Organización De Computadoras
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Computer Architectures an Overview
Computer Architectures An Overview PDF generated using the open source mwlib toolkit. See http://code.pediapress.com/ for more information. PDF generated at: Sat, 25 Feb 2012 22:35:32 UTC Contents Articles Microarchitecture 1 x86 7 PowerPC 23 IBM POWER 33 MIPS architecture 39 SPARC 57 ARM architecture 65 DEC Alpha 80 AlphaStation 92 AlphaServer 95 Very long instruction word 103 Instruction-level parallelism 107 Explicitly parallel instruction computing 108 References Article Sources and Contributors 111 Image Sources, Licenses and Contributors 113 Article Licenses License 114 Microarchitecture 1 Microarchitecture In computer engineering, microarchitecture (sometimes abbreviated to µarch or uarch), also called computer organization, is the way a given instruction set architecture (ISA) is implemented on a processor. A given ISA may be implemented with different microarchitectures.[1] Implementations might vary due to different goals of a given design or due to shifts in technology.[2] Computer architecture is the combination of microarchitecture and instruction set design. Relation to instruction set architecture The ISA is roughly the same as the programming model of a processor as seen by an assembly language programmer or compiler writer. The ISA includes the execution model, processor registers, address and data formats among other things. The Intel Core microarchitecture microarchitecture includes the constituent parts of the processor and how these interconnect and interoperate to implement the ISA. The microarchitecture of a machine is usually represented as (more or less detailed) diagrams that describe the interconnections of the various microarchitectural elements of the machine, which may be everything from single gates and registers, to complete arithmetic logic units (ALU)s and even larger elements. -

“LCD TV Matters” Volume 2, Issue 2
“LCD TV Matters” Volume 2, Issue 2 "A Great TV in Every Room" LCD TV Association LCD TV Matters Pre-CES 2009 Contents Chairman’s Corner: A crazy few months... by Bruce Berkoff 3 LCD-TV News compiled by Veritas et Visus 6 Sharp unveils AQUOS Experience for holiday season 6 Samsung introduces a 2000-nit 70-inch LCD panel 6 Panasonic Viera TH-PZR900 HDTV sports terabyte drive 6 LG Display shows off 480Hz LCD TV panel 7 Viewsonic launches 24-inch 1080p LCD TV 7 Samsung introduces 52-inch “Touch of Color” LCD TV 7 HDMI adopted by 700+ manufacturers as new CE and PC products hit market 7 Sharp releases world’s first LCD TV with built-in Blu-ray Disc recorder 8 Sony unveils world's thinnest LCD TV 8 LifeSize introduces the next-generation telepresence and high definition video communications 8 Sharp adds enhanced inputs and network connectivity to HD LCD line-up 9 Panasonic launches PZ850 Web-enabled TVs – features H.264 and four HDMI ports 9 Schaub Lorenz introduces $130,000 40-inch LCD TV 10 Philips Research reveals ultra-thin backlight technology for TVs 10 LG and Samsung join forces to develop mobile digital TV standard via ATSC 10 eyevis introduces 56-inch LCD TV at 3840x2160 pixels 11 AUO and Qisda form JV to manufacture LCD TVs 11 ATSC approves AVC within DTV transmissions 11 NEC introduces 82-inch professional-grade LCD for digital signage 11 Fairchild Semiconductor’s LCD TV design achieves 90% efficiency 12 ZeeVee now shipping ZvBox for PC content streaming 12 GAO reports DTV transition making progress 12 Broadcom to acquire digital -

