Thai Malena a Ha Una Alta Kama Nina Mitte
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

A Computational Approach for Defining a Signature of Β-Cell Golgi Stress in Diabetes Mellitus
Page 1 of 781 Diabetes A Computational Approach for Defining a Signature of β-Cell Golgi Stress in Diabetes Mellitus Robert N. Bone1,6,7, Olufunmilola Oyebamiji2, Sayali Talware2, Sharmila Selvaraj2, Preethi Krishnan3,6, Farooq Syed1,6,7, Huanmei Wu2, Carmella Evans-Molina 1,3,4,5,6,7,8* Departments of 1Pediatrics, 3Medicine, 4Anatomy, Cell Biology & Physiology, 5Biochemistry & Molecular Biology, the 6Center for Diabetes & Metabolic Diseases, and the 7Herman B. Wells Center for Pediatric Research, Indiana University School of Medicine, Indianapolis, IN 46202; 2Department of BioHealth Informatics, Indiana University-Purdue University Indianapolis, Indianapolis, IN, 46202; 8Roudebush VA Medical Center, Indianapolis, IN 46202. *Corresponding Author(s): Carmella Evans-Molina, MD, PhD ([email protected]) Indiana University School of Medicine, 635 Barnhill Drive, MS 2031A, Indianapolis, IN 46202, Telephone: (317) 274-4145, Fax (317) 274-4107 Running Title: Golgi Stress Response in Diabetes Word Count: 4358 Number of Figures: 6 Keywords: Golgi apparatus stress, Islets, β cell, Type 1 diabetes, Type 2 diabetes 1 Diabetes Publish Ahead of Print, published online August 20, 2020 Diabetes Page 2 of 781 ABSTRACT The Golgi apparatus (GA) is an important site of insulin processing and granule maturation, but whether GA organelle dysfunction and GA stress are present in the diabetic β-cell has not been tested. We utilized an informatics-based approach to develop a transcriptional signature of β-cell GA stress using existing RNA sequencing and microarray datasets generated using human islets from donors with diabetes and islets where type 1(T1D) and type 2 diabetes (T2D) had been modeled ex vivo. To narrow our results to GA-specific genes, we applied a filter set of 1,030 genes accepted as GA associated. -

Ingenuity Pathway Analysis of Differentially Expressed Genes Involved in Signaling Pathways and Molecular Networks in Rhoe Gene‑Edited Cardiomyocytes
INTERNATIONAL JOURNAL OF MOleCular meDICine 46: 1225-1238, 2020 Ingenuity pathway analysis of differentially expressed genes involved in signaling pathways and molecular networks in RhoE gene‑edited cardiomyocytes ZHONGMING SHAO1*, KEKE WANG1*, SHUYA ZHANG2, JIANLING YUAN1, XIAOMING LIAO1, CAIXIA WU1, YUAN ZOU1, YANPING HA1, ZHIHUA SHEN1, JUNLI GUO2 and WEI JIE1,2 1Department of Pathology, School of Basic Medicine Sciences, Guangdong Medical University, Zhanjiang, Guangdong 524023; 2Hainan Provincial Key Laboratory for Tropical Cardiovascular Diseases Research and Key Laboratory of Emergency and Trauma of Ministry of Education, Institute of Cardiovascular Research of The First Affiliated Hospital, Hainan Medical University, Haikou, Hainan 571199, P.R. China Received January 7, 2020; Accepted May 20, 2020 DOI: 10.3892/ijmm.2020.4661 Abstract. RhoE/Rnd3 is an atypical member of the Rho super- injury and abnormalities, cell‑to‑cell signaling and interaction, family of proteins, However, the global biological function and molecular transport. In addition, 885 upstream regulators profile of this protein remains unsolved. In the present study, a were enriched, including 59 molecules that were predicated RhoE‑knockout H9C2 cardiomyocyte cell line was established to be strongly activated (Z‑score >2) and 60 molecules that using CRISPR/Cas9 technology, following which differentially were predicated to be significantly inhibited (Z‑scores <‑2). In expressed genes (DEGs) between the knockout and wild‑type particular, 33 regulatory effects and 25 networks were revealed cell lines were screened using whole genome expression gene to be associated with the DEGs. Among them, the most signifi- chips. A total of 829 DEGs, including 417 upregulated and cant regulatory effects were ‘adhesion of endothelial cells’ and 412 downregulated, were identified using the threshold of ‘recruitment of myeloid cells’ and the top network was ‘neuro- fold changes ≥1.2 and P<0.05. -

