a publicly available website, consistent with the Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License (https://creativecommons.org/licenses/by-nc-nd/4.0/legalcode)." Consent answer: I consent to NSF's use and display of the submitted information. Author Names & Affiliations Submitting author: Jorrit Poelen - Independent Software and Data Engineer in Biodiversity Informatics Additional -

Generalist Repository Comparison Chart
This chart is designed to assist researchers in finding a generalist repository should no domain Generalist Repository repository be available to preserve their research data. Generalist repositories accept data regardless of data type, format, content, or disciplinary focus. For this chart, we included a repository available to all Comparison Chart researchers specific to clinical trials (Vivli) to bring awareness to those in this field. doi: 10.5281/zenodo.3946720 https://fairsharing.org/collection/GeneralRepositoryComparison HARVARD TOPIC DRYAD FIGSHARE MENDELEY DATA OSF VIVLI ZENODO DATAVERSE Brief Description Harvard Dataverse is Open-source, A free, open access, data Mendeley Data is a free OSF is a free and Vivli is an independent, Powering Open Science, a free data repository community-led data repository where users repository specialized open source project non-profit organization built on Open Source. open to all researchers curation, publishing, and can make all outputs of for research data. management tool that that has developed a Built by reserachers for from any discipline, both preservation platform for their research available in Search more than 20+ supports researchers global data-sharing researchers. Run from inside and outside of CC0 publicly available a discoverable, reusable, million datasets indexed throughout their entire and analytics platform. the CERN data centre, the Harvard community, research data and citable manner. from 1000s of data project lifecycle in open Our focus is on sharing whose purpose is long where you can share, Dryad is an independent Users can upload files repositories and collect science best practices. individual participant- term preservation archive, cite, access, and non-profit that works of any type and are and share datasets with level data from for the High Energy explore research data. -

How to Cite Datasets and Link to Publications
A Digital Curation Centre ‘working level’ guide How to Cite Datasets and Link to Publications Alex Ball (DCC) and Monica Duke (DCC) Please cite as: Ball, A., & Duke, M. (2015). ‘How to Cite Datasets and Link to Publications’. DCC How-to Guides. Edinburgh: Digital Curation Centre. Available online: http://www.dcc.ac.uk/resources/how-guides Digital Curation Centre, 2015. Licensed under Creative Commons Attribution 4.0 International: http://creativecommons.org/licenses/by/4.0/ How to Cite Datasets and Link to Publications Introduction This guide will help you create links between your academic publications and the underlying datasets, so that anyone viewing the publication will be able to locate the dataset and vice versa. It provides a working knowledge of the issues and challenges involved, and of how current approaches seek to address them. This guide should interest researchers and principal investigators working on data-led research, as well as the data repositories with which they work. Why cite datasets and link mechanisms allowing authors to be open about their research while still receiving due credit; metrics used them to publications? to translate such attributions into rewards for authors 1 and their institutions; and archives ensuring that the The motivation to cite datasets arises from a recog- work is permanently available for reference and reuse.5 nition that data generated in the course of research If datasets are to be regarded as first-class records of are just as valuable to the ongoing academic discourse research, as they need to be, a similar set of control as papers and monographs. -
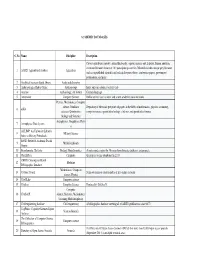
Academic Databases
ACADEMIC DATABASES S. No. Name Discipline Description Covers agriculture, forestry, animal husbandry, aquatic sciences and fisheries, human nutrition, extension literature from over 100 participating countries. Material includes unique grey literature 1 AGRIS: Agricultural database Agriculture such as unpublished scientific and technical reports, theses, conference papers, government publications, and more. 2 Analytical sciences digital library Analytical chemistry 3 Anthropological Index Online Anthropology Index only (no abstracts or full-text). 4 Arachne Archaeology, Art history German language 5 Arnetminer Computer Science Online service used to index and search academic social networks Physics, Mathematics, Computer science, Nonlinear Repository of electronic pre-prints of papers in the fields of mathematics, physics, astronomy, 6 arXiv sciences, Quantitative computer science, quantitative biology, statistics, and quantitative finance. biology and Statistics Astrophysics, Geophysics, Physi 7 Astrophysics Data System cs AULIMP: Air University Library's 8 Military Science Index to Military Periodicals BASE: Bielefeld Academic Search 9 Multidisciplinary Engine 10 Bioinformatic Harvester Biology, Bioinformatics A meta search engine for 50 major bioinformatic databases and projects. 11 ChemXSeer Chemistry the projects seems abandoned in 2018 CHBD: Circumpolar Health 12 Medicine Bibliographic Database Mathematics, Computer 13 Citebase Search Semi-autonomous citation index of free online research science, Physics 14 CiteULike Computer science -
An Editorial and Technical Journey Into Post Publication Peer Review (PPPR) Laurent Romary
An editorial and technical journey into Post Publication Peer Review (PPPR) Laurent Romary To cite this version: Laurent Romary. An editorial and technical journey into Post Publication Peer Review (PPPR). Friday Frontiers: A series of In-House Webinars for the DARIAH community, Oct 2020, Berlin / Virtual, Germany. hal-02960535v2 HAL Id: hal-02960535 https://hal.inria.fr/hal-02960535v2 Submitted on 13 Oct 2020 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Distributed under a Creative Commons Attribution| 4.0 International License An editorial and technical journey into Post Publication Peer Review (PPPR) Laurent Romary, Inria Dédicace spéciale à Jon Tennant Overview • Basic concepts of scholarly publishing • Publication, peer review and current issues • What is PPPR and why would we need it? • The various forms, features and issues related to PPPR • How can it be implemented? • Various private and public platforms • Moving forward • Data, protocols etc. Why PPPR, why now, why DARIAH? • Ever increasing concentra.on of services held by commercial publishers • Beyond their tradi-onal realms: [Mendeley, bepress, Scopus, SSRN] <= Elsevier • Request for more transparency of the reviewing process • Ques-oning the quality and objecves of tradi-onal peer review • Wider implementa.on of open science concepts • Cf.