Implied Volatility Surface Construction
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Machine Learning Based Intraday Calibration of End of Day Implied Volatility Surfaces
DEGREE PROJECT IN MATHEMATICS, SECOND CYCLE, 30 CREDITS STOCKHOLM, SWEDEN 2020 Machine Learning Based Intraday Calibration of End of Day Implied Volatility Surfaces CHRISTOPHER HERRON ANDRÉ ZACHRISSON KTH ROYAL INSTITUTE OF TECHNOLOGY SCHOOL OF ENGINEERING SCIENCES Machine Learning Based Intraday Calibration of End of Day Implied Volatility Surfaces CHRISTOPHER HERRON ANDRÉ ZACHRISSON Degree Projects in Mathematical Statistics (30 ECTS credits) Master's Programme in Applied and Computational Mathematics (120 credits) KTH Royal Institute of Technology year 2020 Supervisor at Nasdaq Technology AB: Sebastian Lindberg Supervisor at KTH: Fredrik Viklund Examiner at KTH: Fredrik Viklund TRITA-SCI-GRU 2020:081 MAT-E 2020:044 Royal Institute of Technology School of Engineering Sciences KTH SCI SE-100 44 Stockholm, Sweden URL: www.kth.se/sci Abstract The implied volatility surface plays an important role for Front office and Risk Manage- ment functions at Nasdaq and other financial institutions which require mark-to-market of derivative books intraday in order to properly value their instruments and measure risk in trading activities. Based on the aforementioned business needs, being able to calibrate an end of day implied volatility surface based on new market information is a sought after trait. In this thesis a statistical learning approach is used to calibrate the implied volatility surface intraday. This is done by using OMXS30-2019 implied volatil- ity surface data in combination with market information from close to at the money options and feeding it into 3 Machine Learning models. The models, including Feed For- ward Neural Network, Recurrent Neural Network and Gaussian Process, were compared based on optimal input and data preprocessing steps. -

Users/Robertjfrey/Documents/Work
AMS 511.01 - Foundations Class 11A Robert J. Frey Research Professor Stony Brook University, Applied Mathematics and Statistics [email protected] http://www.ams.sunysb.edu/~frey/ In this lecture we will cover the pricing and use of derivative securities, covering Chapters 10 and 12 in Luenberger’s text. April, 2007 1. The Binomial Option Pricing Model 1.1 – General Single Step Solution The geometric binomial model has many advantages. First, over a reasonable number of steps it represents a surprisingly realistic model of price dynamics. Second, the state price equations at each step can be expressed in a form indpendent of S(t) and those equations are simple enough to solve in closed form. 1+r D-1 u 1 1 + r D 1 + r D y y ÅÅÅÅÅÅÅÅÅÅÅÅÅÅÅÅÅÅÅÅÅÅÅÅÅÅÅÅÅÅÅÅÅÅ = u fl u = 1+r D u-1 u 1+r-u 1 u 1 u yd yd ÅÅÅÅÅÅÅÅÅÅÅÅÅÅÅÅ1+r D ÅÅÅÅÅÅÅÅ1 uêÅÅÅÅ-ÅÅÅÅu ÅÅ H L H ê L i y As we will see shortlyH weL Hwill solveL the general problemj by solving a zsequence of single step problems on the lattice. That K O K O K O K O j H L H ê L z sequence solutions can be efficientlyê computed because wej only have to zsolve for the state prices once. k { 1.2 – Valuing an Option with One Period to Expiration Let the current value of a stock be S(t) = 105 and let there be a call option with unknown price C(t) on the stock with a strike price of 100 that expires the next three month period. -
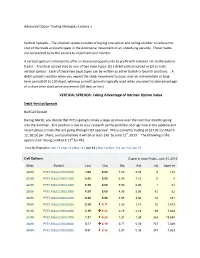
VERTICAL SPREADS: Taking Advantage of Intrinsic Option Value
Advanced Option Trading Strategies: Lecture 1 Vertical Spreads – The simplest spread consists of buying one option and selling another to reduce the cost of the trade and participate in the directional movement of an underlying security. These trades are considered to be the easiest to implement and monitor. A vertical spread is intended to offer an improved opportunity to profit with reduced risk to the options trader. A vertical spread may be one of two basic types: (1) a debit vertical spread or (2) a credit vertical spread. Each of these two basic types can be written as either bullish or bearish positions. A debit spread is written when you expect the stock movement to occur over an intermediate or long- term period [60 to 120 days], whereas a credit spread is typically used when you want to take advantage of a short term stock price movement [60 days or less]. VERTICAL SPREADS: Taking Advantage of Intrinsic Option Value Debit Vertical Spreads Bull Call Spread During March, you decide that PFE is going to make a large up move over the next four months going into the Summer. This position is due to your research on the portfolio of drugs now in the pipeline and recent phase 3 trials that are going through FDA approval. PFE is currently trading at $27.92 [on March 12, 2013] per share, and you believe it will be at least $30 by June 21st, 2013. The following is the option chain listing on March 12th for PFE. View By Expiration: Mar 13 | Apr 13 | May 13 | Jun 13 | Sep 13 | Dec 13 | Jan 14 | Jan 15 Call Options Expire at close Friday, -

