A Language-Based Software Framework for Mission Planning In
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
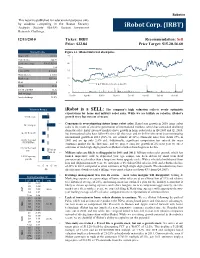
Robotics Irobot Corp. (IRBT)
Robotics This report is published for educational purposes only by students competing in the Boston Security Analysts Society (BSAS) Boston Investment iRobot Corp. (IRBT) Research Challenge. 12/13/2010 Ticker: IRBT Recommendation: Sell Price: $22.84 Price Target: $15.20-16.60 Market Profile Figure 1.1: iRobot historical stock price Shares O/S 25 mm 25 Current price $22.84 52 wk price range $14.45-$23.00 20 Beta 1.86 iRobot 3 mo ADTV 0.14 mm 15 Short interest 2.1 mm Market cap $581mm 10 Debt 0 S & P 500 (benchmarked Jan-09) P/10E 25.2x 5 EV/10 EBITDA 13.5x Instl holdings 57.8% 0 Jan-09 Apr-09 Jul-09 Oct-09 Jan-10 Apr-10 Jul-10 Oct-10 Insider holdings 12.5% Valuation Ranges iRobot is a SELL: The company’s high valuation reflects overly optimistic expectations for home and military robot sales. While we are bullish on robotics, iRobot’s 52 wk range growth story has run out of steam. • Consensus is overestimating future home robot sales: Rapid yoy growth in 2010 home robot Street targets sales is the result of one-time penetration of international markets, which has concealed declining domestic sales. Entry into new markets drove growth in home robot sales in Q4 2009 and Q1 2010, 20-25x P/2011E but international sales have fallen 4% since Q1 this year, and we believe the street is overestimating international growth in 2011 (30% vs. our estimate of 18%). Domestic sales were down 29% in 8-12x Terminal 2009 and are up only 2.5% ytd. -

Packaging Specifications and Design
ECE 477 Digital Systems Senior Design Project Rev 8/09 Homework 4: Packaging Specifications and Design Team Code Name: 2D-MPR Group No. 12 Team Member Completing This Homework: Tyler Neuenschwander E-mail Address of Team Member: tcneuens@ purdue.edu NOTE: This is the first in a series of four “design component” homework assignments, each of which is to be completed by one team member. The body of the report should be 3-5 pages, not including this cover page, references, attachments or appendices. Evaluation: SCORE DESCRIPTION Excellent – among the best papers submitted for this assignment. Very few 10 corrections needed for version submitted in Final Report. Very good – all requirements aptly met. Minor additions/corrections needed for 9 version submitted in Final Report. Good – all requirements considered and addressed. Several noteworthy 8 additions/corrections needed for version submitted in Final Report. Average – all requirements basically met, but some revisions in content should 7 be made for the version submitted in the Final Report. Marginal – all requirements met at a nominal level. Significant revisions in 6 content should be made for the version submitted in the Final Report. Below the passing threshold – major revisions required to meet report * requirements at a nominal level. Revise and resubmit. * Resubmissions are due within one week of the date of return, and will be awarded a score of “6” provided all report requirements have been met at a nominal level. Comments: Comments from the grader will be inserted here. ECE 477 Digital Systems Senior Design Project Rev 8/09 1.0 Introduction The 2D-MPR is an autonomous robot designed to collect data required to map a room. -

