Proposal for a Devanagari Script Root Zone Label Generation Rule-Set (LGR)
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Assessment of Options for Handling Full Unicode Character Encodings in MARC21 a Study for the Library of Congress
1 Assessment of Options for Handling Full Unicode Character Encodings in MARC21 A Study for the Library of Congress Part 1: New Scripts Jack Cain Senior Consultant Trylus Computing, Toronto 1 Purpose This assessment intends to study the issues and make recommendations on the possible expansion of the character set repertoire for bibliographic records in MARC21 format. 1.1 “Encoding Scheme” vs. “Repertoire” An encoding scheme contains codes by which characters are represented in computer memory. These codes are organized according to a certain methodology called an encoding scheme. The list of all characters so encoded is referred to as the “repertoire” of characters in the given encoding schemes. For example, ASCII is one encoding scheme, perhaps the one best known to the average non-technical person in North America. “A”, “B”, & “C” are three characters in the repertoire of this encoding scheme. These three characters are assigned encodings 41, 42 & 43 in ASCII (expressed here in hexadecimal). 1.2 MARC8 "MARC8" is the term commonly used to refer both to the encoding scheme and its repertoire as used in MARC records up to 1998. The ‘8’ refers to the fact that, unlike Unicode which is a multi-byte per character code set, the MARC8 encoding scheme is principally made up of multiple one byte tables in which each character is encoded using a single 8 bit byte. (It also includes the EACC set which actually uses fixed length 3 bytes per character.) (For details on MARC8 and its specifications see: http://www.loc.gov/marc/.) MARC8 was introduced around 1968 and was initially limited to essentially Latin script only. -

Writing Systems Reading and Spelling
Writing systems Reading and spelling Writing systems LING 200: Introduction to the Study of Language Hadas Kotek February 2016 Hadas Kotek Writing systems Writing systems Reading and spelling Outline 1 Writing systems 2 Reading and spelling Spelling How we read Slides credit: David Pesetsky, Richard Sproat, Janice Fon Hadas Kotek Writing systems Writing systems Reading and spelling Writing systems What is writing? Writing is not language, but merely a way of recording language by visible marks. –Leonard Bloomfield, Language (1933) Hadas Kotek Writing systems Writing systems Reading and spelling Writing systems Writing and speech Until the 1800s, writing, not spoken language, was what linguists studied. Speech was often ignored. However, writing is secondary to spoken language in at least 3 ways: Children naturally acquire language without being taught, independently of intelligence or education levels. µ Many people struggle to learn to read. All human groups ever encountered possess spoken language. All are equal; no language is more “sophisticated” or “expressive” than others. µ Many languages have no written form. Humans have probably been speaking for as long as there have been anatomically modern Homo Sapiens in the world. µ Writing is a much younger phenomenon. Hadas Kotek Writing systems Writing systems Reading and spelling Writing systems (Possibly) Independent Inventions of Writing Sumeria: ca. 3,200 BC Egypt: ca. 3,200 BC Indus Valley: ca. 2,500 BC China: ca. 1,500 BC Central America: ca. 250 BC (Olmecs, Mayans, Zapotecs) Hadas Kotek Writing systems Writing systems Reading and spelling Writing systems Writing and pictures Let’s define the distinction between pictures and true writing. -

Part 1: Introduction to The
PREVIEW OF THE IPA HANDBOOK Handbook of the International Phonetic Association: A guide to the use of the International Phonetic Alphabet PARTI Introduction to the IPA 1. What is the International Phonetic Alphabet? The aim of the International Phonetic Association is to promote the scientific study of phonetics and the various practical applications of that science. For both these it is necessary to have a consistent way of representing the sounds of language in written form. From its foundation in 1886 the Association has been concerned to develop a system of notation which would be convenient to use, but comprehensive enough to cope with the wide variety of sounds found in the languages of the world; and to encourage the use of thjs notation as widely as possible among those concerned with language. The system is generally known as the International Phonetic Alphabet. Both the Association and its Alphabet are widely referred to by the abbreviation IPA, but here 'IPA' will be used only for the Alphabet. The IPA is based on the Roman alphabet, which has the advantage of being widely familiar, but also includes letters and additional symbols from a variety of other sources. These additions are necessary because the variety of sounds in languages is much greater than the number of letters in the Roman alphabet. The use of sequences of phonetic symbols to represent speech is known as transcription. The IPA can be used for many different purposes. For instance, it can be used as a way to show pronunciation in a dictionary, to record a language in linguistic fieldwork, to form the basis of a writing system for a language, or to annotate acoustic and other displays in the analysis of speech. -

