DIFUZZRTL: Differential Fuzz Testing to Find CPU Bugs
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
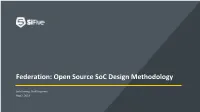
Federation Toolflow
Federation: Open Source SoC Design Methodology Jack Koenig, Staff Engineer Aug 3, 2019 Hardware Trends: Compute Needs are Changing e.g., machine learning But, CPUs are not getting faster! Source: Medium, Entering the world of Machine Learning 2 Hardware Trends: Custom Hardware to the Rescue! Custom Chips But, custom chip development GPUs (e.g., Google TPU) costs are too high! 3 How did turn into a $1B acquisition with only 13 employees?* 4 * https://www.sigarch.org/open-source-hardware-stone-soups-and-not-stone-statues-please Why do silicon projects need experts from at least 14+ disciplines just to get started? 6 <Your Name Here> Tech Stack Tech Stack Readily-Available Reusable Technology from techstacks.io Federation Tools Infrastructure Cloud Services 7 We Should Copy “Innovations” from the Software Industry open-source standards abstraction and code reuse composability and APIs productivity tooling commodity infrastructure 8 npm Enables Modular Web Development with Reusable Packages 9 Source: https://go.tiny.cloud/blog/a-guide-to-npm-the-node-js-package-manager/ npm Enables Javascript as Most Popular Programming Language • 830.000 of packages • 10 million users • 30 billion packages downloads per month • 90% of Web built of NPM packages • NPM used everywhere: client, server, mobile, IoT • Open source libraries availability is the major driving force for Language adoption [Leo2013] proven by NPM • 70+ programming languages can be transpiled into JS, WebAssembly and published on NPM 10 Federation: the action of forming states or organizations into a single group with centralized control, within which smaller divisions have some degree of internal autonomy 11 Federation: a suite of open-source tools that SiFive is using to orchestrate modular SoC design workflows 12 Federation Tools Enable a Modular SoC Design Methodology Federation Tools IP Package 1 IP Package 2 IP Package 3 1. -

Co-Simulation Between Cλash and Traditional Hdls
MASTER THESIS CO-SIMULATION BETWEEN CλASH AND TRADITIONAL HDLS Author: John Verheij Faculty of Electrical Engineering, Mathematics and Computer Science (EEMCS) Computer Architecture for Embedded Systems (CAES) Exam committee: Dr. Ir. C.P.R. Baaij Dr. Ir. J. Kuper Dr. Ir. J.F. Broenink Ir. E. Molenkamp August 19, 2016 Abstract CλaSH is a functional hardware description language (HDL) developed at the CAES group of the University of Twente. CλaSH borrows both the syntax and semantics from the general-purpose functional programming language Haskell, meaning that circuit de- signers can define their circuits with regular Haskell syntax. CλaSH contains a compiler for compiling circuits to traditional hardware description languages, like VHDL, Verilog, and SystemVerilog. Currently, compiling to traditional HDLs is one-way, meaning that CλaSH has no simulation options with the traditional HDLs. Co-simulation could be used to simulate designs which are defined in multiple lan- guages. With co-simulation it should be possible to use CλaSH as a verification language (test-bench) for traditional HDLs. Furthermore, circuits defined in traditional HDLs, can be used and simulated within CλaSH. In this thesis, research is done on the co-simulation of CλaSH and traditional HDLs. Traditional hardware description languages are standardized and include an interface to communicate with foreign languages. This interface can be used to include foreign func- tions, or to make verification and co-simulation possible. Because CλaSH also has possibilities to communicate with foreign languages, through Haskell foreign function interface (FFI), it is possible to set up co-simulation. The Verilog Procedural Interface (VPI), as defined in the IEEE 1364 standard, is used to set-up the communication and to control a Verilog simulator. -

