Linear Algebra
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Linear Algebra for Dummies
Linear Algebra for Dummies Jorge A. Menendez October 6, 2017 Contents 1 Matrices and Vectors1 2 Matrix Multiplication2 3 Matrix Inverse, Pseudo-inverse4 4 Outer products 5 5 Inner Products 5 6 Example: Linear Regression7 7 Eigenstuff 8 8 Example: Covariance Matrices 11 9 Example: PCA 12 10 Useful resources 12 1 Matrices and Vectors An m × n matrix is simply an array of numbers: 2 3 a11 a12 : : : a1n 6 a21 a22 : : : a2n 7 A = 6 7 6 . 7 4 . 5 am1 am2 : : : amn where we define the indexing Aij = aij to designate the component in the ith row and jth column of A. The transpose of a matrix is obtained by flipping the rows with the columns: 2 3 a11 a21 : : : an1 6 a12 a22 : : : an2 7 AT = 6 7 6 . 7 4 . 5 a1m a2m : : : anm T which evidently is now an n × m matrix, with components Aij = Aji = aji. In other words, the transpose is obtained by simply flipping the row and column indeces. One particularly important matrix is called the identity matrix, which is composed of 1’s on the diagonal and 0’s everywhere else: 21 0 ::: 03 60 1 ::: 07 6 7 6. .. .7 4. .5 0 0 ::: 1 1 It is called the identity matrix because the product of any matrix with the identity matrix is identical to itself: AI = A In other words, I is the equivalent of the number 1 for matrices. For our purposes, a vector can simply be thought of as a matrix with one column1: 2 3 a1 6a2 7 a = 6 7 6 . -

Equations of Lines and Planes
Equations of Lines and 12.5 Planes Copyright © Cengage Learning. All rights reserved. Lines A line in the xy-plane is determined when a point on the line and the direction of the line (its slope or angle of inclination) are given. The equation of the line can then be written using the point-slope form. Likewise, a line L in three-dimensional space is determined when we know a point P0(x0, y0, z0) on L and the direction of L. In three dimensions the direction of a line is conveniently described by a vector, so we let v be a vector parallel to L. 2 Lines Let P(x, y, z) be an arbitrary point on L and let r0 and r be the position vectors of P0 and P (that is, they have representations and ). If a is the vector with representation as in Figure 1, then the Triangle Law for vector addition gives r = r0 + a. Figure 1 3 Lines But, since a and v are parallel vectors, there is a scalar t such that a = t v. Thus which is a vector equation of L. Each value of the parameter t gives the position vector r of a point on L. In other words, as t varies, the line is traced out by the tip of the vector r. 4 Lines As Figure 2 indicates, positive values of t correspond to points on L that lie on one side of P0, whereas negative values of t correspond to points that lie on the other side of P0. -

Lecture 3.Pdf
ENGR-1100 Introduction to Engineering Analysis Lecture 3 POSITION VECTORS & FORCE VECTORS Today’s Objectives: Students will be able to : a) Represent a position vector in Cartesian coordinate form, from given geometry. In-Class Activities: • Applications / b) Represent a force vector directed along Relevance a line. • Write Position Vectors • Write a Force Vector along a line 1 DOT PRODUCT Today’s Objective: Students will be able to use the vector dot product to: a) determine an angle between In-Class Activities: two vectors, and, •Applications / Relevance b) determine the projection of a vector • Dot product - Definition along a specified line. • Angle Determination • Determining the Projection APPLICATIONS This ship’s mooring line, connected to the bow, can be represented as a Cartesian vector. What are the forces in the mooring line and how do we find their directions? Why would we want to know these things? 2 APPLICATIONS (continued) This awning is held up by three chains. What are the forces in the chains and how do we find their directions? Why would we want to know these things? POSITION VECTOR A position vector is defined as a fixed vector that locates a point in space relative to another point. Consider two points, A and B, in 3-D space. Let their coordinates be (XA, YA, ZA) and (XB, YB, ZB), respectively. 3 POSITION VECTOR The position vector directed from A to B, rAB , is defined as rAB = {( XB –XA ) i + ( YB –YA ) j + ( ZB –ZA ) k }m Please note that B is the ending point and A is the starting point. -

