Automated Intro Detection for TV Series Automatiserad Detektion Av Intron I TV-Serier
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Uila Supported Apps
Uila Supported Applications and Protocols updated Oct 2020 Application/Protocol Name Full Description 01net.com 01net website, a French high-tech news site. 050 plus is a Japanese embedded smartphone application dedicated to 050 plus audio-conferencing. 0zz0.com 0zz0 is an online solution to store, send and share files 10050.net China Railcom group web portal. This protocol plug-in classifies the http traffic to the host 10086.cn. It also 10086.cn classifies the ssl traffic to the Common Name 10086.cn. 104.com Web site dedicated to job research. 1111.com.tw Website dedicated to job research in Taiwan. 114la.com Chinese web portal operated by YLMF Computer Technology Co. Chinese cloud storing system of the 115 website. It is operated by YLMF 115.com Computer Technology Co. 118114.cn Chinese booking and reservation portal. 11st.co.kr Korean shopping website 11st. It is operated by SK Planet Co. 1337x.org Bittorrent tracker search engine 139mail 139mail is a chinese webmail powered by China Mobile. 15min.lt Lithuanian news portal Chinese web portal 163. It is operated by NetEase, a company which 163.com pioneered the development of Internet in China. 17173.com Website distributing Chinese games. 17u.com Chinese online travel booking website. 20 minutes is a free, daily newspaper available in France, Spain and 20minutes Switzerland. This plugin classifies websites. 24h.com.vn Vietnamese news portal 24ora.com Aruban news portal 24sata.hr Croatian news portal 24SevenOffice 24SevenOffice is a web-based Enterprise resource planning (ERP) systems. 24ur.com Slovenian news portal 2ch.net Japanese adult videos web site 2Shared 2shared is an online space for sharing and storage. -

TV Universe—UK, Germany, Sweden: HOW PEOPLE WATCH TELEVISION TODAY Author: Colin Dixon, Founder and Chief Analyst, Nscreenmedia | 2019
TV Universe—UK, Germany, Sweden: HOW PEOPLE WATCH TELEVISION TODAY Author: Colin Dixon, Founder and Chief Analyst, nScreenMedia | 2019 I NTRODUCTION Technology has become such a part of our daily lives that sometimes it seems that it is an end unto itself. However, in the world of the consumer, it has a particular role to play. Tim O’Reilly, who coined the term “open source,” put Online TV is now the second it this way: most popular source of “What technology does is create new opportunities to do a job that customers want done.”1 Home entertainment is most certainly a job that people “want done.” Ninety years ago, broadcast television television content in the UK, technology was the new opportunity to deliver it in an entirely new way.2 Based on the data from our most recent survey in Europe, the internet has become the next new opportunity to provide television entertainment to the home. Germany, and Sweden. Today, there are three primary sources of TV entertainment available to consumers: free-to-air (FTA), pay TV, and online TV. Free-to-air TV channels are typically received via an antenna but can also arrive over satellite and cable. Examples include BBC1, SVT1, and Das Erste. Pay TV services distribute linear TV over cable, satellite, and telco TV systems. Examples include Virgin Media, Sky Deutschland, and Com Hem. Online TV allows viewers to stream or download shows and movies over mobile and broadband data networks. Examples of services include Netflix, Now TV, and Amazon Prime Video. Just twelve years after Netflix first introduced streaming services, online TV has become the second most popular TV source in the UK, Germany, and Sweden. -

List of Brands
Global Consumer 2019 List of Brands Table of Contents 1. Digital music 2 2. Video-on-Demand 4 3. Video game stores 7 4. Digital video games shops 11 5. Video game streaming services 13 6. Book stores 15 7. eBook shops 19 8. Daily newspapers 22 9. Online newspapers 26 10. Magazines & weekly newspapers 30 11. Online magazines 34 12. Smartphones 38 13. Mobile carriers 39 14. Internet providers 42 15. Cable & satellite TV provider 46 16. Refrigerators 49 17. Washing machines 51 18. TVs 53 19. Speakers 55 20. Headphones 57 21. Laptops 59 22. Tablets 61 23. Desktop PC 63 24. Smart home 65 25. Smart speaker 67 26. Wearables 68 27. Fitness and health apps 70 28. Messenger services 73 29. Social networks 75 30. eCommerce 77 31. Search Engines 81 32. Online hotels & accommodation 82 33. Online flight portals 85 34. Airlines 88 35. Online package holiday portals 91 36. Online car rental provider 94 37. Online car sharing 96 38. Online ride sharing 98 39. Grocery stores 100 40. Banks 104 41. Online payment 108 42. Mobile payment 111 43. Liability insurance 114 44. Online dating services 117 45. Online event ticket provider 119 46. Food & restaurant delivery 122 47. Grocery delivery 125 48. Car Makes 129 Statista GmbH Johannes-Brahms-Platz 1 20355 Hamburg Tel. +49 40 2848 41 0 Fax +49 40 2848 41 999 [email protected] www.statista.com Steuernummer: 48/760/00518 Amtsgericht Köln: HRB 87129 Geschäftsführung: Dr. Friedrich Schwandt, Tim Kröger Commerzbank AG IBAN: DE60 2004 0000 0631 5915 00 BIC: COBADEFFXXX Umsatzsteuer-ID: DE 258551386 1. -

