A Description of the Phonology and Morphology of Kɔɖa, an Endangered Language of Bangladesh
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
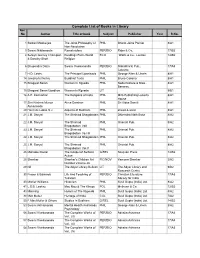
Complete List of Books in Library Acc No Author Title of Book Subject Publisher Year R.No
Complete List of Books in Library Acc No Author Title of book Subject Publisher Year R.No. 1 Satkari Mookerjee The Jaina Philosophy of PHIL Bharat Jaina Parisat 8/A1 Non-Absolutism 3 Swami Nikilananda Ramakrishna PER/BIO Rider & Co. 17/B2 4 Selwyn Gurney Champion Readings From World ECO `Watts & Co., London 14/B2 & Dorothy Short Religion 6 Bhupendra Datta Swami Vivekananda PER/BIO Nababharat Pub., 17/A3 Calcutta 7 H.D. Lewis The Principal Upanisads PHIL George Allen & Unwin 8/A1 14 Jawaherlal Nehru Buddhist Texts PHIL Bruno Cassirer 8/A1 15 Bhagwat Saran Women In Rgveda PHIL Nada Kishore & Bros., 8/A1 Benares. 15 Bhagwat Saran Upadhya Women in Rgveda LIT 9/B1 16 A.P. Karmarkar The Religions of India PHIL Mira Publishing Lonavla 8/A1 House 17 Shri Krishna Menon Atma-Darshan PHIL Sri Vidya Samiti 8/A1 Atmananda 20 Henri de Lubac S.J. Aspects of Budhism PHIL sheed & ward 8/A1 21 J.M. Sanyal The Shrimad Bhagabatam PHIL Dhirendra Nath Bose 8/A2 22 J.M. Sanyal The Shrimad PHIL Oriental Pub. 8/A2 Bhagabatam VolI 23 J.M. Sanyal The Shrimad PHIL Oriental Pub. 8/A2 Bhagabatam Vo.l III 24 J.M. Sanyal The Shrimad Bhagabatam PHIL Oriental Pub. 8/A2 25 J.M. Sanyal The Shrimad PHIL Oriental Pub. 8/A2 Bhagabatam Vol.V 26 Mahadev Desai The Gospel of Selfless G/REL Navijvan Press 14/B2 Action 28 Shankar Shankar's Children Art FIC/NOV Yamuna Shankar 2/A2 Number Volume 28 29 Nil The Adyar Library Bulletin LIT The Adyar Library and 9/B2 Research Centre 30 Fraser & Edwards Life And Teaching of PER/BIO Christian Literature 17/A3 Tukaram Society for India 40 Monier Williams Hinduism PHIL Susil Gupta (India) Ltd. -

BR-October 08
power. It is less convincing Celebrating Indian in the reasons it gives for the CPM’s fall and the rise of Democracy Mamata Banerjee. From the late 1990s, CPM Ministers, Satyabrata Pal travelling abroad to woo for- eign investors, would freely confess that they had a he books under review are two additions to the long and distin- problem with their younger Tguished line of books that have puzzled over the improbable generation, which argued success of democracy in India. Sumantra Bose starts off by recalling that the Party had given land Seymour Martin Lipset’s view that ‘the more well-to-do a nation, to their parents but done the greater the chances that it will sustain democracy’. Ashutosh nothing for them. The Varshney invokes the work of Prezeworski and others, who estab- CPM knew it had to offer lished that income was the best predictor of democracy. Both stress jobs, but hamstrung by its that India has remained democratic against the odds. But perhaps it past, clumsily forced should not be surprising if India does not fit an academic mould or through land acquisitions conform to political theory, simply because, on so many counts, for the major industrial including its size and heterogeneity, it is sui generis. Theses devel- projects that it realized were oped from the experience of smaller nations may not fit a subconti- essential. nent. In the chapter on ‘The For the same reason, examining the ways in which India kept Maoist Challenge’, Bose argues that an absence of governance and of the democratic flame alive serves a limited practical purpose, be- government support for remote and impoverished communities led cause what worked here might fail in states much smaller or less to the rebirth of the Maoists after the implosion of the original Naxal complex, where simple totalitarian solutions are both more tempt- movement in West Bengal. -