A Glossary of Securities and Financial Terms
A Glossary of Securities and Financial Terms (English to Traditional Chinese) 9-times Restriction Rule 九倍限制規則 24-spread rule 24 個價位規則 1 A AAAC see Academic and Accreditation Advisory Committee【SFC】 ABS see asset-backed securities ACCA see Association of Chartered Certified Accountants, The ACG see Asia-Pacific Central Securities Depository Group ACIHK see ACI-The Financial Markets of Hong Kong ADB see Asian Development Bank ADR see American depositary receipt AFTA see ASEAN Free Trade Area AGM see annual general meeting AIB see Audit Investigation Board AIM see Alternative Investment Market【UK】 AIMR see Association for Investment Management and Research AMCHAM see American Chamber of Commerce AMEX see American Stock Exchange AMS see Automatic Order Matching and Execution System AMS/2 see Automatic Order Matching and Execution System / Second Generation AMS/3 see Automatic Order Matching and Execution System / Third Generation ANNA see Association of National Numbering Agencies AOI see All Ordinaries Index AOSEF see Asian and Oceanian Stock Exchanges Federation APEC see Asia Pacific Economic Cooperation API see Application Programming Interface APRC see Asia Pacific Regional Committee of IOSCO ARM see adjustable rate mortgage ASAC see Asian Securities' Analysts Council ASC see Accounting Society of China 2 ASEAN see Association of South-East Asian Nations ASIC see Australian Securities and Investments Commission AST system see automated screen trading system ASX see Australian Stock Exchange ATI see Account Transfer Instruction ABF Hong -

The Impact of Implied Volatility Fluctuations on Vertical Spread Option Strategies: the Case of WTI Crude Oil Market
energies Article The Impact of Implied Volatility Fluctuations on Vertical Spread Option Strategies: The Case of WTI Crude Oil Market Bartosz Łamasz * and Natalia Iwaszczuk Faculty of Management, AGH University of Science and Technology, 30-059 Cracow, Poland; [email protected] * Correspondence: [email protected]; Tel.: +48-696-668-417 Received: 31 July 2020; Accepted: 7 October 2020; Published: 13 October 2020 Abstract: This paper aims to analyze the impact of implied volatility on the costs, break-even points (BEPs), and the final results of the vertical spread option strategies (vertical spreads). We considered two main groups of vertical spreads: with limited and unlimited profits. The strategy with limited profits was divided into net credit spread and net debit spread. The analysis takes into account West Texas Intermediate (WTI) crude oil options listed on New York Mercantile Exchange (NYMEX) from 17 November 2008 to 15 April 2020. Our findings suggest that the unlimited vertical spreads were executed with profits less frequently than the limited vertical spreads in each of the considered categories of implied volatility. Nonetheless, the advantage of unlimited strategies was observed for substantial oil price movements (above 10%) when the rates of return on these strategies were higher than for limited strategies. With small price movements (lower than 5%), the net credit spread strategies were by far the best choice and generated profits in the widest price ranges in each category of implied volatility. This study bridges the gap between option strategies trading, implied volatility and WTI crude oil market. The obtained results may be a source of information in hedging against oil price fluctuations. -

