Methods and Systems for Understanding Large-Scale Internet Threats
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Challenges and Benefits of Web 2.0-Based Learning Among International Students of English During the Covid-19 Pandemic in Cyprus
Arab World English Journal (AWEJ) Special Issue on Covid 19 Challenges April 2021 Pp.295-306 DOI: https://dx.doi.org/10.24093/awej/covid.22 Challenges and Benefits of Web 2.0-based Learning among International Students of English during the Covid-19 Pandemic in Cyprus Isyaku Hassan Faculty of Languages and Communication Universiti Sultan Zainal Abidin, Kuala Terengganu, Malaysia Musa BaraU Gamji Department of Mass Communication Ahmadu Bello University, Zaria, Kaduna State, Nigeria Eastern Medtrenian University (EMU), Cyprus Corresponding Author: [email protected] Qaribu Yahaya Nasidi Department of Mass Communication Ahmadu Bello University, Zaria, Kaduna State, Nigeria Mohd Nazri Latiff Azmi Faculty of Languages and Communication Universiti Sultan Zainal Abidin, Kuala Terengganu, Malaysia Received: 2/15/2021 Accepted: 3/2/2021 Published: 4/26/2021 Abstract There has been an increased reliance on Web-based learning, particularly in higher learning institutions, due to the outbreak of Covid-19. However, learners require knowledge and skills on how to use Web 2.0- based learning tools. Thus, there is a need to focus on how Web-based tools can be used to enhance learning outcomes. Therefore, this study aims to explore the challenges and benefits of Web 2.0-based learning among international students of English as a Second Language (ESL) at the Eastern Mediterranean University (EMU), North Cyprus during the Covid-19 pandemic. The data were collected from a purposive sample of 15 ESL learners at EMU using focus group interviews. The interview data were analyzed using inductive thematic analysis. The findings showed that challenges faced by international students of English at EMU during the Covid-19 pandemic include inadequate knowledge of technology and technical issues such as poor internet connectivity, inability to upload large files, and loss of password. -

The Role of User Generated Content (UGC) in Social Media for Tourism Sector
The 2013 WEI International Academic Conference Proceedings Istanbul, Turkey The Role of User Generated Content (UGC) in Social Media for Tourism Sector KhairulHilmi A Manap Phd Candidate [email protected] Nor Azura Adzharudin (PhD) Faculty of Modern Languages & Communication Universiti Putra Malaysia, Serdang, Selangor Malaysia [email protected] Abstract The existence of social media has marked a substantial milestone in the way both business enterprises and government agencies communicate and engage with their demographic markets. Social media has essentially revolutionized our communication patterns and behavior through the Internet, thus creating a new medium in which we consume and disseminate information. This paper will disclose and describe how social media can help the tourism industry leverage on User-Generated Content (UGC) generated by social media services to strategically position tourism based products and services. This paper focuses on the role of social media and its relation to the hospitality and tourism industry. This paper examines the perspective of travelers who search for online information via social media channels and make well-informed decisions of their travel based on user-generated content (UGC). The authenticity and credibility of user-generated content is also explored and discussed in this paper. This paper highlights both the benefits and issues encountered during the process of UGC to make travel decisions. The recommendation suggest that although social media channels are popular, they are not yet considered to be as a credible or trustworthy as incumbent sources of travel information. UGC plays the role as an additional source of information that travelers consider as part of their search information process, rather than as the only source of information. -