Morphological Causatives Are Voice Over Voice
Morphological causatives are Voice over Voice Yining Nie New York University Abstract Causative morphology has been associated with either the introduction of an event of causation or the introduction of a causer argument. However, morphological causatives are mono-eventive, casting doubt on the notion that causatives fundamentally add a causing event. On the other hand, in some languages the causative morpheme is closer to the verb root than would be expected if the causative head is responsible for introducing the causer. Drawing on evidence primarily from Tagalog and Halkomelem, I argue that the syntactic configuration for morphological causatives involves Voice over Voice, and that languages differ in whether their ‘causative marker’ spells out the higher Voice, the lower Voice or both. Keywords: causative, Voice, argument structure, morpheme order, typology, Tagalog 1. Introduction Syntactic approaches to causatives generally fall into one of two camps. The first view builds on the discovery that causatives may semantically consist of multiple (sub)events (Jackendoff 1972, Dowty 1979, Parsons 1990, Levin & Rappaport Hovav 1994, a.o.). Consider the following English causative–anticausative pair. The anticausative in (1a) consists of an event of change of state, schematised in (1b). The causative in (2a) involves the same change of state plus an additional layer of semantics that conveys how that change of state is brought about (2b). (1) a. The stick broke. b. [ BECOME [ stick STATE(broken) ]] (2) a. Pat broke the stick. b. [ Pat CAUSE [ BECOME [ stick STATE(broken) ]]] Word Structure 13.1 (2020): 102–126 DOI: 10.3366/word.2020.0161 © Edinburgh University Press www.euppublishing.com/word MORPHOLOGICAL CAUSATIVES ARE VOICE OVER VOICE 103 Several linguists have proposed that the semantic CAUSE and BECOME components of the causative are encoded as independent lexical verbal heads in the syntax (Harley 1995, Cuervo 2003, Folli & Harley 2005, Pylkkänen 2008, a.o.). -

Minimalist C/Case Sigurðsson, Halldor Armann
Minimalist C/case Sigurðsson, Halldor Armann Published in: Linguistic Inquiry 2012 Link to publication Citation for published version (APA): Sigurðsson, H. A. (2012). Minimalist C/case. Linguistic Inquiry, 43(2), 191-227. http://ling.auf.net/lingBuzz/000967 Total number of authors: 1 General rights Unless other specific re-use rights are stated the following general rights apply: Copyright and moral rights for the publications made accessible in the public portal are retained by the authors and/or other copyright owners and it is a condition of accessing publications that users recognise and abide by the legal requirements associated with these rights. • Users may download and print one copy of any publication from the public portal for the purpose of private study or research. • You may not further distribute the material or use it for any profit-making activity or commercial gain • You may freely distribute the URL identifying the publication in the public portal Read more about Creative commons licenses: https://creativecommons.org/licenses/ Take down policy If you believe that this document breaches copyright please contact us providing details, and we will remove access to the work immediately and investigate your claim. LUND UNIVERSITY PO Box 117 221 00 Lund +46 46-222 00 00 Access Provided by Lunds universitet at 04/30/12 3:55PM GMT Minimalist C/case Halldo´rA´ rmann SigurLsson This article discusses A-licensing and case from a minimalist perspec- tive, pursuing the idea that argument NPs cyclically enter a number of A-relations, rather than just a single one, resulting in event licensing, case licensing, and -licensing. -