Copyrighted Material
Index AA estimate, 68–69 At-the-money (ATM) SPX variance Affine jump diffusion (AJD), 15–16 levels/skews, 39f AJD. See Affine jump diffusion Avellaneda, Marco, 114, 163 Alfonsi, Aurelien,´ 163 American Airlines (AMR), negative book Bakshi, Gurdip, 66, 163 value, 84 Bakshi-Cao-Chen (BCC) parameters, 40, 66, American implied volatilities, 82 67f, 70f, 146, 152, 154f American options, 82 Barrier level, Amortizing options, 135 distribution, 86 Andersen, Leif, 24, 67, 68, 163 equal to strike, 108–109 Andreasen, Jesper, 67, 68, 163 Barrier options, 107, 114. See also Annualized Heston convexity adjustment, Out-of-the-money barrier options 145f applications, 120 Annualized Heston VXB convexity barrier window, 120 adjustment, 160f definitions, 107–108 Ansatz, 32–33 discrete monitoring, adjustment, 117–119 application, 34 knock-in options, 107 Arbitrage, 78–79. See also Capital structure knock-out options, 107, 108 arbitrage limiting cases, 108–109 avoidance, 26 live-out options, 116, 117f calendar spread arbitrage, 26 one-touch options, 110, 111f, 112f, 115 vertical spread arbitrage, 26, 78 out-of-the-money barrier, 114–115 Arrow-Debreu prices, 8–9 Parisian options, 120 Asymptotics, summary, 100 rebate, 108 Benaim, Shalom, 98, 163 At-the-money (ATM) implied volatility (or Berestycki, Henri, 26, 163 variance), 34, 37, 39, 79, 104 Bessel functions, 23, 151. See also Modified structure, computation, 60 Bessel function At-the-money (ATM) lookback (hindsight) weights, 149 option, 119 Bid/offer spread, 26 At-the-money (ATM) option, 70, 78, 126, minimization, -

Smile Arbitrage: Analysis and Valuing
UNIVERSITY OF ST. GALLEN Master program in banking and finance MBF SMILE ARBITRAGE: ANALYSIS AND VALUING Master’s Thesis Author: Alaa El Din Hammam Supervisor: Prof. Dr. Karl Frauendorfer Dietikon, 15th May 2009 Author: Alaa El Din Hammam Title of thesis: SMILE ARBITRAGE: ANALYSIS AND VALUING Date: 15th May 2009 Supervisor: Prof. Dr. Karl Frauendorfer Abstract The thesis studies the implied volatility, how it is recognized, modeled, and the ways used by practitioners in order to benefit from an arbitrage opportunity when compared to the realized volatility. Prediction power of implied volatility is exam- ined and findings of previous studies are supported, that it has the best prediction power of all existing volatility models. When regressed on implied volatility, real- ized volatility shows a high beta of 0.88, which contradicts previous studies that found lower betas. Moment swaps are discussed and the ways to use them in the context of volatility trading, the payoff of variance swaps shows a significant neg- ative variance premium which supports previous findings. An algorithm to find a fair value of a structured product aiming to profit from skew arbitrage is presented and the trade is found to be profitable in some circumstances. Different suggestions to implement moment swaps in the context of portfolio optimization are discussed. Keywords: Implied volatility, realized volatility, moment swaps, variance swaps, dispersion trading, skew trading, derivatives, volatility models Language: English Contents Abbreviations and Acronyms i 1 Introduction 1 1.1 Initial situation . 1 1.2 Motivation and goals of the thesis . 2 1.3 Structure of the thesis . 3 2 Volatility 5 2.1 Volatility in the Black-Scholes world . -