Wdv-Notes Stand: 29.DEZ.1994 (2.) 329 Intel Pentium – Business Must Learn from the Debacle
wdv-notes Stand: 29.DEZ.1994 (2.) 329 Intel Pentium – Business Must Learn from the Debacle. Wiss.Datenverarbeitung © 1994–1995 Edited by Karl-Heinz Dittberner FREIE UNIVERSITÄT BERLIN Theo Die kanadische Monatszeitschrift The Im folgenden sowie in den wdv-notes verbreitet werden, wenn dabei die folgen- Computer Post, Winnipeg veröffentlicht Nr. 330 werden diese Artikel im Original den Spielregeln beachtet werden. in mehreren Artikeln in ihrer Januar-Aus- nachgedruckt. Der Dank dafür geht an Permission is hereby granted to copy gabe 1995 eine exzellente erste Zusam- Sylvia Douglas von The Computer Post, this article electronically or in any other menfassung des Debakels um den Defekt 301 – 68 Higgins Avenue, Winnipeg, Ma- form, provided it is reproduced without des Pentium-Mikroprozessors [1–2] des nitoba, Canada, Email: SDouglas@post. alteration, and you credit it to The Compu- Computergiganten Intel. mb.ca. Diese Artikel dürfen auch weiter- ter Post. Intel’s top of the line Pentium™ microproc- This particular error in the Pentium was in essor chip has turned out to have a slight flaw the floating-point divide unit. Intel manage- Editorial: The Computer Post – Jan.95 in its character: when dividing certain rare ment was concerned enough about it that pairs of floating point numbers, it gives the they pulled together a special team to assess The Way it Will Be wrong answer. For anyone who owns a Pen- the implications. tium-based computer, or was thinking about This month you’ll find we’re reporting a In the words of Andrew Grove, Intel’s CEO, buying one, or is just feeling curious, here lot of background information on Intel’s posting later to the Internet [3], “We were are.. -

Pyvsc: Systemverilog-Style Constraints and Coverage in Python
PyVSC: SystemVerilog-Style Constraints, and Coverage in Python M. Ballance Milwaukie, OR, USA [email protected] Abstract—Constrained-randomization and functional Coverage is captured as a set of individual coverpoint coverage are key elements in the widely-used SystemVerilog-based instances, and is not organized into covergroup types and verification flow. The use of Python in functional verification is instances in the same way that SystemVerilog does. growing in popularity, but Python has historically lacked support for the constraint and coverage features provided by B. SystemC SystemVerilog. This paper describes PyVSC, a library that SystemC has been one of the longer-lasting languages used provides these features. for modeling and verifying hardware that is built as an embedded domain-specific language within a general-purpose Keywords—functional verification, Python, constrained programming language (C++). While libraries for constraints random, functional coverage and coverage targeting SystemC are not directly applicable in I. INTRODUCTION Python, it’s worthwhile considering approaches taken. Verification flows based on constrained-random stimulus The SystemC Verification Library (SCV) provides basic generation and functional coverage collection have become randomizations and constraints, using a Binary Decision dominant where SystemVerilog is used for the testbench Diagram (BDD) solver. BDD-based constraint solvers are environment. Consequently, verification engineers have known to have performance and capacity challenges, especially significant experience with the constructs and patterns provided with sizable constraint spaces. No support for capturing by SystemVerilog. functional coverage is provided. There is growing interest in making use of Python in The CRAVE [4] library sought to bring higher performance verification environments – either as a complete verification and capacity to randomization in SystemC using Satifiability environment or as an adjunct to a SystemVerilog verification Modulo Theories (SMT) constraint solvers. -

PGAS Communication for Heterogeneous Clusters with Fpgas
PGAS Communication for Heterogeneous Clusters with FPGAs by Varun Sharma A thesis submitted in conformity with the requirements for the degree of Master of Applied Science Graduate Department of Electrical and Computer Engineering University of Toronto © Copyright 2020 by Varun Sharma Abstract PGAS Communication for Heterogeneous Clusters with FPGAs Varun Sharma Master of Applied Science Graduate Department of Electrical and Computer Engineering University of Toronto 2020 This work presents a heterogeneous communication library for generic clusters of processors and FPGAs. This library, Shoal, supports the partitioned global address space (PGAS) memory model for applications. PGAS is a shared memory model for clusters that creates a distinction between local and remote memory accesses. Through Shoal and its common application programming interface for hardware and software, applications can be more freely migrated to the optimal platform and deployed onto dynamic cluster topologies. The library is tested using a thorough suite of microbenchmarks to establish latency and throughput performance. We also show an implementation of the Jacobi method that demonstrates the ease with which applications can be moved between platforms to yield faster run times. ii Acknowledgements It takes a village to raise a child and about as many people to raise a thesis as well. Foremost, I would like to thank my supervisor, Paul Chow, for all that he’s done for me over the course of the four years that I’ve known him thus far. Thank you for accepting me as your student for my undergraduate thesis and not immediately rejecting me when I asked to pursue a Masters under your supervision as well. -