Irobot: ROBOTS for the HOME
Licensed to: iChapters User CASE 5 iROBOT: ROBOTS FOR THE HOME Robots have been around for a long time. Detroit has appeared on the cover of Popular Science. It was clear used robots for four decades to build cars, and manu- by then that his future lay in inventions. facturers of all kinds of goods use some form of robot- ics to achieve effi ciencies and productivity. But until The Opportunity iRobot brought its battery-powered vacuum cleaner to the market, no one had successfully used robots in In 1990, Brooks and Angle, who by then had be- the home as an appliance. The issue was not whether it come close working partners with their MIT col- was possible to use robots in the home, but could they league Helen Greiner, borrowed from their credit be produced at a price customers would pay. Until the cards and used bank debt to found iRobot in a tiny introduction of Roomba, iRobot’s intelligent vacuum apartment in Somerville, Massachusetts. The goal of cleaner, robots for the home cost tens of thousands of the company was to build robots that would affect dollars. At Roomba’s price point of $$199,199, it was now hhowow peppeopleople llivedived ttheirheir llives.ivese . AtAt tthathaat ttime, no one possiblee ffororor ttheheh aaveragevev rar gee cconsumeronsus meer too aaffordfford to hhaveava e a cocouldoulld coconceivenceie ve ooff a wawwayy tot bbringringn rrobotsoboto s into domes- robot cleanleaean the hohhouse.usu e.. TThathah t inn iitselftssele f is aann iniinterestingteerrests inng titicc lilifefe iinn aan aaffordableffforordad blle wwaway,y, aandndd iiRobotRoR bob t was still years story, bututt eevenveen mommorerer iinterestingnteresestitingg iiss ththehe eneentrepreneurialnttrepepreenen ururiiaal awawayayy ffromroom didiscoveringsscoovverrini g ththee oononee aapapplicationppliccatiio that would journey of Colin Angle and his company, iRobot. -

Irobot Create 2 Tethered Driving Using Serial Communication and Python Nick Saxton April 2, 2015
iRobot Create 2 Tethered Driving Using Serial Communication and Python Nick Saxton April 2, 2015 Executive Summary: This application note will detail the necessary steps to write a simple Python script to control an iRobot Create 2 through serial port communication. Following an introduction to the topic and the technology used, a detailed walkthrough will be provided showing the reader how to write a user controlled tethered driving script. This walkthrough will start with a blank file and show all of the required steps to reach the final script. Additionally, automated driving code will be discussed, including comments on how it is used in the Automated 3D Environment Modeling project sponsored by Dr. Daniel Morris of the Michigan State University 3D Vision Lab1. Keywords: iRobot Create Tethered Driving Serial Communication2 Python Programming 1 Introduction: This section will introduce the technology and concepts used in this application note. First, an overview of the iRobot Create 2 Programmable Robot will be provided. Then, the Python programming language will be examined, including a brief history of the language and some of its key features. Finally, serial port communication will be discussed. Following this introduction, the objective of this application note will be looked at. The iRobot Create 2 Programmable Robot is a fully programmable version of iRobot’s popular Roomba vacuum cleaning robot. It weighs under 8 lbs, measures a little over 13 inches in diameter and approximately 3.5 inches tall, and has a serial port on its top side, accessible after removing the top cover. An image of the Create 2 can be seen below in Figure 1. -

1 ROS SEMINAR UNIT 1.3 ROS & People & Rethink Give a Short
ROS SEMINAR UNIT 1.3 ROS & People & Rethink Give a short description of the following organizations and include their contributions to Robotics and ROS. Give References. a. Willow Garage b. iRobot c. Rethink Robotics a. https://en.wikipedia.org/wiki/Willow_Garage Willow Garage hired its first employees in January 2007, Jonathan Stark, Melonee Wise, Curt Meyers, and John Hsu. All four were recruited by Scott Hassan to work on Willow Garage's first projects which included an SUV entrant into the DARPA Grand Challenge and an autonomous solar powered boat for deploying scientific payloads in open oceans.[8] In the Fall of 2008, Eric Berger and Keenan Wyrobek pitched Willow Garage on creating a common hardware (PR1) and software (ROS) platforms and the idea of creating a Personal Robotics Program at Willow Garage[9]. They has previously started the Stanford Personal Robotics Program[10] to build the platform technologies that would enable the personal robotics industry. At Willow Garage they led the development of PR2[11], the common hardware platform for robotics R&D, and ROS[12], the open source robot operating system. https://spectrum.ieee.org/automaton/robotics/robotics-software/the-origin-story-of-ros-the-linux-of- robotics [9] Willow Garage currently has eight spin-offs: Here are four of importance: Industrial Perception Inc. - Acquired by Google in August 2013, IPI had as its broader mission "eyes and brains for industrial robots", focused on new robotic applications in logistics such as autonomous truck unloading. OpenCV - An open source computer vision and machine learning software library built to provide a common infrastructure for computer vision applications and to accelerate the use of machine perception in the commercial products. -

