An Introduction to the Improved SAS Data Integration Studio Batch
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Operating Systems
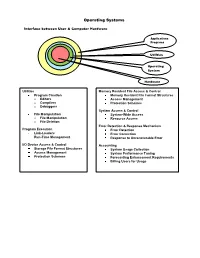
Operating Systems Interface between User & Computer Hardware Applications Programs Utilities Operating System Hardware Utilities Memory Resident File Access & Control Program Creation Memory Resident File Format Structures o Editors Access Management o Compilers Protection Schemes o Debuggers System Access & Control File Manipulation System-Wide Access o File Manipulation Resource Access o File Deletion Error Detection & Response Mechanism Program Execution Error Detection Link-Loaders Error Correction Run-Time Management Response to Unrecoverable Error I/O Device Access & Control Accounting Storage File Format Structures System Usage Collection Access Management System Performance Tuning Protection Schemes Forecasting Enhancement Requirements Billing Users for Usage Resource Manager O/S KernelKernel I/O Controller Printers, Keyboards, I/O Controller Monitors, Portions of Cameras, the O/S Etc. currently in use Computer Main System Memory Portions of Various I/O Application Devices Programs Currently in use Operating System Data Application Programs I/O Controller Storage Processor Processor Data Processor Processor Operation Allocation of Main Memory is made jointly by both the O/S and Memory Management Hardware O/S controls access to I/O devices by Application Programs O/S controls access to and use of files O/S controls access to and use of the processors, i.e., how much time can be allocated to the execution of a particular Application Program Classification of Operating Systems Interactive O/S Keyboard & Monitor Access to O/S Immediate, -

Chapter 10 Introduction to Batch Files
Instructor’s Manual Chapter 10 Lecture Notes Introduction to Batch Files Chapter 10 Introduction to Batch Files LEARNING OBJECTIVES 1. Compare and contrast batch and interactive processing. 2. Explain how batch files work. 3. Explain the purpose and function of the REM, ECHO, and PAUSE commands. 4. Explain how to stop or interrupt the batch file process. 5. Explain the function and use of replaceable parameters in batch files. 6. Explain the function of pipes, filters, and redirection in batch files. STUDENT OUTCOMES 1. Use Edit to write batch files. 2. Use COPY CON to write batch files. 3. Write and execute a simple batch file. 4. Write a batch file to load an application program. 5. Use the REM, PAUSE, and ECHO commands in batch files. 6. Terminate a batch file while it is executing. 7. Write batch files using replaceable parameters. 8. Write a batch file using pipes, filters, and redirection. CHAPTER SUMMARY 1. Batch processing means running a series of instructions without interruption. 2. Interactive processing allows the user to interface directly with the computer and update records immediately. 3. Batch files allow a user to put together a string of commands and execute them with one command. 4. Batch files must have the .BAT or .CMD file extension. 5. Windows looks first internally for a command, then for a .COM files extension, then for a .EXE file extension, and finally for a .BAT or .CMD file extension. 6. Edit is a full-screen text editor used to write batch files. 7. A word processor, if it has a means to save files in ASCII, can be used to write batch files. -

Uni Hamburg – Mainframe Summit 2010 Z/OS – the Mainframe Operating System
Uni Hamburg – Mainframe Summit 2010 z/OS – The Mainframe Operating System Appendix 2 – JES and Batchprocessing Redelf Janßen IBM Technical Sales Mainframe Systems [email protected] © Copyright IBM Corporation 2010 Course materials may not be reproduced in whole or in part without the prior written permission of IBM. 4.0.1 Introduction to the new mainframe Chapter 7: Batch processing and the Job Entry Subsystem (JES) © Copyright IBM Corp., 2010. All rights reserved. Introduction to the new mainframe Chapter 7 objectives Be able to: • Give an overview of batch processing and how work is initiated and managed in the system. • Explain how the job entry subsystem (JES) governs the flow of work through a z/OS system. © Copyright IBM Corp., 2010. All rights reserved. 3 Introduction to the new mainframe Key terms in this chapter • batch processing • procedure • execution • purge • initiator • queue • job • spool • job entry subsystem (JES) • symbolic reference • output • workload manager (WLM) © Copyright IBM Corp., 2010. All rights reserved. 4 Introduction to the new mainframe What is batch processing? Much of the work running on z/OS consists of programs called batch jobs. Batch processing is used for programs that can be executed: • With minimal human interaction • At a scheduled time or on an as-needed basis. After a batch job is submitted to the system for execution, there is normally no further human interaction with the job until it is complete. © Copyright IBM Corp., 2010. All rights reserved. 5 Introduction to the new mainframe What is JES? In the z/OS operating system, JES manages the input and output job queues and data. -