Embedded Linux Primer: a Practical Real-World Approach
Embedded Linux Primer: A Practical, Real-World Approach By Christopher Hallinan ............................................... Publisher: Prentice Hall Pub Date: September 18, 2006 Print ISBN-10: 0-13-167984-8 Print ISBN-13: 978-0-13-167984-9 Pages: 576 Table of Contents | Index Comprehensive Real-World Guidance for Every Embedded Developer and Engineer This book brings together indispensable knowledge for building efficient, high-value, Linux-based embedded products: information that has never been assembled in one place before. Drawing on years of experience as an embedded Linux consultant and field application engineer, Christopher Hallinan offers solutions for the specific technical issues you're most likely to face, demonstrates how to build an effective embedded Linux environment, and shows how to use it as productively as possible. Hallinan begins by touring a typical Linux-based embedded system, introducing key concepts and components, and calling attention to differences between Linux and traditional embedded environments. Writing from the embedded developer's viewpoint, he thoroughly addresses issues ranging from kernel building and initialization to bootloaders, device drivers to file systems. Hallinan thoroughly covers the increasingly popular BusyBox utilities; presents a step-by-step walkthrough of porting Linux to custom boards; and introduces real-time configuration via CONFIG_RT--one of today's most exciting developments in embedded Linux. You'll find especially detailed coverage of using development tools to analyze -

Radeon® X1550 Graphics Technology - GPU Specifications
Radeon® X1550 Graphics Technology - GPU Specifications Advanced Image Quality Features • 64-bit floating point HDR rendering supported throughout the pipeline Features • Includes support for blending and multi-sample anti-aliasing • 105 million transistors on 90nm fabrication process • 32-bit integer HDR (10:10:10:2) format supported throughout the pipeline • Ultra-threaded architecture with fast dynamic branching • Includes support for blending and multi-sample anti-aliasing • 4 pixel shader processors • 2x/4x/6x Anti-Aliasing modes • 2 vertex shader processors • Multi-sample algorithm with gamma correction, programmable sparse sample • 128-bit 4-channel DDR2 memory interface, 64-bit/2-channel patterns, and centroid sampling configurations • New Adaptive Anti-Aliasing feature with Performance and Quality modes • Native PCI Express x16 bus interface, AGP 8x/4x, 3.3v PCI • Temporal Anti-Aliasing mode Note: AGP and PCI supported through bridge ASIC • Lossless Color Compression (up to 6:1) at all resolutions, including widescreen HDTV resolutions High Performance Memory Controller • 2x/4x/8x/16x Anisotropic Filtering modes • Fully associative texture, color, and Z/stencil cache designs • Up to 128-tap texture filtering • Hierarchical Z-buffer with Early Z test • Adaptive algorithm with Performance and Quality options • Lossless Z Compression (up to 48:1) • High resolution texture support (up to 4k x 4k) • Fast Z-Buffer Clear • Z/stencil xache optimized for real-time shadow rendering Avivo™ Video and Display Platform • High performance programmable -

Video Streaming
Video streaming a research on free video streaming technologies Jaromil dyne.org / rastasoft.org Table of Contents Introduction................................................................................................................................................1 We need CPU for compression .................................................................................................................2 We need bandwidth for distribution ........................................................................................................2 We need harddisk space for storage.........................................................................................................3 Distribution of video archives...................................................................................................................4 Embedded solutions...................................................................................................................................6 Streaming video software..........................................................................................................................8 About the author of this document ........................................................................................................10 Video streaming terms glossary..............................................................................................................11 Introduction Given the vast panorama of video technologies available nowadays, this research could fill up way too much paper in the -