India Freedom Fighters' Organisation
A Guide to the Microfiche Edition of Political Pamphlets from the Indian Subcontinent Part 5: Political Parties, Special Interest Groups, and Indian Internal Politics UNIVERSITY PUBLICATIONS OF AMERICA A Guide to the Microfiche Edition of POLITICAL PAMPHLETS FROM THE INDIAN SUBCONTINENT PART 5: POLITICAL PARTIES, SPECIAL INTEREST GROUPS, AND INDIAN INTERNAL POLITICS Editorial Adviser Granville Austin Guide compiled by Daniel Lewis A microfiche project of UNIVERSITY PUBLICATIONS OF AMERICA An Imprint of CIS 4520 East-West Highway • Bethesda, MD 20814-3389 Library of Congress Cataloging-in-Publication Data Indian political pamphlets [microform] microfiche Accompanied by printed guide. Includes bibliographical references. Content: pt. 1. Political Parties and Special Interest Groups—pt. 2. Indian Internal Politics—[etc.]—pt. 5. Political Parties, Special Interest Groups, and Indian Internal Politics ISBN 1-55655-829-5 (microfiche) 1. Political parties—India. I. UPA Academic Editions (Firm) JQ298.A1 I527 2000 <MicRR> 324.254—dc20 89-70560 CIP Copyright © 2000 by University Publications of America. All rights reserved. ISBN 1-55655-829-5. ii TABLE OF CONTENTS Introduction ............................................................................................................................. vii Source Note ............................................................................................................................. xi Reference Bibliography Series 1. Political Parties and Special Interest Groups Organization Accession # -

Rivers of Peace: Restructuring India Bangladesh Relations
C-306 Montana, Lokhandwala Complex, Andheri West Mumbai 400053, India E-mail: [email protected] Project Leaders: Sundeep Waslekar, Ilmas Futehally Project Coordinator: Anumita Raj Research Team: Sahiba Trivedi, Aneesha Kumar, Diana Philip, Esha Singh Creative Head: Preeti Rathi Motwani All rights are reserved. No part of this book may be reproduced or utilised in any form or by any means, electronic or mechanical, without prior permission from the publisher. Copyright © Strategic Foresight Group 2013 ISBN 978-81-88262-19-9 Design and production by MadderRed Printed at Mail Order Solutions India Pvt. Ltd., Mumbai, India PREFACE At the superficial level, relations between India and Bangladesh seem to be sailing through troubled waters. The failure to sign the Teesta River Agreement is apparently the most visible example of the failure of reason in the relations between the two countries. What is apparent is often not real. Behind the cacophony of critics, the Governments of the two countries have been working diligently to establish sound foundation for constructive relationship between the two countries. There is a positive momentum. There are also difficulties, but they are surmountable. The reason why the Teesta River Agreement has not been signed is that seasonal variations reduce the flow of the river to less than 1 BCM per month during the lean season. This creates difficulties for the mainly agrarian and poor population of the northern districts of West Bengal province in India and the north-western districts of Bangladesh. There is temptation to argue for maximum allocation of the water flow to secure access to water in the lean season. -

German Free Datives and Knight Move Binding Daniel Hole/Universität Stuttgart
German free datives and Knight Move Binding Daniel Hole/Universität Stuttgart 1. Introduction This paper is concerned with German free datives and their peculiar binding behavior. * I ar- gue that free datives are best described in terms of voice. The free dative voice turns out to be very similar to run-of-the-mill cases of reflexivity, which must likewise be modeled as a kind of voice under the theoretical assumptions of Kratzer’s (1996) agent severance. The free da- tive, just like a reflexive antecedent in German, binds a variable in the local tense domain. What is highly peculiar about the free dative voice is the tree-geometrical requirement that goes along with it. The variable that free datives bind must be at the left edge of a clause-mate coargumental possessum phrase or purpose phrase (‘Knight Move Binding’). Standard im- plementations of binding don’t include requirements of this kind. The argumentation strives to show that the requirement of Knight Move Binding really exists, and that this kind of bind- ing is a privileged configuration in the grammaticalization of reflexive pronouns crosslinguis- tically. The paper delimits the empirical domain of free datives in sects. 2 and 3. Sect. 4 estab- lishes the parallel locality restrictions of dative binding for “possessor” and “beneficiary” da- tives. Sect. 5 establishes the Knight Move Binding requirement of free datives. Sect. 6 devel- ops the semantic implementation of free dative binding with a large detour via semantic theo- ries of reflexivization. Competing proposals are briefly discussed in sect. 7. Sect. 8 concludes the paper. -