Approaches to Optimize Batch Processing on Z/OS
Front cover Approaches to Optimize Batch Processing on z/OS Apply the latest z/OS features Analyze bottlenecks Evaluate critical path Alex Louwe Kooijmans Elsie Ramos Jan van Cappelle Lydia Duijvestijn Tomohiko Kaneki Martin Packer ibm.com/redbooks Redpaper International Technical Support Organization Approaches to Optimize Batch Processing on z/OS October 2012 REDP-4816-00 Note: Before using this information and the product it supports, read the information in “Notices” on page v. First Edition (October 2012) This edition applies to all supported z/OS versions and releases. This document created or updated on October 24, 2012. © Copyright International Business Machines Corporation 2012. All rights reserved. Note to U.S. Government Users Restricted Rights -- Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. Contents Notices . .v Trademarks . vi Preface . vii The team who wrote this paper . vii Now you can become a published author, too! . viii Comments welcome. viii Stay connected to IBM Redbooks . ix Chapter 1. Getting started . 1 1.1 The initial business problem statement. 2 1.2 How to clarify the problem statement . 3 1.3 Process to formulate a good problem statement . 3 1.4 How to create a good business case . 5 1.5 Analysis methodology . 6 1.5.1 Initialization . 6 1.5.2 Analysis. 6 1.5.3 Implementation . 10 Chapter 2. Analysis steps. 13 2.1 Setting the technical strategy . 14 2.2 Understanding the batch landscape . 15 2.2.1 Identifying where batch runs and the available resources . 15 2.2.2 Job naming conventions . 15 2.2.3 Application level performance analysis. -

Parallel Processing Here at the School of Statistics
Parallel Processing here at the School of Statistics Charles J. Geyer School of Statistics University of Minnesota http://www.stat.umn.edu/~charlie/parallel/ 1 • batch processing • R package multicore • R package rlecuyer • R package snow • grid engine (CLA) • clusters (MSI) 2 Batch Processing This is really old stuff (from 1975). But not everyone knows it. If you do the following at a unix prompt nohup nice -n 19 some job & where \some job" is replaced by an actual job, then • the job will run in background (because of &). • the job will not be killed when you log out (because of nohup). • the job will have low priority (because of nice -n 19). 3 Batch Processing (cont.) For example, if foo.R is a plain text file containing R commands, then nohup nice -n 19 R CMD BATCH --vanilla foo.R & executes the commands and puts the printout in the file foo.Rout. And nohup nice -n 19 R CMD BATCH --no-restore foo.R & executes the commands, puts the printout in the file foo.Rout, and saves all created R objects in the file .RData. 4 Batch Processing (cont.) nohup nice -n 19 R CMD BATCH foo.R & is a really bad idea! It reads in all the objects in the file .RData (if one is present) at the beginning. So you have no idea whether the results are reproducible. Always use --vanilla or --no-restore except when debugging. 5 Batch Processing (cont.) This idiom has nothing to do with R. If foo is a compiled C or C++ or Fortran main program that doesn't have command line arguments (or a shell, Perl, Python, or Ruby script), then nohup nice -n 19 foo & runs it. -