Fidelity 2017 Credit Spreads
Credit Spreads – And How to Use Them Marty Kearney 789768.1.0 1 Disclaimer Options involve risks and are not suitable for everyone. Individuals should not enter into options transactions until they have read and understood the risk disclosure document, Characteristics and Risks of Standardized Options, available by visiting OptionsEducation.org. To obtain a copy, contact your broker or The Options Industry Council at One North Wacker Drive, Chicago, IL 60606. Individuals should not enter into options transactions until they have read and understood this document. In order to simplify the computations used in the examples in these materials, commissions, fees, margin interest and taxes have not been included. These costs will impact the outcome of any stock and options transactions and must be considered prior to entering into any transactions. Investors should consult their tax advisor about any potential tax consequences. Any strategies discussed, including examples using actual securities and price data, are strictly for illustrative and educational purposes and should not be construed as an endorsement, recommendation, or solicitation to buy or sell securities. Past performance is not a guarantee of future results. 2 Spreads . What is an Option Spread? . An Example of a Vertical Debit Spread . Examples of Vertical Credit Spreads . How to choose strike prices when employing the Vertical Credit Spread strategy . Note: Any mention of Credit Spread today is using a Vertical Credit Spread. 3 A Spread A Spread is a combination trade, buying and/or selling two or more financial products. It could be stock and stock (long Coca Cola – short shares of Pepsi), Stock and Option (long Qualcomm, short a March QCOM call - many investors have used the “Covered Call”), maybe long an IBM call and Put. -

Pricing Bermudan and American Options Using the FFT Method
Master Thesis for Degree in Computational Engineering of Uni. Erlangen-Nuernberg, Germany Pricing Bermudan and American Options Using the FFT Method by Fang FANG Martrikelnummer: 21119128 Advisor: Dr. Ir. Kees Oosterlee (TU Delft, Netherlands) and Prof. Ulrich Ruede Cooperation with: Ir. Drs. Roger Lord (Rabobank, Utrecht, Netherlands) May 25, 2006 Special Thanks This thesis work was carried out in the Delft Center for Computational Science and Engi- neering, TU Delft, the Netherlands. The research started in September 2005 and ¯nished in May 2006. During the whole period, from literature review, numerical implementation, to remedy seeking for discovered problems, and ¯nal thesis writing, the work was under supervision of Dr.Ir. Kees Oosterlee. Without his great help, the thesis work could never have been ¯nished successfully. The work is performed in a cooperation with Ir. Drs. Roger Lord from Rabobank. The starting point of the methods involved in this thesis is based on his research. The idea of replacing FFT by FRFT is also proposed by him. Besides, I've bene¯ted a lot from his comments to my work and from discussions and brain-storming together with him and Dr.Ir. Kees Oosterlee. Mr. Frank Bervoets helped a lot in the aspect of high e±ciency Matlab programming. Besides, discussions on parameter choosing and other problems in implementation with him gave me a better understanding of the methods and their behaviors. Without the full support and help of prof. Ulrich Ruede, it was not possible for me to focus on this thesis work in the Netherlands. My husband is the one who's always standing by my side, with encouragement and support. -

“Trading the Volatility Skew of the Options on the S&P Index”
\Trading the volatility skew of the options on the S&P index" Juan Aguirre Bueno Directors: Juan Toro Cebada Angel Manuel Ramos de Olmo Benjamin Ivorra Trabajo de Fin de Master Academic year: 2011-2012 Contents 1 Introduction and objectives of the work 4 2 Basic concepts 4 2.1 Options general terminology . 4 2.2 Payoff .......................................... 5 2.3 Option value . 6 2.4 Options pricing . 6 2.5 Decomposition of a portfolio profits and losses (P&L) in its greeks components . 7 3 Vertical spreads 9 4 Greeks analysis of vertical spreads 10 4.1 Bullish call spread. 11 4.1.1 Delta . 11 4.1.2 Gamma . 11 4.1.3 Vega . 11 4.1.4 "Singular" point . 11 4.1.5 Graphs . 12 4.2 Bullish put spread. 13 4.3 Bearish call spread. 14 4.3.1 Delta . 14 4.3.2 Gamma . 14 4.3.3 Vega . 14 4.3.4 "Singular" point . 14 4.3.5 Graphs . 15 4.4 Bearish put spread. 16 4.5 Influence of volatility on the spreads . 16 4.5.1 Low implied volatility scenario . 16 4.5.2 High implied volatility scenario . 17 5 The volatility smile 18 5.1 Features of the volatility smile of equity index options . 19 2 5.1.1 "Volatility are steepest for small expirations as a function of strike, shal- lower for longer expirations" . 19 5.1.2 "There is a negative correlation between changes in implied ATM volatility and changes in the underlying itself" . 20 5.1.3 "Low strike volatilities are usually higher than high-strike volatilities" . -