Download X100 Graphics Overview In
x100 - graphics overview Bringing a unique way of seeing things. The Shuttle X100 features ATI’s Mobility™ Radeon® X1400 - providing best-in-class graph- ics performance, delivering enhanced 3D gaming, high quality video playback, and high energy efficency. Boost graphics performance with the dedicated 90-nanometer process Graphics Processing Unit (GPU) with an ultra-threaded 3D architecture, ring-bus memory controller, and a native 16x PCI Express® bus interface. Render lifelike 3D characters and scenes with any OpenGL® and DirectX® 9 game and enjoy astonishing effects with full DirectX® 9 Shader Model 3.0 support. With ATI’s Avivo™ High-Definition video and display enhancements and PowerPlay™ 6.0 advanced power management, Mobility Radeon X1400 creates a new performance threshold for mobile productivity and entertainment. Best-in-class mobile graphics performance. Go for the industry’s best-in-class graphics performance for your small-form-factor—ATI’s Mobile on desktop. Mobility™ Radeon® X1400. A discrete 90-nanometer process GPU with a new ultra-threaded The X100 breaks the rules of the 3D architecture delivers visual power far beyond integrated UMA graphics, performance- computing world, by bring mobile enhanced with a new ring-bus memory controller and high-speed 128-bit 4-channel technology in a desktop form-fac- tor. The Intel Core Duo, Core Solo, DDR/DDR2/GDDR3 RAM support. Accelerate through tasks and entertainment with a native and Celeron M bring powerful and x16-lane PCI Express® bus interface, pumping data through 4 pixel shader pipelines and 2 energy efficent processors to time vertex processors. Mobility Radeon X1400 packs all the mobile graphics power and visual when environmental consideration velocity you need with your X100. -

Development of an Immersive Challenge Racing Game for 3D-TV
SBC - Proceedings of SBGames 2013 Computing Track – Full Papers Development of an Immersive Challenge Racing Game for 3D-TV Ana Grasielle Dionísio Corrêa, Alexandre Antonino Gonçalves Martinazzo, Erich Panzenboeck Lotto, Marcelo Archanjo José, Irene Karaguilla Ficheman, Roseli de Deus Lopes Escola Politécnica da Universidade de São Paulo (EP-USP) Laboratório de Sistemas Integráveis (LSI), São Paulo, Brasil {anagrasi, am, irene, roseli} @lsi.usp.br; [email protected]; [email protected] Abstract—Television is most people favorite pastime. [7]. For this reason, the Advanced Television Systems The way we watch TV has not changed since its invention Committee (ATSC) in North America has created a planning 75 years ago. However, research in computer graphics and team to examine the possible advantages and disadvantages, display technology favored the advances of TV platforms, requirements and steps required to manufacture and deliver such as interactivity and stereoscopy. Moreover device 3D-TV content [7]. Similar investigations are also being connectivity allows new ways of distributing content and carried out by international standardization bodies such as the applications, including films and games. Combining those European Broadcasting Union (EBU), the International innovations, 3D-TV is a new type of home entertainment Telecommunication Union (ITU) and 3D Home Consortium [8]. that provides a rich and fun experience, innovating not only the way we watch movies and television series but also Great interest in 3D-TV is the recognition that compared the way we interact. In this context, this paper presents the with conventional television (standard 2D), 3D technology development of an immersive racing game for 3D-TV, improves significantly television entertainment value [9], [10]. -
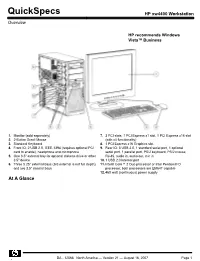
HP Xw4400 Workstation Overview
QuickSpecs HP xw4400 Workstation Overview HP recommends Windows Vista™ Business 1. Monitor (sold separately) 7. 3 PCI slots, 1 PCI Express x1 slot, 1 PCI Express x16 slot 2. 2-Button Scroll Mouse (with x4 functionality) 3. Standard Keyboard 8. 1 PCI Express x16 Graphics slot 4. Front IO: 2 USB 2.0, IEEE-1394 (requires optional PCI 9. Rear IO: 5 USB 2.0, 1 standard serial port, 1 optional card to enable), headphone and microphone serial port, 1 parallel port, PS/2 keyboard, PS/2 mouse, 5. One 3.5" external bay for optional diskette drive or other RJ-45, audio in, audio out, mic in 3.5" device 10. 1 USB 2.0 internal port 6. Three 5.25" external bays (3rd external is not full depth), 11. Intel® Core™ 2 Duo processor or Intel Pentium® D and two 3.5" internal bays processor; both processors are EM64T capable 12. 460 watt (continuous) power supply At A Glance DA - 12568 North America — Version 21 — August 16, 2007 Page 1 QuickSpecs HP xw4400 Workstation Overview Choice of Operating Systems: Microsoft Vista™ Business 32 or 64* Microsoft Windows Vista™ Business 32-bit downgrade to Microsoft Windows XP Professional Microsoft Windows Vista™ Business 64-bit downgrade to Microsoft Windows XP Professional x64 Microsoft Windows XP Professional (32-Bit) Microsoft Windows XP Professional x64 Edition Preloaded: Red Hat Enterprise Linux® WS 4 (Update 4 or later) (32- or 64-bit version) HP Linux Installer Kit (see http://www.hp.com/workstations/software/linux) Red Hat Enterprise Linux WS 4 (Update 4 or later) (32- or 64-bit version) Red Hat Enterprise Linux -