Detecting and Removing Malicious Hardware Automatically
Appears in Proceedings of the 31st IEEE Symposium on Security & Privacy (Oakland), May 2010 Overcoming an Untrusted Computing Base: Detecting and Removing Malicious Hardware Automatically Matthew Hicks, Murph Finnicum, Samuel T. King Milo M. K. Martin, Jonathan M. Smith University of Illinois at Urbana-Champaign University of Pennsylvania Abstract hardware-level vulnerabilities would likely require phys- ically replacing the compromised hardware components. The computer systems security arms race between at- A hardware recall similar to Intel’s Pentium FDIV bug tackers and defenders has largely taken place in the do- (which cost 500 million dollars to recall five million main of software systems, but as hardware complexity chips) has been estimated to cost many billions of dollars and design processes have evolved, novel and potent today [7]. Furthermore, the skill required to replace hard- hardware-based security threats are now possible. This ware and the rise of deeply embedded systems ensure paper presents a hybrid hardware/software approach to that vulnerable systems will remain in active use after the defending against malicious hardware. discovery of the vulnerability. Second, hardware is the We propose BlueChip, a defensive strategy that has lowest layer in the computer system, providing malicious both a design-time component and a runtime component. hardware with control over the software running above. During the design verification phase, BlueChip invokes This low-level control enables sophisticated and stealthy a new technique, unused circuit identification (UCI), attacks aimed at evading software-based defenses. to identify suspicious circuitry—those circuits not used Such an attack might use a special, or unlikely, event to or otherwise activated by any of the design verification trigger deeply buried malicious logic which was inserted tests. -

Lastlayer:Towards Hardware and Software Continuous Integration
1 LastLayer:Towards Hardware and Software Continuous Integration Luis Vega, Jared Roesch, Joseph McMahan, Luis Ceze. Paul G. Allen School of Computer Science & Engineering, University of Washington F Abstract—This paper presents LastLayer, an open-source tool1 that enables hardware and software continuous integration and simulation. Python Compared to traditional testing approaches based on the register transfer Scala level (RTL) abstraction, LastLayer provides a mechanism for testing RTL input signals Python Verilog designs with any programming language that supports the C RTL DSLs hardware foreign function interface (CFFI). Furthermore, it supports a generic C Scala RTL input signals design Verilog ports interface that allows external programs convenient access to storage RTL DSLs RTL output signals hardware resources such as registers and memories in the design as well as control design VHDL ports over the hardware simulation. Moreover, LastLayer achieves this software Verilog RTL output signals hardware tests integration without requiring any hardware modification and automatically VHDL generates language bindings for these storage resources according to user specification. Using LastLayer, we evaluated two representative hardware tests Python (a) Traditional RTL simulationDPI integration examples: a hardware adder written in Verilog operating reg_a Java DPIDPI over NumPy arrays, and a ReLu vector-accelerator written in Chisel Python reg_amem_a processing tensors from PyTorch. Racket Java DPIDPI CFFI mem_a mem_b Index terms— hardware simulation, hardware language inter- HaskellRacket DPI CFFI DPI mem_b LastLayer reg_b operability, agile hardware design HaskellRust DPI LastLayer reg_b JavaScriptRust hardware design 1 INTRODUCTION softwareJavaScript tests hardware design software tests From RISC-V [9] processors to domain-specific accelerators, both industry and academia have produced an outstanding number of (b) LastLayer simulation open-source hardware projects. -