Global Connectivity and Multilinguals in the Twitter Network
Global Connectivity and Multilinguals in the Twitter Network Scott A. Hale Oxford Internet Institute, University of Oxford 1 St Giles, Oxford OX1 3JS, UK [email protected] ABSTRACT the Twitter mentions and retweet network to assess the extent This article analyzes the global connectivity of the Twitter to which language structures the network and asks whether retweet and mentions network and the role of multilingual multilingual users form cross-language bridges for informa- users engaging with content in multiple languages. The net- tion exchange that provide unique connections without which work is heavily structured by language with most mentions the network would break apart. The study finds language is a and retweets directed to users writing in the same language. key force structuring ties in the network, but that multilingual Users writing in multiple languages are more active, author- users are an important case to design for: over 10% of users ing more tweets than monolingual users. These multilingual engage with content in multiple languages and these users users play an important bridging role in the global connectiv- are more active than their monolingual counterparts. There ity of the network. The mean level of insularity from speak- is thus value in a single multilingual system, and language ers in each language does not correlate straightforwardly with should not be used as an absolute (i.e. only ever returning the size of the user base as predicted by previous research. Fi- search results or recommending friends in the main language nally, the English language does play more of a bridging role of the user). -

The Connectivity Doctrine: a Critique of Techo-Utopian Discourse, Liberal Governmentality, and the Colonization of Cyberspace
DePaul University Via Sapientiae College of Liberal Arts & Social Sciences Theses and Dissertations College of Liberal Arts and Social Sciences 8-2012 The connectivity doctrine: A critique of techo-utopian discourse, liberal governmentality, and the colonization of cyberspace Geoffrey S. Pettys DePaul University, [email protected] Follow this and additional works at: https://via.library.depaul.edu/etd Recommended Citation Pettys, Geoffrey S., "The connectivity doctrine: A critique of techo-utopian discourse, liberal governmentality, and the colonization of cyberspace" (2012). College of Liberal Arts & Social Sciences Theses and Dissertations. 131. https://via.library.depaul.edu/etd/131 This Thesis is brought to you for free and open access by the College of Liberal Arts and Social Sciences at Via Sapientiae. It has been accepted for inclusion in College of Liberal Arts & Social Sciences Theses and Dissertations by an authorized administrator of Via Sapientiae. For more information, please contact [email protected]. The Connectivity Doctrine: A Critique of Techno-Utopian Discourse, Liberal-Governmentality, and the Colonization of Cyberspace A Thesis Presented in Partial Fulfillment of the Requirements for the Degree of Master of Arts August 2012 By Geoffrey S. Pettys Department of International Studies College of Liberal Arts and Sciences DePaul University Chicago, Illinois Table of Contents Acknowledgements 3 Introduction 4 Chapter Overview 6 Chapter I: The Connectivity Doctrine 9 1.1: The Connectivity Doctrine as Articulated -
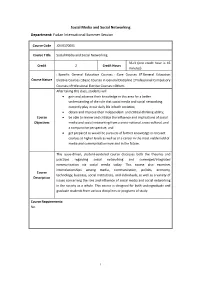
Social Media and Social Networking Department: Fudan International Summer Session
Social Media and Social Networking Department: Fudan International Summer Session Course Code JOUR170005 Course Title Social Media and Social Networking 36+3 (one credit hour is 45 Credit 2 Credit Hours minutes) □Specific General Education Courses □Core Courses ☑General Education Course Nature Elective Courses □Basic Courses in General Discipline □Professional Compulsory Courses □Professional Elective Courses □Others After taking this class, students will gain and advance their knowledge in this area for a better understanding of the role that social media and social networking currently play in our daily life in both societies; obtain and improve their independent- and critical-thinking ability; Course be able to review and criticize the influence and implications of social Objectives media and social networking from a cross-national, cross-cultural, and a comparative perspective; and get prepared as would-be pursuers of further knowledge in relevant courses at higher levels as well as of a career in the most viable field of media and communication now and in the future. This issue-driven, student-centered course discusses both the theories and practices regarding social networking and converged/integrated communication via social media today. This course also examines interrelationships among media, communication, politics, economy, Course technology, business, social institutions, and individuals, as well as a variety of Description issues concerning the role and influence of social media and social networking in the society as a whole. This course is designed for both undergraduate and graduate students from various disciplines or programs of study. Course Requirements: No. 1 Teaching Methods: This course is devoted to creating a student-centered learning environment, by adopting a balanced approach to covering both the breadth and depth of the subjects. -