1 Mucosal Effects of Tenofovir 1% Gel 1 Florian Hladik1,2,5*, Adam
1 Mucosal effects of tenofovir 1% gel 2 Florian Hladik1,2,5*, Adam Burgener8,9, Lamar Ballweber5, Raphael Gottardo4,5,6, Lucia Vojtech1, 3 Slim Fourati7, James Y. Dai4,6, Mark J. Cameron7, Johanna Strobl5, Sean M. Hughes1, Craig 4 Hoesley10, Philip Andrew12, Sherri Johnson12, Jeanna Piper13, David R. Friend14, T. Blake Ball8,9, 5 Ross D. Cranston11,16, Kenneth H. Mayer15, M. Juliana McElrath2,3,5 & Ian McGowan11,16 6 Departments of 1Obstetrics and Gynecology, 2Medicine, 3Global Health, 4Biostatistics, University 7 of Washington, Seattle, USA; 5Vaccine and Infectious Disease Division, 6Public Health Sciences 8 Division, Fred Hutchinson Cancer Research Center, Seattle, USA; 7Vaccine and Gene Therapy 9 Institute-Florida, Port St. Lucie, USA; 8Department of Medical Microbiology, University of 10 Manitoba, Winnipeg, Canada; 9National HIV and Retrovirology Laboratories, Public Health 11 Agency of Canada; 10University of Alabama, Birmingham, USA; 11University of Pittsburgh 12 School of Medicine, Pittsburgh, USA; 12FHI 360, Durham, USA; 13Division of AIDS, NIAID, NIH, 13 Bethesda, USA; 14CONRAD, Eastern Virginia Medical School, Arlington, USA; 15Fenway Health, 14 Beth Israel Deaconess Hospital and Harvard Medical School, Boston, USA; 16Microbicide Trials 15 Network, Magee-Women’s Research Institute, Pittsburgh, USA. 16 Adam Burgener and Lamar Ballweber contributed equally to this work. 17 *Corresponding author E-mail: [email protected] 18 Address reprint requests to Florian Hladik at [email protected] or Ian McGowan at 19 [email protected]. 20 Abstract: 150 words. Main text (without Methods): 2,603 words. Methods: 3,953 words 1 21 ABSTRACT 22 Tenofovir gel is being evaluated for vaginal and rectal pre-exposure prophylaxis against HIV 23 transmission. -

Noncoding Rnas As Novel Pancreatic Cancer Targets
NONCODING RNAS AS NOVEL PANCREATIC CANCER TARGETS by Amy Makler A Thesis Submitted to the Faculty of The Charles E. Schmidt College of Science In Partial Fulfillment of the Requirements for the Degree of Master of Science Florida Atlantic University Boca Raton, FL August 2018 Copyright 2018 by Amy Makler ii ACKNOWLEDGEMENTS I would first like to thank Dr. Narayanan for his continuous support, constant encouragement, and his gentle, but sometimes critical, guidance throughout the past two years of my master’s education. His faith in my abilities and his belief in my future success ensured I continue down this path of research. Working in Dr. Narayanan’s lab has truly been an unforgettable experience as well as a critical step in my future endeavors. I would also like to extend my gratitude to my committee members, Dr. Binninger and Dr. Jia, for their support and suggestions regarding my thesis. Their recommendations added a fresh perspective that enriched our initial hypothesis. They have been indispensable as members of my committee, and I thank them for their contributions. My parents have been integral to my successes in life and their support throughout my education has been crucial. They taught me to push through difficulties and encouraged me to pursue my interests. Thank you, mom and dad! I would like to thank my boyfriend, Joshua Disatham, for his assistance in ensuring my writing maintained a logical progression and flow as well as his unwavering support. He was my rock when the stress grew unbearable and his encouraging words kept me pushing along. -

