The Puzzle of Albanian Po
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

0. Introduction L2/12-386
Doc Type: Working Group Document Title: Revised Proposal to Encode Additional Old Italic Characters Source: UC Berkeley Script Encoding Initiative (Universal Scripts Project) Author: Christopher C. Little ([email protected]) Status: Liaison Contribution Action: For consideration by JTC1/SC2/WG2 and UTC Replaces: N4046 (L2/11-146R) Date: 2012-11-06 0. Introduction The existing Old Italic character repertoire includes 31 letters and 4 numerals. The Unicode Standard, following the recommendations in the proposal L2/00-140, states that Old Italic is to be used for the encoding of Etruscan, Faliscan, Oscan, Umbrian, North Picene, and South Picene. It also specifically states that Old Italic characters are inappropriate for encoding the languages of ancient Italy north of Etruria (Venetic, Raetic, Lepontic, and Gallic). It is true that the inscriptions of languages north of Etruria exhibit a number of common features, but those features are often exhibited by the other scripts of Italy. Only one of these northern languages, Raetic, requires the addition of any additional characters in order to be fully supported by the Old Italic block. Accordingly, following the addition of this one character, the Unicode Standard should be amended to recommend the encoding of Venetic, Raetic, Lepontic, and Gallic using Old Italic characters. In addition, one additional character is necessary to encode South Picene inscriptions. This proposal is divided into five parts: The first part (§1) identifies the two unencoded characters (Raetic Ɯ and South Picene Ũ) and demonstrates their use in inscriptions. The second part (§2) examines the use of each Old Italic character, as it appears in Etruscan, Faliscan, Oscan, Umbrian, South Picene, Venetic, Raetic, Lepontic, Gallic, and archaic Latin, to demonstrate the unifiability of the northern Italic languages' scripts with Old Italic. -

Albanian Language Identification in Text
5 BSHN(UT)23/2017 ALBANIAN LANGUAGE IDENTIFICATION IN TEXT DOCUMENTS *KLESTI HOXHA.1, ARTUR BAXHAKU.2 1University of Tirana, Faculty of Natural Sciences, Department of Informatics 2University of Tirana, Faculty of Natural Sciences, Department of Mathematics email: [email protected] Abstract In this work we investigate the accuracy of standard and state-of-the-art language identification methods in identifying Albanian in written text documents. A dataset consisting of news articles written in Albanian has been constructed for this purpose. We noticed a considerable decrease of accuracy when using test documents that miss the Albanian alphabet letters “Ë” and “Ç” and created a custom training corpus that solved this problem by achieving an accuracy of more than 99%. Based on our experiments, the most performing language identification methods for Albanian use a naïve Bayes classifier and n-gram based classification features. Keywords: Language identification, text classification, natural language processing, Albanian language. Përmbledhje Në këtë punim shqyrtohet saktësia e disa metodave standarde dhe bashkëkohore në identifikimin e gjuhës shqipe në dokumente tekstuale. Për këtë qëllim është ndërtuar një bashkësi të dhënash testuese e cila përmban artikuj lajmesh të shkruara në shqip. Për tekstet shqipe që nuk përmbajnë gërmat “Ë” dhe “Ç” u vu re një zbritje e konsiderueshme e saktësisë së identifikimit të gjuhës. Për këtë arsye u krijua një korpus trajnues i posaçëm që e zgjidhi këtë problem duke arritur një saktësi prej më shumë se 99%. Bazuar në eksperimentet e kryera, metodat më të sakta për identifikimin e gjuhës shqipe përdorin një klasifikues “naive Bayes” dhe veçori klasifikuese të bazuara në n-grame. -