Annual Report 2016 - 2017 English Edition
ANNUAL REPORT 2016 - 2017 ENGLISH EDITION NORD VISION Nordvision 2016 - 2017 Published by Nordvision Design Lars Schmidt Hansen Editorial team: Henrik Hartmann (editor in chief) Kristian Martikainen Øystein Espeseth-Andresen The annual report can be found at nordvision.org Cover photo front: DELHIS VACKRASTE HÄNDER / SVT and Anagram Photo: Janne Danielsson BEDRAG / DR Photo: Christian Geisnæs SKAM / NRK Cover photo back: PRISONERS / RUV and Mystery Productions BLIND DONNA / Yle Photo: Joonas Pulkkanen FRÖKEN FRIMANS KRIG / SVT Photo: Peter Cederling Foreword 2016 saw a breakthrough in two cooperative areas for Nordvision: We launched a major digital cooperation around Euro 2016, and we also established an important technological cooperation between NRK and DR for a radio app. The general media-technological development is both a challenge and a great opportunity for us. On the whole, it is positive to see new and excit- ing digital and publishing cooperation projects based around technology, which, by their very nature keeps us moving forward. Overall, 2016 was the best year ever based on the number of programmes and hours generated by collaboration within the Nordvision partnership. For co-productions, the cooperation rose by 13%, an impressive figure considering how challenged the public service has been in recent years financially, politically and from global players. Strategies and promising visions for the future are all well and good, but it is the specific programme collaboration we need to measure Nordic cooperation with. Once again, we can enjoy the fact that the many programme groups and people working on programme sharing have succeeded in achieving excellent results. There are numerous notable projects from 2016, and many new projects on the horizon. -

Reimagining TV Viewing Jack Davison, Executive Vice President, 3Vision
Reimagining TV Viewing Jack Davison, Executive Vice President, 3Vision CTAM Europe OTT Symposium 2019 CTAM Europe OTT Symposium 2019 Growing complexities Media Direct to SVOD Short Form & Content AVOD Consolidation Consumer Growth Social Market 2 CTAM Europe OTT Symposium 2019 Media Consolidation AT&T Walt Disney Discovery Comcast & Time Warner & 21st Century Fox & Scripps & Sky $85 billion $72 billion $15 billion $39 billion Mergers March 2019 March 2019 March 2018 October 2018 Discovery, ProSieben TF1, M6 BBC Studios TBS, TV Tokyo, & additional partners & France Television & ITV WOWOW & others 7TV Salto Britbox Paravi Alliances Launched but rebuilding Launch date tbc UK launch date tbc Launched April 2018 3 CTAM Europe OTT Symposium 2019 Direct to Consumer Disney+ Unnamed Shudder Disney NBCU AMC Launching globally US & UK & others tbc US, Canada, UK & Germany SVOD AVOD on Pay TV, SVOD OTT SVOD HBO Hayu Crackle WarnerMedia NBC Universal Sony US, ESP, Nordics & others UK, Nordics, US only SVOD Australia & Canada AVOD Starz Play Hulu Eurosport Starz/Lionsgate Disney, Comcast/NBCU, Discovery US, Canada, UK & Germany WarnerMedia Europe SVOD US SVOD & VMVPD SVOD Britbox Epix Now Zee5 BBC & ITV MGM Zee Ent. Enterprises US with UK coming US Global SVOD SVOD SVOD & linear channels 4 CTAM Europe OTT Symposium 2019 SVOD Global Growth Global SVOD Growth 600 50 546 520 490 451 450 38 405 Subscribers (Millions) Subscribers 344 (US$ Billions) Revenues 300 262 25 Revenues (US$B) 179 Subscribers (M) 150 121 13 82 54 27 35 '- 0 0 2010 2011 2012 2013 2014 -