Conservation of Core Gene Expression in Vertebrate Tissues
Open Access Research article Conservation of core gene expression in vertebrate tissues Esther T Chan*¶, Gerald T Quon†¶, Gordon Chua‡¶¥, Tomas Babak¶#, Miles Trochesset†‡, Ralph A Zirngibl*, Jane Aubin*, Michael JH Ratcliffe§, Andrew Wilde*, Michael Brudno†‡¶, Quaid D Morris*†‡¶ and Timothy R Hughes*‡¶ Addresses: *Department of Molecular Genetics, †Department of Computer Science, ‡Banting and Best Department of Medical Research, §Department of Immunology and Sunnybrook Research Institute, and ¶Terrence Donnelly Centre for Cellular and Biomolecular Research, University of Toronto, 160 College Street, Toronto, Ontario M5S 3E1, Canada. ¥Current address: Department of Biological Sciences, University of Calgary, 2500 University Drive NW, Calgary, Alberta, T2N 1N4 Canada. #Current address: Rosetta Inpharmatics, 401 Terry Avenue North, Seattle, WA 98109, USA. Correspondence: Quaid D Morris. Email: [email protected]. Timothy R Hughes. Email: [email protected] Published: 16 April 2009 Received: 23 January 2009 Revised: 12 March 2009 Journal of Biology 2009, 8:33 (doi:10.1186/jbiol130) Accepted: 18 March 2009 The electronic version of this article is the complete one and can be found online at http://jbiol.com/content/8/3/33 © 2009 Chan et al.; licensee BioMed Central Ltd. This is an Open Access article distributed under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/2.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. Abstract Background Vertebrates share the same general body plan and organs, possess related sets of genes, and rely on similar physiological mechanisms, yet show great diversity in morphology, habitat and behavior. -

Mass Spectrometry-Based Proteomics Reveals Distinct Mechanisms of Astrocyte Protein Secretion
University of Pennsylvania ScholarlyCommons Publicly Accessible Penn Dissertations Summer 2009 Mass Spectrometry-Based Proteomics Reveals Distinct Mechanisms of Astrocyte Protein Secretion Todd M. Greco University of Pennsylvania, [email protected] Follow this and additional works at: https://repository.upenn.edu/edissertations Part of the Cell Biology Commons, and the Molecular and Cellular Neuroscience Commons Recommended Citation Greco, Todd M., "Mass Spectrometry-Based Proteomics Reveals Distinct Mechanisms of Astrocyte Protein Secretion" (2009). Publicly Accessible Penn Dissertations. 22. https://repository.upenn.edu/edissertations/22 This paper is posted at ScholarlyCommons. https://repository.upenn.edu/edissertations/22 For more information, please contact [email protected]. Mass Spectrometry-Based Proteomics Reveals Distinct Mechanisms of Astrocyte Protein Secretion Abstract The ability of astrocytes to secrete proteins subserves many of its known function, such as synapse formation during development and extracellular matrix remodeling after cellular injury. Protein secretion may also play an important, but less clear, role in the propagation of inflammatory responses and neurodegenerative disease pathogenesis. While potential astrocyte-secreted proteins may number in the thousands, known astrocyte-secreted proteins are less than 100. To address this fundamental deficiency, mass spectrometry-based proteomics and bioinformatic tools were utilized for global discovery, comparison, and quantification of astrocyte-secreted proteins. A primary mouse astrocyte cell culture model was used to generate a collection of astrocyte-secreted proteins termed the astrocyte secretome. A multidimensional protein and peptide separation approach paired with mass spectrometric analysis interrogated the astrocyte secretome under control and cytokine-exposed conditions, identifying cytokine- induced secreted proteins, while extending the depth of known astrocyte-secreted proteins to 169. -