Integrating Irobot-Arduino-Kinect Systems: an Educational Voice and Keyboard Operated Wireless Mobile Robot
International Journal of Scientific Engineering and Technology ISSN : 2277-1581 Volume No. 6, Issue No. 6, PP : 188-192 1 June 2017 Integrating iRobot-Arduino-Kinect Systems: An Educational Voice and Keyboard Operated Wireless Mobile Robot S. I. A. P. Diddeniya1, K. A. S. V. Rathnayake1, H. N. Gunasinghe2, W. K. I. L. Wanniarachchi1* 1Department of Physics, Faculty of Applied Sciences, University of Sri Jayewardenepura, 10250 Sri Lanka 2Department of Mathematics and Computer Science, The Open University of Sri Lanka, 10250 Sri Lanka Corresponding Email: [email protected] Abstract: This paper presents use of iRobot Create different time frames. Siliveru Ramesh et al. proposed a brain- Programmable Robot for real time wireless controlling via computer interface system for a mind controlled robot. The speech and keyboard commands in a domestic environment. system uses Mindwave Headset which is provided by Neurosky Commercial hardware such as iRobot create 2 programmable Technologies and those signals will be transferred by using robot, Kinect V2, Arduino Uno and NRF24L01 radio Bluetooth and uses LabVIEW design software to analyze brain frequency module were used, based on open-source code in the waves [1]. implementation. At the receiver end iRobot programmable Muhammed Zahit et al. proposed a robot controlling system robot was used as the mobile robot. At the transmission end, a with voice commands that takes speech commands to the PC based system was used. The keyboard controlling system is computer by using a microphone and the features are extracted designed to control the directions of the moving robot. In the by using Mel Frequency Cepstral Coefficients algorithms. -

Turtlebot: ROS Meets Kinect Meets Create
Then & Now - Jan 12.qxd 12/5/2011 11:24 AM Page 78 and forums atThen NOW Discuss this article in the SERVO Magazine TurtleBot: ROS Meets http://forum.servomagazine.com Kinect Meets Create by Tom Carroll Turtle robots have been around since Grey Walter’s Tortoise of the late ‘40s. When hobbyist robots started to be popular in the early ‘80s, robots such as the Tasman Turtle (shown in Figure 1) were popular. They were easy to interface and control by an Apple II or similar computer. ewer turtle-type robots such as the BBC Turtle robot One is the Willow Garage ROS-based TurtleBot and the Nshown in Figure 2 or the Propeller-head Geek Turtle other is Eddie from Parallax that is based on Microsoft’s robot shown in Figure 3 are still popular and are sold at Robotics Developer Studio, RDS4. Neither of these two many hobby robot outlets. These robots are simple to robots actually utilize turtle shell construction and both construct, interface, program, and operate as they are feature Microsoft’s powerful vision sensor: the Kinect. Each usually differentially-driven and have a clear plastic shell that robot actually has so many features that I will do a comparison shows the interior. They offer beginners a way to learn over the next couple columns. I’ll concentrate on the programming techniques to control a basic robot. TurtleBot this month. Next time, we’ll take a look at Eddie. The term ‘turtle’ has recently taken on a new meaning with the introduction of two turtle-style experimenter’s The TurtleBot machines that are changing the face of hobby and advanced experimental robotics. -