Can the Computer Be Wrong?
Can the computer be wrong? Wojciech Myszka Department of Mechanics, Materials and Biomedical Engineering January 2021 1 Data 2 Human (operator) 3 Hardware (inevitable) 4 Hardware 5 Manufacturer fault 6 Software 7 Bug free software 8 List of software bugs Data Absolute error I I was talking about this in one of the previous lectures. I One of the main sources of errors are data. I Knowing the range of each value allows us to predict values of the result. I This can be difficult and tricky. I However, in most cases we assume that the data values are correct and believe in computer calculations. Human (operator) Operator I In general, it is difficult to take into account human errors. I These include: I not understanding the problem solved by the program, I errors in preparing input data, I wrong answer to the computer prompt, I ... Hardware (inevitable) Number of bits This is a quite different source of error. 1. Most of todays computers have I 32 or 64 bits processors 2. What does this mean? Number of bits — rangeI 1. The biggest integer value I 32 bits: from −231 to 231 − 1 (−2; 147; 483; 648 to 2; 147; 483; 647) or two billion, one hundred forty-seven million, four hundred eighty-three thousand, six hundred forty-seven I 64 bits: from −263 to 263 − 1 (−9; 223; 372; 036; 854; 775; 808 to 9; 223; 372; 036; 854; 775; 807) nine quintillion two hundred twenty three quadrillion three hundred seventy two trillion thirty six billion eight hundred fifty four million seven hundred seventy five thousand eight hundred and seven 2. -

Cocotb: a Python-Based Digital Logic Verification Framework
Cocotb: a Python-based digital logic verification framework Ben Rosser University of Pennsylvania December 11, 2018 Ben Rosser (Penn) Cocotb for CERN Microelectronics December 11, 2018 1 / 41 Introduction Cocotb is a library for digital logic verification in Python. Coroutine cosimulation testbench. Provides Python interface to control standard RTL simulators (Cadence, Questa, VCS, etc.) Offers an alternative to using Verilog/SystemVerilog/VHDL framework for verification. At Penn, we chose to use cocotb instead of UVM for verification last summer. This talk will cover: What cocotb is, what its name means, and how it works. What are the potential advantages of cocotb over UVM or a traditional testbench? What has Penn’s experience been like using cocotb? Ben Rosser (Penn) Cocotb for CERN Microelectronics December 11, 2018 2 / 41 Introduction: Disclaimer Disclaimer: I am not a UVM expert! My background is in physics and computer science, not hardware or firmware design. During my first year at Penn, I spent some time trying to learn UVM, but we decided to try out cocotb soon afterward. I can talk about what made us want an alternative to UVM, but I cannot provide a perfect comparison between the two. Ben Rosser (Penn) Cocotb for CERN Microelectronics December 11, 2018 3 / 41 What is Cocotb? Ben Rosser (Penn) Cocotb for CERN Microelectronics December 11, 2018 4 / 41 Approaches to Verification Why not just use Verilog or VHDL for verification? Hardware description languages are great for designing hardware or firmware. But hardware design and verification are different problems. Using the same language for both might not be optimal. -