Mining Exosomal Genes for Pancreatic Cancer Targets AMY MAKLER and RAMASWAMY NARAYANAN
CANCER GENOMICS & PROTEOMICS 14 : 161-172 (2017) doi:10.21873/cgp.20028 Mining Exosomal Genes for Pancreatic Cancer Targets AMY MAKLER and RAMASWAMY NARAYANAN Department of Biological Sciences, Charles E. Schmidt College of Science, Florida Atlantic University, Boca Raton, FL, U.S.A. Abstract. Background: Exosomes, cell-derived vesicles Pancreatic ductal adenocarcinoma is predicted to overtake encompassing lipids, DNA, proteins coding genes and breast cancer and become the third leading cause of cancer- noncoding RNAs (ncRNAs) are present in diverse body related deaths in the United States (1). Pancreatic cancer has fluids. They offer novel biomarker and drug therapy a very poor prognosis in most patients and seriously lacks potential for diverse diseases, including cancer. Materials effective therapies. Early diagnosis continues to be a and Methods: Using gene ontology, exosomal genes challenge in clinics due to advanced-stage presentation. database and GeneCards metadata analysis tool s, a Metastasis and resistance to current chemotherapeutics further database of cancer-associated protein coding genes and contributes to the poor prognosis (2). Most therapies for ncRNAs (n=2,777) was established. Variant analysis, pancreatic cancer still revolve around the use of ineffective expression profiling and pathway mapping were used to cytotoxic drugs. Novel drug targets and early-stage identify putative pancreatic cancer exosomal gene biomarkers are urgently needed for this untreatable cancer. candidates. Results: Five hundred and seventy-five protein- Exosomes are 40-150 nm extracellular vesicles (EVs) coding genes, 26 RNA genes and one pseudogene directly released by all cell types (3, 4). Exosomes are highly associated with pancreatic cancer were identified in the heterogeneous (5) and likely reflect the phenotype of the cell study. -

Genome-Wide Gene Expression Profiling of Randall's Plaques In
CLINICAL RESEARCH www.jasn.org Genome-Wide Gene Expression Profiling of Randall’s Plaques in Calcium Oxalate Stone Formers † † Kazumi Taguchi,* Shuzo Hamamoto,* Atsushi Okada,* Rei Unno,* Hideyuki Kamisawa,* Taku Naiki,* Ryosuke Ando,* Kentaro Mizuno,* Noriyasu Kawai,* Keiichi Tozawa,* Kenjiro Kohri,* and Takahiro Yasui* *Department of Nephro-urology, Nagoya City University Graduate School of Medical Sciences, Nagoya, Japan; and †Department of Urology, Social Medical Corporation Kojunkai Daido Hospital, Daido Clinic, Nagoya, Japan ABSTRACT Randall plaques (RPs) can contribute to the formation of idiopathic calcium oxalate (CaOx) kidney stones; however, genes related to RP formation have not been identified. We previously reported the potential therapeutic role of osteopontin (OPN) and macrophages in CaOx kidney stone formation, discovered using genome-recombined mice and genome-wide analyses. Here, to characterize the genetic patho- genesis of RPs, we used microarrays and immunohistology to compare gene expression among renal papillary RP and non-RP tissues of 23 CaOx stone formers (SFs) (age- and sex-matched) and normal papillary tissue of seven controls. Transmission electron microscopy showed OPN and collagen expression inside and around RPs, respectively. Cluster analysis revealed that the papillary gene expression of CaOx SFs differed significantly from that of controls. Disease and function analysis of gene expression revealed activation of cellular hyperpolarization, reproductive development, and molecular transport in papillary tissue from RPs and non-RP regions of CaOx SFs. Compared with non-RP tissue, RP tissue showed upregulation (˃2-fold) of LCN2, IL11, PTGS1, GPX3,andMMD and downregulation (0.5-fold) of SLC12A1 and NALCN (P,0.01). In network and toxicity analyses, these genes associated with activated mitogen- activated protein kinase, the Akt/phosphatidylinositol 3-kinase pathway, and proinflammatory cytokines that cause renal injury and oxidative stress. -