Chipping Away at Censorship Firewalls with User-Generated Content
Chipping Away at Censorship Firewalls with User-Generated Content Sam Burnett, Nick Feamster, and Santosh Vempala School of Computer Science, Georgia Tech fsburnett, feamster, [email protected] Abstract For example, Pakistan recently blocked YouTube [47]. Content deemed offensive by the government has been Oppressive regimes and even democratic governments blocked in Turkey [48]. The Chinese government reg- restrict Internet access. Existing anti-censorship systems ularly blocks activist websites [37], even as China has often require users to connect through proxies, but these become the country with the most Internet users [19]; systems are relatively easy for a censor to discover and more recently, China has filtered popular content sites block. This paper offers a possible next step in the cen- such as Facebook and Twitter, and even require their sorship arms race: rather than relying on a single system users to register to visit certain sites [43]. Even demo- or set of proxies to circumvent censorship firewalls, we cratic countries such as the United Kingdom and Aus- explore whether the vast deployment of sites that host tralia have recently garnered attention with controversial user-generated content can breach these firewalls. To ex- filtering practices [35, 54, 55]; South Korea’s president plore this possibility, we have developed Collage, which recently considered monitoring Web traffic for political allows users to exchange messages through hidden chan- opposition [31]. nels in sites that host user-generated content. Collage has Although existing anti-censorship systems—notably, two components: a message vector layer for embedding onion routing systems such as Tor [18]—have allowed content in cover traffic; and a rendezvous mechanism citizens some access to censored information, these sys- to allow parties to publish and retrieve messages in the tems require users outside the censored regime to set up cover traffic. -

Understanding User-Generated Content on Social Media
Wright State University CORE Scholar Browse all Theses and Dissertations Theses and Dissertations 2010 Understanding User-Generated Content on Social Media Bala Meenakshi Nagarajan Wright State University Follow this and additional works at: https://corescholar.libraries.wright.edu/etd_all Part of the Computer Engineering Commons, and the Computer Sciences Commons Repository Citation Nagarajan, Bala Meenakshi, "Understanding User-Generated Content on Social Media" (2010). Browse all Theses and Dissertations. 1008. https://corescholar.libraries.wright.edu/etd_all/1008 This Dissertation is brought to you for free and open access by the Theses and Dissertations at CORE Scholar. It has been accepted for inclusion in Browse all Theses and Dissertations by an authorized administrator of CORE Scholar. For more information, please contact [email protected]. Understanding User-Generated Content on Social Media Dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy By BALA MEENAKSHI NAGARAJAN (Signature of Student) 2010 Wright State University COPYRIGHT BY BALA MEENAKSHI NAGARAJAN 2010 WRIGHT STATE UNIVERSITY SCHOOL OF GRADUATE STUDIES August 18, 2010 I HEREBY RECOMMEND THAT THE DISSERTATION PREPARED UNDER MY SUPER- VISION BY Meenakshi Nagarajan ENTITLED Understanding User-generated Content on Social Media BE ACCEPTED IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF Doctor of Philosophy. Amit P. Sheth, Ph.D. Dissertation Director Arthur Ardeshir Goshtasby, Ph.D. Director, Computer Science and Engineering Ph.D. Program Andrew T. Hsu, Ph.D. Dean, School of Graduate Studies Committee on Final Examination John M. Flach, Ph.D. Daniel Gruhl, Ph.D. Michael L. Raymer, Ph.D. Shaojun Wang, Ph.D. -