A Hybrid-Parallel Architecture for Applications in Bioinformatics
A Hybrid-parallel Architecture for Applications in Bioinformatics M.Sc. Jan Christian Kässens Dissertation zur Erlangung des akademischen Grades Doktor der Ingenieurwissenschaften (Dr.-Ing.) der Technischen Fakultät der Christian-Albrechts-Universität zu Kiel eingereicht im Jahr 2017 Kiel Computer Science Series (KCSS) 2017/4 dated 2017-11-08 URN:NBN urn:nbn:de:gbv:8:1-zs-00000335-a3 ISSN 2193-6781 (print version) ISSN 2194-6639 (electronic version) Electronic version, updates, errata available via https://www.informatik.uni-kiel.de/kcss The author can be contacted via [email protected] Published by the Department of Computer Science, Kiel University Computer Engineering Group Please cite as: Ź Jan Christian Kässens. A Hybrid-parallel Architecture for Applications in Bioinformatics Num- ber 2017/4 in Kiel Computer Science Series. Department of Computer Science, 2017. Dissertation, Faculty of Engineering, Kiel University. @book{Kaessens17, author = {Jan Christian K\"assens}, title = {A Hybrid-parallel Architecture for Applications in Bioinformatics}, publisher = {Department of Computer Science, CAU Kiel}, year = {2017}, number = {2017/4}, doi = {10.21941/kcss/2017/4}, series = {Kiel Computer Science Series}, note = {Dissertation, Faculty of Engineering, Kiel University.} } © 2017 by Jan Christian Kässens ii About this Series The Kiel Computer Science Series (KCSS) covers dissertations, habilitation theses, lecture notes, textbooks, surveys, collections, handbooks, etc. written at the Department of Computer Science at Kiel University. It was initiated in 2011 to support authors in the dissemination of their work in electronic and printed form, without restricting their rights to their work. The series provides a unified appearance and aims at high-quality typography. The KCSS is an open access series; all series titles are electronically available free of charge at the department’s website. -

Latest Updates
The PoC-Library Documentation Release 1.2.0 Patrick Lehmann, Thomas B. Preusser, Martin Zabel Sep 11, 2018 Introduction I Introduction1 1 What is PoC? 5 1.1 What is the History of PoC?.....................................6 1.2 Which Tool Chains are supported?..................................6 1.3 Why should I use PoC?.......................................7 1.4 Who uses PoC?............................................7 2 Quick Start Guide 9 2.1 Requirements and Dependencies...................................9 2.2 Download............................................... 10 2.3 Configuring PoC on a Local System................................. 10 2.4 Integration.............................................. 10 2.5 Run a Simulation........................................... 12 2.6 Run a Synthesis........................................... 13 2.7 Updating............................................... 13 3 Get Involved 15 3.1 Report a Bug............................................. 15 3.2 Feature Request........................................... 15 3.3 Talk to us on Gitter.......................................... 15 3.4 Contributers License Agreement................................... 16 3.5 Contribute to PoC.......................................... 16 3.6 Give us Feedback........................................... 18 3.7 List of Contributers.......................................... 18 4 Apache License 2.0 19 4.1 1. Definitions............................................. 19 4.2 2. Grant of Copyright License.................................... -
P5 (Microarchitecture)
P5 (microarchitecture) The Intel P5 Pentium family Produced From 1993 to 1999 Common manufacturer(s) • Intel Max. CPU clock rate 60 MHz to 300 MHz FSB speeds 50 MHz to 66 MHz Min. feature size 0.8pm to 0.25pm Instruction set x86 Socket(s) • Socket 4, Socket 5, Socket 7 Core name(s) P5. P54C, P54CS, P55C, Tillamook The original Pentium microprocessor was introduced on March 22, 1993.^^ Its microarchitecture, deemed P5, was Intel's fifth-generation and first superscalar x86 microarchitecture. As a direct extension of the 80486 architecture, it included dual integer pipelines, a faster FPU, wider data bus, separate code and data caches and features for further reduced address calculation latency. In 1996, the Pentium with MMX Technology (often simply referred to as Pentium MMX) was introduced with the same basic microarchitecture complemented with an MMX instruction set, larger caches, and some other enhancements. The P5 Pentium competitors included the Motorola 68060 and the PowerPC 601 as well as the SPARC, MIPS, and Alpha microprocessor families, most of which also used a superscalar in-order dual instruction pipeline configuration at some time. Intel's Larrabee multicore architecture project uses a processor core derived from a P5 core (P54C), augmented by multithreading, 64-bit instructions, and a 16-wide vector processing unit. T31 Intel's low-powered Bonnell [4i microarchitecture employed in Atom processor cores also uses an in-order dual pipeline similar to P5. Development The P5 microarchitecture was designed by the same Santa Clara team which designed the 386 and 486.^ Design work started in 1989;^ the team decided to use a superscalar architecture, with on-chip cache, floating-point, and branch prediction.