AMD M690T Databook
AMD M690T Databook Technical Reference Manual Rev. 3.04 P/N: 42437_m690t_ds_nda_3.04 © 2007 Advanced Micro Devices, Inc Please note that in this databook, references to "DVI" and "HDMI" refer to the capability of the TMDS interface, multiplexed on the PCI Express® external graphics interface, to enable DVI or HDMI through passive enabling circuitries. Any statement in this databook on any DVI or HDMI-related functionality must be understood in that context. Advanced Micro Devices, Inc., will not provide any indemnity, pay any royalty, nor provide any license/sublicense to any: (a) Intellectual property rights relating to any of the following: (i) Macrovision for its Analog Protection System ("APS") technologies; (ii) Advanced Television Systems Committee (ATSC) standard and related technologies; or (iii) the High Definition Multimedia Interface (HDMI) standard and related technologies; or (b) Audio and/or video codecs or any industry standard technology (e.g., technology or specifications promulgated by any standards development organization, consortium, trade association, special interest group or like entity). This device is protected by U.S. patent numbers 4,631,603, 4,577,216 and 4,819,098 and other intellectual property rights. The use of Macrovision's copy protection technology in the device must be authorized by Macrovision and is intended for home and other limited pay-per-view uses only, unless otherwise authorized in writing by Macrovision. Reverse engineering or disassembly is prohibited. This device may only be sold or distributed to: (i) a Macrovision Authorized Buyer, (ii) a customer (PMA Customer) who has executed a Proprietary Materials Agreement (PMA) with Macrovision that is still in effect, (iii) a contract manufacturer approved by Macrovision to purchase this device on behalf of a Macrovision Authorized Buyer or a PMA Customer, or (iv) a distributor who has executed a Macrovision-specified distribution agreement with ATI. -

A Platform for Building Programmable Multicore Video Processors
mediaDSP™: A Platform for Building Programmable Multicore Video Processors Richard Selvaggi and Larry Pearlstein AMD Hot Chips 20, August 2008 Recent Trends Big-screen TV sets have been selling in ever-increasing numbers in the past 5 to 10 years. LCDs have recently overtaken CRTs in unit shipments. LCD display technology has advanced in many ways over these years. – Wider viewing angle – Higher contrast ratio – Wider color gamut – Higher resolution But...motion blur is one of the last remaining challenges for LCD display technology. – This is the problem our chip is addressing. 2 August 2008 Hot Chips 20: mediaDSP Perception of Motion Blur on LCD Panels 60 frames/sec 120 frames/sec 16ms 16ms 8ms Reduced blur Reduced Interpolated frames Eye moves continuously, smearing Eye moves a shorter arc in 8ms, thus the still image across the retina reducing amount of blur across retina LCD is a hold-type display (not impulsive, like CRT). Projected object is smeared on the retina by the amount that the eye moves in one frame-time (16 vs. 8ms). 3 August 2008 Hot Chips 20: mediaDSP TV System Block Diagram TV System (FullHD, 1080p) TV Main Board Panel Board 120Hz 60Hz AMD DTV SoC Xilleon™ 420 120Hz LCD Panel DRAM DRAM AMD Xilleon 420 (X420) performs motion compensated frame rate conversion (MC-FRC) and doubles the frame rate. Samsung Timing Controller (TCON) for LCD panel is integrated inside X420. 4 August 2008 Hot Chips 20: mediaDSP AMD Xilleon 420 Block Diagram AMD Xilleon™ 420 Timing mini-LVDS LVDS LVDS mini-LVDS Controller Pixel Pixel Input -