South Asian Art a Resource for Classroom Teachers
South Asian Art A Resource for Classroom Teachers South Asian Art A Resource for Classroom Teachers Contents 2 Introduction 3 Acknowledgments 4 Map of South Asia 6 Religions of South Asia 8 Connections to Educational Standards Works of Art Hinduism 10 The Sun God (Surya, Sun God) 12 Dancing Ganesha 14 The Gods Sing and Dance for Shiva and Parvati 16 The Monkeys and Bears Build a Bridge to Lanka 18 Krishna Lifts Mount Govardhana Jainism 20 Harinegameshin Transfers Mahavira’s Embryo 22 Jina (Jain Savior-Saint) Seated in Meditation Islam 24 Qasam al-Abbas Arrives from Mecca and Crushes Tahmasp with a Mace 26 Prince Manohar Receives a Magic Ring from a Hermit Buddhism 28 Avalokiteshvara, Bodhisattva of Compassion 30 Vajradhara (the source of all teachings on how to achieve enlightenment) CONTENTS Introduction The Philadelphia Museum of Art is home to one of the most important collections of South Asian and Himalayan art in the Western Hemisphere. The collection includes sculptures, paintings, textiles, architecture, and decorative arts. It spans over two thousand years and encompasses an area of the world that today includes multiple nations and nearly a third of the planet’s population. This vast region has produced thousands of civilizations, birthed major religious traditions, and provided fundamental innovations in the arts and sciences. This teaching resource highlights eleven works of art that reflect the diverse cultures and religions of South Asia and the extraordinary beauty and variety of artworks produced in the region over the centuries. We hope that you enjoy exploring these works of art with your students, looking closely together, and talking about responses to what you see. -

Proposal for a Kannada Script Root Zone Label Generation Ruleset (LGR)
Proposal for a Kannada Script Root Zone Label Generation Ruleset (LGR) Proposal for a Kannada Script Root Zone Label Generation Ruleset (LGR) LGR Version: 3.0 Date: 2019-03-06 Document version: 2.6 Authors: Neo-Brahmi Generation Panel [NBGP] 1. General Information/ Overview/ Abstract The purpose of this document is to give an overview of the proposed Kannada LGR in the XML format and the rationale behind the design decisions taken. It includes a discussion of relevant features of the script, the communities or languages using it, the process and methodology used and information on the contributors. The formal specification of the LGR can be found in the accompanying XML document: proposal-kannada-lgr-06mar19-en.xml Labels for testing can be found in the accompanying text document: kannada-test-labels-06mar19-en.txt 2. Script for which the LGR is Proposed ISO 15924 Code: Knda ISO 15924 N°: 345 ISO 15924 English Name: Kannada Latin transliteration of the native script name: Native name of the script: ಕನ#ಡ Maximal Starting Repertoire (MSR) version: MSR-4 Some languages using the script and their ISO 639-3 codes: Kannada (kan), Tulu (tcy), Beary, Konkani (kok), Havyaka, Kodava (kfa) 1 Proposal for a Kannada Script Root Zone Label Generation Ruleset (LGR) 3. Background on Script and Principal Languages Using It 3.1 Kannada language Kannada is one of the scheduled languages of India. It is spoken predominantly by the people of Karnataka State of India. It is one of the major languages among the Dravidian languages. Kannada is also spoken by significant linguistic minorities in the states of Andhra Pradesh, Telangana, Tamil Nadu, Maharashtra, Kerala, Goa and abroad. -

Writing Systems: Their Properties and Implications for Reading
Writing Systems: Their Properties and Implications for Reading Brett Kessler and Rebecca Treiman doi:10.1093/oxfordhb/9780199324576.013.1 Draft of a chapter to appear in: The Oxford Handbook of Reading, ed. by Alexander Pollatsek and Rebecca Treiman. ISBN 9780199324576. Abstract An understanding of the nature of writing is an important foundation for studies of how people read and how they learn to read. This chapter discusses the characteristics of modern writing systems with a view toward providing that foundation. We consider both the appearance of writing systems and how they function. All writing represents the words of a language according to a set of rules. However, important properties of a language often go unrepresented in writing. Change and variation in the spoken language result in complex links to speech. Redundancies in language and writing mean that readers can often get by without taking in all of the visual information. These redundancies also mean that readers must often supplement the visual information that they do take in with knowledge about the language and about the world. Keywords: writing systems, script, alphabet, syllabary, logography, semasiography, glottography, underrepresentation, conservatism, graphotactics The goal of this chapter is to examine the characteristics of writing systems that are in use today and to consider the implications of these characteristics for how people read. As we will see, a broad understanding of writing systems and how they work can place some important constraints on our conceptualization of the nature of the reading process. It can also constrain our theories about how children learn to read and about how they should be taught to do so. -