Rajya Sabha Debates
5341 Oral Answers [24 SEP. 1965] to Questions 5342 RAJYA SABHA Friday, the 25th September, 1965/the 2nd Asvina, 1887 (Saka) The House met at ten of the clock, MR. CHAIRMAN in the Chair. ORAL ANSWERS TO QUESTIONS t[THE MINISTER OF STATE IN THE MINISTRY OF HOME AFFAIRS (SHRI JAISUKHLAL HATHI): A statement is laid on the Table of the House. STATEMENT A steady reduction in the proportion of those dependent on agriculture is an important objective of our Five Year Plan. In the Third Plan it was proposed that about two-thirds of the increase in the labour force during the 15 years 1961—1976 should be absorbed in non- f [AGRICULTURISTS AND AGRICULTURAL agricultural occupations. To this end LABOUR programmes for the development of industries, transport and power, rural •806. SHRI B. N. SHARGAVA: Will the industrialisation and intensification of Minister of HOME AFFAIRS be pleased to agriculture are being pursued systematically state what more steps Government propose to through our Plans. Special attention to these take to bring down the percentage of aspects is being given in the context of the agriculturists and agricultural labour in the Fourth Plan.] total number of working force?] ] English translation 748RS—1 5343 Oral Answers [ RAJYA SABHA] to Questions, 5344 SHRI M. M. DHARIA: Is the Government considering to have an enactment of the nature of minimum wages for agricultural labourers while bring, ing down the proportion? SHRI JAISUKHLAL HATHI: Perhaps that SHRI JAISUKHLAL HATHI: In the Third might be under the consideration of the Plan a target of employment opportunities for Labour Ministry. -

NO PLACE for CRITICISM Bangladesh Crackdown on Social Media Commentary WATCH
HUMAN RIGHTS NO PLACE FOR CRITICISM Bangladesh Crackdown on Social Media Commentary WATCH No Place for Criticism Bangladesh Crackdown on Social Media Commentary Copyright © 2018 Human Rights Watch All rights reserved. Printed in the United States of America ISBN: 978-1-6231-36017 Cover design by Rafael Jimenez Human Rights Watch defends the rights of people worldwide. We scrupulously investigate abuses, expose the facts widely, and pressure those with power to respect rights and secure justice. Human Rights Watch is an independent, international organization that works as part of a vibrant movement to uphold human dignity and advance the cause of human rights for all. Human Rights Watch is an international organization with staff in more than 40 countries, and offices in Amsterdam, Beirut, Berlin, Brussels, Chicago, Geneva, Goma, Johannesburg, London, Los Angeles, Moscow, Nairobi, New York, Paris, San Francisco, Sydney, Tokyo, Toronto, Tunis, Washington DC, and Zurich. For more information, please visit our website: http://www.hrw.org MAY 2018 ISBN: 978-1-6231-36017 No Place for Criticism Bangladesh Crackdown on Social Media Commentary Summary ........................................................................................................................... 1 Information and Communication Act ......................................................................................... 3 Punishing Government Critics ...................................................................................................4 Protecting Religious -

P. D. T. Achary LOKSABHASECRETAR~T NEW DELHI SPEAKER RULES SPEAKER RULES
P. D. T. Achary LOKSABHASECRETAR~T NEW DELHI SPEAKER RULES SPEAKER RULES P. D. T. ACHARY LOK SABHA SECRETARIAT Published by the Lok Sabha Secretariat, New Delhi-I 10 001, (India). First Published, 2001 Price: Rs. 600/- ©2007 Lok Sabha Secretariat Published under Rule 382 of the Rules of Procedure and Conduct of Business in Lok Sabha (Eleventh Edition). Printed by: J ainco Art India, New Delhi-lIO 005, (India). TABLE OF CONTENTS PAGE Nos. FOREWORD ..................................................................................... (iii) PREFACE ••.........................................•..............................•••..........•• (v) CHAPTERS 1. Adjournment of Debate on a Bill ................................... 1 2. Adjournment Motion ..................................................... 5 3. Allegation ....................................................................... 20 4. Arrest of a Member ........................................................ 25 5. Bills ................................................................................ 30 6. Budget ............................... .......... ................................... 44 7. Calling Attention. ............. ........... ........... .......... ........... ... 59 8. Censure Motion against Ministers ......... ........................ 67 9. Consideration of Demands for Grants by Departmentally- related Standing Committees (DRSCs) ......................... 72 10. Custody of Papers of the House ..................................... 74 11. Cut Motions ........... ...... -