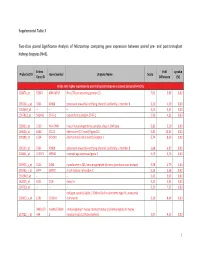
Supplemental Table 3 Two-Class Paired Significance Analysis of Microarrays Comparing Gene Expression Between Paired
Supplemental Table 3 Two‐class paired Significance Analysis of Microarrays comparing gene expression between paired pre‐ and post‐transplant kidneys biopsies (N=8). Entrez Fold q‐value Probe Set ID Gene Symbol Unigene Name Score Gene ID Difference (%) Probe sets higher expressed in post‐transplant biopsies in paired analysis (N=1871) 218870_at 55843 ARHGAP15 Rho GTPase activating protein 15 7,01 3,99 0,00 205304_s_at 3764 KCNJ8 potassium inwardly‐rectifying channel, subfamily J, member 8 6,30 4,50 0,00 1563649_at ‐‐ ‐‐ ‐‐ 6,24 3,51 0,00 1567913_at 541466 CT45‐1 cancer/testis antigen CT45‐1 5,90 4,21 0,00 203932_at 3109 HLA‐DMB major histocompatibility complex, class II, DM beta 5,83 3,20 0,00 204606_at 6366 CCL21 chemokine (C‐C motif) ligand 21 5,82 10,42 0,00 205898_at 1524 CX3CR1 chemokine (C‐X3‐C motif) receptor 1 5,74 8,50 0,00 205303_at 3764 KCNJ8 potassium inwardly‐rectifying channel, subfamily J, member 8 5,68 6,87 0,00 226841_at 219972 MPEG1 macrophage expressed gene 1 5,59 3,76 0,00 203923_s_at 1536 CYBB cytochrome b‐245, beta polypeptide (chronic granulomatous disease) 5,58 4,70 0,00 210135_s_at 6474 SHOX2 short stature homeobox 2 5,53 5,58 0,00 1562642_at ‐‐ ‐‐ ‐‐ 5,42 5,03 0,00 242605_at 1634 DCN decorin 5,23 3,92 0,00 228750_at ‐‐ ‐‐ ‐‐ 5,21 7,22 0,00 collagen, type III, alpha 1 (Ehlers‐Danlos syndrome type IV, autosomal 201852_x_at 1281 COL3A1 dominant) 5,10 8,46 0,00 3493///3 IGHA1///IGHA immunoglobulin heavy constant alpha 1///immunoglobulin heavy 217022_s_at 494 2 constant alpha 2 (A2m marker) 5,07 9,53 0,00 1 202311_s_at -

Proteomic Analysis Identifies Distinct Glomerular Extracellular Matrix In
CLINICAL RESEARCH www.jasn.org Proteomic Analysis Identifies Distinct Glomerular Extracellular Matrix in Collapsing Focal Segmental Glomerulosclerosis Michael L. Merchant,1 Michelle T. Barati,1 Dawn J. Caster ,1 Jessica L. Hata,2 Liliane Hobeika,3 Susan Coventry,2 Michael E. Brier,1 Daniel W. Wilkey,1 Ming Li,1 Ilse M. Rood,4 Jeroen K. Deegens,4 Jack F. Wetzels,4 Christopher P. Larsen,5 Jonathan P. Troost,6 Jeffrey B. Hodgin,7 Laura H. Mariani,8 Matthias Kretzler ,8 Jon B. Klein,1,9 and Kenneth R. McLeish1 Due to the number of contributing authors, the affiliations are listed at the end of this article. ABSTRACT Background The mechanisms leading to extracellular matrix (ECM) replacement of areas of glomerular capillaries in histologic variants of FSGS are unknown. This study used proteomics to test the hypothesis that glomerular ECM composition in collapsing FSGS (cFSGS) differs from that of other variants. Methods ECM proteins in glomeruli from biopsy specimens of patients with FSGS not otherwise specified (FSGS-NOS) or cFSGS and from normal controls were distinguished and quantified using mass spectrom- etry, verified and localized using immunohistochemistry (IHC) and confocal microscopy, and assessed for gene expression. The analysis also quantified urinary excretion of ECM proteins and peptides. Results Of 58 ECM proteins that differed in abundance between cFSGS and FSGS-NOS, 41 were more abundant in cFSGS and 17 in FSGS-NOS. IHC showed that glomerular tuft staining for cathepsin B, ca- thepsin C, and annexin A3 in cFSGS was significantly greater than in other FSGS variants, in minimal change disease, or in membranous nephropathy. -