Exercise 7.5
IN SUMMARY Key Idea • A projection of one vector onto another can be either a scalar or a vector. The difference is the vector projection has a direction. A A a a u u O O b NB b N B Scalar projection of a on b Vector projection of a on b Need to Know ! ! ! ! a # b ! • The scalar projection of a on b ϭϭ! 0 a 0 cos u, where u is the angle @ b @ ! ! between a and b. ! ! ! ! ! ! a # b ! a # b ! • The vector projection of a on b ϭ ! b ϭ a ! ! b b @ b @ 2 b # b ! • The direction cosines for OP ϭ 1a, b, c2 are a b cos a ϭ , cos b ϭ , 2 2 2 2 2 2 Va ϩ b ϩ c Va ϩ b ϩ c c cos g ϭ , where a, b, and g are the direction angles 2 2 2 Va ϩ b ϩ c ! between the position vector OP and the positive x-axis, y-axis and z-axis, respectively. Exercise 7.5 PART A ! 1. a. The vector a ϭ 12, 32 is projected onto the x-axis. What is the scalar projection? What is the vector projection? ! b. What are the scalar and vector projections when a is projected onto the y-axis? 2. Explain why it is not possible to obtain! either a scalar! projection or a vector projection when a nonzero vector x is projected on 0. 398 7.5 SCALAR AND VECTOR PROJECTIONS NEL ! ! 3. Consider two nonzero vectors,a and b, that are perpendicular! ! to each other.! Explain why the scalar and vector projections of a on b must! be !0 and 0, respectively. -

MATH 304 Linear Algebra Lecture 24: Scalar Product. Vectors: Geometric Approach
MATH 304 Linear Algebra Lecture 24: Scalar product. Vectors: geometric approach B A B′ A′ A vector is represented by a directed segment. • Directed segment is drawn as an arrow. • Different arrows represent the same vector if • they are of the same length and direction. Vectors: geometric approach v B A v B′ A′ −→AB denotes the vector represented by the arrow with tip at B and tail at A. −→AA is called the zero vector and denoted 0. Vectors: geometric approach v B − A v B′ A′ If v = −→AB then −→BA is called the negative vector of v and denoted v. − Vector addition Given vectors a and b, their sum a + b is defined by the rule −→AB + −→BC = −→AC. That is, choose points A, B, C so that −→AB = a and −→BC = b. Then a + b = −→AC. B b a C a b + B′ b A a C ′ a + b A′ The difference of the two vectors is defined as a b = a + ( b). − − b a b − a Properties of vector addition: a + b = b + a (commutative law) (a + b) + c = a + (b + c) (associative law) a + 0 = 0 + a = a a + ( a) = ( a) + a = 0 − − Let −→AB = a. Then a + 0 = −→AB + −→BB = −→AB = a, a + ( a) = −→AB + −→BA = −→AA = 0. − Let −→AB = a, −→BC = b, and −→CD = c. Then (a + b) + c = (−→AB + −→BC) + −→CD = −→AC + −→CD = −→AD, a + (b + c) = −→AB + (−→BC + −→CD) = −→AB + −→BD = −→AD. Parallelogram rule Let −→AB = a, −→BC = b, −−→AB′ = b, and −−→B′C ′ = a. Then a + b = −→AC, b + a = −−→AC ′. -

Basics of Linear Algebra
Basics of Linear Algebra Jos and Sophia Vectors ● Linear Algebra Definition: A list of numbers with a magnitude and a direction. ○ Magnitude: a = [4,3] |a| =sqrt(4^2+3^2)= 5 ○ Direction: angle vector points ● Computer Science Definition: A list of numbers. ○ Example: Heights = [60, 68, 72, 67] Dot Product of Vectors Formula: a · b = |a| × |b| × cos(θ) ● Definition: Multiplication of two vectors which results in a scalar value ● In the diagram: ○ |a| is the magnitude (length) of vector a ○ |b| is the magnitude of vector b ○ Θ is the angle between a and b Matrix ● Definition: ● Matrix elements: ● a)Matrix is an arrangement of numbers into rows and columns. ● b) A matrix is an m × n array of scalars from a given field F. The individual values in the matrix are called entries. ● Matrix dimensions: the number of rows and columns of the matrix, in that order. Multiplication of Matrices ● The multiplication of two matrices ● Result matrix dimensions ○ Notation: (Row, Column) ○ Columns of the 1st matrix must equal the rows of the 2nd matrix ○ Result matrix is equal to the number of (1, 2, 3) • (7, 9, 11) = 1×7 +2×9 + 3×11 rows in 1st matrix and the number of = 58 columns in the 2nd matrix ○ Ex. 3 x 4 ॱ 5 x 3 ■ Dot product does not work ○ Ex. 5 x 3 ॱ 3 x 4 ■ Dot product does work ■ Result: 5 x 4 Dot Product Application ● Application: Ray tracing program ○ Quickly create an image with lower quality ○ “Refinement rendering pass” occurs ■ Removes the jagged edges ○ Dot product used to calculate ■ Intersection between a ray and a sphere ■ Measure the length to the intersection points ● Application: Forward Propagation ○ Input matrix * weighted matrix = prediction matrix http://immersivemath.com/ila/ch03_dotprodu ct/ch03.html#fig_dp_ray_tracer Projections One important use of dot products is in projections. -