1 Possessive Voice in Wolof: a Rara Type of Valency Operator 1
Possessive voice construction in Wolof Sylvie Voisin 29/11/06 “Rara & rarissima” MPI – Leipzig (29 March – 1 April 2006) Possessive voice in Wolof: A rara type of valency operator 1 INTRODUCTION The purpose of this paper is to describe an uncommon valency operator in Wolof, the verbal morpheme –le which encodes a possessive relation between the subject and the object of a derived verb. After a brief presentation of background information to facilitate the discussion, internal possessive constructions in Wolof will be presented. First, the particularities of the “le- construction” will be compared to different strategies of external possession construction observed in different languages following the typology proposed by Payne & Barshi (1999). Second, the “le- construction” will be compared to the Japanese possessive passive, as well as to double derivation constructions, such applicative-passives in other languages. Finally, even if the possessive construction –le in Wolof, and external possession constructions or derivations including passive share some characteristics, I will concluded that this valency operator in Wolof is specific and will propose a hypothesis of its emergence. 2 WOLOF BACKGROUNG INFORMATION1 Wolof is a West Atlantic language spoken in Senegal and also in Gambia and Mauritania. As many Niger-congo languages, Wolof has a nominal class system. It is reduced in comparison with other Atlantic languages. It is compounded of 8 consonants for singular and 2 consonants for plural: - singular: b-, k-, l-, w-, m-, g-, s- and j- - plural: y- and ñ- In this system, the consonants are used as support for determinant markers and can’t be analyzed as affixed class markers (*ñ-góor ; góor ñ-i “the men” ; góor ñ-ale “these men”). -

Diminutive and Augmentative Functions of Some Luganda Noun Class Markers Samuel Namugala MA Thesis in Linguistics Norwegian Un
Diminutive and Augmentative Functions of some Luganda Noun Class Markers Samuel Namugala MA Thesis in Linguistics Norwegian University of Science and Technology (NTNU) Faculty of Humanities Department of Language and Literature Trondheim, April, 2014 To my parents, Mr. and Mrs. Wampamba, and my siblings, Polycarp, Lydia, Christine, Violet, and Joyce ii Acknowledgements I wish to express my gratitude to The Norwegian Government for offering me a grant to pursue the master’s program at NTNU. Without this support, I would perhaps not have achieved my dream of pursuing the master’s degree in Norway. Special words of thanks go to my supervisors, Professor Kaja Borthen and Professor Assibi Amidu for guiding me in writing this thesis. Your scholarly guidance, constructive comments and critical revision of the drafts has made it possible for me to complete this thesis. I appreciate the support and the knowledge that you have shared with me. I look forward to learn more from you. My appreciation also goes to my lecturers and the entire staff at the Department of Language and Literature. I am grateful to Professor Lars Hellan, Assoc. Professor Dorothee Beermann, Professor Wim Van Dommelen, and Assoc. Professor Jardar Abrahamsen for the knowledge you have shared with me since I joined NTNU. You have made me the linguist that I desired to be. I also wish to thank the authors that didn’t mind to help me when contacted for possible relevant literature for my thesis. My appreciation goes to Prof. Nana Aba Appiah Amfo (University of Ghana), Assistant Prof. George J. Xydopoulos (Linguistics School of Philology, University of Patras, Greece), Prof.