THE INDO-EUROPEAN FAMILY — the LINGUISTIC EVIDENCE by Brian D
THE INDO-EUROPEAN FAMILY — THE LINGUISTIC EVIDENCE by Brian D. Joseph, The Ohio State University 0. Introduction A stunning result of linguistic research in the 19th century was the recognition that some languages show correspondences of form that cannot be due to chance convergences, to borrowing among the languages involved, or to universal characteristics of human language, and that such correspondences therefore can only be the result of the languages in question having sprung from a common source language in the past. Such languages are said to be “related” (more specifically, “genetically related”, though “genetic” here does not have any connection to the term referring to a biological genetic relationship) and to belong to a “language family”. It can therefore be convenient to model such linguistic genetic relationships via a “family tree”, showing the genealogy of the languages claimed to be related. For example, in the model below, all the languages B through I in the tree are related as members of the same family; if they were not related, they would not all descend from the same original language A. In such a schema, A is the “proto-language”, the starting point for the family, and B, C, and D are “offspring” (often referred to as “daughter languages”); B, C, and D are thus “siblings” (often referred to as “sister languages”), and each represents a separate “branch” of the family tree. B and C, in turn, are starting points for other offspring languages, E, F, and G, and H and I, respectively. Thus B stands in the same relationship to E, F, and G as A does to B, C, and D. -

The Shared Lexicon of Baltic, Slavic and Germanic
THE SHARED LEXICON OF BALTIC, SLAVIC AND GERMANIC VINCENT F. VAN DER HEIJDEN ******** Thesis for the Master Comparative Indo-European Linguistics under supervision of prof.dr. A.M. Lubotsky Universiteit Leiden, 2018 Table of contents 1. Introduction 2 2. Background topics 3 2.1. Non-lexical similarities between Baltic, Slavic and Germanic 3 2.2. The Prehistory of Balto-Slavic and Germanic 3 2.2.1. Northwestern Indo-European 3 2.2.2. The Origins of Baltic, Slavic and Germanic 4 2.3. Possible substrates in Balto-Slavic and Germanic 6 2.3.1. Hunter-gatherer languages 6 2.3.2. Neolithic languages 7 2.3.3. The Corded Ware culture 7 2.3.4. Temematic 7 2.3.5. Uralic 9 2.4. Recapitulation 9 3. The shared lexicon of Baltic, Slavic and Germanic 11 3.1. Forms that belong to the shared lexicon 11 3.1.1. Baltic-Slavic-Germanic forms 11 3.1.2. Baltic-Germanic forms 19 3.1.3. Slavic-Germanic forms 24 3.2. Forms that do not belong to the shared lexicon 27 3.2.1. Indo-European forms 27 3.2.2. Forms restricted to Europe 32 3.2.3. Possible Germanic borrowings into Baltic and Slavic 40 3.2.4. Uncertain forms and invalid comparisons 42 4. Analysis 48 4.1. Morphology of the forms 49 4.2. Semantics of the forms 49 4.2.1. Natural terms 49 4.2.2. Cultural terms 50 4.3. Origin of the forms 52 5. Conclusion 54 Abbreviations 56 Bibliography 57 1 1. -