Proposal for a Gujarati Script Root Zone Label Generation Ruleset (LGR)
Proposal for a Gujarati Root Zone LGR Neo-Brahmi Generation Panel Proposal for a Gujarati Script Root Zone Label Generation Ruleset (LGR) LGR Version: 3.0 Date: 2019-03-06 Document version: 3.6 Authors: Neo-Brahmi Generation Panel [NBGP] 1 General Information/ Overview/ Abstract The purpose of this document is to give an overview of the proposed Gujarati LGR in the XML format and the rationale behind the design decisions taken. It includes a discussion of relevant features of the script, the communities or languages using it, the process and methodology used and information on the contributors. The formal specification of the LGR can be found in the accompanying XML document: proposal-gujarati-lgr-06mar19-en.xml Labels for testing can be found in the accompanying text document: gujarati-test-labels-06mar19-en.txt 2 Script for which the LGR is proposed ISO 15924 Code: Gujr ISO 15924 Key N°: 320 ISO 15924 English Name: Gujarati Latin transliteration of native script name: gujarâtî Native name of the script: ગજુ રાતી Maximal Starting Repertoire (MSR) version: MSR-4 1 Proposal for a Gujarati Root Zone LGR Neo-Brahmi Generation Panel 3 Background on the Script and the Principal Languages Using it1 Gujarati (ગજુ રાતી) [also sometimes written as Gujerati, Gujarathi, Guzratee, Guujaratee, Gujrathi, and Gujerathi2] is an Indo-Aryan language native to the Indian state of Gujarat. It is part of the greater Indo-European language family. It is so named because Gujarati is the language of the Gujjars. Gujarati's origins can be traced back to Old Gujarati (circa 1100– 1500 AD). -
Census of India Website at Censusinfo.Html
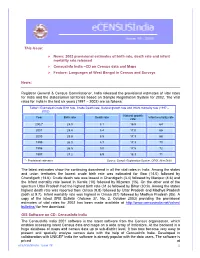
This Issue: News: 2002 provisional estimates of birth rate, death rate and infant mortality rate released CensusInfo India –CD on Census data and Maps Feature: Languages of West Bengal in Census and Surveys News: Registrar General & Census Commissioner, India released the provisional estimates of vital rates for India and the states/union territories based on Sample Registration System for 2002. The vital rates for India in the last six years (1997 – 2002) are as follows: Table1: Estimated Crude Birth rate, Crude Death rate, Natural growth rate and Infant mortality rate (1997 – 2002) Natural growth Year Birth rate Death rate Infant mortality rate rate 2002* 25.0 8.1 16.9 64 2001 25.4 8.4 17.0 66 2000 25.8 8.5 17.3 68 1999 26.0 8.7 17.3 70 1998 26.5 9.0 17.5 72 1997 27.2 8.9 18.3 71 * - Provisional estimates Source: Sample Registration System, ORGI, New Delhi The latest estimates show the continuing downtrend in all the vital rates in India. Among the states and union territories the lowest crude birth rate was estimated for Goa (14.0) followed by Chandigarh (14.6). Crude death rate was lowest in Chandigarh (3.4) followed by Manipur (4.6) and the Infant mortality rate lowest in Kerala (10) followed by Mizoram (15). On the other end of the spectrum Uttar Pradesh had the highest birth rate (31.6) followed by Bihar (30.9). Among the states highest death rate was reported from Orissa (9.8) followed by Uttar Pradesh and Madhya Pradesh (both at 9.7). -

Finite-State Script Normalization and Processing Utilities: the Nisaba Brahmic Library
Finite-state script normalization and processing utilities: The Nisaba Brahmic library Cibu Johny† Lawrence Wolf-Sonkin‡ Alexander Gutkin† Brian Roark‡ Google Research †United Kingdom and ‡United States {cibu,wolfsonkin,agutkin,roark}@google.com Abstract In addition to such normalization issues, some scripts also have well-formedness constraints, i.e., This paper presents an open-source library for efficient low-level processing of ten ma- not all strings of Unicode characters from a single jor South Asian Brahmic scripts. The library script correspond to a valid (i.e., legible) grapheme provides a flexible and extensible framework sequence in the script. Such constraints do not ap- for supporting crucial operations on Brahmic ply in the basic Latin alphabet, where any permuta- scripts, such as NFC, visual normalization, tion of letters can be rendered as a valid string (e.g., reversible transliteration, and validity checks, for use as an acronym). The Brahmic family of implemented in Python within a finite-state scripts, however, including the Devanagari script transducer formalism. We survey some com- mon Brahmic script issues that may adversely used to write Hindi, Marathi and many other South affect the performance of downstream NLP Asian languages, do have such constraints. These tasks, and provide the rationale for finite-state scripts are alphasyllabaries, meaning that they are design and system implementation details. structured around orthographic syllables (aksara)̣ as the basic unit.1 One or more Unicode characters 1 Introduction combine when rendering one of thousands of leg- The Unicode Standard separates the representation ible aksara,̣ but many combinations do not corre- of text from its specific graphical rendering: text spond to any aksara.̣ Given a token in these scripts, is encoded as a sequence of characters, which, at one may want to (a) normalize it to a canonical presentation time are then collectively rendered form; and (b) check whether it is a well-formed into the appropriate sequence of glyphs for display. -