MTS on Wikipedia Snapshot Taken 9 January 2011
MTS on Wikipedia Snapshot taken 9 January 2011 PDF generated using the open source mwlib toolkit. See http://code.pediapress.com/ for more information. PDF generated at: Sun, 09 Jan 2011 13:08:01 UTC Contents Articles Michigan Terminal System 1 MTS system architecture 17 IBM System/360 Model 67 40 MAD programming language 46 UBC PLUS 55 Micro DBMS 57 Bruce Arden 58 Bernard Galler 59 TSS/360 60 References Article Sources and Contributors 64 Image Sources, Licenses and Contributors 65 Article Licenses License 66 Michigan Terminal System 1 Michigan Terminal System The MTS welcome screen as seen through a 3270 terminal emulator. Company / developer University of Michigan and 7 other universities in the U.S., Canada, and the UK Programmed in various languages, mostly 360/370 Assembler Working state Historic Initial release 1967 Latest stable release 6.0 / 1988 (final) Available language(s) English Available programming Assembler, FORTRAN, PL/I, PLUS, ALGOL W, Pascal, C, LISP, SNOBOL4, COBOL, PL360, languages(s) MAD/I, GOM (Good Old Mad), APL, and many more Supported platforms IBM S/360-67, IBM S/370 and successors History of IBM mainframe operating systems On early mainframe computers: • GM OS & GM-NAA I/O 1955 • BESYS 1957 • UMES 1958 • SOS 1959 • IBSYS 1960 • CTSS 1961 On S/360 and successors: • BOS/360 1965 • TOS/360 1965 • TSS/360 1967 • MTS 1967 • ORVYL 1967 • MUSIC 1972 • MUSIC/SP 1985 • DOS/360 and successors 1966 • DOS/VS 1972 • DOS/VSE 1980s • VSE/SP late 1980s • VSE/ESA 1991 • z/VSE 2005 Michigan Terminal System 2 • OS/360 and successors -

Implementing Batch Processing in Java EE 7 Ivar Grimstad
Implementing Batch Processing in Java EE 7 Ivar Grimstad Batch - JavaLand 2014 @ivar_grimstad About Ivar Grimstad @ivar_grimstad Batch - JavaLand 2014 @ivar_grimstad batch (plural batches) The quantity of bread or other baked goods baked at one time. We made a batch of cookies to take to the party. Source: http://en.wiktionary.org/wiki/batch Batch - JavaLand 2014 @ivar_grimstad Content • Batch Applications • Batch in Java EE 7 • Demo • Wrap-Up Batch - JavaLand 2014 @ivar_grimstad History Batch - JavaLand 2014 @ivar_grimstad Batch Applications Batch - JavaLand 2014 @ivar_grimstad Common Usages • Bulk database updates • Image processing • Conversions Batch - JavaLand 2014 @ivar_grimstad Advantages of Batch Processing • No User Interaction • Utilize Batch Windows • Repetitive Work Batch - JavaLand 2014 @ivar_grimstad Disadvantages of Batch Processing • Training • Difficult Debugging • Costly Batch - JavaLand 2014 @ivar_grimstad To The Rescue Batch Frameworks Batch - JavaLand 2014 @ivar_grimstad Batch Frameworks • Jobs, steps, decision elements, relationships • Parallel or sequential processing • State • Launch, pause and resume • Error handling Batch - JavaLand 2014 @ivar_grimstad Requirements of Batch Applications Large Data Volume Automation Robustness Reliability Performance Batch - JavaLand 2014 @ivar_grimstad Batch Processing in Java EE 7 Batch - JavaLand 2014 @ivar_grimstad The Batch Processing Framework • Batch Runtime • Job Specification • Java API – Runtime interaction – Implementation Batch - JavaLand 2014 @ivar_grimstad Batch -