Rock Art and Celto-Germanic Vocabulary Shared Iconography and Words As Reflections of Bronze Age Contact
John T. Koch Rock art and Celto-Germanic vocabulary Shared iconography and words as reflections of Bronze Age contact Abstract Recent discoveries in the chemical and isotopic sourcing of metals and ancient DNA have transformed our understanding of the Nordic Bronze Age in two key ways. First, we find that Scandinavia and the Iberian Peninsula were in contact within a system of long- distance exchange of Baltic amber and Iberian copper. Second, by the Early Bronze Age, mass migrations emanating from the Pontic-Caspian steppe had reached both regions, probably bringing Indo-European languages with them. In the light of these discoveries, we launched a research project in 2019 — ‘Rock art, Atlantic Europe, Words & Warriors (RAW)’ — based at the University of Gothenburg and funded by the Swedish Research Council (Vetenskapsrådet). The RAW project undertakes an extensive programme of scanning and documentation to enable detailed comparison of the strikingly similar iconography of Scandinavian rock art and Iberian ‘warrior’ stelae. A linguistic aspect of this cross-disciplinary project is to re-examine the inherited word stock shared by Celtic and Germanic, but absent from the other Indo-European languages, exploring how these words might throw light onto the world of meaning of Bronze rock art and the people who made it. This paper presents this linguistic aspect of the RAW project and some pre- liminary findings. Keywords: rock art, Bronze Age, Proto-Celtic, Proto-Germanic Introduction The recurrent themes and concepts found migrations emanating from the Pontic- in both the rock art of Scandinavia and Caspian steppe spreading widely across the Late Bronze Age ‘warrior’ stelae of the Western Eurasia, transforming the popula- Iberian Peninsula could undoubtedly also tions of regions including Southern Scan- be expressed in words. -
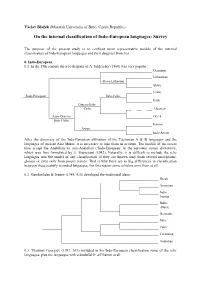
Internal Classification of Indo-European Languages: Survey
Václav Blažek (Masaryk University of Brno, Czech Republic) On the internal classification of Indo-European languages: Survey The purpose of the present study is to confront most representative models of the internal classification of Indo-European languages and their daughter branches. 0. Indo-European 0.1. In the 19th century the tree-diagram of A. Schleicher (1860) was very popular: Germanic Lithuanian Slavo-Lithuaian Slavic Celtic Indo-European Italo-Celtic Italic Graeco-Italo- -Celtic Albanian Aryo-Graeco- Greek Italo-Celtic Iranian Aryan Indo-Aryan After the discovery of the Indo-European affiliation of the Tocharian A & B languages and the languages of ancient Asia Minor, it is necessary to take them in account. The models of the recent time accept the Anatolian vs. non-Anatolian (‘Indo-European’ in the narrower sense) dichotomy, which was first formulated by E. Sturtevant (1942). Naturally, it is difficult to include the relic languages into the model of any classification, if they are known only from several inscriptions, glosses or even only from proper names. That is why there are so big differences in classification between these scantily recorded languages. For this reason some scholars omit them at all. 0.2. Gamkrelidze & Ivanov (1984, 415) developed the traditional ideas: Greek Armenian Indo- Iranian Balto- -Slavic Germanic Italic Celtic Tocharian Anatolian 0.3. Vladimir Georgiev (1981, 363) included in his Indo-European classification some of the relic languages, plus the languages with a doubtful IE affiliation at all: Tocharian Northern Balto-Slavic Germanic Celtic Ligurian Italic & Venetic Western Illyrian Messapic Siculian Greek & Macedonian Indo-European Central Phrygian Armenian Daco-Mysian & Albanian Eastern Indo-Iranian Thracian Southern = Aegean Pelasgian Palaic Southeast = Hittite; Lydian; Etruscan-Rhaetic; Elymian = Anatolian Luwian; Lycian; Carian; Eteocretan 0.4. -

CHAPTER SEVENTEEN History of the German Language 1 Indo
CHAPTER SEVENTEEN History of the German Language 1 Indo-European and Germanic Background Indo-European Background It has already been mentioned in this course that German and English are related languages. Two languages can be related to each other in much the same way that two people can be related to each other. If two people share a common ancestor, say their mother or their great-grandfather, then they are genetically related. Similarly, German and English are genetically related because they share a common ancestor, a language which was spoken in what is now northern Germany sometime before the Angles and the Saxons migrated to England. We do not have written records of this language, unfortunately, but we have a good idea of what it must have looked and sounded like. We have arrived at our conclusions as to what it looked and sounded like by comparing the sounds of words and morphemes in earlier written stages of English and German (and Dutch) and in modern-day English and German dialects. As a result of the comparisons we are able to reconstruct what the original language, called a proto-language, must have been like. This particular proto-language is usually referred to as Proto-West Germanic. The method of reconstruction based on comparison is called the comparative method. If faced with two languages the comparative method can tell us one of three things: 1) the two languages are related in that both are descended from a common ancestor, e.g. German and English, 2) the two are related in that one is the ancestor of the other, e.g. -