The Unicode Standard, Version 6.3
Currency Symbols Range: 20A0–20CF This file contains an excerpt from the character code tables and list of character names for The Unicode Standard, Version 6.3 This file may be changed at any time without notice to reflect errata or other updates to the Unicode Standard. See http://www.unicode.org/errata/ for an up-to-date list of errata. See http://www.unicode.org/charts/ for access to a complete list of the latest character code charts. See http://www.unicode.org/charts/PDF/Unicode-6.3/ for charts showing only the characters added in Unicode 6.3. See http://www.unicode.org/Public/6.3.0/charts/ for a complete archived file of character code charts for Unicode 6.3. Disclaimer These charts are provided as the online reference to the character contents of the Unicode Standard, Version 6.3 but do not provide all the information needed to fully support individual scripts using the Unicode Standard. For a complete understanding of the use of the characters contained in this file, please consult the appropriate sections of The Unicode Standard, Version 6.3, online at http://www.unicode.org/versions/Unicode6.3.0/, as well as Unicode Standard Annexes #9, #11, #14, #15, #24, #29, #31, #34, #38, #41, #42, #44, and #45, the other Unicode Technical Reports and Standards, and the Unicode Character Database, which are available online. See http://www.unicode.org/ucd/ and http://www.unicode.org/reports/ A thorough understanding of the information contained in these additional sources is required for a successful implementation. -

Ancient Writing
Ancient Writing As early civilizations developed, societies became more complicated. Record keeping and communication demanded something beyond symbols and pictures to represent the spoken word. This resource explores the early writing systems of four ancient civilizations: Mesopotamia, Egypt, China, and Mesoamerica. You'll also learn about the Rosetta Stone, the 19th-century discovery that gave scholars the key that unlocked the language of ancient Egypt. Grade Level: Grades 3-5 Collection: Ancient Art, East Asian Art, Egyptian Art, Pre-Columbian Art Culture/Region: America, China, Egypt Subject Area: History and Social Science, Science, Visual Arts Activity Type: Art in Depth HOW ANCIENT WRITING BEGAN… AND ENDED As early civilizations developed, societies became more complicated. Record keeping and communication demanded something beyond symbols and pictures to represent the spoken word. This gallery explores the early writing systems of four ancient civilizations: Mesopotamia, Egypt, China, and Mesoamerica. Here you’ll also learn about the Rosetta Stone, the 19th-century discovery that gave scholars the key that unlocked the language of ancient Egypt. Why were writing systems developed? Communication – Sounds and speech needed to be visually represented. Correspondence – There was a desire to send notes, letters, and instructions. Recording – Bookkeeping tasks became important for counting crops, paying workers’ rations, and collecting taxes. Preservation – Personal stories, rituals, religious texts, hymns, literature, and history all needed to be recorded. Why did some writing systems disappear? Change – Corresponding cultures died out or were absorbed by others. Innovation – Newer, simpler systems replaced older systems. Conquest – Invaders or new rulers imposed their own writing systems. New Beginnings – New ways of writing developed with new belief systems. -

The Unicode Standard, Version 4.0--Online Edition
This PDF file is an excerpt from The Unicode Standard, Version 4.0, issued by the Unicode Consor- tium and published by Addison-Wesley. The material has been modified slightly for this online edi- tion, however the PDF files have not been modified to reflect the corrections found on the Updates and Errata page (http://www.unicode.org/errata/). For information on more recent versions of the standard, see http://www.unicode.org/standard/versions/enumeratedversions.html. Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this book, and Addison-Wesley was aware of a trademark claim, the designations have been printed in initial capital letters. However, not all words in initial capital letters are trademark designations. The Unicode® Consortium is a registered trademark, and Unicode™ is a trademark of Unicode, Inc. The Unicode logo is a trademark of Unicode, Inc., and may be registered in some jurisdictions. The authors and publisher have taken care in preparation of this book, but make no expressed or implied warranty of any kind and assume no responsibility for errors or omissions. No liability is assumed for incidental or consequential damages in connection with or arising out of the use of the information or programs contained herein. The Unicode Character Database and other files are provided as-is by Unicode®, Inc. No claims are made as to fitness for any particular purpose. No warranties of any kind are expressed or implied. The recipient agrees to determine applicability of information provided. Dai Kan-Wa Jiten used as the source of reference Kanji codes was written by Tetsuji Morohashi and published by Taishukan Shoten.