GFSR-Transition Challenges to Stability: Chapter 2 and Chapter 3
CHAPTER 2 ASSESSING POLICIES TO REVIVE CREDIT MARKETS SUMMARY olicymakers in economies hit hard by the global financial crisis have been concerned about weak growth in credit, considered a main factor in the slow economic recovery. Many countries with near-zero or nega- tive credit growth for a number of years sense that the strategy of very accommodative macroeconomic policies has been insufficient in reviving credit activity. Authorities have therefore implemented a host of Ppolicies to target credit creation (which are documented in an appendix to the chapter).1 Effectively targeting these policies requires identifying the factors that underlie the weakness in credit. In credit markets, these factors center around the buildup of excessive debt in households and firms, reducing their credit demand, as well as excessive leverage (or a shortage of capital) in banks, restricting their ability or willingness to provide additional loans. The government could also usefully alleviate a shortage of collateral (perhaps resulting from large declines in asset values), which could constrain credit activity. To address such a technically challenging exercise, this chapter takes a stepwise approach. The first step is an attempt to identify the constraints to credit through the use of lending surveys—trying to disentangle whether banks are unwilling to lend (on the supply side) or whether firms or households are reluctant to borrow (on the demand side). This distinction helps narrow down the set of policies to consider, which differ depending on the side of the market that faces the major constraint. A more challenging second step—which is hampered by the lack of sufficient data for many countries—is to identify the individual factors that are constraining credit, specifically what makes banks unwilling to lend or households and firms reluctant to borrow. -
![To Sigmoid-Based Functional Description of the Volatility Smile. Arxiv:1407.0256V3 [Q-Fin.MF] 8 Dec 2014](https://docslib.b-cdn.net/cover/5764/to-sigmoid-based-functional-description-of-the-volatility-smile-arxiv-1407-0256v3-q-fin-mf-8-dec-2014-2455764.webp)
To Sigmoid-Based Functional Description of the Volatility Smile. Arxiv:1407.0256V3 [Q-Fin.MF] 8 Dec 2014
To sigmoid-based functional description of the volatility smile. Andrey Itkin Polytechnic School of Engineering, New York University, 6 Metro Tech Center, RH 517E, Brooklyn NY 11201, USA December 9, 2014 Abstract We propose a new static parameterization of the implied volatility surface which is constructed by using polynomials of sigmoid functions combined with some other terms. This parameterization is flexible enough to fit market implied volatilities which demonstrate smile or skew. An arbitrage-free calibration algorithm is considered that constructs the implied volatility surface as a grid in the strike-expiration space and guarantees a lack of arbitrage at every node of this grid. We also demonstrate how to construct an arbitrage-free interpolation and extrapolation in time, as well as build a local volatility and implied pdf surfaces. Asymptotic behavior of this parameterization is discussed, as well as results on stability of the calibrated parameters are presented. Numerical examples show robustness of the proposed approach in building all these surfaces as well as demonstrate a better quality of the fit as compared with some known models. Keywords: volatility surface, static parametrization, arbitrage-free interpolation and extrapolation JEL classification: C6, C61, G17 arXiv:1407.0256v3 [q-fin.MF] 8 Dec 2014 1 Overview During last 15 years various parameterizations of the implied volatility (IV) surface were proposed in the literature to address few goals: a) given a set of market quotes for some options build an arbitrage-free local volatility (Dupire's) surface to further exploit it for calibration of a local stochastic volatility model; b) obtain volatilities for pricing OTC options and other derivatives with strikes and maturities other than that offered by the option exchanges; c) assess an adequacy of an option pricing model based on the shape of the IV 1 surface.