An Elementary System of Axioms for Euclidean Geometry Based on Symmetry Principles
An Elementary System of Axioms for Euclidean Geometry based on Symmetry Principles Boris Čulina Department of Mathematics, University of Applied Sciences Velika Gorica, Zagrebačka cesta 5, Velika Gorica, CROATIA email: [email protected] arXiv:2105.14072v1 [math.HO] 28 May 2021 1 Abstract. In this article I develop an elementary system of axioms for Euclidean geometry. On one hand, the system is based on the symmetry principles which express our a priori ignorant approach to space: all places are the same to us (the homogeneity of space), all directions are the same to us (the isotropy of space) and all units of length we use to create geometric figures are the same to us (the scale invariance of space). On the other hand, through the process of algebraic simplification, this system of axioms directly provides the Weyl’s system of axioms for Euclidean geometry. The system of axioms, together with its a priori interpretation, offers new views to philosophy and pedagogy of mathematics: (i) it supports the thesis that Euclidean geometry is a priori, (ii) it supports the thesis that in modern mathematics the Weyl’s system of axioms is dominant to the Euclid’s system because it reflects the a priori underlying symmetries, (iii) it gives a new and promising approach to learn geometry which, through the Weyl’s system of axioms, leads from the essential geometric symmetry principles of the mathematical nature directly to modern mathematics. keywords: symmetry, Euclidean geometry, axioms, Weyl’s axioms, phi- losophy of geometry, pedagogy of geometry 1 Introduction The connection of Euclidean geometry with symmetries has a long history. -
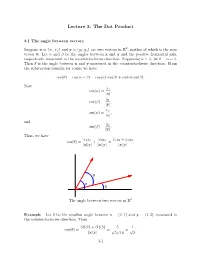
The Dot Product
Lecture 3: The Dot Product 3.1 The angle between vectors 2 Suppose x = (x1; x2) and y = (y1; y2) are two vectors in R , neither of which is the zero vector 0. Let α and β be the angles between x and y and the positive horizontal axis, respectively, measured in the counterclockwise direction. Supposing α β, let θ = α β. Then θ is the angle between x and y measured in the counterclockwise≥ direction. From− the subtraction formula for cosine we have cos(θ) = cos(α β) = cos(α) cos(β) + sin(α) sin(β): − Now x cos(α) = 1 ; x j j y cos(β) = 1 ; y j j x sin(α) = 2 ; x j j and y sin(β) = 2 : y j j Thus, we have x y x y x y + x y cos(θ) = 1 1 + 2 2 = 1 1 2 2 : x y x y x y j jj j j jj j j jj j θ α β The angle between two vectors in R2 Example Let θ be the smallest angle between x = (2; 1) and y = (1; 3), measured in the counterclockwise direction. Then (2)(1) + (1)(3) 5 1 cos(θ) = = = : x y p5p10 p2 j jj j 3-1 Lecture 3: The Dot Product 3-2 Hence 1 1 π θ = cos− = : p2 4 With more work it is possible to show that if x = (x1; x2; x3) and y = (y1; y2; y3) are two vectors in R3, neither of which is the zero vector 0, and θ is the smallest positive angle between x and y, then x y + x y + x y cos(θ) = 1 1 2 2 3 3 x y j jj j 3.2 The dot product n Definition If x = (x1; x2; : : : ; xn) and y = (y1; y2; : : : ; yn) are vectors in R , then the dot product of x and y, denoted x y, is given by · x y = x1y1 + x2y2 + + xnyn: · ··· Note that the dot product of two vectors is a scalar, not another vector. -

The Dot Product
MATH 241-02, Multivariable Calculus, Spring 2019 Section 9.3: The Dot Product How do we multiply two vectors? We have seen that there is a natural geometric and algebraic way to add two vectors. But what about multiplying them together? It turns out that there are two different ways to multiply vectors: the dot product and the cross product. This sections focuses on the dot product. The Dot Product Suppose that v = <a1; b1; c1 > and w = <a2; b2; c2 > are two vectors and let θ be the angle between them. To find θ, place the tails of the two vectors at the same point and measure the angle between them, assuming that 0 ≤ θ ≤ π. If the vectors point in the same direction, then θ = 0; if they point in the opposite direction, then θ = π; and if they are perpendicular, then θ = π=2. We give two equivalent definitions of the dot product. Dot Product: Algebraic Definition: v · w = a1a2 + b1b2 + c1c2 Geometric Definition: v · w = jvj jwj cos θ Thus, the dot product can be found by multiplying corresponding components together and then adding the result. Or, if you know the angle between the two vectors, then the dot product can be found by multiplying the lengths of the two vectors together along with the cosine of the angle between them. If the vectors are two dimensional, then the dot product definition is the same as above except that the c1c2 term in the algebraic definition vanishes. Important Observation: The dot product of two vectors is always a number (a scalar)! Example 1: Compute the dot product of v = <1; −4; 0> and w = <5; 3; −2>. -