Aligning Design of Embodied Interfaces to Learner Goals
Aligning Capabilities of Interactive Educational Tools to Learner Goals Tom Lauwers CMU-RI-TR-10-09 Submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy in Robotics The Robotics Institute Carnegie Mellon University Pittsburgh, Pennsylvania 15213 Submitted in partial fulfillment of the requirements of the Program for Interdisciplinary Education Research (PIER) Carnegie Mellon University Pittsburgh, Pennsylvania 15213 Thesis Committee: Illah Nourbakhsh, Chair, Carnegie Mellon Robotics Institute Sharon Carver, Carnegie Mellon Psychology Department John Dolan, Carnegie Mellon Robotics Institute, Fred Martin, University of Massachusetts Lowell Computer Science c 2010, Tom Lauwers. ABSTRACT This thesis is about a design process for creating educationally relevant tools. I submit that the key to creating tools that are educationally relevant is to focus on ensuring a high degree of alignment between the designed tool and the broader educational context into which the tool will be integrated. The thesis presents methods and processes for creating a tool that is both well aligned and relevant. The design domain of the thesis is described by a set of tools I refer to as “Configurable Embodied Interfaces”. Configurable embodied interfaces have a number of key features, they: • Can sense their local surroundings through the detection of such environ- mental and physical parameters as light, sound, imagery, device acceleration, etc. • Act on their local environment by outputting sound, light, imagery, motion of the device, etc. • Are configurable in such a way as to link these inputs and outputs in a nearly unlimited number of ways. • Contain active ways for users to either directly create new programs linking input and output, or to easily re-configure them by running different pro- grams on them. -

Using the Android Platform to Control Robots
Using the Android Platform to control Robots Stephan Gobel,¨ Ruben Jubeh, Simon-Lennert Raesch and Albert Zundorf¨ Software Engineering Research Group Kassel University Wilhelmshoher¨ Allee 73 34121 Kassel, Germany Email: [sgoe jubeh lrae zuendorf]@cs.uni-kassel.de Abstract—The Android Mobile Phone Platform by Google motors and provides a set of useful sensors, which is sufficient becomes more and more popular among software developers, for building simple robots like path finders, forklifts etc. From because of its powerful capabilities and open architecture. As our point of view, another advantage of the NXT system its based on the java programming language, its ideal lecture content of specialized computer science courses or applicable to is the availability of a Java Virtual Machine, called leJOS. student projects. We think it is a great platform for a robotic However the leJOS Java (no reflection), the CPU power and system control, as it provides plenty of resources and already the RAM and ROM space (64kb each) provided by the NXT integrates a lot of sensors. The java language makes the system are quite restricted. Due to our experiences, the capabilities very attractive to apply state-of-the-art software engineering of the NXT do not suffice to run complex Java programs techniques, which is our main research topic. The unsolved issue is to make the android device interoperate with the remaining with complex runtime data models that want to use for smart parts of the robot: actuators, specialized sensors and maybe co- system behavior. The LEGO Mindstorms NXT and leJOS will processors. In this paper we discuss various connection methods be further discussed in section III. -