ATI Radeon™ HD 4300 Series GPU Specifications
ATI Radeon™ HD 4300 Series GPU Specifications Products & Technologies Support & Drivers at Work at Home at Play Worldwide | About AMD | News | Where to buy Find a Driver Products & Technologies ATI Radeon HD 4000 ATI Radeon HD 4870 X2 ATI Radeon HD 4890 ATI Radeon HD 4870 ATI Radeon HD 4850 ATI Radeon HD 4830 ATI Radeon™ HD 4770 ATI Radeon HD 4600 ATI Radeon HD 4550 ATI Radeon HD 4300 ATI Radeon HD 4200 Series ATI Radeon™ HD 4300 Series GPU Specifications ● 242 million transistors on 55nm fabrication process ● PCI Express 2.0 x16 bus interface ● GDDR3/DDR3/DDR2 memory interface (depending on model) ● Microsoft® DirectX® 10.1 support ❍ Shader Model 4.1 ❍ 32-bit floating point texture filtering ❍ Indexed cube map arrays ❍ Independent blend modes per render target ❍ Pixel coverage sample masking ❍ Read/write multi-sample surfaces with shaders ❍ Gather4 texture fetching ● Unified Superscalar Shader Architecture ❍ 80 stream processing units ■ Dynamic load balancing and resource allocation for vertex, geometry, and pixel shaders ■ Common instruction set and texture unit access supported for all types of shaders ■ Dedicated branch execution units and texture address processors ❍ 128-bit floating point precision for all operations ❍ Command processor for reduced CPU overhead ❍ Shader instruction and constant caches ❍ Up to 32 texture fetches per clock cycle ❍ Up to 128 textures per pixel ❍ Fully associative multi-level texture cache design ❍ DXTC and 3Dc+ texture compression ❍ High resolution texture support (up to 8192 x 8192) ❍ Fully associative -

Club 3D Radeon X1300 Pcie New Standard for Mainstream VGA
Club 3D Radeon X1300 PCIe New Standard For Mainstream VGA Introduction: The Club 3D Radeon® X1300Pro is a completely new generation of graphics based on latest 3D Technolo- gies. In fact it is a derivative of the ATI™ high end X1800 family to bring high performance graphics tech- nology to the discrete desktop market on extremely PowerPack sharp pricing levels. The Club 3D Radeon® X1300Pro is targeted to the more 3D games orientated PC user. It combines the excellent desktop capabilities for Home and Office applications of the X1300 with more rendering power for 3D games by having higher clock speeds. Order Information: • Radeon X1300 256MB : CGAX-136TVD Product Positioning: Colin McRae 2005 • Mainstream market • SOHO and Gaming Features: System requirements ® ® ® Specifications: • DirectX 9.x compliant • Intel Pentium or AMD™ Athlon™ or • Shader Model 3 support compatible Item code: CGAX-136TVD • High Dimension Floating-Point Textures • 128MB of system memory Format: PCIe • Full Screen Anti Aliasing Gamma Correction • Mainboard with free PCIe (x16) slot Engine Clock: 400MHz • Avivo™ • CD-ROM drive for software installation Memory Clock: 500MHz • Video Gamma Correction • 350Watt or greater Power Supply Driver/E-manual Memory: 256MB DDR2 • 3Dc™ Normal Map Compression • Enhanced HyperMemory Technology Memory Bus: 128 bit Pixel Pipelines: 4 Accessories: Operating System Support RAMDAC: 2x 400MHz • S-video/Composite cable • Microsoft® Windows® XP/x64, MCE ® ® DVI-I: √ • Panda Jr WWF, Colin McRae 2005 Game • Microsoft Windows 2000 • DVI/CRT converter