Whsc1l1 Regulates Estrogen Receptor Activity in Sum44 Breast Cancer Cells Jonathan Curtis Irish Wayne State University
Wayne State University Wayne State University Dissertations 1-1-2016 Whsc1l1 Regulates Estrogen Receptor Activity In Sum44 Breast Cancer Cells Jonathan Curtis Irish Wayne State University, Follow this and additional works at: https://digitalcommons.wayne.edu/oa_dissertations Part of the Oncology Commons Recommended Citation Irish, Jonathan Curtis, "Whsc1l1 Regulates Estrogen Receptor Activity In Sum44 Breast Cancer Cells" (2016). Wayne State University Dissertations. 1641. https://digitalcommons.wayne.edu/oa_dissertations/1641 This Open Access Dissertation is brought to you for free and open access by DigitalCommons@WayneState. It has been accepted for inclusion in Wayne State University Dissertations by an authorized administrator of DigitalCommons@WayneState. WHSC1L1 REGULATES ESTROGEN RECEPTOR ACTIVITY IN SUM44 BREAST CANCER CELLS by JONATHAN CURTIS IRISH DISSERTATION Submitted to the Graduate School of Wayne State University, Detroit, Michigan in partial fulfillment of the requirements for the degree of DOCTOR OF PHILOSOPHY 2016 MAJOR: Cancer Biology Approved By: Advisor Date © COPYRIGHT BY JONATHAN CURTIS IRISH 2016 All Rights Reserved DEDICATION I dedicate this work to my loving, patient wife Cesira. To my parents, Lori and Sean, who have been unwavering in their support of me and my family during my temporally and geographically long educational journey. Finally, to my grandparents and aunt, Curtis, Norma, and Linda, for motivating me to study cancer. ii ACKNOWLEDGEMENTS I would like to thank my mentor, Dr. Ethier, for providing an environment where I could learn think critically and become proficient at applying the scientific method to problems in biology. I owe my future in science in no small part to the time spent with Dr. -
BT-CSC Dznep Treated Up-Regulated Genes Gene Symbol Gene Name M
BT-CSC DZNep treated up-regulated genes Gene Symbol Gene Name M Value KRTAP19-1 keratin associated protein 19-1 5.091638802 VPS53 vacuolar protein sorting 53 homolog (S. cerevisiae) 4.920143235 HEATR2 HEAT repeat containing 2 4.545255947 BRAF v-raf murine sarcoma viral oncogene homolog B1 4.404531741 PCDH7 protocadherin 7 4.378536321 PRKACB protein kinase, cAMP-dependent, catalytic, beta 4.337185544 C6orf166 chromosome 6 open reading frame 166 4.244909909 HIST1H3H histone cluster 1, H3h 4.085723721 CRAMP1L Crm, cramped-like (Drosophila) 3.811674874 RPS15 ribosomal protein S15 3.776296646 EPPK1 epiplakin 1 3.724368921 LAMA4 laminin, alpha 4 3.634864123 SEMA3C sema domain, immunoglobulin domain (Ig), short basic domain, secreted, (semaphorin) 3C 3.504490549 MALAT1 metastasis associated lung adenocarcinoma transcript 1 (non-protein coding) 3.3915307 EPC1 enhancer of polycomb homolog 1 (Drosophila) 3.37404925 ANKRD13C ankyrin repeat domain 13C 3.367543301 HIST2H2BE histone cluster 2, H2be 3.331087945 LOC158301 hypothetical protein LOC158301 3.328891352 LOC56755 hypothetical protein LOC56755 3.233203867 HEXIM1 hexamethylene bis-acetamide inducible 1 3.231227044 SYT11 synaptotagmin XI 3.217641148 KRTAP7-1 keratin associated protein 7-1 3.202664068 TEX14 testis expressed 14 3.19144479 TUG1 taurine upregulated gene 1 3.15045817 KLHL28 kelch-like 28 (Drosophila) 3.074070618 KRTAP19-3 keratin associated protein 19-3 3.056583425 DOCK1 dedicator of cytokinesis 1 3.053526521 NHEDC1 Na+/H+ exchanger domain containing 1 3.013610505 SFN stratifin 3.000939496