PFA Smartphone
PFA Smartphone Standardrapport Procent Antal Ja. 78,8% 6816 Nej. 21,2% 1835 Svarande 8651 Inget svar 0 Procent Antal Android 27% 1807 iOS (Iphone) 31,9% 2137 Bada 0,1% 10 Blackberry 0,7% 50 Maemo 1,1% 73 Symbian 19,1% 1278 Windows Phone 13,8% 927 Annat 6,2% 415 Svarande 6697 Inget svar 118 Procent Antal Ja 27,1% 1804 Nej 72,9% 4848 Svarande 6652 Inget svar 163 Procent Antal Jag tycker det är alldeles för bökigt eller tar för lång tid att slå koden hela tiden. 74,9% 3606 Jag visste inte att alternativet fanns 11,1% 535 Förstår inte varför man behöver det. 14% 674 Svarande 4815 Inget svar 197 Kryssa i ett eller flera alternativ Svaran Inget de svar Jobbmejl 100% 2957 3859 Privat mejl 100% 4842 1974 Adressbok 100% 5358 1458 Kalender 100% 5486 1330 Komma åt företagets system (säljstöd, ekonomi, 100% 534 6282 databaser etc.) Företagsrelaterade dokument, kalkyler eller liknande 100% 1117 5699 Privata dokument, kalkyler eller liknande 100% 2561 4255 Sociala tjänster (facebook, twitter mm) 100% 3461 3355 Fotoalbum 100% 3697 3119 Spel 100% 3231 3585 Totalt 6443 373 Övrigt - Hitta bensinstation, restaurang, bankomat och brevlåda, systemet, etc. - Panera resor för tex buss, tunnelbana och tåg (res i stockholm appen). Tex var ligger närmaste busstation och när går bussen... - GPS-navigering och tracker för tex bil, träning och skidor som sen kab publiceras på nätet... - Kolla på TV - Lyssna på musik i bilen, via hörlurar eller kopplad till hemstereon. - Lyssna på radio tex P1 (direkt och gamla sändingar) - Att-göra listor ala GTD (Get Things Done) - Inköpslistor - Kolla på film direkt på telefonen eller via LAN (XBMC) - Universal Fjärrkontroll (XBMC, iTunes, TV) - Styra värmen på landet via SMS eller internet. -

Supported Sites
# Supported sites - **1tv**: Первый канал - **1up.com** - **20min** - **220.ro** - **22tracks:genre** - **22tracks:track** - **24video** - **3qsdn**: 3Q SDN - **3sat** - **4tube** - **56.com** - **5min** - **6play** - **8tracks** - **91porn** - **9c9media** - **9c9media:stack** - **9gag** - **9now.com.au** - **abc.net.au** - **abc.net.au:iview** - **abcnews** - **abcnews:video** - **abcotvs**: ABC Owned Television Stations - **abcotvs:clips** - **AcademicEarth:Course** - **acast** - **acast:channel** - **AddAnime** - **ADN**: Anime Digital Network - **AdobeTV** - **AdobeTVChannel** - **AdobeTVShow** - **AdobeTVVideo** - **AdultSwim** - **aenetworks**: A+E Networks: A&E, Lifetime, History.com, FYI Network - **afreecatv**: afreecatv.com - **afreecatv:global**: afreecatv.com - **AirMozilla** - **AlJazeera** - **Allocine** - **AlphaPorno** - **AMCNetworks** - **anderetijden**: npo.nl and ntr.nl - **AnimeOnDemand** - **anitube.se** - **Anvato** - **AnySex** - **Aparat** - **AppleConnect** - **AppleDaily**: 臺灣蘋果⽇報 - **appletrailers** - **appletrailers:section** - **archive.org**: archive.org videos - **ARD** - **ARD:mediathek** - **Arkena** - **arte.tv** - **arte.tv:+7** - **arte.tv:cinema** - **arte.tv:concert** - **arte.tv:creative** - **arte.tv:ddc** - **arte.tv:embed** - **arte.tv:future** - **arte.tv:info** - **arte.tv:magazine** - **arte.tv:playlist** - **AtresPlayer** - **ATTTechChannel** - **ATVAt** - **AudiMedia** - **AudioBoom** - **audiomack** - **audiomack:album** - **auroravid**: AuroraVid - **AWAAN** - **awaan:live** - **awaan:season** -