Annual Report 2006 Grow the Business
Grow the business. Lead the industry. Annual Report 2006 Grow the business. Lead the industry. Dear Stockholder, Fiscal 2006 – our first full year as a public company – was a very successful year for iRobot. We delivered record financial results against our aggressive 2006 growth plan while continuing to invest in and develop new products in both of our divisions. The significant progress we made in maturing the operational capabilities of the organization will support our multi-year growth strategy as we move through 2007 and beyond. iRobot’s revenue increased 33 percent this past year, from nearly $142 million in fiscal 2005 to a record $189 million in 2006, the result of growth in both divisions. We also achieved profitability for the third consecutive year, as pre-tax income grew 39 percent to $3.9 million in fiscal 2006. Revenue growth for the year was driven by a 60% increase in our Government & Industrial Robots division, primarily the result of producing and delivering 385 iRobot PackBot robots, bringing our current total to Revenue Growth more than 900 worldwide, and selling associated spares, support and accessories. Fueling the 20% growth of 200 Home Robots revenue was continued demand for our Roomba floor vacuuming robot, especially in the direct sales channel where we more than doubled revenue for 150 the full year, and the initial distribution into the retail channel of our Scooba floor washing robot, which was released late in 2005. $ in Millions 100 Investment in R&D is critical to ensuring the sustained, organic growth of the company. Our outstanding 50 performance in 2006 provided us with the opportunity to make incremental investments that yielded concrete 0 2002 2003 2004 2005 2006 results, including the iRobot PackBot 510, a faster, stronger, easier-to-use, next generation PackBot, and the accelerated development of the iRobot Warrior, our 250-pound, multi-mission platform. -
The Creation of a Low-Cost, Reliable Platform for Mobile Robotics Research By
The Creation of a Low-Cost, Reliable Platform for Mobile Robotics Research by Taylor Harrison Gilbert MASSACHUSETTS INSTITUTE OF TECHNOLOGY Submitted to the Department of Mechanical on May 6, 2011 in partial fulfillment of the J OCT 2 0 2011 requirements for the degree of LIBRARIES Bachelor of Science in Mechanical Engineering ARCHivEs at the MASSACHUSETTS INSTITUTE OF TECHNOLOGY June 2011 C Taylor Harrison Gilbert. All rights reserved. The author hereby grants to MIT permission to reproduce and distribute publicly paper and electronic copies of this thesis document in whole or in part. Author ................................................................................... '1' Taylor Gilbert Department of Mechanical Engineering February 1, 2010 Certified by ....................... f/ John Leonard Po of Mechanical Engineering Accepted by........................... ........... ............. ......................... oIn . 1enhard,lit~ V Samuel C. Collin of Mechanical Engineering Undergraduate Officer T. H. Gilbert 2011 Undergraduate Thesis The Creation of a Low-Cost, Reliable Platform designed for Mobile Robotics Research by Taylor Harrison Gilbert Submitted to the Department of Mechanical Engineering on May 6, 2011 in partial fulfillment of the requirements for the degree of Bachelor of Science in Mechanical Engineering Abstract This work documents the planning process, design, fabrication, and integration of a low- cost robot designed for research on the problem of life-long robot mapping. The robotics platform used is the iRobot Create. This robot also employs the PrimeSensor, a sensor with the ability to provide a pixel-matched, colored depth field in real time. This sensor was later purchased by Microsoft and leveraged in their popular gaming device, the Microsoft Kinect. The robot has a powerful Acer Aspire 1830T-6651 laptop with an Intel Core i5 to perform processor- intensive, real-time image processing. -

101 OPEN ROBOTICS M. Ryan Calo* Robotics Is Poised to Be the Next
Calo FinalBookProofIII 4/6/11 12:03 PM OPEN ROBOTICS M. Ryan Calo* I. INTRODUCTION Robotics is poised to be the next transformative technology. Robots are widely used in manufacturing, warfare, and disaster response,1 and the market for personal robotics is exploding.2 Worldwide sales of home robots—such as iRobot’s popular robotic vacuum cleaner3—are in the millions.4 In fact, Honda has predicted that by the year 2020, it will sell as many robots as it does cars.5 Microsoft founder Bill Gates believes that the robotics industry is in the same place today as the personal computer (“PC”) business was in the 1970s,6 a belief that is significant given that there are now well over one billion PCs—just three decades after their introduction into the market.7 Personal robots under development are sophisticated and versatile. The Japanese company Kawada Industries recently released the HRP4, an all-purpose humanoid robot that is, according to one reporter, “quite Copyright © 2011 by M. Ryan Calo. * Director, Consumer Privacy Project, Center for Internet and Society, Stanford Law School. Co-Chair, Artificial Intelligence and Robotics Committee, American Bar Association. I would like to thank Daniel Siciliano, Mary-Anne Williams, Stephen Wu, Richard Craswell, Noriko Kageki, and Leila Takayama for helping me think through these ideas. Thanks also to the librarians at Stanford Law School for their research guidance. 1. E.g., P.W. SINGER, WIRED FOR WAR: THE ROBOTICS REVOLUTION AND CONFLICT IN THE TWENTY-FIRST CENTURY 7–8 (2009) (noting that robots are being used in the contexts of manufacturing and warfare).