Jose Van Dijck: Culture of Connectivity: a Critical History of Social Media
http://www.diva-portal.org This is the published version of a paper published in Mediekultur. Citation for the original published paper (version of record): Kaun, A. (2014) Jose van Dijck: Culture of Connectivity: A Critical History of Social Media. Oxford: Oxford University Press. 2013. Mediekultur, 30(56): 195-197 Access to the published version may require subscription. N.B. When citing this work, cite the original published paper. Permanent link to this version: http://urn.kb.se/resolve?urn=urn:nbn:se:sh:diva-23531 MedieKultur | Journal of media and communication research | ISSN 1901-9726 Book Review Jose van Dijck: Culture of Connectivity: A Critical History of Social Media. Oxford: Oxford University Press. 2013 Anne Kaun MedieKultur 2014, 56, 204-206 Published by SMID | Society of Media researchers In Denmark | www.smid.dk The online version of this text can be found open access at www.mediekultur.dk In the beginning of the book, we get to know the Alvin family. Their everyday life story illustrates and makes tangible how social media are engrained in our everyday lives by now. And the Alvins are not alone: according to Jose van Dijck, there are 1.2 billion users logging on to social media sites worldwide as of December 2011. Social media that ideologically and technically embody the web 2.0 based on user-generated content have become one of the major forms of engaging online. Platforms such as YouTube, Wikipedia and Facebook are our daily companions. This initial, compelling narrative paves the way for an analysis of what Raymond Williams (1981) has called the structure of feeling namely that our culture is largely characterized by connectivity. -
Social Networks and the Diffusion of User-Generated Content: Evidence from Youtube
Published online ahead of print April 8, 2011 Information Systems Research informs ® Articles in Advance, pp. 1–19 doi 10.1287/isre.1100.0339 issn 1047-7047 eissn 1526-5536 © 2011 INFORMS Social Networks and the Diffusion of User-Generated Content: Evidence from YouTube Anjana Susarla Tepper School of Business, Carnegie Mellon University, Pittsburgh, Pennsylvania 15213, [email protected] Jeong-Ha Oh School of Management, University of Texas at Dallas, Richardson, Texas 52242, [email protected] Yong Tan Michael G. Foster School of Business, University of Washington, Seattle, Washington 98195, [email protected] his paper is motivated by the success of YouTube, which is attractive to content creators as well as corpo- Trations for its potential to rapidly disseminate digital content. The networked structure of interactions on YouTube and the tremendous variation in the success of videos posted online lends itself to an inquiry of the role of social influence. Using a unique data set of video information and user information collected from YouTube, we find that social interactions are influential not only in determining which videos become successful but also on the magnitude of that impact. We also find evidence for a number of mechanisms by which social influence is transmitted, such as (i) a preference for conformity and homophily and (ii) the role of social networks in guid- ing opinion formation and directing product search and discovery. Econometrically, the problem in identifying social influence is that individuals’ choices depend in great part upon the choices of other individuals, referred to as the reflection problem. Another problem in identification is to distinguish between social contagion and user heterogeneity in the diffusion process. -

The Marketer's Guide to User-Generated Content
The People-Powered Marketing Platform The Marketer’s Guide to User-Generated Content Best Practices for the Future of Brand Storytelling INTRODUCTION What’s the role of a brand when everyone is a storyteller? Your customers are media-empowered and highly vocal when it comes to their brand and product preferences. They don’t simply want a say in your marketing — they want a seat at the table. The million-dollar question: How can you mobilize them to drive business impact? This report aims to shed light on the rapidly evolving user-generated content landscape and provide tangible best practices for marketers navigating this new terrain. You’ll see that we’ve also provided some research around the impact of consumer-led stories, and even asked a few of our friends in the industry to weigh in with their own opinions on the state of UGC. Read on to learn why we believe the future of brand storytelling will be people-powered, and why in many ways, the future is now. ©CROWDTAP, THE PEOPLE-POWERED MARKETING PLATFORM 2015 2 CORP.CROWDTAP.COM • @CROWDTAP • REQUEST A DEMO: [email protected] INSIDE THIS REPORT 4 What is UGC? Defining the Emerging User-Generated Content Landscape 8 Why UGC? The Case for Elevating the Role of User-Generated Content in Your Marketing 16 UGC in Action Best Practices for Using Consumer Content to Fuel Earned, Owned & Paid CASE STUDY: Whirlpool Corporation CASE STUDY: ABSOLUT Vodka 27 Appendix Crowdtap Research: What Motivates People to Create & Share Digital Content ©CROWDTAP, THE PEOPLE-POWERED MARKETING PLATFORM 2015 3 CORP.CROWDTAP.COM • @CROWDTAP • REQUEST A DEMO: [email protected] WHAT IS UGC? Defining the Emerging User-Generated Content Landscape In its simplest form, user-generated content, or UGC, is media that has been created and/or shared online by a person. -