Covid-19 and Public Service Media: Impact of the Pandemic on Public Television in Europe Miguel Túñez-López; Martín Vaz-Álvarez; César Fieiras-Ceide
Covid-19 and public service media: Impact of the pandemic on public television in Europe Miguel Túñez-López; Martín Vaz-Álvarez; César Fieiras-Ceide Nota: Este artículo se puede leer en español en: http://www.elprofesionaldelainformacion.com/contenidos/2020/sep/tunez-vaz-fieiras_es.pdf How to cite this article: Túñez-López, Miguel; Vaz-Álvarez, Martín; Fieiras-Ceide, César (2020). “Covid-19 and public service media: Impact of the pandemic on public television in Europe”. Profesional de la información, v. 29, n. 5, e290518. https://doi.org/10.3145/epi.2020.sep.18 Manuscript received on 16th June 2020 Accepted on 11th August 2020 Miguel Túñez-López * Martín Vaz-Álvarez https://orcid.org/0000-0002-5036-9143 https://orcid.org/0000-0002-4848-9795 Universidade de Santiago de Compostela, Universidade de Santiago de Compostela, Facultad de Ciencias de la Comunicación, Facultade de Ciencias da Comunicación, Depto. de Ciencias de la Comunicación Depto. de Ciencias da Comunicación Av. de Castelao, s/n. Campus Norte Av. Castelao, s/n. Campus Norte 15782 Santiago de Compostela, Spain 15782 Santiago de Compostela, Spain [email protected] [email protected] César Fieiras-Ceide https://orcid.org/0000-0001-5606-3236 Universidade de Santiago de Compostela, Grupo Novos Medios Ronda de la Muralla, 142 27004 Lugo, España [email protected] Abstract This article analyses the response of European Public Service Media to the crisis caused by Covid-19, especially the impact of the pandemic on Europe’s major public broadcasters, with a particular focus on technical and professional constraints, alterations in audience volume and habits, production strategies, type of broadcast content and journalists’ routines. -

Broadcasters and the Broadcasters and the Internet
Broadcasters and the Broadcasters and the Internet Internet EBU Members’ Internet Presence Distribution Strategies Online Consumption Trends Social Networking and Video Sharing Communities November 2007 European Broadcasting Union Strategic Information Service (SIS) L’Ancienne-Route 17A CH-1218 Grand-Saconnex Switzerland Phone +41 (0) 22 717 21 11 Fax +41 (0)22 747 40 00 www.ebu.ch/sis European Broadcasting Union l Strategic Information Service Broadcasters and the Internet EBU Members' Internet Presence Distribution Strategies Online Consumption Trends Social Networking and Video Sharing Communities November 2007 The Report Staff This report was produced by the Strategic Information Service of the EBU. Editor: Alexander Shulzycki Production Editor: Anna-Sara Stalvik Principal Researcher: Anna-Sara Stalvik Special appreciation to: Danish Radio and Television (DR) Swedish Television (SVT) Swedish Radio (SR) Cover Design: Philippe Juttens European Broadcasting Union Telephone: +41 22 717 2111 Address: L'Ancienne-Route 17A, 1218 Geneva, Switzerland SIS web-site: www.ebu.ch/director_general/sis.php SIS contact e-mail: [email protected] BROADCASTERS AND THE INTERNET TABLE OF CONTENTS INTRODUCTION.............................................................................................................. 1 OVERVIEW .............................................................................................................................1 1. The general Internet landscape: usage, websites, advertising ............................................ -
3000 Applications
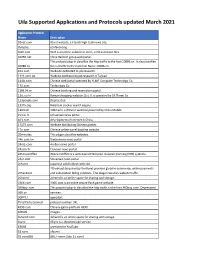
Uila Supported Applications and Protocols updated March 2021 Application Protocol Name Description 01net.com 05001net plus website, is a Japanese a French embedded high-tech smartphonenews site. application dedicated to audio- 050 plus conferencing. 0zz0.com 0zz0 is an online solution to store, send and share files 10050.net China Railcom group web portal. This protocol plug-in classifies the http traffic to the host 10086.cn. It also classifies 10086.cn the ssl traffic to the Common Name 10086.cn. 104.com Web site dedicated to job research. 1111.com.tw Website dedicated to job research in Taiwan. 114la.com Chinese cloudweb portal storing operated system byof theYLMF 115 Computer website. TechnologyIt is operated Co. by YLMF Computer 115.com Technology Co. 118114.cn Chinese booking and reservation portal. 11st.co.kr ThisKorean protocol shopping plug-in website classifies 11st. the It ishttp operated traffic toby the SK hostPlanet 123people.com. Co. 123people.com Deprecated. 1337x.org Bittorrent tracker search engine 139mail 139mail is a chinese webmail powered by China Mobile. 15min.lt ChineseLithuanian web news portal portal 163. It is operated by NetEase, a company which pioneered the 163.com development of Internet in China. 17173.com Website distributing Chinese games. 17u.com 20Chinese minutes online is a travelfree, daily booking newspaper website. available in France, Spain and Switzerland. 20minutes This plugin classifies websites. 24h.com.vn Vietnamese news portal 24ora.com Aruban news portal 24sata.hr Croatian news portal 24SevenOffice 24SevenOffice is a web-based Enterprise resource planning (ERP) systems. 24ur.com Slovenian news portal 2ch.net Japanese adult videos web site 2Checkout (acquired by Verifone) provides global e-commerce, online payments 2Checkout and subscription billing solutions. -