Operating System (OS) - Early OS
Operating System (OS) - Early OS Unit-1 Virtual University Of Kumar Dept. Of Computing BCA – 2nd Year Objective – Operating System • Introduction to OS Early OS Buffering SPOOLING Different kinds of operating systems (OS) • Process Management • CPU Scheduling concepts Operating System(OS) - Early OS 2 Early OS • Efficiency consideration is more important than convenience • Different Phases / Generations in the past 40 years ( In decade interval) • 1940’s, earliest digital computers has NO OS • Machine language on PUNCHED CARD was used • Later ASSEMBLY LANGUAGE was developed to increase speed of programming. Operating System(OS) - Early OS 3 Early OS • 1st OS by 1950’s for IBM701 by GM RESEARCH Laboratories One job at a time Smoothed the transition between jobs to increase the UTILIZATION of computer system • Program's and Data's were submitted in groups or batches Called “Single stream batch processing system” Operating System(OS) - Early OS 4 The 1960`s Batch processing systems • Contains – Card reader – Card punches – Printers – Tape drives & Disk Drives Development of multiprogramming • Several programs are in memory at once • Processor switch from job to job as needed, and keeps the peripheral devices in use Operating System(OS) - Early OS 5 The 1960`s Advanced OS developed to service multiple “Interactive users” at once – Interactive users communicate to the computer via TERMINALS which are online (Directly connected) to computer. Timesharing systems were developed to multi program large numbers of simultaneous users • Mostly multimode systems – Support batch processing & real-time • Real-time = Supplies immediate response Operating System(OS) - Early OS 6 The 1970`s • Mostly Multi-mode Time-sharing systems Support • Batch processing • Time sharing • Real-time applications TCP/IP communication standard of dept.of.defence (USA) widely used LAN was made practical & Economical by Ethernet standard. -

Introduction-To-Mainframes.Pdf
Mainframe The term ‘MainFrame’ brings to mind a giant room of electronic parts that is a computer, referring to the original CPU cabinet in a computer of the mid-1960’s. Today, Mainframe refers to a class of ultra-reliable large and medium-scale servers designed for carrier-class and enterprise-class systems operations. Mainframes are costly, due to the support of symmetric multiprocessing (SMP) and dozens of central processors existing within in a single system. Mainframes are highly scalable. Through the addition of clusters, high-speed caches and volumes of memory, they connect to terabyte holding data subsystems. Mainframe computer Mainframe is a very large and expensive computer capable of supporting hundreds, or even thousands, of users simultaneously. In the hierarchy that starts with a simple microprocessor at the bottom and moves to supercomputers at the top, mainframes are just below supercomputers. In some ways, mainframes are more powerful than supercomputers because they support more simultaneous programs. But supercomputers can execute a single program faster than a mainframe. The distinction between small mainframes and minicomputers is vague, depending really on how the manufacturer wants to market its machines. Modern mainframe computers have abilities not so much defined by their single task computational speed (usually defined as MIPS — Millions of Instructions Per Second) as by their redundant internal engineering and resulting high reliability and security, extensive input-output facilities, strict backward compatibility with older software, and high utilization rates to support massive throughput. These machines often run for years without interruption, with repairs and hardware upgrades taking place during normal operation. -

Xerox Batch Processing Monitor (BPM) and XEROX Batch Time-Sharing Monitor (BTM) Sigma 5-8 Computers
Xerox Data Systems Xerox Batch Processing Monitor (BPM) and XEROX Batch Time-Sharing Monitor (BTM) Sigma 5-8 Computers System Management Reference Manual Xerox Data Systems XEROX l01 South Aviation Boulevard ~I Segundo, California 90245 213679-4511 Xerox Batch Processing Monitor (BPM) and Batch Time-Sharing Monitor (BTM) Sigma 5-8 Computers System Management Reference Manual FIRST EDITION 90 17 41A Decembe r 1971 Price; $7.50 © 1971, Xerox Corporation Printed in U.S.A. NOTICE This manual covers the FOl version of BPM/BTM. Much of the information contained in the manual came from the BPM/BP, RT Reference Manual (90 09 54) and the BTM/TS Reference Manual (90 15 77). Although this information is presently duplicated, the duplicate information will be deleted from those manuals during the next revision and reprint. RELATED PUBLICATIONS Publi cation No. Xerox Sigma 5 Computer/Reference Manual 900959 Xerox Sigma 6 Computer/Reference Manual 90 17 13 Xerox Sigma 7 Computer/Reference Manual 900950 Xerox Sigma 8 Computer/Reference Manual 90 1749 Xerox Batch Processing Monitor (BPM)/BP, RT Reference Manual 900954 Xerox Batch Processi ng Monitor (BPM) and Batch Time-Shari ng Monitor (BT M)/ OPS Reference Manual 90 11 98 Xerox Batch Time-Sharing Monitor (BTM)/fS Reference Manual 90 15 77 Xerox Batch Time-Sharing Monitor (BTM)/fS User's Guide 90 16 79 Xerox Batch Processing Monitor (BPM)/System Technical Manual 90 15 28 Xerox BTM/BPM/UTS Overlay Loader Technical Manual 90 18 03 Xerox Symbol/LN, OPS Reference Manual 90 1790 Xerox Meta-Symbol/LN, OPS -