Indo-European Languages and Branches
Indo-European languages and branches Language Relations One of the first hurdles anyone encounters in studying a foreign language is learning a new vocabulary. Faced with a list of words in a foreign language, we instinctively scan it to see how many of the words may be like those of our own language.We can provide a practical example by surveying a list of very common words in English and their equivalents in Dutch, Czech, and Spanish. A glance at the table suggests that some words are more similar to their English counterparts than others and that for an English speaker the easiest or at least most similar vocabulary will certainly be that of Dutch. The similarities here are so great that with the exception of the words for ‘dog’ (Dutch hond which compares easily with English ‘hound’) and ‘pig’ (where Dutch zwijn is the equivalent of English ‘swine’), there would be a nearly irresistible temptation for an English speaker to see Dutch as a bizarrely misspelled variety of English (a Dutch reader will no doubt choose to reverse the insult). When our myopic English speaker turns to the list of Czech words, he discovers to his pleasant surprise that he knows more Czech than he thought. The Czech words bratr, sestra,and syn are near hits of their English equivalents. Finally, he might be struck at how different the vocabulary of Spanish is (except for madre) although a few useful correspondences could be devised from the list, e.g. English pork and Spanish puerco. The exercise that we have just performed must have occurred millions of times in European history as people encountered their neighbours’ languages. -

Galen's Legacy in Alexandrian Texts Written in Greek, Latin, And
chapter 3 Galen’s Legacy in Alexandrian Texts Written in Greek, Latin, and Arabic Ivan Garofalo From the end of the fifth and throughout the sixth century,1 a medical school with a philosophical framework was active in the Egyptian city of Alexandria.2 A selection was made from the available works of Galen to form a clearly de- fined curriculum for the students, divided into various courses.3 In the process of selection, Galenic works were commented on, summarised, and reduced to schemata and synopses. Subsequent decades saw a number of new studies and editions of texts connected to this tradition. This rich legacy shaped a substan- tial part of the transmission and reception of Galenic thought. The Alexandrian canon of Galenic works consists of sixteen single works or groups of works. Many Alexandrian physicians had already written com- mentaries on these works from as early as the fifth century.4 The clearest 1 The floruit of Gesios, the earliest commentator, is from around the beginning of the sixth century. John of Alexandria and Stephen are probably a generation or two later than Gesios, whom they quote. All translations into English are my own unless otherwise stated. 2 A useful presentation of the topic of this chapter is in Palmieri (2002). For textual criticism concerning the Alexandrian production, see Garofalo (2003a). For a general survey, see Duffy (1984). On late antique Alexandria, see Harris and Ruffini (2004); Pormann (2010: 419–21); Roueché (1991). For archaeological evidence, see Majcherek (2008). The professors of medi- cine who taught in Alexandria were called iatrosophistae; see Baldwin (1984). -