Math 3A Notes
5. Orthogonality 5.1. The Scalar Product in Euclidean Space 5.1 The Scalar Product in Rn Thusfar we have restricted ourselves to vector spaces and the operations of addition and scalar multiplication: how else might we combine vectors? You should know about the scalar (dot) and cross products of vectors in R3 The scalar product extends nicely to other vector spaces, while the cross product is another story1 The basic purpose of scalar products is to define and analyze the lengths of and angles between vectors2 1But not for this class! You may see ‘wedge’ products in later classes. 2It is important to note that everything in this chapter, until mentioned, only applies to real vector spaces (where F = R) 5. Orthogonality 5.1. The Scalar Product in Euclidean Space Euclidean Space Definition 5.1.1 Suppose x, y Rn are written with respect to the standard 2 basis e ,..., e f 1 ng 1 The scalar product of x, y is the real numbera (x, y) := xTy = x y + x y + + x y 1 1 2 2 ··· n n 2 x, y are orthogonal or perpendicular if (x, y) = 0 3 n-dimensional Euclidean Space Rn is the vector space of n 1 column vectors R × together with the scalar product aOther notations include x y and x, y · h i Euclidean Space is more than just a collection of co-ordinates vectors: it implicitly comes with notions of angle and length3 Important Fact: (y, x) = yTx = (xTy)T = xTy = (x, y) so the scalar product is symmetric 3To be seen in R2 and R3 shortly 5. -

DOT and CROSS PRODUCT Math 21A, O. Knill
DOT AND CROSS PRODUCT Math 21a, O. Knill DOT PRODUCT. The dot product of two vectors v = (v1; v2; v3) and w = (w1; w2; w3) is defined as v w = i · v1w1 + v2w2 + v3w3. Other notations are v w = (v; w) or < v w > (quantum mechanics) or viw (Einstein i j · j notation) or gij v w (general relativity). The dot product is also called scalar product, or inner product. LENGTH. Using the dot product one can express the length of v as v = pv v. jj jj · The dot product can be recovered from the length only because (v + w; v + w) = (v; v) + (w; w) + 2(v; w) can be solved for (v; w). ANGLE. Because v w 2 = (v w; v w) = v 2 + w 2 2(v; w) is by the cos-theoremjj −equaljj to v −2 + w− 2 2 jjv jj wjj cosjj (φ−), where φ is the angle between the vectorsjj vjjandjjw,jjwe−hajjvejjthe· jjformjj ula v w = v w cos(φ) : · jj jj · jj jj Using the dot product, we can measure angles! FINDING ANGLES BETWEEN VECTORS. Find the angle between the vectors (1; 4; 3) and ( 1; 2; 3). − ANSWER: cos(φ) = 16=(p26p14) 0:839. So that φ = arccos(0:839::) 33◦. ∼ ∼ ORTHOGONALITY. Two vectors are called orthogonal if v w = 0. · PROJECTION. The vector a = w(v w= w 2) is called the projection of v onto w. Its length a = (v w= w 2) is called the scalar projection. The· vjjectorjj b = v a is the component of v orthogonal tojjthejj w-direction.· jj jj − PLANES. -

(Iff) ∈ Belongs to {X|Q(X)}
PRELIMINARIES Some Useful Notations there exists ∃ for all ∀ implies ⇒ equivalent to (iff) ⇔ belongs to ∈ x q(x) set specification { | } A B A is a subset of B ⊂ A B the union of A and B ∪ A B the intersection of A and B ∩ Points and Sets in n R What is n? n R is the set (x1, x2,...,xn) xi are real numbers . R { n| } An element, or a point, of is an n-tuple R (x1, x2,...,xn). n is the Cartesian product of n s. R R Example 2 = = (x, y) x, y belong to R R×R { | R} 1 Recall the following way to construct the product of two sets Definition The Cartesian product of two sets X and Y is the set X Y = (x, y) x belongs to X and y × { | belongs to Y . } A rectangular region in n can be constructed as the R Cartesian product of n intervals. Example [a,b] [c, d]= (x, y) a x b & c y × { | ≤ ≤2 ≤ ≤ d It is a closed subset of . } R Rectangular (Cartesian) Coordinates In Analytic Geometry, the location of a point in three-dimensional space can be determined by its co- ordinates with respect to a coordinate system. Usually the system is rectangular; it means that the coordinate axes are perpendicular to each other. Arrangement of the axes in 3D is according to the “Right-Hand Rule”. 2 Important Open Sets In the one dimensional case, Open neighborhoods Nδ(x0)= x x x0 < δ { | | − | } and deleted open neighborhoods N δ(x0)= x 0 < x x0 < δ { | | − | } are needed in defining ’limit’.