Z/OS Basic Skills Information Center: Mainframe Concepts
z/OS Basic Skills Information Center Mainframe concepts z/OS Basic Skills Information Center Mainframe concepts Note Before using this information and the product it supports, read the information in “Notices” on page 45. This edition applies to z/OS (product number 5694-A01). We appreciate your comments about this publication. Comment on specific errors or omissions, accuracy, organization, subject matter, or completeness of this book. The comments you send should pertain to only the information in this manual or product and the way in which the information is presented. For technical questions and information about products and prices, contact your IBM branch office, your IBM business partner, or your authorized remarketer. When you send comments to IBM, you grant IBM a nonexclusive right to use or distribute your comments in any way it believes appropriate without incurring any obligation to you. IBM or any other organizations will only use the personal information that you supply to contact you about the issues that you state on this form. Send your comments through this Web site: http://publib.boulder.ibm.com/infocenter/zoslnctr/v1r7/ index.jsp?topic=/com.ibm.zcontact.doc/webqs.html © Copyright International Business Machines Corporation 2005, 2008. US Government Users Restricted Rights – Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. Contents Introduction to the mainframe . .v Mainframe operating system: z/TPF . .22 Chapter 1. The value of the mainframe Chapter 2. Mainframe hardware today . .1 concepts . .23 The S/360: A turning point in mainframe history . .1 Mainframe hardware: Terminology . .23 Mainframe architecture: Secure, compatible, and still Mainframe hardware: Evolving design . -

Operating System of the VX/VPP300/VPP700 Series of Vector-Parallel Supercomputer Systems
UDC 681.3.06 Operating System of the VX/VPP300/ VPP700 Series of Vector-Parallel Supercomputer Systems VYuji Koeda (Manuscript received April 29, 1997) The computers used in science and technology are generally either low-end, high cost-performance machines owned by individual research and development sec- tions, or high-end ultra high-speed machines. This paper describes the features of the UXP/V operating system of the VX/ VPP300/VPP700 series of vector parallel supercomputers, which were developed to flexibly cover the requirements for science and technology computing. It also looks at the following important topics regarding vector parallel supercomputers : - The method of allocating resources such as the CPU and memory - The scheduling technique for batch processing - The technology used to achieve high-speed I/O processing and network process- ing This paper also describes a function for easy installation and administration and a strengthened operational management function for the computer center. 1. Introduction 2. Development history The cost effectiveness of science and technol- The history of UXP/V began with UTS/M, ogy calculation environments has rapidly im- which is a UNIXNote1) system that operates on a proved due to increases in the processing speeds mainframe. UTS/M was based on the UTS, which of high-end EWSs and the falling prices of super- was developed between 1982 and 1985 by Amdahl computers and minicomputers. These changes Corporation in the USA as a UNIX system on have encouraged more research departments and Amdahl’s mainframe. At first, UTS/M was based researchers to use science and technology calcu- on SVR2Note2), and was supplied as a business-ori- lation machines.