The Esperantist Background of René De Saussure's Work
Chapter 1 The Esperantist background of René de Saussure’s work Marc van Oostendorp Radboud University and The Meertens Institute ené de Saussure was arguably more an esperantist than a linguist – R somebody who was primarily inspired by his enthusiasm for the language of L. L. Zamenhof, and the hope he thought it presented for the world. His in- terest in general linguistics seems to have stemmed from his wish to show that the structure of Esperanto was better than that of its competitors, and thatit reflected the ways languages work in general. Saussure became involved in the Esperanto movement around 1906, appar- ently because his brother Ferdinand had asked him to participate in an inter- national Esperanto conference in Geneva; Ferdinand himself did not want to go because he did not want to become “compromised” (Künzli 2001). René be- came heavily involved in the movement, as an editor of the Internacia Scienca Re- vuo (International Science Review) and the national journal Svisa Espero (Swiss Hope), as well as a member of the Akademio de Esperanto, the Academy of Es- peranto that was and is responsible for the protection of the norms of the lan- guage. Among historians of the Esperanto movement, he is also still known as the inventor of the spesmilo, which was supposed to become an international currency among Esperantists (Garvía 2015). At the time, the interest in issues of artificial language solutions to perceived problems in international communication was more widespread in scholarly cir- cles than it is today. In the western world, German was often used as a language of e.g. -
Last Name First Name Middle Name Taken Test Registered License
As of 12:00 am on Thursday, December 14, 2017 Last Name First Name Middle Name Taken Test Registered License Richter Sara May Yes Yes Silver Matthew A Yes Yes Griffiths Stacy M Yes Yes Archer Haylee Nichole Yes Yes Begay Delores A Yes Yes Gray Heather E Yes Yes Pearson Brianna Lee Yes Yes Conlon Tyler Scott Yes Yes Ma Shuang Yes Yes Ott Briana Nichole Yes Yes Liang Guopeng No Yes Jung Chang Gyo Yes Yes Carns Katie M Yes Yes Brooks Alana Marie Yes Yes Richardson Andrew Yes Yes Livingston Derek B Yes Yes Benson Brightstar Yes Yes Gowanlock Michael Yes Yes Denny Racheal N No Yes Crane Beverly A No Yes Paramo Saucedo Jovanny Yes Yes Bringham Darren R Yes Yes Torresdal Jack D Yes Yes Chenoweth Gregory Lee Yes Yes Bolton Isabella Yes Yes Miller Austin W Yes Yes Enriquez Jennifer Benise Yes Yes Jeplawy Joann Rose Yes Yes Harward Callie Ruth Yes Yes Saing Jasmine D Yes Yes Valasin Christopher N Yes Yes Roegge Alissa Beth Yes Yes Tiffany Briana Jekel Yes Yes Davis Hannah Marie Yes Yes Smith Amelia LesBeth Yes Yes Petersen Cameron M Yes Yes Chaplin Jeremiah Whittier Yes Yes Sabo Samantha Yes Yes Gipson Lindsey A Yes Yes Bath-Rosenfeld Robyn J Yes Yes Delgado Alonso No Yes Lackey Rick Howard Yes Yes Brockbank Taci Ann Yes Yes Thompson Kaitlyn Elizabeth No Yes Clarke Joshua Isaiah Yes Yes Montano Gabriel Alonzo Yes Yes England Kyle N Yes Yes Wiman Charlotte Louise Yes Yes Segay Marcinda L Yes Yes Wheeler Benjamin Harold Yes Yes George Robert N Yes Yes Wong Ann Jade Yes Yes Soder Adrienne B Yes Yes Bailey Lydia Noel Yes Yes Linner Tyler Dane Yes Yes -

Europaio: a Brief Grammar of the European Language Reconstruct Than the Individual Groupings
1. Introduction 1.1. The Indo-European 1. The Indo-European languages are a family of several hundred languages and dialects, including most of the major languages of Europe, as well as many in South Asia. Contemporary languages in this family include English, German, French, Spanish, Countries with IE languages majority in orange. In Portuguese, Hindustani (i.e., mainly yellow, countries in which have official status. [© gfdl] Hindi and Urdu) and Russian. It is the largest family of languages in the world today, being spoken by approximately half the world's population as their mother tongue, while most of the other half speak at least one of them. 2. The classification of modern IE dialects into languages and dialects is controversial, as it depends on many factors, such as the pure linguistic ones (most of the times being the least important of them), the social, economic, political and historical ones. However, there are certain common ancestors, some of them old, well-attested languages (or language systems), as Classic Latin for Romance languages (such as French, Spanish, Portuguese, Italian, Rumanian or Catalan), Classic Sanskrit for the Indo-Aryan languages or Classic Greek for present-day Greek. Furthermore, there are other, still older -some of them well known- dialects from which these old language systems were derived and later systematized, which are, following the above examples, Archaic Latin, Archaic Sanskrit and Archaic Greek, also attested in older compositions and inscriptions. And there are, finally, old related dialects which help develop a Proto-Language, as the Faliscan (and Osco-Umbrian for many scholars) for Latino-Faliscan (Italic for many), the Avestan for Indo-Iranian or the Mycenaean for Proto-Greek.