Facts & Figures About European Telecoms Operators
Facts & Figures about European Telecoms Operators 4th edition - October 2009 European Telecommunications Network Operators’ Association European Telecommunications Network Operators’ Association ETNO has been the voice of Europe’s telecommunications network operators since 1992. Its 42 members in 36 countries collectively account for a turnover of more than € 270 billion and one million employees. ETNO members also hold new entrant positions outside their national markets. ETNO brings together the main investors in innovative and high-quality e-communications platforms and services, representing 70% of total sector investment. ETNO closely contributes to shaping the best regulatory and commercial environment for its members to continue rolling out innovative and high quality services and platforms for the benefit of European consumers and businesses. Design & Production: Frigolite Photography: Corbis, Masterfile 2 Introduction: a word from the ETNO Director and IDATE ������������������������������������������������������������������������������������������������������������ 4 ETNO membership – key facts and figures ������������������������������������������������������������������������������������������������������������������������������������� 6 The Telecoms sector in Europe: a key pillar of the EU economy ����������������������������������������������������������������������������������������� 10 Investing in the future ���������������������������������������������������������������������������������������������������������������������������������������������������������������������������� -

VEWD Style Guide
VEWD Style Guide 1 VEWD Style Guide Contents Brand Strategy 3 Incorrect Use 18 Our Name: VEWD 4 Brand Colors 19 Brand Idea: Enabling Extraordinary 5 Typefaces 20 Brand Building Blocks 7 Imagery 21 Tone of Voice 8 Supergraphic & Secondary Graphics 22 Brand Touchpoint Wheel 13 Visual Examples 23 Brand Logo 14 Business Card 24 The VEWD Logo 15 Web 25 Clear Space & Minimum Size 16 PowerPoint 26 Correct Use 17 Contact Information 27 2 VEWD Style Guide Brand Strategy 3 VEWD Style Guide Our Name: VEWD The Triangular Connection Device – Viewing capabilities our technology offers. UI to streaming video Content – We will strive to get our partners content viewed Consumers – A clear message that there is something to see here Global Software Company One Word Punch - Fresh, short & modern Software company with a globally relevant, easy to remember name A solid and futuristic brand which that will inspire all employees, much like Opera did Leadership & Synergy Alignment Start with why – VEWD focuses on the end goal. It will inspire our team and partners to understand why we are doing what we are doing. At the end of the day, we want our consumers to be able to watch anything, anywhere at anytime – without limits. 4 VEWD Style Guide Brand Idea: Enabling Extraordinary VEWD is a leading enterprise software, services and solution company that enable device manufacturers, operators, broadcasters, andcontent providers to create Over The Top “OTT” environments on any screen, anywhere in the world. Previously part of Opera (the renowned open-source web browser founded in Scandinavia) but now a separate company, VEWD is a pioneer in the connected television category having built the first connected set top box for Canal+ in 2002, the first Smart TV from Philips in 2007 and the first connected gaming device for the Nintendo Wii.