Digital Globalization: the New Era of Global Flows March 2016
DIGITAL GLOBALIZATION: THE NEW ERA OF GLOBAL FLOWS MARCH 2016 HIGHLIGHTS 43 73 85 Broadening participation Boosting productivity Changing the way and GDP companies go global In the 25 years since its founding, the McKinsey Global Institute (MGI) has sought to develop a deeper understanding of the evolving global economy. As the business and economics research arm of McKinsey & Company, MGI aims to provide leaders in the commercial, public, and social sectors with the facts and insights on which to base management and policy decisions. We are proud to be ranked the top private-sector think tank, according to the authoritative 2015 Global Go To Think Tank Index, an annual report issued by the University of Pennsylvania Think Tanks and Civil Societies Program at the Lauder Institute. MGI research combines the disciplines of economics and management, employing the analytical tools of economics with the insights of business leaders. Our “micro-to-macro” methodology examines microeconomic industry trends to better understand the broad macroeconomic forces affecting business strategy and public policy. MGI’s in-depth reports have covered more than 20 countries and 30 industries. Current research focuses on six themes: productivity and growth, natural resources, labor markets, the evolution of global financial markets, the economic impact of technology and innovation, and urbanization. Recent reports have assessed global flows; the economies of Brazil, Mexico, Nigeria, and Japan; China’s digital transformation; India’s path from poverty to empowerment; affordable housing; the effects of global debt; and the economics of tackling obesity. MGI is led by three McKinsey & Company directors: Richard Dobbs, James Manyika, and Jonathan Woetzel. -

Teaching and Learning with Twitter
Teaching and Learning with Twitter M I ed nf ia or a L m n it at d er i ac o y n digital classroom Teaching and Learning with Twitter 1 With the support of the Communication and Information Sector United Nations Educational, Scientific and Cultural Organization CREDITS This resource was produced by Twitter in collaboration with UNESCO. UNESCO’s objective in this collaboration is to promote media and information literacy learning. Special thanks to: Alton Grizzle, Programme Specialist, UNESCO 2 Teaching and Learning with Twitter Contents 02 Introduction 04 Getting Started on Twitter 06 Media & Information Literacy and Global Citizenship Education 08 Media & Information Literacy and Digital Citizenship 08 Digital etiquette 09 Dealing with Cyberbullying 10 Nurturing your Digital Footprints through Media & Information Literacy Footprints 11 Controlling your Digital Footprint 13 Controlling your Experience on Twitter 15 Media & Information Literacy Skills in the Digital Space 18 UNESCO’s Five Laws of Media & Information Literacy 21 Learning Activities for Educators and Development Actors Create your 22 Twitter: The Digital Staffroom own activities and Tweet them 23 Case Studies using #MILClicks to share your 26 Testimonials favorites with the rest of the world. 28 Hashtags 29 Appendix 1: Twitter 101 33 Appendix 2: Twitter Rules 34 Appendix 3: Media & Information Literacy Resources from UNESCO Teaching and Learning with Twitter 01 Introduction: Innovation for Better Learning Experiences and how it relates to global citizenship and digital “Innovation and ICT must citizenship education. Whether your focus is on be harnessed to strengthen media and information literacy (MIL) or nurturing good online habits, or other social competencies, education systems, there’ll be something here for you.